1515 Repositories
Python video-segmentation Libraries

PyTorch implementation of paper: HPNet: Deep Primitive Segmentation Using Hybrid Representations.
HPNet This repository contains the PyTorch implementation of paper: HPNet: Deep Primitive Segmentation Using Hybrid Representations. Installation The
 42 Dec 7, 2022
42 Dec 7, 2022
Per-Pixel Classification is Not All You Need for Semantic Segmentation
MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation Bowen Cheng, Alexander G. Schwing, Alexander Kirillov [arXiv] [Proj
 1k Jan 8, 2023
1k Jan 8, 2023

ESTDepth: Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks (CVPR 2021)
ESTDepth: Multi-view Depth Estimation using Epipolar Spatio-Temporal Networks (CVPR 2021) Project Page | Video | Paper | Data We present a novel metho
 65 Nov 28, 2022
65 Nov 28, 2022

A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
 75 Dec 26, 2022
75 Dec 26, 2022

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021

1st place solution to the Satellite Image Change Detection Challenge hosted by SenseTime
1st place solution to the Satellite Image Change Detection Challenge hosted by SenseTime
 209 Jan 1, 2023
209 Jan 1, 2023

PyTorch implementation of EGVSR: Efficcient & Generic Video Super-Resolution (VSR)
This is a PyTorch implementation of EGVSR: Efficcient & Generic Video Super-Resolution (VSR), using subpixel convolution to optimize the inference speed of TecoGAN VSR model. Please refer to the official implementation ESPCN and TecoGAN for more information.
 789 Jan 4, 2023
789 Jan 4, 2023

U-Net implementation in PyTorch for FLAIR abnormality segmentation in brain MRI
U-Net for brain segmentation U-Net implementation in PyTorch for FLAIR abnormality segmentation in brain MRI based on a deep learning segmentation alg
 562 Jan 2, 2023
562 Jan 2, 2023
STEAL - Learning Semantic Boundaries from Noisy Annotations (CVPR 2019)
STEAL This is the official inference code for: Devil Is in the Edges: Learning Semantic Boundaries from Noisy Annotations David Acuna, Amlan Kar, Sanj
 469 Dec 26, 2022
469 Dec 26, 2022
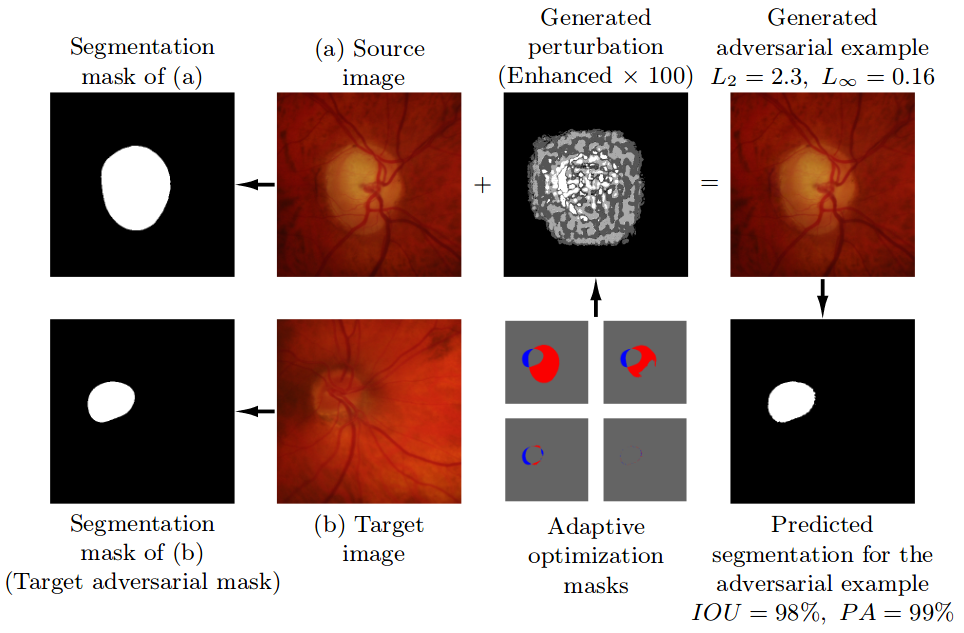
Pre-trained model, code, and materials from the paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation" (MICCAI 2019).
Adaptive Segmentation Mask Attack This repository contains the implementation of the Adaptive Segmentation Mask Attack (ASMA), a targeted adversarial
 53 Jul 4, 2022
53 Jul 4, 2022

Unsupervised Video Interpolation using Cycle Consistency
Unsupervised Video Interpolation using Cycle Consistency Project | Paper | YouTube Unsupervised Video Interpolation using Cycle Consistency Fitsum A.
 100 Nov 30, 2022
100 Nov 30, 2022

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023
Kaggle | 9th place single model solution for TGS Salt Identification Challenge
UNet for segmenting salt deposits from seismic images with PyTorch. General We, tugstugi and xuyuan, have participated in the Kaggle competition TGS S
 276 Dec 20, 2022
276 Dec 20, 2022

The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

Official PyTorch implementation of UACANet: Uncertainty Aware Context Attention for Polyp Segmentation
UACANet: Uncertainty Aware Context Attention for Polyp Segmentation Official pytorch implementation of UACANet: Uncertainty Aware Context Attention fo
 85 Dec 14, 2022
85 Dec 14, 2022

Gesture-controlled Video Game. Just swing your finger and play the game without touching your PC
Gesture Controlled Video Game Detailed Blog : https://www.analyticsvidhya.com/blog/2021/06/gesture-controlled-video-game/ Introduction This project is
 35 Jan 6, 2023
35 Jan 6, 2023

Real-time multi-object tracker using YOLO v5 and deep sort
This repository contains a two-stage-tracker. The detections generated by YOLOv5, a family of object detection architectures and models pretrained on the COCO dataset, are passed to a Deep Sort algorithm which tracks the objects. It can track any object that your Yolov5 model was trained to detect.
 3.6k Jan 5, 2023
3.6k Jan 5, 2023

This is the unofficial code of Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes. which achieve state-of-the-art trade-off between accuracy and speed on cityscapes and camvid, without using inference acceleration and extra data
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes Introduction This is the unofficial code of Deep Dual-re
 113 Dec 23, 2022
113 Dec 23, 2022

2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation
2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation Authors: Ge-Peng Ji*, Yu-Cheng Chou*, Deng-Ping Fan, Geng Che
 85 Dec 30, 2022
85 Dec 30, 2022
Code for 'Self-Guided and Cross-Guided Learning for Few-shot segmentation. (CVPR' 2021)'
SCL Introduction Code for 'Self-Guided and Cross-Guided Learning for Few-shot segmentation. (CVPR' 2021)' We evaluated our approach using two baseline
 34 Oct 8, 2022
34 Oct 8, 2022

iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis
iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis Andreas Bl
 36 Dec 25, 2022
36 Dec 25, 2022

A PyTorch Reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution
TecoGAN-PyTorch Introduction This is a PyTorch reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution (VSR). Please refer to
 165 Dec 17, 2022
165 Dec 17, 2022

Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion (CVPR 2021)
Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion (CVPR 2021) This repository is for BAAF-Net introduce
 90 Dec 29, 2022
90 Dec 29, 2022

joint detection and semantic segmentation, based on ultralytics/yolov5,
Multi YOLO V5——Detection and Semantic Segmentation Overeview This is my undergraduate graduation project which based on ultralytics YOLO V5 tag v5.0.
 477 Jan 6, 2023
477 Jan 6, 2023
Introduction to Django Rest Framework
Introduction to Django Rest Framework This is the repository of the video series Introduction to Django Rest Framework published on YouTube. It is a s
 20 Jul 14, 2022
20 Jul 14, 2022

Fix Twitter video embeds in Discord
TwitFix very basic flask server that fixes twitter embeds in discord by using youtube-dl to grab the direct link to the MP4 file and embeds the link t
 682 Dec 28, 2022
682 Dec 28, 2022
Code for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"
Triple-cooperative Video Shadow Detection Code and dataset for the CVPR 2021 paper "Triple-cooperative Video Shadow Detection"[arXiv link] [official l
 24 Oct 4, 2022
24 Oct 4, 2022

Code implementation of Data Efficient Stagewise Knowledge Distillation paper.
Data Efficient Stagewise Knowledge Distillation Table of Contents Data Efficient Stagewise Knowledge Distillation Table of Contents Requirements Image
 112 Dec 2, 2022
112 Dec 2, 2022

clDice - a Novel Topology-Preserving Loss Function for Tubular Structure Segmentation
README clDice - a Novel Topology-Preserving Loss Function for Tubular Structure Segmentation CVPR 2021 Authors: Suprosanna Shit and Johannes C. Paetzo
 110 Dec 29, 2022
110 Dec 29, 2022

Point Cloud Denoising input segmentation output raw point-cloud valid/clear fog rain de-noised Abstract Lidar sensors are frequently used in environme
Point Cloud Denoising input segmentation output raw point-cloud valid/clear fog rain de-noised Abstract Lidar sensors are frequently used in environme
 75 Nov 24, 2022
75 Nov 24, 2022
Codes for paper "Towards Diverse Paragraph Captioning for Untrimmed Videos". CVPR 2021
Towards Diverse Paragraph Captioning for Untrimmed Videos This repository contains PyTorch implementation of our paper Towards Diverse Paragraph Capti
 61 Oct 11, 2022
61 Oct 11, 2022
Robust Consistent Video Depth Estimation
[CVPR 2021] Robust Consistent Video Depth Estimation This repository contains Python and C++ implementation of Robust Consistent Video Depth, as descr
213 Dec 17, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Generic Event Boundary Detection: A Benchmark for Event Segmentation We release our data annotation & baseline codes for detecting generic event bound
 47 Nov 22, 2022
47 Nov 22, 2022
Complete U-net Implementation with keras
U Net Lowered with Keras Complete U-net Implementation with keras Original Paper Link : https://arxiv.org/abs/1505.04597 Special Implementations : The
 14 Oct 10, 2022
14 Oct 10, 2022
The codes for the work "Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation"
Swin-Unet The codes for the work "Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation"(https://arxiv.org/abs/2105.05537). A validatio
 869 Jan 7, 2023
869 Jan 7, 2023

This repo is a PyTorch implementation for Paper "Unsupervised Learning for Cuboid Shape Abstraction via Joint Segmentation from Point Clouds"
Unsupervised Learning for Cuboid Shape Abstraction via Joint Segmentation from Point Clouds This repository is a PyTorch implementation for paper: Uns
 42 Dec 9, 2022
42 Dec 9, 2022
Implementation of FitVid video prediction model in JAX/Flax.
FitVid Video Prediction Model Implementation of FitVid video prediction model in JAX/Flax. If you find this code useful, please cite it in your paper:
 62 Nov 25, 2022
62 Nov 25, 2022

(CVPR2021) DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation
DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation CVPR2021(oral) [arxiv] Requirements python3.7 pytorch==
 85 Dec 7, 2022
85 Dec 7, 2022
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player
Playing videos through S3 buckets (Wasabi, AWS, etc.) through client-side VideoJS player without incurring ingress/egree traffic on EC2 Instance.
 8 Mar 28, 2022
8 Mar 28, 2022
The repository for my video "Playing MINECRAFT with a WEBCAM"
This is the official repo for my video "Playing MINECRAFT with a WEBCAM" on YouTube Original video can be found here: https://youtu.be/701TPxL0Skg Red
 27 Jun 7, 2022
27 Jun 7, 2022

BRepNet: A topological message passing system for solid models
BRepNet: A topological message passing system for solid models This repository contains the an implementation of BRepNet: A topological message passin
 42 Dec 30, 2022
42 Dec 30, 2022
![Robust Instance Segmentation through Reasoning about Multi-Object Occlusion [CVPR 2021]](https://github.com/XD7479/Multi-Object-Occlusion/raw/main/images/figure_1.jpg)
Robust Instance Segmentation through Reasoning about Multi-Object Occlusion [CVPR 2021]
Robust Instance Segmentation through Reasoning about Multi-Object Occlusion [CVPR 2021] Abstract Analyzing complex scenes with DNN is a challenging ta
 24 Jun 27, 2022
24 Jun 27, 2022

PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in clustering (CVPR2021)
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering Jang Hyun Cho1, Utkarsh Mall2, Kavita Bala2, Bharath Harihar
 164 Dec 30, 2022
164 Dec 30, 2022

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023
Code for the paper One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation, CVPR 2021.
One Thing One Click One Thing One Click: A Self-Training Approach for Weakly Supervised 3D Semantic Segmentation (CVPR2021) Code for the paper One Thi
 44 Dec 12, 2022
44 Dec 12, 2022

Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
LASR Installation Build with conda conda env create -f lasr.yml conda activate lasr # install softras cd third_party/softras; python setup.py install;
 157 Dec 26, 2022
157 Dec 26, 2022
The implementation of CVPR2021 paper Temporal Query Networks for Fine-grained Video Understanding, by Chuhan Zhang, Ankush Gupta and Andrew Zisserman.
Temporal Query Networks for Fine-grained Video Understanding 📋 This repository contains the implementation of CVPR2021 paper Temporal_Query_Networks
 55 Dec 21, 2022
55 Dec 21, 2022

Towards Long-Form Video Understanding
Towards Long-Form Video Understanding Chao-Yuan Wu, Philipp Krähenbühl, CVPR 2021 [Paper] [Project Page] [Dataset] Citation @inproceedings{lvu2021,
 69 Dec 26, 2022
69 Dec 26, 2022

OrienMask: Real-time Instance Segmentation with Discriminative Orientation Maps
OrienMask This repository implements the framework OrienMask for real-time instance segmentation. It achieves 34.8 mask AP on COCO test-dev at the spe
 45 Dec 13, 2022
45 Dec 13, 2022

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022
pygamevideo module helps developer to embed videos into their Pygame display
pygamevideo module helps developer to embed videos into their Pygame display. Audio playback doesn't use pygame.mixer.
 10 Dec 28, 2022
10 Dec 28, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

Segmentation and Identification of Vertebrae in CT Scans using CNN, k-means Clustering and k-NN
Segmentation and Identification of Vertebrae in CT Scans using CNN, k-means Clustering and k-NN If you use this code for your research, please cite ou
 41 Dec 8, 2022
41 Dec 8, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021

This repository contains the code for our fast polygonal building extraction from overhead images pipeline.
Polygonal Building Segmentation by Frame Field Learning We add a frame field output to an image segmentation neural network to improve segmentation qu
 186 Jan 4, 2023
186 Jan 4, 2023
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

CT-Net: Channel Tensorization Network for Video Classification
[ICLR2021] CT-Net: Channel Tensorization Network for Video Classification @inproceedings{ li2021ctnet, title={{\{}CT{\}}-Net: Channel Tensorization Ne
 33 Nov 15, 2022
33 Nov 15, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
 72 Dec 19, 2022
72 Dec 19, 2022

Code for Towards Streaming Perception (ECCV 2020) :car:
sAP — Code for Towards Streaming Perception ECCV Best Paper Honorable Mention Award Feb 2021: Announcing the Streaming Perception Challenge (CVPR 2021
 85 Dec 22, 2022
85 Dec 22, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022

Official implementation of "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers"
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers Figure 1: Performance of SegFormer-B0 to SegFormer-B5. Project page
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
A Telegram Video Merge Bot by @AbirHasan2005
VideoMerge-Bot This is very simple Telegram Videos Merge Bot by @AbirHasan2005. Using FFmpeg for Merging Videos. Features: Merge Multiple Videos. User
 57 Nov 12, 2022
57 Nov 12, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022
FANet - Real-time Semantic Segmentation with Fast Attention
FANet Real-time Semantic Segmentation with Fast Attention Ping Hu, Federico Perazzi, Fabian Caba Heilbron, Oliver Wang, Zhe Lin, Kate Saenko , Stan Sc
 42 Nov 30, 2022
42 Nov 30, 2022
Code for weakly supervised segmentation of a single class
SingleClassRL Implementation of weak single object segmentation from paper "Regularized Loss for Weakly Supervised Single Class Semantic Segmentation"
 16 Nov 14, 2022
16 Nov 14, 2022

A lightweight deep network for fast and accurate optical flow estimation.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation The official PyTorch implementation of FastFlowNet (ICRA 2021). Authors: Lingtong
 161 Jan 3, 2023
161 Jan 3, 2023

Adaptive Prototype Learning and Allocation for Few-Shot Segmentation (CVPR 2021)
ASGNet The code is for the paper "Adaptive Prototype Learning and Allocation for Few-Shot Segmentation" (accepted to CVPR 2021) [arxiv] Overview data/
 91 Dec 23, 2022
91 Dec 23, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023
Towards End-to-end Video-based Eye Tracking
Towards End-to-end Video-based Eye Tracking The code accompanying our ECCV 2020 publication and dataset, EVE. Authors: Seonwook Park, Emre Aksan, Xuco
 76 Dec 12, 2022
76 Dec 12, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file
Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file. VISD can also perform vehicle speed detection on a video. All these features of VSID are provided to the user using a Web Application which is created using Flask
 6 Feb 22, 2022
6 Feb 22, 2022

"SOLQ: Segmenting Objects by Learning Queries", SOLQ is an end-to-end instance segmentation framework with Transformer.
SOLQ: Segmenting Objects by Learning Queries This repository is an official implementation of the paper SOLQ: Segmenting Objects by Learning Queries.
 179 Jan 2, 2023
179 Jan 2, 2023

This is the official Pytorch implementation of "Lung Segmentation from Chest X-rays using Variational Data Imputation", Raghavendra Selvan et al. 2020
README This is the official Pytorch implementation of "Lung Segmentation from Chest X-rays using Variational Data Imputation", Raghavendra Selvan et a
 42 Dec 15, 2022
42 Dec 15, 2022

The implementation of PEMP in paper "Prior-Enhanced Few-Shot Segmentation with Meta-Prototypes"
Prior-Enhanced network with Meta-Prototypes (PEMP) This is the PyTorch implementation of PEMP. Overview of PEMP Meta-Prototypes & Adaptive Prototypes
 8 Oct 14, 2021
8 Oct 14, 2021
![[CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision](https://github.com/charlesCXK/TorchSemiSeg/raw/main/ReadmePic/cps.png)
[CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
TorchSemiSeg [CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision by Xiaokang Chen1, Yuhui Yuan2, Gang Zeng1, Jingdong Wang
 387 Jan 8, 2023
387 Jan 8, 2023

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022

PyTorch implementation of: Michieli U. and Zanuttigh P., "Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations", CVPR 2021.
Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations This is the official PyTorch implementation
 42 Nov 9, 2022
42 Nov 9, 2022

Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
 15.3k Jan 5, 2023
15.3k Jan 5, 2023
A PyTorch implementation of EfficientDet.
A PyTorch impl of EfficientDet faithful to the original Google impl w/ ported weights
 1.4k Jan 7, 2023
1.4k Jan 7, 2023

Self-Learned Video Rain Streak Removal: When Cyclic Consistency Meets Temporal Correspondence
In this paper, we address the problem of rain streaks removal in video by developing a self-learned rain streak removal method, which does not require any clean groundtruth images in the training process.
 44 Dec 6, 2022
44 Dec 6, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

(AAAI2020)Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing
Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing This repository contains pytorch source code for AAAI2020 oral paper: Grapy-ML
 54 Aug 4, 2022
54 Aug 4, 2022
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022

Official implementation of the network presented in the paper "M4Depth: A motion-based approach for monocular depth estimation on video sequences"
M4Depth This is the reference TensorFlow implementation for training and testing depth estimation models using the method described in M4Depth: A moti
 76 Jan 3, 2023
76 Jan 3, 2023
Medical Image Segmentation using Squeeze-and-Expansion Transformers
Medical Image Segmentation using Squeeze-and-Expansion Transformers Introduction This repository contains the code of the IJCAI'2021 paper 'Medical Im
 172 Dec 20, 2022
172 Dec 20, 2022

Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving
SalsaNext: Fast, Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving Abstract In this paper, we introduce SalsaNext f
 308 Jan 4, 2023
308 Jan 4, 2023

Pytorch codes for "Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation"
Self-Supervised-MVS This repository is the official PyTorch implementation of our AAAI 2021 paper: "Self-supervised Multi-view Stereo via Effective Co
 127 Jan 4, 2023
127 Jan 4, 2023

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022

code for `Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation`
Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation (CVPR 2021) Introduction PBR is a conceptually simple yet effective
 143 Jan 5, 2023
143 Jan 5, 2023

SiamMOT is a region-based Siamese Multi-Object Tracking network that detects and associates object instances simultaneously.
SiamMOT: Siamese Multi-Object Tracking
 432 Dec 17, 2022
432 Dec 17, 2022
Music and video downloader, Made with love by Bryan Herrera
Python-Mp3Mp4-Downloader Music and video downloader, Made with love by Bryan Herrera Requirements CHOCOLATELY windows command If your system does not
 104 Dec 27, 2022
104 Dec 27, 2022

precise iris segmentation
PI-DECODER Introduction PI-DECODER, a decoder structure designed for Precise Iris Segmentation and Location. The decoder structure is shown below: Ple
 8 Aug 8, 2022
8 Aug 8, 2022
Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification"
hypergraph_reid Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification" If you find this help your research,
 62 Dec 21, 2022
62 Dec 21, 2022
The implemention of Video Depth Estimation by Fusing Flow-to-Depth Proposals
Flow-to-depth (FDNet) video-depth-estimation This is the implementation of paper Video Depth Estimation by Fusing Flow-to-Depth Proposals Jiaxin Xie,
 32 Jun 14, 2022
32 Jun 14, 2022