774 Repositories
Python video-annotation Libraries

The Original Snake Game. Maneuver a snake in its burrow and earn points while avoiding the snake itself and the walls of the snake burrow.
Maneuver a snake in its burrow and earn points while avoiding the snake itself and the walls of the snake burrow. The snake grows when it eats an apple by default which can be disabled in the settings tab where you can also find all the other customization options.
 17 Nov 12, 2022
17 Nov 12, 2022
RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation Ported from https://github.com/hzwer/arXiv2020-RIFE Dependencies NumPy
 49 Jan 7, 2023
49 Jan 7, 2023

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022
A command line tool to remove background from video and image
A command line tool to remove background from video and image, brought to you by BackgroundRemover.app which is an app made by nadermx powered by this tool
 1.7k Jan 1, 2023
1.7k Jan 1, 2023
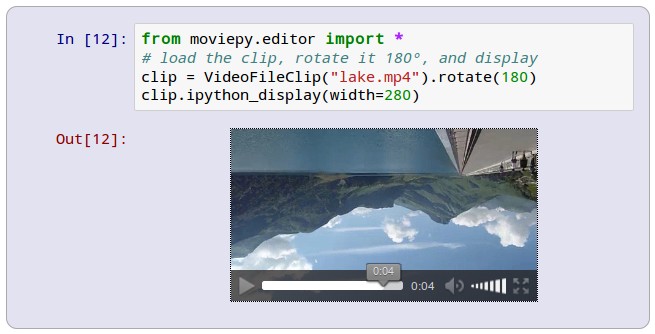
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023

Compressed Video Action Recognition
Compressed Video Action Recognition Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R. Manmatha, Alexander J. Smola, Philipp Krähenbühl. In CVPR, 2018. [Proj
 479 Dec 26, 2022
479 Dec 26, 2022
Send notification to your telegram group/channel/private whenever a new video is uploaded on a youtube channel!
YouTube Feeds Bot. Send notification to your telegram group/channel/private whenever a new video is uploaded on a youtube channel! Variables BOT_TOKEN
 30 Dec 7, 2022
30 Dec 7, 2022

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
 1.5k Jan 7, 2023
1.5k Jan 7, 2023

Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic video-to-video translation.
vid2vid Project | YouTube(short) | YouTube(full) | arXiv | Paper(full) Pytorch implementation for high-resolution (e.g., 2048x1024) photorealistic vid
 8.1k Jan 1, 2023
8.1k Jan 1, 2023

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
 248 Nov 21, 2022
248 Nov 21, 2022
Implementation of experiments in the paper Clockwork Variational Autoencoders (project website) using JAX and Flax
Clockwork VAEs in JAX/Flax Implementation of experiments in the paper Clockwork Variational Autoencoders (project website) using JAX and Flax, ported
 26 Oct 5, 2022
26 Oct 5, 2022

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval project page | arXiv | webvid-data Repository containing the code,
 225 Dec 25, 2022
225 Dec 25, 2022

Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference
RawVSR This repo contains the official codes for our paper: Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference Xiaoh
 23 Oct 8, 2022
23 Oct 8, 2022

ESTDepth: Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks (CVPR 2021)
ESTDepth: Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks (CVPR 2021) Project Page | Video | Paper | Data We present a novel metho
 65 Nov 28, 2022
65 Nov 28, 2022

PyTorch implementation of EGVSR: Efficcient & Generic Video Super-Resolution (VSR)
This is a PyTorch implementation of EGVSR: Efficcient & Generic Video Super-Resolution (VSR), using subpixel convolution to optimize the inference speed of TecoGAN VSR model. Please refer to the official implementation ESPCN and TecoGAN for more information.
 789 Jan 4, 2023
789 Jan 4, 2023
STEAL - Learning Semantic Boundaries from Noisy Annotations (CVPR 2019)
STEAL This is the official inference code for: Devil Is in the Edges: Learning Semantic Boundaries from Noisy Annotations David Acuna, Amlan Kar, Sanj
 469 Dec 26, 2022
469 Dec 26, 2022

Unsupervised Video Interpolation using Cycle Consistency
Unsupervised Video Interpolation using Cycle Consistency Project | Paper | YouTube Unsupervised Video Interpolation using Cycle Consistency Fitsum A.
100 Nov 30, 2022
Another Autoscaler is a Kubernetes controller that automatically starts, stops, or restarts pods from a deployment at a specified time using a cron annotation.
Another Autoscaler Another Autoscaler is a Kubernetes controller that automatically starts, stops, or restarts pods from a deployment at a specified t
 66 Nov 19, 2022
66 Nov 19, 2022

Gesture-controlled Video Game. Just swing your finger and play the game without touching your PC
Gesture Controlled Video Game Detailed Blog : https://www.analyticsvidhya.com/blog/2021/06/gesture-controlled-video-game/ Introduction This project is
 35 Jan 6, 2023
35 Jan 6, 2023

Real-time multi-object tracker using YOLO v5 and deep sort
This repository contains a two-stage-tracker. The detections generated by YOLOv5, a family of object detection architectures and models pretrained on the COCO dataset, are passed to a Deep Sort algorithm which tracks the objects. It can track any object that your Yolov5 model was trained to detect.
 3.6k Jan 5, 2023
3.6k Jan 5, 2023
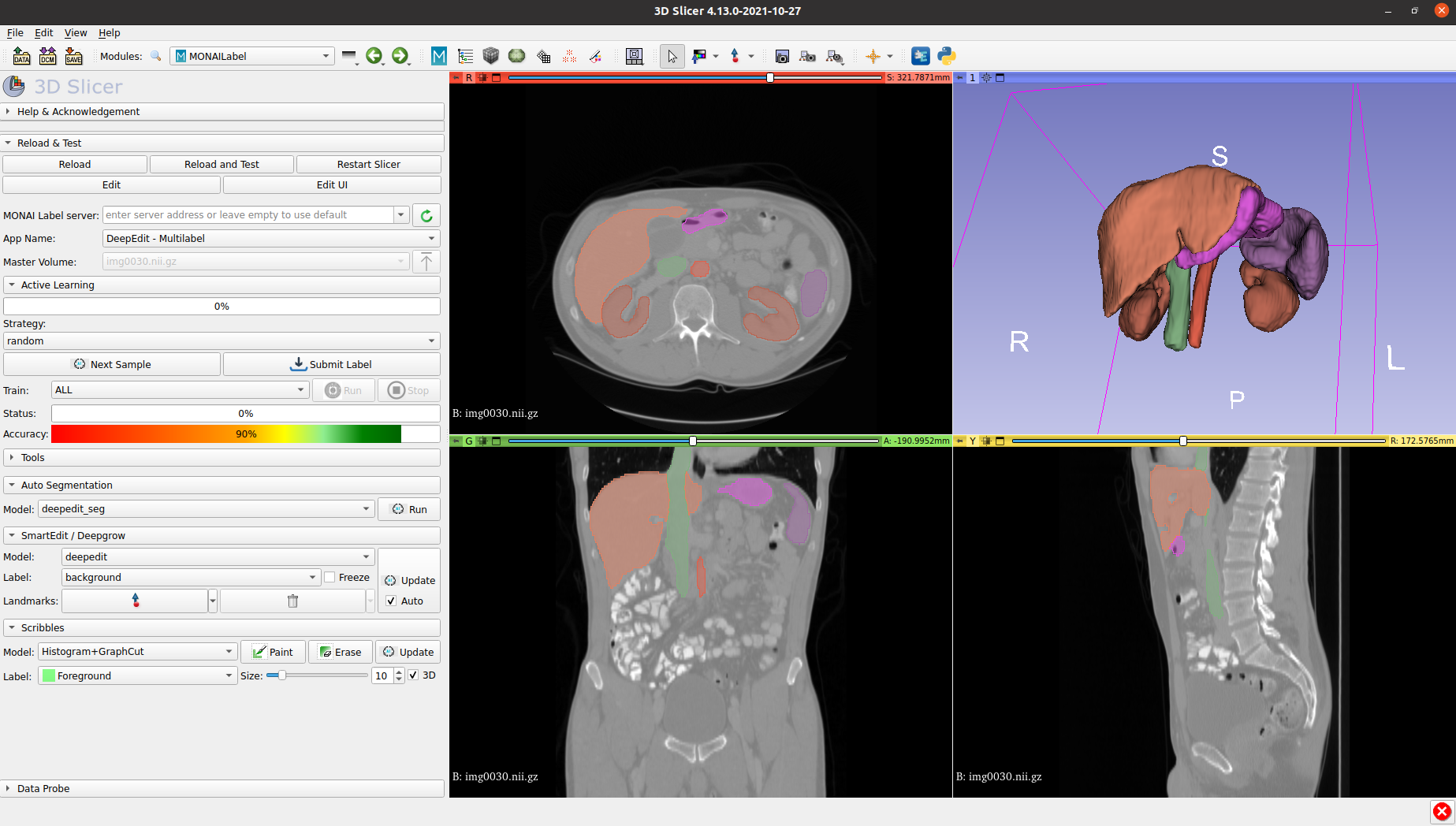
MONAI Label is a server-client system that facilitates interactive medical image annotation by using AI.
MONAI Label is a server-client system that facilitates interactive medical image annotation by using AI. It is an open-source and easy-to-install ecosystem that can run locally on a machine with one or two GPUs. Both server and client work on the same/different machine. However, initial support for multiple users is restricted. It shares the same principles with MONAI.
 344 Dec 23, 2022
344 Dec 23, 2022

2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation
2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation Authors: Ge-Peng Ji*, Yu-Cheng Chou*, Deng-Ping Fan, Geng Che
 85 Dec 30, 2022
85 Dec 30, 2022

iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis Andreas Bl
 36 Dec 25, 2022
36 Dec 25, 2022

A PyTorch Reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution
TecoGAN-PyTorch Introduction This is a PyTorch reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution (VSR). Please refer to
 165 Dec 17, 2022
165 Dec 17, 2022
Another Scheduler is a Kubernetes controller that automatically starts, stops, or restarts pods from a deployment at a specified time using a cron annotation.
Another Scheduler Another Scheduler is a Kubernetes controller that automatically starts, stops, or restarts pods from a deployment at a specified tim
66 Nov 19, 2022
Introduction to Django Rest Framework
Introduction to Django Rest Framework This is the repository of the video series Introduction to Django Rest Framework published on YouTube. It is a s
 20 Jul 14, 2022
20 Jul 14, 2022

Fix Twitter video embeds in Discord
TwitFix very basic flask server that fixes twitter embeds in discord by using youtube-dl to grab the direct link to the MP4 file and embeds the link t
 682 Dec 28, 2022
682 Dec 28, 2022
Code for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"
Triple-cooperative Video Shadow Detection Code and dataset for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"[arXiv link] [official l
 24 Oct 4, 2022
24 Oct 4, 2022
Codes for paper "Towards Diverse Paragraph Captioning for Untrimmed Videos". CVPR 2021
Towards Diverse Paragraph Captioning for Untrimmed Videos This repository contains PyTorch implementation of our paper Towards Diverse Paragraph Capti
 61 Oct 11, 2022
61 Oct 11, 2022
Robust Consistent Video Depth Estimation
[CVPR 2021] Robust Consistent Video Depth Estimation This repository contains Python and C++ implementation of Robust Consistent Video Depth, as descr
 213 Dec 17, 2022
213 Dec 17, 2022
convert a dict-list object from / to a typed object(class instance with type annotation)
objtyping 带类型定义的对象转换器 由来 Python不是强类型语言,开发人员没有给数据定义类型的习惯。这样虽然灵活,但处理复杂业务逻辑的时候却不够方便——缺乏类型检查可能导致很难发现错误,在IDE里编码时也没
 15 Dec 22, 2022
15 Dec 22, 2022
Implementation of FitVid video prediction model in JAX/Flax.
FitVid Video Prediction Model Implementation of FitVid video prediction model in JAX/Flax. If you find this code useful, please cite it in your paper:
 62 Nov 25, 2022
62 Nov 25, 2022
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player without incurring ingress/egree traffic on EC2 Instance.
 8 Mar 28, 2022
8 Mar 28, 2022
The repository for my video "Playing MINECRAFT with a WEBCAM"
This is the official repo for my video "Playing MINECRAFT with a WEBCAM" on YouTube Original video can be found here: https://youtu.be/701TPxL0Skg Red
 27 Jun 7, 2022
27 Jun 7, 2022

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023

Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
LASR Installation Build with conda conda env create -f lasr.yml conda activate lasr # install softras cd third_party/softras; python setup.py install;
 157 Dec 26, 2022
157 Dec 26, 2022
The implementation of CVPR2021 paper Temporal Query Networks for Fine-grained Video Understanding, by Chuhan Zhang, Ankush Gupta and Andrew Zisserman.
Temporal Query Networks for Fine-grained Video Understanding 📋 This repository contains the implementation of CVPR2021 paper Temporal_Query_Networks
 55 Dec 21, 2022
55 Dec 21, 2022

Towards Long-Form Video Understanding
Towards Long-Form Video Understanding Chao-Yuan Wu, Philipp Krähenbühl, CVPR 2021 [Paper] [Project Page] [Dataset] Citation @inproceedings{lvu2021,
69 Dec 26, 2022

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022
pygamevideo module helps developer to embed videos into their Pygame display
pygamevideo module helps developer to embed videos into their Pygame display. Audio playback doesn't use pygame.mixer.
 10 Dec 28, 2022
10 Dec 28, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

領域を指定し、キーを入力することで画像を保存するツールです。クラス分類用のデータセット作成を想定しています。
image-capture-class-annotation 領域を指定し、キーを入力することで画像を保存するツールです。 クラス分類用のデータセット作成を想定しています。 Requirement OpenCV 3.4.2 or later Usage 実行方法は以下です。 起動後はマウスクリック4
 5 May 28, 2021
5 May 28, 2021

CT-Net: Channel Tensorization Network for Video Classification
[ICLR2021] CT-Net: Channel Tensorization Network for Video Classification @inproceedings{ li2021ctnet, title={{\{}CT{\}}-Net: Channel Tensorization Ne
 33 Nov 15, 2022
33 Nov 15, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022
A Telegram Video Merge Bot by @AbirHasan2005
VideoMerge-Bot This is very simple Telegram Videos Merge Bot by @AbirHasan2005. Using FFmpeg for Merging Videos. Features: Merge Multiple Videos. User
 57 Nov 12, 2022
57 Nov 12, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022

A lightweight deep network for fast and accurate optical flow estimation.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation The official PyTorch implementation of FastFlowNet (ICRA 2021). Authors: Lingtong
 161 Jan 3, 2023
161 Jan 3, 2023
Towards End-to-end Video-based Eye Tracking
Towards End-to-end Video-based Eye Tracking The code accompanying our ECCV 2020 publication and dataset, EVE. Authors: Seonwook Park, Emre Aksan, Xuco
 76 Dec 12, 2022
76 Dec 12, 2022
A embed able annotation tool for end to end cross document co-reference
CoRefi CoRefi is an emebedable web component and stand alone suite for exaughstive Within Document and Cross Document Coreference Anntoation. For a de
 39 Dec 12, 2022
39 Dec 12, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file
Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file. VISD can also perform vehicle speed detection on a video. All these features of VSID are provided to the user using a Web Application which is created using Flask
 6 Feb 22, 2022
6 Feb 22, 2022

PointCloud Annotation Tools, support to label object bound box, ground, lane and kerb
PointCloud Annotation Tools, support to label object bound box, ground, lane and kerb
 368 Dec 6, 2022
368 Dec 6, 2022

Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
 15.3k Jan 5, 2023
15.3k Jan 5, 2023

Self-Learned Video Rain Streak Removal: When Cyclic Consistency Meets Temporal Correspondence
In this paper, we address the problem of rain streaks removal in video by developing a self-learned rain streak removal method, which does not require any clean groundtruth images in the training process.
 44 Dec 6, 2022
44 Dec 6, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022

Official implementation of the network presented in the paper "M4Depth: A motion-based approach for monocular depth estimation on video sequences"
M4Depth This is the reference TensorFlow implementation for training and testing depth estimation models using the method described in M4Depth: A moti
 76 Jan 3, 2023
76 Jan 3, 2023

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022

SiamMOT is a region-based Siamese Multi-Object Tracking network that detects and associates object instances simultaneously.
SiamMOT: Siamese Multi-Object Tracking
 432 Dec 17, 2022
432 Dec 17, 2022
Music and video downloader, Made with love by Bryan Herrera
Python-Mp3Mp4-Downloader Music and video downloader, Made with love by Bryan Herrera Requirements CHOCOLATELY windows command If your system does not
 104 Dec 27, 2022
104 Dec 27, 2022
Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification"
hypergraph_reid Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification" If you find this help your research,
 62 Dec 21, 2022
62 Dec 21, 2022
The implemention of Video Depth Estimation by Fusing Flow-to-Depth Proposals
Flow-to-depth (FDNet) video-depth-estimation This is the implementation of paper Video Depth Estimation by Fusing Flow-to-Depth Proposals Jiaxin Xie,
 32 Jun 14, 2022
32 Jun 14, 2022
A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
225 Dec 25, 2022

Code for ECCV 2020 paper "Contacts and Human Dynamics from Monocular Video".
Contact and Human Dynamics from Monocular Video This is the official implementation for the ECCV 2020 spotlight paper by Davis Rempe, Leonidas J. Guib
 207 Jan 5, 2023
207 Jan 5, 2023
Inference code for "StylePeople: A Generative Model of Fullbody Human Avatars" paper. This code is for the part of the paper describing video-based avatars.
NeuralTextures This is repository with inference code for paper "StylePeople: A Generative Model of Fullbody Human Avatars" (CVPR21). This code is for
 18 Oct 6, 2022
18 Oct 6, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 82 Jan 3, 2023
82 Jan 3, 2023
Deep learning (neural network) based remote photoplethysmography: how to extract pulse signal from video using deep learning tools
Deep-rPPG: Camera-based pulse estimation using deep learning tools Deep learning (neural network) based remote photoplethysmography: how to extract pu
 138 Dec 17, 2022
138 Dec 17, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
135 Dec 28, 2022
PRAnCER is a web platform that enables the rapid annotation of medical terms within clinical notes.
PRAnCER (Platform enabling Rapid Annotation for Clinical Entity Recognition) is a web platform that enables the rapid annotation of medical terms within clinical notes. A user can highlight spans of text and quickly map them to concepts in large vocabularies within a single, intuitive platform.
 39 Nov 14, 2022
39 Nov 14, 2022

Code for paper 'Audio-Driven Emotional Video Portraits'.
Audio-Driven Emotional Video Portraits [CVPR2021] Xinya Ji, Zhou Hang, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, Feng Xu [Project] [Paper] G
 197 Dec 31, 2022
197 Dec 31, 2022

QueryInst: Parallelly Supervised Mask Query for Instance Segmentation
QueryInst is a simple and effective query based instance segmentation method driven by parallel supervision on dynamic mask heads, which outperforms previous arts in terms of both accuracy and speed.
 386 Jan 8, 2023
386 Jan 8, 2023

Code for "ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on", accepted at WACV 2021 Generation of Human Behavior Workshop.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on [ Paper ] [ Project Page ] This repository contains the code fo
 97 Dec 13, 2022
97 Dec 13, 2022
![[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior](https://github.com/yzxing87/pytorch-deep-video-prior/raw/main/example/example_in.gif)
[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior
pytorch-deep-video-prior (DVP) Official PyTorch implementation for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior TensorFlo
 90 Oct 19, 2022
90 Oct 19, 2022
Awesome Video Datasets
Awesome Video Datasets
 462 Jan 2, 2023
462 Jan 2, 2023
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
17k Jan 1, 2023
API spec validator and OpenAPI document generator for Python web frameworks.
API spec validator and OpenAPI document generator for Python web frameworks.
 249 Dec 22, 2022
249 Dec 22, 2022

Official implementation of "Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets" (CVPR2021)
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets This is the official implementation of "Towards Good Pract
 52 Nov 22, 2022
52 Nov 22, 2022

A simple image/video to Desmos graph converter run locally
Desmos Bezier Renderer A simple image/video to Desmos graph converter run locally Sample Result Setup Install dependencies apt update apt install git
 339 Dec 23, 2022
339 Dec 23, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
33 Nov 21, 2022
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022
[CVPR 2021] MiVOS - Mask Propagation module. Reproduced STM (and better) with training code :star2:. Semi-supervised video object segmentation evaluation.
MiVOS (CVPR 2021) - Mask Propagation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [arXiv] [Paper PDF] [Project Page] [Papers with Code] This repo impleme
106 Jan 3, 2023

Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021
TCMR: Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video Qualtitative result Paper teaser video Introduction This r
 215 Jan 6, 2023
215 Jan 6, 2023
Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021, Pytorch)
S2VD Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021) Requirements and Dependencies Ubuntu 16.04, cuda 10.0 Python 3.6.10, P
 53 Nov 23, 2022
53 Nov 23, 2022
This is a simple collection of instructions and scripts to accompany the computerphile video about mininet and openflow.
How to get going. This project should work on Linux or MacOS. I used Ubuntu 20.04 and provide some notes here. Note, this is certainly not intended as
 70 Jan 2, 2023
70 Jan 2, 2023

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023
[TIP2020] Adaptive Graph Representation Learning for Video Person Re-identification
Introduction This is the PyTorch implementation for Adaptive Graph Representation Learning for Video Person Re-identification. Get started git clone h
 41 Dec 12, 2022
41 Dec 12, 2022
The official pytorch implemention of the CVPR paper "Temporal Modulation Network for Controllable Space-Time Video Super-Resolution".
This is the official PyTorch implementation of TMNet in the CVPR 2021 paper "Temporal Modulation Network for Controllable Space-Time VideoSuper-Resolu
 95 Oct 24, 2022
95 Oct 24, 2022

Training code of Spatial Time Memory Network. Semi-supervised video object segmentation.
Training-code-of-STM This repository fully reproduces Space-Time Memory Networks Performance on Davis17 val set&Weights backbone training stage traini
 128 Dec 11, 2022
128 Dec 11, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
Syntax-Aware Action Targeting for Video Captioning
Syntax-Aware Action Targeting for Video Captioning Code for SAAT from "Syntax-Aware Action Targeting for Video Captioning" (Accepted to CVPR 2020). Th
 59 Oct 13, 2022
59 Oct 13, 2022

TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks [Paper] [Project Website] This repository holds the source code, pretra
 83 Dec 21, 2022
83 Dec 21, 2022

VideoGPT: Video Generation using VQ-VAE and Transformers
VideoGPT: Video Generation using VQ-VAE and Transformers [Paper][Website][Colab][Gradio Demo] We present VideoGPT: a conceptually simple architecture
 470 Dec 30, 2022
470 Dec 30, 2022

It is a simple python package to play videos in the terminal using characters as pixels
It is a simple python package to play videos in the terminal using characters as pixels
 1.4k Jan 7, 2023
1.4k Jan 7, 2023