147 Repositories
Python multilingual-summarization Libraries
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022
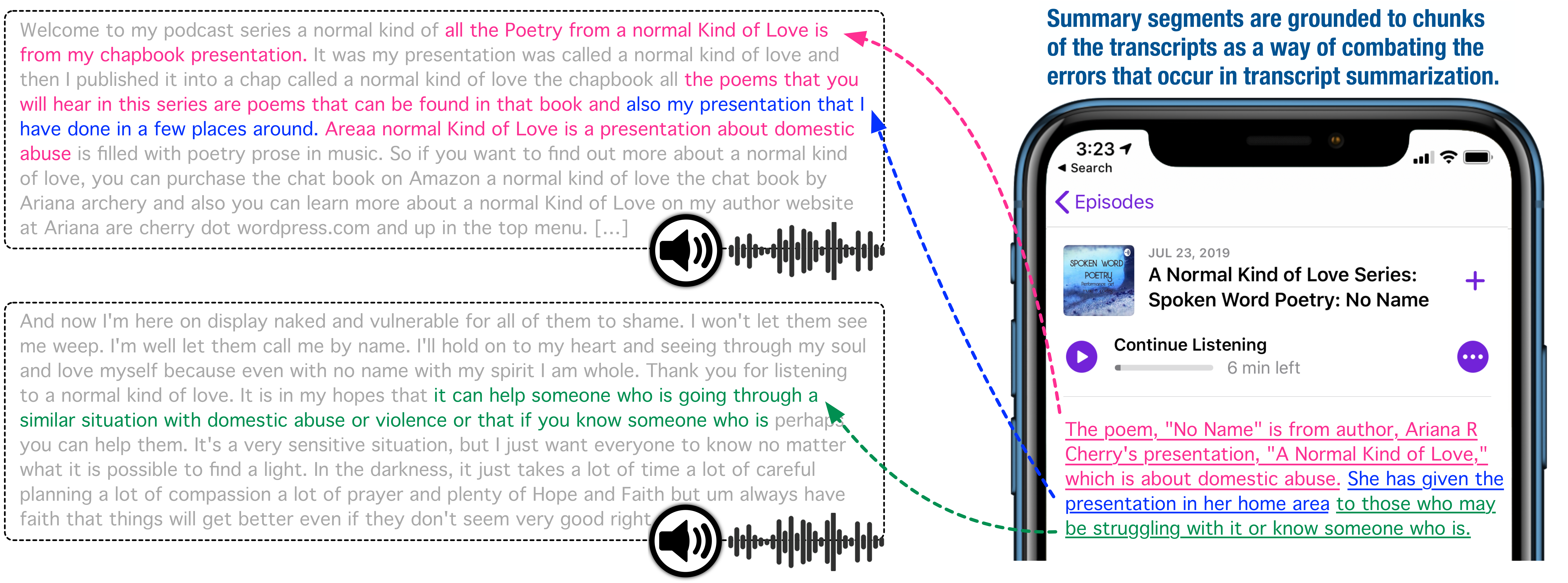
(ACL 2022) The source code for the paper "Towards Abstractive Grounded Summarization of Podcast Transcripts"
Towards Abstractive Grounded Summarization of Podcast Transcripts We provide the source code for the paper "Towards Abstractive Grounded Summarization
 10 Jul 1, 2022
10 Jul 1, 2022

Text-Summarization-using-NLP - Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization
Text-Summarization-using-NLP Text Summarization using NLP to fetch BBC News Arti
 21 Aug 6, 2022
21 Aug 6, 2022
FAMIE is a comprehensive and efficient active learning (AL) toolkit for multilingual information extraction (IE)
FAMIE: A Fast Active Learning Framework for Multilingual Information Extraction
 18 Sep 1, 2022
18 Sep 1, 2022
A python package for deep multilingual punctuation prediction.
This python library predicts the punctuation of English, Italian, French and German texts. We developed it to restore the punctuation of transcribed spoken language.
 27 Dec 22, 2022
27 Dec 22, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022
Multilingual finetuning of Machine Translation model on low-resource languages. Project for Deep Natural Language Processing course.
Low-resource-Machine-Translation This repository contains the code for the project relative to the course Deep Natural Language Processing. The goal o
 3 Jun 22, 2022
3 Jun 22, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques
Tackling data scarcity in Speech Translation using zero-shot multilingual Machine Translation techniques This repository is derived from the NMTGMinor
 1 Sep 7, 2022
1 Sep 7, 2022
Klexikon: A German Dataset for Joint Summarization and Simplification
Klexikon: A German Dataset for Joint Summarization and Simplification Dennis Aumiller and Michael Gertz Heidelberg University Under submission at LREC
 8 Jan 3, 2023
8 Jan 3, 2023

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
26 Jan 16, 2022
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus
CVSS: A Massively Multilingual Speech-to-Speech Translation Corpus CVSS is a massively multilingual-to-English speech-to-speech translation corpus, co
118 Jan 6, 2023
AMUSE - financial summarization
AMUSE AMUSE - financial summarization Unzip data.zip Train new model: python FinAnalyze.py --task train --start 0 --count how many files,-1 for all
 1 Jan 11, 2022
1 Jan 11, 2022

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
Official Implementation of "DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization."
DialogLM Code for AAAI 2022 paper: DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization. Pre-trained Models We release two ve
 92 Dec 19, 2022
92 Dec 19, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023

Understand Text Summarization and create your own summarizer in python
Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.
 1 Oct 18, 2022
1 Oct 18, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022
Pointer-generator - Code for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Networks
Note: this code is no longer actively maintained. However, feel free to use the Issues section to discuss the code with other users. Some users have u
 2.1k Jan 4, 2023
2.1k Jan 4, 2023
Multilingual Image Captioning
Multilingual Image Captioning Authors: Bhavitvya Malik, Gunjan Chhablani Demo Link: https://huggingface.co/spaces/flax-community/multilingual-image-ca
 32 Nov 25, 2022
32 Nov 25, 2022
The implementation of Parameter Differentiation based Multilingual Neural Machine Translation .
The implementation of Parameter Differentiation based Multilingual Neural Machine Translation .
 3 Dec 28, 2021
3 Dec 28, 2021
The implementation of Parameter Differentiation based Multilingual Neural Machine Translation
The implementation of Parameter Differentiation based Multilingual Neural Machin
21 Dec 17, 2022
Age of Empires II recorded game parsing and summarization in Python 3.
mgz Age of Empires II recorded game parsing and summarization in Python 3. Supported Versions Age of Kings (.mgl) The Conquerors (.mgx) Userpatch 1.4
 148 Dec 11, 2022
148 Dec 11, 2022

OpenAI CLIP text encoders for multiple languages!
Multilingual-CLIP OpenAI CLIP text encoders for any language Colab Notebook · Pre-trained Models · Report Bug Overview OpenAI recently released the pa
 481 Dec 30, 2022
481 Dec 30, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
Simple multilingual lemmatizer for Python, especially useful for speed and efficiency
Simplemma: a simple multilingual lemmatizer for Python Purpose Lemmatization is the process of grouping together the inflected forms of a word so they
 70 Dec 29, 2022
70 Dec 29, 2022

This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs".
CrossSum This repository contains the code, data, and models of the paper titled "CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summ
 29 Nov 19, 2022
29 Nov 19, 2022
The source code of "Language Models are Few-shot Multilingual Learners" (MRL @ EMNLP 2021)
Language Models are Few-shot Multilingual Learners Paper This is the source code of the paper [Arxiv] [ACL Anthology]: This code has been written usin
 45 Nov 21, 2022
45 Nov 21, 2022
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022
BERT, LDA, and TFIDF based keyword extraction in Python
BERT, LDA, and TFIDF based keyword extraction in Python kwx is a toolkit for multilingual keyword extraction based on Google's BERT and Latent Dirichl
 41 Dec 27, 2022
41 Dec 27, 2022

A webcam-based 3x3x3 rubik's cube solver written in Python 3 and OpenCV.
Qbr Qbr, pronounced as Cuber, is a webcam-based 3x3x3 rubik's cube solver written in Python 3 and OpenCV. 🌈 Accurate color detection 🔍 Accurate 3x3x
 502 Dec 29, 2022
502 Dec 29, 2022
Official code repository for "Exploring Neural Models for Query-Focused Summarization"
Query-Focused Summarization Official code repository for "Exploring Neural Models for Query-Focused Summarization" This is a work in progress. Expect
 29 Dec 18, 2022
29 Dec 18, 2022
Repo for Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
ESACL: Enhanced Seq2Seq Autoencoder via Contrastive Learning for AbstractiveText Summarization This repo is for our paper "Enhanced Seq2Seq Autoencode
 14 Nov 1, 2022
14 Nov 1, 2022
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models
PEGASUS library Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised
 1.4k Dec 22, 2022
1.4k Dec 22, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
Python Multilingual Ucrel Semantic Analysis System
PymUSAS Python Multilingual Ucrel Semantic Analysis System, it currently is a rule based token level semantic tagger which can be added to any spaCy p
 13 Nov 18, 2022
13 Nov 18, 2022

Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU
GPU Docker NLP Application Deployment Deploying a Text Summarization NLP use case on Docker Container Utilizing Nvidia GPU, to setup the enviroment on
 9 Oct 14, 2022
9 Oct 14, 2022

Korean extractive summarization. 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드
korean extractive summarization 2021 AI 텍스트 요약 온라인 해커톤 화성갈끄니까팀 코드 Leaderboard Notice Text Summarization with Pretrained Encoders에 나오는 bertsumext모델(ext
 3 Aug 10, 2022
3 Aug 10, 2022
Simple GUI where you can enter an article and get a crisp summarized version.
Text-Summarization-using-TextRank-BART Simple GUI where you can enter an article and get a crisp summarized version. How to run: Clone the repo Instal
 4 Sep 28, 2022
4 Sep 28, 2022
Research code for the paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models"
Introduction This repository contains research code for the ACL 2021 paper "How Good is Your Tokenizer? On the Monolingual Performance of Multilingual
 20 Aug 4, 2022
20 Aug 4, 2022
A PyTorch Implementation of PGL-SUM from "Combining Global and Local Attention with Positional Encoding for Video Summarization", Proc. IEEE ISM 2021
PGL-SUM: Combining Global and Local Attention with Positional Encoding for Video Summarization PyTorch Implementation of PGL-SUM From "PGL-SUM: Combin
 35 Dec 22, 2022
35 Dec 22, 2022
CROSS-LINGUAL ABILITY OF MULTILINGUAL BERT: AN EMPIRICAL STUDY
M-BERT-Study CROSS-LINGUAL ABILITY OF MULTILINGUAL BERT: AN EMPIRICAL STUDY Motivation Multilingual BERT (M-BERT) has shown surprising cross lingual a
 1 Feb 28, 2022
1 Feb 28, 2022
Code for the AAAI 2022 paper "Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph".
multilingual-mrc-isdg Code for the AAAI 2022 paper "Zero-Shot Cross-Lingual Machine Reading Comprehension via Inter-Sentence Dependency Graph". This r
 5 Dec 7, 2022
5 Dec 7, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 2, 2023
124 Jan 2, 2023
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021

Automated question generation and question answering from Turkish texts using text-to-text transformers
Turkish Question Generation Offical source code for "Automated question generation & question answering from Turkish texts using text-to-text transfor
 29 Dec 14, 2022
29 Dec 14, 2022
code for EMNLP 2019 paper Text Summarization with Pretrained Encoders
PreSumm This code is for EMNLP 2019 paper Text Summarization with Pretrained Encoders Updates Jan 22 2020: Now you can Summarize Raw Text Input!. Swit
 1.2k Dec 28, 2022
1.2k Dec 28, 2022

Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models.
Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models. Solve a variety of tasks with pre-trained models or finetune them in
 227 Dec 10, 2022
227 Dec 10, 2022
Multiple implementations for abstractive text summurization , using google colab
Text Summarization models if you are able to endorse me on Arxiv, i would be more than glad https://arxiv.org/auth/endorse?x=FRBB89 thanks This repo i
 463 Dec 26, 2022
463 Dec 26, 2022
This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
SummaC: Summary Consistency Detection This repository contains the code for TACL2021 paper: SummaC: Re-Visiting NLI-based Models for Inconsistency Det
 24 Jan 3, 2023
24 Jan 3, 2023
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages This repository contains the code for the pa
 40 Nov 24, 2022
40 Nov 24, 2022

AI-UPV at IberLEF-2021 EXIST task: Sexism Prediction in Spanish and English Tweets Using Monolingual and Multilingual BERT and Ensemble Models
AI-UPV at IberLEF-2021 EXIST task: Sexism Prediction in Spanish and English Tweets Using Monolingual and Multilingual BERT and Ensemble Models Descrip
 1 Jun 8, 2022
1 Jun 8, 2022
Improving Factual Consistency of Abstractive Text Summarization
Improving Factual Consistency of Abstractive Text Summarization We provide the code for the papers: "Entity-level Factual Consistency of Abstractive T
 61 Nov 27, 2022
61 Nov 27, 2022

A Python 3.6+ package to run .many files, where many programs written in many languages may exist in one file.
RunMany Intro | Installation | VSCode Extension | Usage | Syntax | Settings | About A tool to run many programs written in many languages from one fil
 6 May 22, 2022
6 May 22, 2022

Repository for the paper titled: "When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer"
When is BERT Multilingual? Isolating Crucial Ingredients for Cross-lingual Transfer This repository contains code for our paper titled "When is BERT M
 9 Dec 23, 2022
9 Dec 23, 2022
AI Assistant for Building Reliable, High-performing and Fair Multilingual NLP Systems
AI Assistant for Building Reliable, High-performing and Fair Multilingual NLP Systems
37 Nov 29, 2022
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
Amazon Multilingual Counterfactual Dataset (AMCD)
Amazon Multilingual Counterfactual Dataset (AMCD)
35 Sep 20, 2022
This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorithm to summarize documents and FastAPI for the framework.
Indonesian Text Summarization Using FastAPI This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorit
 2 Nov 3, 2022
2 Nov 3, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023

Pytorch implementation of "Get To The Point: Summarization with Pointer-Generator Networks"
About this repository This repo contains an Pytorch implementation for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Netwo
 7 Oct 14, 2022
7 Oct 14, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022
One implementation of the paper "DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing".
Introduction One implementation of the paper "DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing". Users
 18 Dec 11, 2022
18 Dec 11, 2022
utoken is a multilingual tokenizer that divides text into words, punctuation and special tokens such as numbers, URLs, XML tags, email-addresses and hashtags.
utoken utoken is a multilingual tokenizer that divides text into words, punctuation and special tokens such as numbers, URLs, XML tags, email-addresse
 11 Jan 5, 2023
11 Jan 5, 2023

Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
MT5_paddle Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer English | 简体中文 mT5: A Massively
 2 Oct 17, 2021
2 Oct 17, 2021
Code and data for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources.
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS) The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limit
 43 Nov 7, 2022
43 Nov 7, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
740 Dec 24, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 7, 2022
74 Oct 7, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022
Does Pretraining for Summarization Reuqire Knowledge Transfer?
Pretraining summarization models using a corpus of nonsense
 12 Dec 19, 2022
12 Dec 19, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023
A multilingual version of MS MARCO passage ranking dataset
mMARCO A multilingual version of MS MARCO passage ranking dataset This repository presents a neural machine translation-based method for translating t
 75 Dec 27, 2022
75 Dec 27, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
197 Dec 25, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
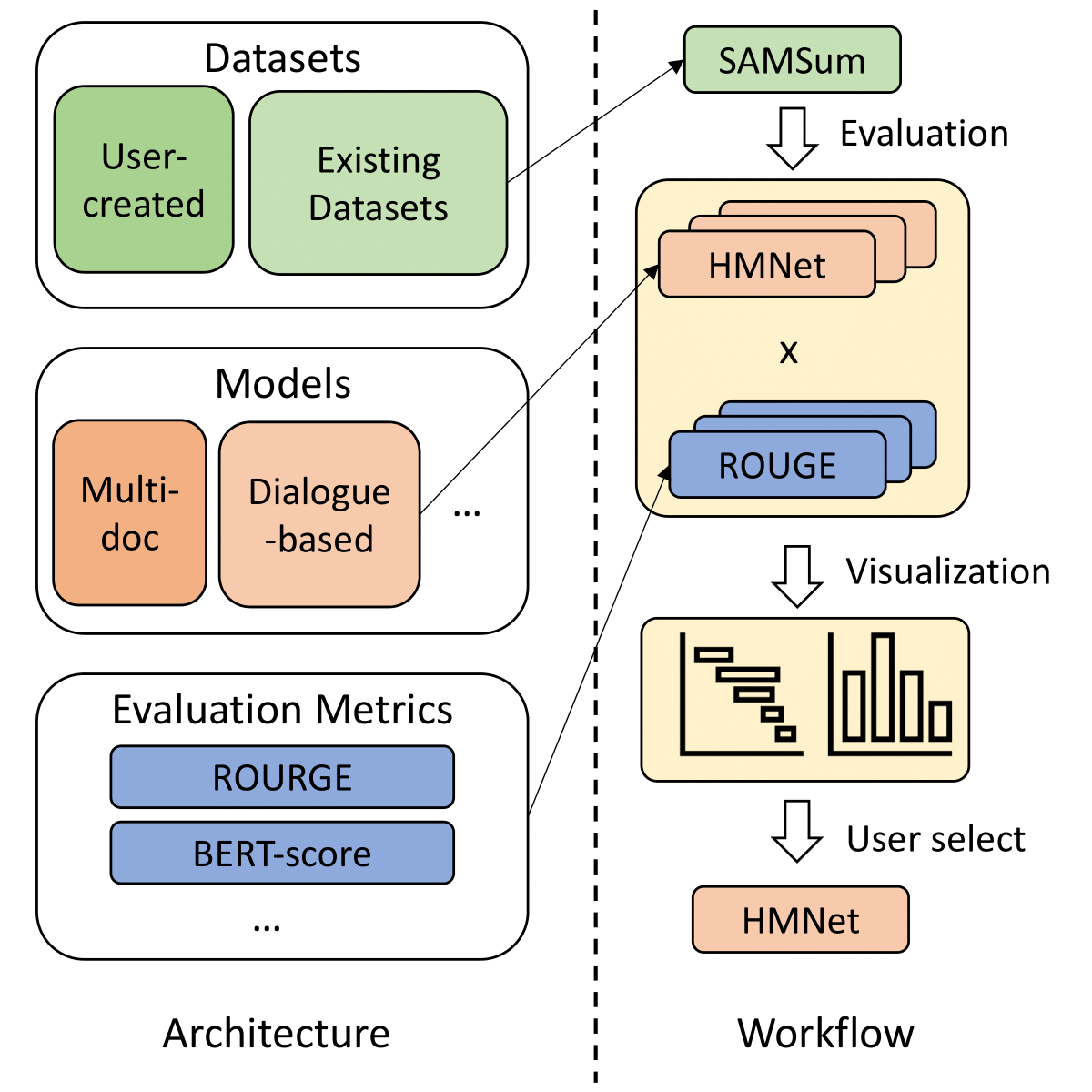
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023
一个多语言支持、易使用的 OCR 项目。An easy-to-use OCR project with multilingual support.
AgentOCR 简介 AgentOCR 是一个基于 PaddleOCR 和 ONNXRuntime 项目开发的一个使用简单、调用方便的 OCR 项目 本项目目前包含 Python Package 【AgentOCR】 和 OCR 标注软件 【AgentOCRLabeling】 使用指南 Pytho
 98 Nov 10, 2022
98 Nov 10, 2022

Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer Summary Explorer is a tool to visually inspect the summaries from several state-of-the-art neural summarization models across multipl
 42 Aug 14, 2022
42 Aug 14, 2022
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
Summary Explorer is a tool to visually explore the state-of-the-art in text summarization.
42 Aug 14, 2022
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022

Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021 The code for training mCOLT/mRASP2, a multilingua
 104 Jan 1, 2023
104 Jan 1, 2023

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022
Code for the paper "Balancing Training for Multilingual Neural Machine Translation, ACL 2020"
Balancing Training for Multilingual Neural Machine Translation Implementation of the paper Balancing Training for Multilingual Neural Machine Translat
 21 May 18, 2022
21 May 18, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
190 Jan 3, 2023
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023