1385 Repositories
Python text-to-audio Libraries

Database Reasoning Over Text project for ACL paper
Database Reasoning over Text This repository contains the code for the Database Reasoning Over Text paper, to appear at ACL2021. Work is performed in
 320 Dec 12, 2022
320 Dec 12, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
 47 Dec 18, 2022
47 Dec 18, 2022
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
Full-text multi-table search application for Django. Easy to install and use, with good performance.
django-watson django-watson is a fast multi-model full-text search plugin for Django. It is easy to install and use, and provides high quality search
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022
Export solved codewars kata challenges to a text file.
Codewars Kata Exporter Note:this is not totally my work.i've edited the project to make more easier and faster for me.you can find the original work h
 4 Aug 13, 2021
4 Aug 13, 2021

A demo for end-to-end English and Chinese text spotting using ABCNet.
ABCNet_Chinese A demo for end-to-end English and Chinese text spotting using ABCNet. This is an old model that was trained a long ago, which serves as
 45 Oct 4, 2022
45 Oct 4, 2022
Text-Based Ideal Points
Text-Based Ideal Points Source code for the paper: Text-Based Ideal Points by Keyon Vafa, Suresh Naidu, and David Blei (ACL 2020). Update (June 29, 20
 37 Oct 9, 2022
37 Oct 9, 2022

Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
Textual is a TUI (Text User Interface) framework for Python inspired by modern web development.
 17.1k Jan 8, 2023
17.1k Jan 8, 2023
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022
ThinkTwice: A Two-Stage Method for Long-Text Machine Reading Comprehension
ThinkTwice ThinkTwice is a retriever-reader architecture for solving long-text machine reading comprehension. It is based on the paper: ThinkTwice: A
 4 Aug 6, 2021
4 Aug 6, 2021
This app converts an pdf file into the audio file.
PDF-to-Audio This app takes an pdf as an input and convert it into audio, and the library text-to-speech starts speaking the preffered page given in t
 3 Aug 4, 2021
3 Aug 4, 2021
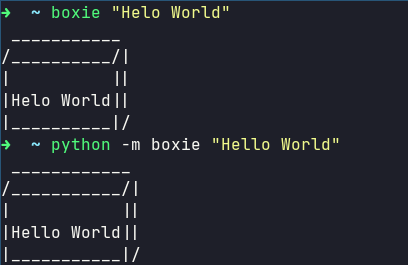
📦 A command line utility to put text in a box.
boxie A command line utility to put text in a box. Installation pip install boxie If you are on Linux you may need to use sudo to access this globally
 10 Jun 30, 2022
10 Jun 30, 2022

Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized
VQGAN-CLIP-Docker About Zero-Shot Text-to-Image Generation VQGAN+CLIP Dockerized This is a stripped and minimal dependency repository for running loca
 73 Sep 11, 2022
73 Sep 11, 2022
API for the GPT-J language model 🦜. Including a FastAPI backend and a streamlit frontend
gpt-j-api 🦜 An API to interact with the GPT-J language model. You can use and test the model in two different ways: Streamlit web app at http://api.v
 276 Dec 31, 2022
276 Dec 31, 2022

Google Project: Search and auto-complete sentences within given input text files, manipulating data with complex data-structures.
Auto-Complete Google Project In this project there is an implementation for one feature of Google's search engines - AutoComplete. Autocomplete, or wo
 10 Jun 20, 2022
10 Jun 20, 2022
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (WSDM'21)
Hierarchical Metadata-Aware Document Categorization under Weak Supervision This project provides a weakly supervised framework for hierarchical metada
 53 Sep 17, 2022
53 Sep 17, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

"Inductive Entity Representations from Text via Link Prediction" @ The Web Conference 2021
Inductive entity representations from text via link prediction This repository contains the code used for the experiments in the paper "Inductive enti
 45 Jan 9, 2023
45 Jan 9, 2023

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023

A python script to prefab your scripts/text files, and re create them with ease and not have to open your browser to copy code or write code yourself
Scriptfab - What is it? A python script to prefab your scripts/text files, and re create them with ease and not have to open your browser to copy code
 3 Jul 28, 2021
3 Jul 28, 2021

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 170 Jan 4, 2023
170 Jan 4, 2023

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Dec 30, 2022
1.8k Dec 30, 2022

This project is a re-implementation of MASTER: Multi-Aspect Non-local Network for Scene Text Recognition by MMOCR
This project is a re-implementation of MASTER: Multi-Aspect Non-local Network for Scene Text Recognition by MMOCR,which is an open-source toolbox based on PyTorch. The overall architecture will be shown below.
 82 Nov 17, 2022
82 Nov 17, 2022
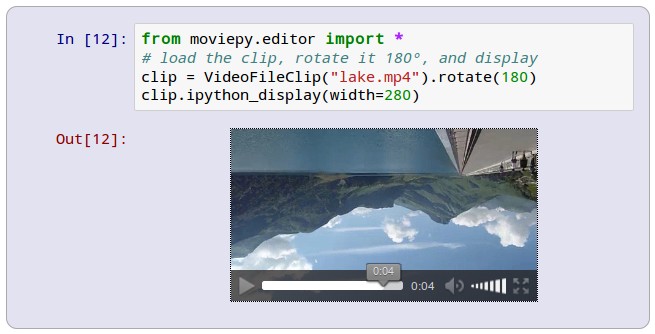
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023

T2F: text to face generation using Deep Learning
⭐ [NEW] ⭐ T2F - 2.0 Teaser (coming soon ...) Please note that all the faces in the above samples are generated ones. The T2F 2.0 will be using MSG-GAN
 533 Dec 22, 2022
533 Dec 22, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022
A Telegram Bot to Play Audio in Voice Chats With Youtube and Deezer support. Supports Live streaming from youtube Supports Mega Radio Fm Streamings
Bot To Stream Musics on PyTGcalls with Channel Support. A Telegram Bot to Play Audio in Voice Chats With Supports Live streaming from youtube and Mega
 37 Dec 15, 2022
37 Dec 15, 2022

Code for Text Prior Guided Scene Text Image Super-Resolution
Code for Text Prior Guided Scene Text Image Super-Resolution
 82 Dec 26, 2022
82 Dec 26, 2022

Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
 193 Dec 30, 2022
193 Dec 30, 2022

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
This is the official PyTorch implementation of the ALBEF paper [Blog]. This repository supports pre-training on custom datasets, as well as finetuning on VQA, SNLI-VE, NLVR2, Image-Text Retrieval on MSCOCO and Flickr30k, and visual grounding on RefCOCO+. Pre-trained and finetuned checkpoints are released.
 805 Jan 9, 2023
805 Jan 9, 2023

Code for the Interspeech 2021 paper "AST: Audio Spectrogram Transformer".
AST: Audio Spectrogram Transformer Introduction Citing Getting Started ESC-50 Recipe Speechcommands Recipe AudioSet Recipe Pretrained Models Contact I
 603 Jan 7, 2023
603 Jan 7, 2023
Global Rhythm Style Transfer Without Text Transcriptions
Global Prosody Style Transfer Without Text Transcriptions This repository provides a PyTorch implementation of AutoPST, which enables unsupervised glo
193 Dec 30, 2022
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022
efficient neural audio synthesis in the waveform domain
neural waveshaping synthesis real-time neural audio synthesis in the waveform domain paper • website • colab • audio by Ben Hayes, Charalampos Saitis,
 169 Dec 23, 2022
169 Dec 23, 2022

Unofficial Pytorch Implementation of WaveGrad2
WaveGrad 2 — Unofficial PyTorch Implementation WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis Unofficial PyTorch+Lightning Implementati
104 Nov 29, 2022
Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech"
GradTTS Unofficial Pytorch implementation of "Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech" (arxiv) About this repo This is an unoffic
 103 Dec 23, 2022
103 Dec 23, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 286 Jan 2, 2023
286 Jan 2, 2023
Telegram Radio - A User-bot who continuously play random audio files (from the famous telegram music channel @mveargasm) in the intended voice chat.
MvEargasmDJ: This is my submission for the Telegram Radio Project of Baivaru. Which required a userbot to continiously play random audio files from th
 24 Nov 12, 2022
24 Nov 12, 2022
Wrapper to display a script output or a text file content on the desktop in sway or other wlroots-based compositors
nwg-wrapper This program is a part of the nwg-shell project. This program is a GTK3-based wrapper to display a script output, or a text file content o
 94 Dec 27, 2022
94 Dec 27, 2022

NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling @ INTERSPEECH 2021 Accepted
NU-Wave — Official PyTorch Implementation NU-Wave: A Diffusion Probabilistic Model for Neural Audio Upsampling Junhyeok Lee, Seungu Han @ MINDsLab Inc
242 Dec 23, 2022

box is a text-based visual programming language inspired by Unreal Engine Blueprint function graphs.
Box is a text-based visual programming language inspired by Unreal Engine blueprint function graphs. $ cat factorial.box ┌─ƒ(Factorial)───┐
 104 Dec 24, 2022
104 Dec 24, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022

Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
 2.3k Jan 4, 2023
2.3k Jan 4, 2023

Command Line Text-To-Speech using Google TTS
cli-tts Thanks to gTTS by @pndurette! This is an interactive command line text-to-speech tool using Google TTS. Just type text and the voice will be p
 3 Nov 11, 2022
3 Nov 11, 2022

Classify bird species based on their songs using SIamese Networks and 1D dilated convolutions.
The goal is to classify different birds species based on their songs/calls. Spectrograms have been extracted from the audio samples and used as features for classification.
 9 Dec 27, 2022
9 Dec 27, 2022
A toolbox of scene text detection and recognition
FudanOCR This toolbox contains the implementations of the following papers: Scene Text Telescope: Text-Focused Scene Image Super-Resolution [Chen et a
 170 Dec 26, 2022
170 Dec 26, 2022
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022

BARTScore: Evaluating Generated Text as Text Generation
This is the Repo for the paper: BARTScore: Evaluating Generated Text as Text Generation Updates 2021.06.28 Release online evaluation Demo 2021.06.25 R
 196 Dec 17, 2022
196 Dec 17, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
63 Jan 2, 2023
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023

Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback
CoSMo.pytorch Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback, Seungmin Lee*, Dongwan Kim*, Bohyung
 54 Dec 8, 2022
54 Dec 8, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
Cross-Modal Contrastive Learning for Text-to-Image Generation
Cross-Modal Contrastive Learning for Text-to-Image Generation This repository hosts the open source JAX implementation of XMC-GAN. Setup instructions
94 Nov 12, 2022

Blender Python - Node-based multi-line text and image flowchart
MindMapper v0.8 Node-based text and image flowchart for Blender Mindmap with shortcuts visible: Mindmap with shortcuts hidden: Notes This was requeste
 58 Oct 8, 2022
58 Oct 8, 2022

This repository contains a PyTorch implementation of "AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis".
AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis | Project Page | Paper | PyTorch implementation for the paper "AD-NeRF: Audio
 551 Dec 29, 2022
551 Dec 29, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
Sublime Text 2/3 style auto completion for ST4
Hippie Autocompletion Sublime Text 2/3 style auto completion for ST4: cycle through words, do not show popup. Simply hit Tab to insert completion, hit
 20 May 19, 2022
20 May 19, 2022

Official Pytorch Implementation of: "Semantic Diversity Learning for Zero-Shot Multi-label Classification"(2021) paper
Semantic Diversity Learning for Zero-Shot Multi-label Classification Paper Official PyTorch Implementation Avi Ben-Cohen, Nadav Zamir, Emanuel Ben Bar
 28 Aug 29, 2022
28 Aug 29, 2022
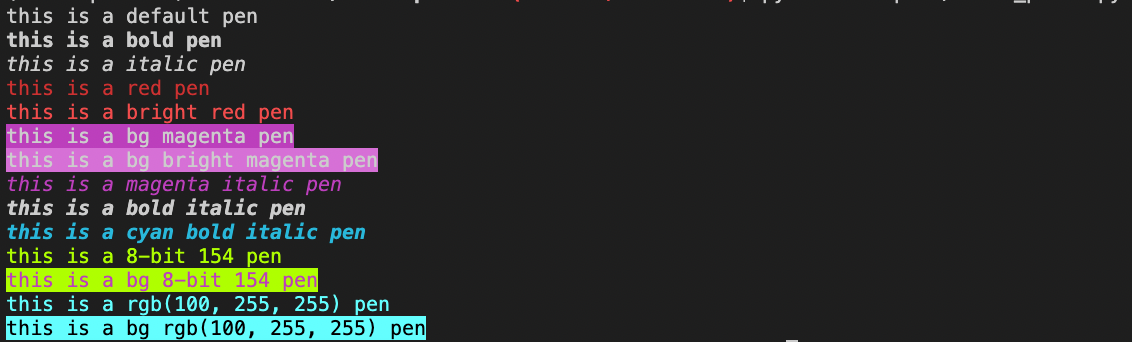
Print 'text color' and 'text format' on Term with Python
term-printer Print 'text color' and 'text format' on Term with Python ※ It may not work depending on the OS and shell used. PIP $ pip install term-pri
 10 Nov 12, 2022
10 Nov 12, 2022

Pytorch implementation for "Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter".
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter This is a pytorch-based implementation for paper Implicit Feature Alignme
 61 Nov 12, 2022
61 Nov 12, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 6, 2022
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption, CVPR 2021 (Oral)
TAP: Text-Aware Pre-training TAP: Text-Aware Pre-training for Text-VQA and Text-Caption by Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Flo
61 Nov 14, 2022

Unconstrained Text Detection with Box Supervisionand Dynamic Self-Training
SelfText Beyond Polygon: Unconstrained Text Detection with Box Supervisionand Dynamic Self-Training Introduction This is a PyTorch implementation of "
 34 Nov 9, 2022
34 Nov 9, 2022
Code for "Primitive Representation Learning for Scene Text Recognition" (CVPR 2021)
Primitive Representation Learning Network (PREN) This repository contains the code for our paper accepted by CVPR 2021 Primitive Representation Learni
 76 Jan 2, 2023
76 Jan 2, 2023
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
 5.6k Jan 3, 2023
5.6k Jan 3, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023
Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification"
PTR Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification" If you use the code, please cite the following paper: @art
 118 Dec 30, 2022
118 Dec 30, 2022
easySpeech is an open-source Python wrapper for google speech to text API that doesn't require PyAudio(So you especially windows user don't have to deal with the errors while installing PyAudio) and also works with hugging face transformers
easySpeech easySpeech is an open source python wrapper for google speech to text api that doesn't require PyAaudio(So you specially windows user don't
 14 May 24, 2022
14 May 24, 2022
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022
CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable.
CausalNLP CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable. Install pip install -U
 95 Jan 3, 2023
95 Jan 3, 2023
Easy-to-use CPM for Chinese text generation
CPM 项目描述 CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂
 382 Jan 7, 2023
382 Jan 7, 2023

My Sublime Text theme
rsms sublime text theme Install: cd path/to/your/sublime/packages git clone https://github.com/rsms/sublime-theme.git rsms-theme You'll also need the
 166 Jan 4, 2023
166 Jan 4, 2023