2415 Repositories
Python Image-Fusion-Transformer Libraries

CoReNet is a technique for joint multi-object 3D reconstruction from a single RGB image.
CoReNet CoReNet is a technique for joint multi-object 3D reconstruction from a single RGB image. It produces coherent reconstructions, where all objec
 80 Dec 25, 2022
80 Dec 25, 2022
《Deep Single Portrait Image Relighting》(ICCV 2019)
Ratio Image Based Rendering for Deep Single-Image Portrait Relighting [Project Page] This is part of the Deep Portrait Relighting project. If you find
 62 Dec 21, 2022
62 Dec 21, 2022

AOT-GAN for High-Resolution Image Inpainting (codebase for image inpainting)
AOT-GAN for High-Resolution Image Inpainting Arxiv Paper | AOT-GAN: Aggregated Contextual Transformations for High-Resolution Image Inpainting Yanhong
 214 Jan 3, 2023
214 Jan 3, 2023
Code for the Convolutional Vision Transformer (ConViT)
ConViT : Vision Transformers with Convolutional Inductive Biases This repository contains PyTorch code for ConViT. It builds on code from the Data-Eff
 418 Jan 6, 2023
418 Jan 6, 2023

StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation Demo video: CVPR 2021 Oral: Single Channel Manipulation: Localized or attribu
 267 Dec 30, 2022
267 Dec 30, 2022

Transformer related optimization, including BERT, GPT
This repository provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
 1.7k Jan 4, 2023
1.7k Jan 4, 2023
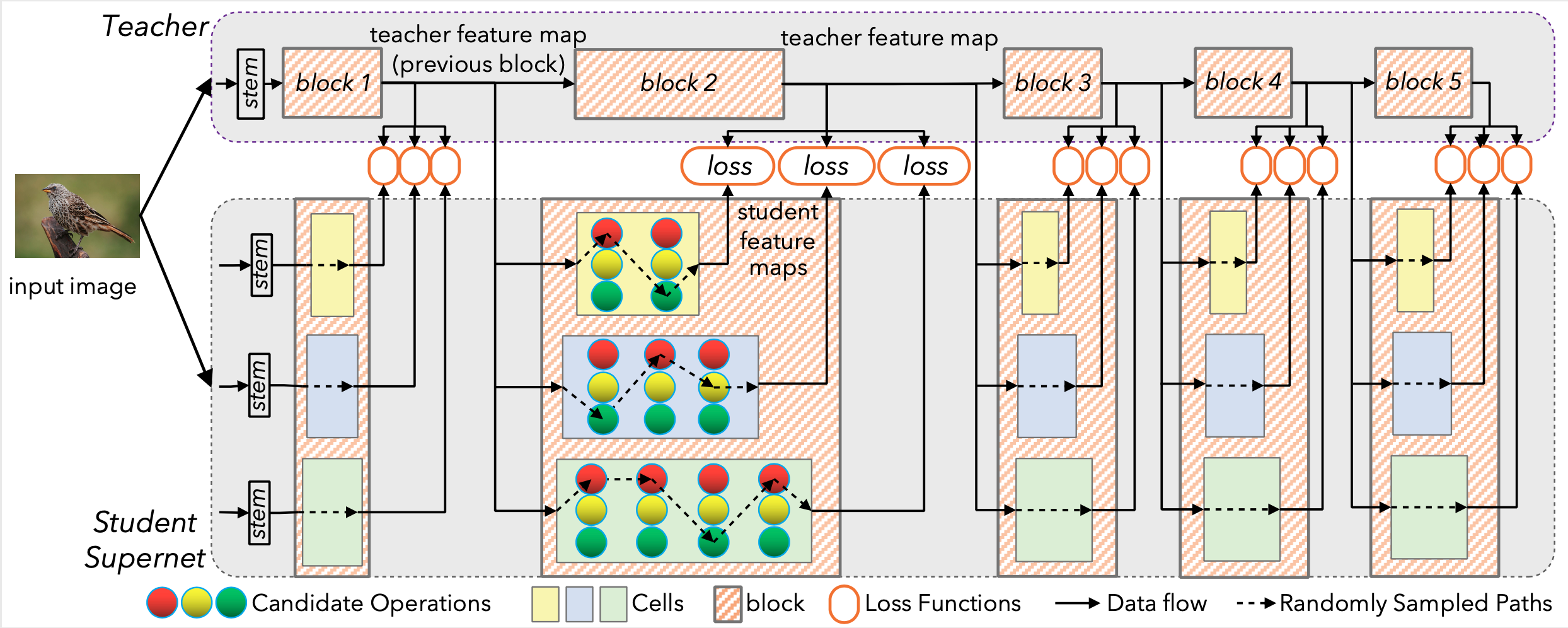
Block-wisely Supervised Neural Architecture Search with Knowledge Distillation (CVPR 2020)
DNA This repository provides the code of our paper: Blockwisely Supervised Neural Architecture Search with Knowledge Distillation. Illustration of DNA
 215 Dec 19, 2022
215 Dec 19, 2022
TRIQ implementation
TRIQ Implementation TF-Keras implementation of TRIQ as described in Transformer for Image Quality Assessment. Installation Clone this repository. Inst
 115 Dec 30, 2022
115 Dec 30, 2022

Regularizing Generative Adversarial Networks under Limited Data (CVPR 2021)
Regularizing Generative Adversarial Networks under Limited Data [Project Page][Paper] Implementation for our GAN regularization method. The proposed r
 148 Nov 18, 2022
148 Nov 18, 2022

《Improving Unsupervised Image Clustering With Robust Learning》(2020)
Improving Unsupervised Image Clustering With Robust Learning This repo is the PyTorch codes for "Improving Unsupervised Image Clustering With Robust L
 129 Dec 27, 2022
129 Dec 27, 2022
geemap - A Python package for interactive mapping with Google Earth Engine, ipyleaflet, and ipywidgets.
A Python package for interactive mapping with Google Earth Engine, ipyleaflet, and folium
 2.4k Dec 30, 2022
2.4k Dec 30, 2022

A collection of loss functions for medical image segmentation
A collection of loss functions for medical image segmentation
 3.1k Jan 3, 2023
3.1k Jan 3, 2023

SimDeblur is a simple framework for image and video deblurring, implemented by PyTorch
SimDeblur (Simple Deblurring) is an open source framework for image and video deblurring toolbox based on PyTorch, which contains most deep-learning based state-of-the-art deblurring algorithms. It is easy to implement your own image or video deblurring or other restoration algorithms.
 220 Jan 7, 2023
220 Jan 7, 2023

Code to reproduce the experiments in the paper "Transformer Based Multi-Source Domain Adaptation" (EMNLP 2020)
Transformer Based Multi-Source Domain Adaptation Dustin Wright and Isabelle Augenstein To appear in EMNLP 2020. Read the preprint: https://arxiv.org/a
 36 Dec 5, 2022
36 Dec 5, 2022

A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains (IJCV submission)
wsss-analysis The code of: A Comprehensive Analysis of Weakly-Supervised Semantic Segmentation in Different Image Domains, arXiv pre-print 2019 paper.
 48 Dec 18, 2022
48 Dec 18, 2022
Official implementation of "An Image is Worth 16x16 Words, What is a Video Worth?" (2021 paper)
An Image is Worth 16x16 Words, What is a Video Worth? paper Official PyTorch Implementation Gilad Sharir, Asaf Noy, Lihi Zelnik-Manor DAMO Academy, Al
 213 Nov 12, 2022
213 Nov 12, 2022

source code and pre-trained/fine-tuned checkpoint for NAACL 2021 paper LightningDOT
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval This repository contains source code and pre-trained/fine-tun
 65 Dec 26, 2022
65 Dec 26, 2022
Code for CVPR 2021 paper: Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning This is the PyTorch companion code for the paper: A
 69 Jan 3, 2023
69 Jan 3, 2023

Official PyTorch implementation for Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, a novel method to visualize any Transformer-based network. Including examples for DETR, VQA.
PyTorch Implementation of Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers 1 Using Colab Please notic
 489 Jan 7, 2023
489 Jan 7, 2023

Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Hiring research interns for visual transformer
484 Dec 29, 2022

Official PyTorch implementation of "ArtFlow: Unbiased Image Style Transfer via Reversible Neural Flows"
ArtFlow Official PyTorch implementation of the paper: ArtFlow: Unbiased Image Style Transfer via Reversible Neural Flows Jie An*, Siyu Huang*, Yibing
 123 Dec 27, 2022
123 Dec 27, 2022
![git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]](https://github.com/happycaoyue/Pseudo-ISP/raw/main/img/3.png)
git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]
Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser Abstract The success of deep denoisers on real-world colo
 51 Nov 22, 2022
51 Nov 22, 2022

This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
 307 Jan 3, 2023
307 Jan 3, 2023
Leveraging Instance-, Image- and Dataset-Level Information for Weakly Supervised Instance Segmentation
Leveraging Instance-, Image- and Dataset-Level Information for Weakly Supervised Instance Segmentation This paper has been accepted and early accessed
 39 Sep 20, 2022
39 Sep 20, 2022

PyTorch Implementation of CvT: Introducing Convolutions to Vision Transformers
CvT: Introducing Convolutions to Vision Transformers Pytorch implementation of CvT: Introducing Convolutions to Vision Transformers Usage: img = torch
 193 Jan 3, 2023
193 Jan 3, 2023

Implementation of 'lightweight' GAN, proposed in ICLR 2021, in Pytorch. High resolution image generations that can be trained within a day or two
512x512 flowers after 12 hours of training, 1 gpu 256x256 flowers after 12 hours of training, 1 gpu Pizza 'Lightweight' GAN Implementation of 'lightwe
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Implementation of the Swin Transformer in PyTorch.
Swin Transformer - PyTorch Implementation of the Swin Transformer architecture. This paper presents a new vision Transformer, called Swin Transformer,
 597 Jan 3, 2023
597 Jan 3, 2023

TransReID: Transformer-based Object Re-Identification
TransReID: Transformer-based Object Re-Identification [arxiv] The official repository for TransReID: Transformer-based Object Re-Identification achiev
 569 Dec 30, 2022
569 Dec 30, 2022
This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
307 Jan 3, 2023
Learning Spatio-Temporal Transformer for Visual Tracking
STARK The official implementation of the paper Learning Spatio-Temporal Transformer for Visual Tracking Highlights The strongest performances Tracker
485 Jan 4, 2023
Hybrid Neural Fusion for Full-frame Video Stabilization
FuSta: Hybrid Neural Fusion for Full-frame Video Stabilization Project Page | Video | Paper | Google Colab Setup Setup environment for [Yu and Ramamoo
 430 Jan 4, 2023
430 Jan 4, 2023

This code extends the neural style transfer image processing technique to video by generating smooth transitions between several reference style images
Neural Style Transfer Transition Video Processing By Brycen Westgarth and Tristan Jogminas Description This code extends the neural style transfer ima
 110 Jan 7, 2023
110 Jan 7, 2023
Implementation of LambdaNetworks, a new approach to image recognition that reaches SOTA with less compute
Lambda Networks - Pytorch Implementation of λ Networks, a new approach to image recognition that reaches SOTA on ImageNet. The new method utilizes λ l
1.5k Jan 7, 2023

An implementation of Performer, a linear attention-based transformer, in Pytorch
Performer - Pytorch An implementation of Performer, a linear attention-based transformer variant with a Fast Attention Via positive Orthogonal Random
900 Dec 22, 2022
PyTorch extensions for fast R&D prototyping and Kaggle farming
Pytorch-toolbelt A pytorch-toolbelt is a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping and Kaggle farming: What
 1.3k Jan 5, 2023
1.3k Jan 5, 2023

Reformer, the efficient Transformer, in Pytorch
Reformer, the Efficient Transformer, in Pytorch This is a Pytorch implementation of Reformer https://openreview.net/pdf?id=rkgNKkHtvB It includes LSH
1.8k Jan 6, 2023
The easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Written in PyTorch.
News March 3: v0.9.97 has various bug fixes and improvements: Bug fixes for NTXentLoss Efficiency improvement for AccuracyCalculator, by using torch i
 5k Jan 2, 2023
5k Jan 2, 2023

Rembg is a tool to remove images background.
Rembg is a tool to remove images background.
 7.8k Jan 5, 2023
7.8k Jan 5, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
4.2k Jan 8, 2023
An easier way to build neural search on the cloud
An easier way to build neural search on the cloud Jina is a deep learning-powered search framework for building cross-/multi-modal search systems (e.g
 17k Jan 2, 2023
17k Jan 2, 2023
git《Self-Attention Attribution: Interpreting Information Interactions Inside Transformer》(AAAI 2021) GitHub:
Self-Attention Attribution This repository contains the implementation for AAAI-2021 paper Self-Attention Attribution: Interpreting Information Intera
 60 Dec 29, 2022
60 Dec 29, 2022

Diverse Image Captioning with Context-Object Split Latent Spaces (NeurIPS 2020)
Diverse Image Captioning with Context-Object Split Latent Spaces This repository is the PyTorch implementation of the paper: Diverse Image Captioning
 34 Nov 21, 2022
34 Nov 21, 2022
a general-purpose Transformer based vision backbone
Swin Transformer By Ze Liu*, Yutong Lin*, Yue Cao*, Han Hu*, Yixuan Wei, Zheng Zhang, Stephen Lin and Baining Guo. This repo is the official implement
 9.9k Jan 8, 2023
9.9k Jan 8, 2023
Conversion of Image, video, text into ASCII format
asciju Python package that converts image to ascii Free software: MIT license
 11 Aug 22, 2022
11 Aug 22, 2022
git git《Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking》(CVPR 2021) GitHub:git2] 《Masksembles for Uncertainty Estimation》(CVPR 2021) GitHub:git3]
Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking Ning Wang, Wengang Zhou, Jie Wang, and Houqiang Li Accepted by CVPR
 236 Dec 22, 2022
236 Dec 22, 2022
Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning (ICLR 2021)
Understanding and Improving Encoder Layer Fusion in Sequence-to-Sequence Learning (ICLR 2021) Citation Please cite as: @inproceedings{liu2020understan
 22 Nov 25, 2022
22 Nov 25, 2022
Monocular Depth Estimation - Weighted-average prediction from multiple pre-trained depth estimation models
merged_depth runs (1) AdaBins, (2) DiverseDepth, (3) MiDaS, (4) SGDepth, and (5) Monodepth2, and calculates a weighted-average per-pixel absolute dept
 39 Nov 21, 2022
39 Nov 21, 2022
Rotary Transformer
Rotary Transformer Rotary Transformer,简称RoFormer,是我们自研的语言模型之一,主要是为Transformer结构设计了新的旋转式位置编码(Rotary Position Embedding,RoPE)。RoPE具有良好的理论性质,且是目前唯一一种可以应用
 325 Jan 3, 2023
325 Jan 3, 2023
![[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.](https://github.com/ethnhe/FFB6D/raw/master/figs/FFB6D_overview.png)
[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.
FFB6D This is the official source code for the CVPR2021 Oral work, FFB6D: A Full Flow Biderectional Fusion Network for 6D Pose Estimation. (Arxiv) Tab
 201 Dec 28, 2022
201 Dec 28, 2022
![[CVPR'21] FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space](https://github.com/liuquande/FedDG-ELCFS/raw/main/figure/cvpr21_feddg.png)
[CVPR'21] FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space
FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space by Quande Liu, Cheng Chen, Ji
 178 Jan 6, 2023
178 Jan 6, 2023
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf # it's a scriptable c
 7.9k Jan 3, 2023
7.9k Jan 3, 2023
ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes.
ScanTailor Advanced The ScanTailor version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and f
 952 Dec 31, 2022
952 Dec 31, 2022

document image degradation
ocrodeg The ocrodeg package is a small Python library implementing document image degradation for data augmentation for handwriting recognition and OC
 134 Nov 18, 2022
134 Nov 18, 2022
A selectional auto-encoder approach for document image binarization
The code of this repository was used for the following publication. If you find this code useful please cite our paper: @article{Gallego2019, title =
 89 Nov 18, 2022
89 Nov 18, 2022
Geometric Augmentation for Text Image
Text Image Augmentation A general geometric augmentation tool for text images in the CVPR 2020 paper "Learn to Augment: Joint Data Augmentation and Ne
 440 Jan 5, 2023
440 Jan 5, 2023
PAGE XML format collection for document image page content and more
PAGE-XML PAGE XML format collection for document image page content and more For an introduction, please see the following publication: http://www.pri
 46 Nov 14, 2022
46 Nov 14, 2022
A general list of resources to image text localization and recognition 场景文本位置感知与识别的论文资源与实现合集 シーンテキストの位置認識と識別のための論文リソースの要約
Scene Text Localization & Recognition Resources Read this institute-wise: English, 简体中文. Read this year-wise: English, 简体中文. Tags: [STL] (Scene Text L
 901 Dec 11, 2022
901 Dec 11, 2022

OCR system for Arabic language that converts images of typed text to machine-encoded text.
Arabic OCR OCR system for Arabic language that converts images of typed text to machine-encoded text. The system currently supports only letters (29 l
 144 Jan 5, 2023
144 Jan 5, 2023
Solution for Problem 1 by team codesquad for AIDL 2020. Uses ML Kit for OCR and OpenCV for image processing
CodeSquad PS1 Solution for Problem Statement 1 for AIDL 2020 conducted by @unifynd technologies. Problem Given images of bills/invoices, the task was
 111 Nov 27, 2022
111 Nov 27, 2022
A Tensorflow model for text recognition (CNN + seq2seq with visual attention) available as a Python package and compatible with Google Cloud ML Engine.
Attention-based OCR Visual attention-based OCR model for image recognition with additional tools for creating TFRecords datasets and exporting the tra
 933 Dec 29, 2022
933 Dec 29, 2022
The first open-source library that detects the font of a text in a image.
Typefont Typefont is an experimental library that detects the font of a text in a image. Usage Import the main function and invoke it like in the foll
 1.6k Feb 24, 2022
1.6k Feb 24, 2022

Textboxes : Image Text Detection Model : python package (tensorflow)
shinTB Abstract A python package for use Textboxes : Image Text Detection Model implemented by tensorflow, cv2 Textboxes Paper Review in Korean (My Bl
 91 Dec 15, 2022
91 Dec 15, 2022

AdvancedEAST is an algorithm used for Scene image text detect, which is primarily based on EAST, and the significant improvement was also made, which make long text predictions more accurate.https://github.com/huoyijie/raspberrypi-car
AdvancedEAST AdvancedEAST is an algorithm used for Scene image text detect, which is primarily based on EAST:An Efficient and Accurate Scene Text Dete
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
Detecting Text in Natural Image with Connectionist Text Proposal Network (ECCV'16)
Detecting Text in Natural Image with Connectionist Text Proposal Network The codes are used for implementing CTPN for scene text detection, described
 1.3k Dec 22, 2022
1.3k Dec 22, 2022

keras复现场景文本检测网络CPTN: 《Detecting Text in Natural Image with Connectionist Text Proposal Network》;欢迎试用,关注,并反馈问题...
keras-ctpn [TOC] 说明 预测 训练 例子 4.1 ICDAR2015 4.1.1 带侧边细化 4.1.2 不带带侧边细化 4.1.3 做数据增广-水平翻转 4.2 ICDAR2017 4.3 其它数据集 toDoList 总结 说明 本工程是keras实现的CPTN: Detecti
 107 Jan 9, 2023
107 Jan 9, 2023

TensorFlow Implementation of FOTS, Fast Oriented Text Spotting with a Unified Network.
FOTS: Fast Oriented Text Spotting with a Unified Network I am still working on this repo. updates and detailed instructions are coming soon! Table of
 52 Nov 11, 2022
52 Nov 11, 2022

Scene text detection and recognition based on Extremal Region(ER)
Scene text recognition A real-time scene text recognition algorithm. Our system is able to recognize text in unconstrain background. This algorithm is
 155 Dec 6, 2022
155 Dec 6, 2022
Python library to extract tabular data from images and scanned PDFs
Overview ExtractTable - API to extract tabular data from images and scanned PDFs The motivation is to make it easy for developers to extract tabular d
 165 Dec 31, 2022
165 Dec 31, 2022
Extract tables from scanned image PDFs using Optical Character Recognition.
ocr-table This project aims to extract tables from scanned image PDFs using Optical Character Recognition. Install Requirements Tesseract OCR sudo apt
 209 Dec 6, 2022
209 Dec 6, 2022

Turn images of tables into CSV data. Detect tables from images and run OCR on the cells.
Table of Contents Overview Requirements Demo Modules Overview This python package contains modules to help with finding and extracting tabular data fr
 311 Dec 24, 2022
311 Dec 24, 2022

Use Convolutional Recurrent Neural Network to recognize the Handwritten line text image without pre segmentation into words or characters. Use CTC loss Function to train.
Handwritten Line Text Recognition using Deep Learning with Tensorflow Description Use Convolutional Recurrent Neural Network to recognize the Handwrit
 224 Jan 7, 2023
224 Jan 7, 2023
Handwritten Number Recognition using CNN and Character Segmentation
Handwritten-Number-Recognition-With-Image-Segmentation Info About this repository This Repository is aimed at reading handwritten images of numbers an
 17 Aug 25, 2022
17 Aug 25, 2022
Page to PAGE Layout Analysis Tool
P2PaLA Page to PAGE Layout Analysis (P2PaLA) is a toolkit for Document Layout Analysis based on Neural Networks. 💥 Try our new DEMO for online baseli
 180 Nov 24, 2022
180 Nov 24, 2022

Detect handwritten words in a text-line (classic image processing method).
Word segmentation Implementation of scale space technique for word segmentation as proposed by R. Manmatha and N. Srimal. Even though the paper is fro
 190 Jan 3, 2023
190 Jan 3, 2023

Code for the paper "DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks" (ICCV '19)
DewarpNet This repository contains the codes for DewarpNet training. Recent Updates [May, 2020] Added evaluation images and an important note about Ma
 354 Jan 1, 2023
354 Jan 1, 2023

Detect and fix skew in images containing text
Alyn Skew detection and correction in images containing text Image with skew Image after deskew Install and use via pip! Recommended way(using virtual
 230 Dec 21, 2022
230 Dec 21, 2022

Document Image Dewarping
Document image dewarping using text-lines and line Segments Abstract Conventional text-line based document dewarping methods have problems when handli
 268 Dec 23, 2022
268 Dec 23, 2022
Deskew is a command line tool for deskewing scanned text documents. It uses Hough transform to detect "text lines" in the image. As an output, you get an image rotated so that the lines are horizontal.
Deskew by Marek Mauder https://galfar.vevb.net/deskew https://github.com/galfar/deskew v1.30 2019-06-07 Overview Deskew is a command line tool for des
 127 Dec 3, 2022
127 Dec 3, 2022

MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition
MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition Python 2.7 Python 3.6 MORAN is a network with rectification mechanism for
595 Dec 27, 2022
Adaptive Attention Span for Reinforcement Learning
Adaptive Transformers in RL Official implementation of Adaptive Transformers in RL In this work we replicate several results from Stabilizing Transfor
 100 Nov 15, 2022
100 Nov 15, 2022

Code for SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics (ACL'2020).
SentiBERT Code for SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics (ACL'2020). https://arxiv.org/abs/20
 66 Aug 13, 2022
66 Aug 13, 2022
![[ICLR 2021, Spotlight] Large Scale Image Completion via Co-Modulated Generative Adversarial Networks](https://github.com/zsyzzsoft/co-mod-gan/raw/master/imgs/demo.gif)
[ICLR 2021, Spotlight] Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
Large Scale Image Completion via Co-Modulated Generative Adversarial Networks, ICLR 2021 (Spotlight) Demo | Paper [NEW!] Time to play with our interac
 373 Jan 2, 2023
373 Jan 2, 2023
Transformer Tracking (CVPR2021)
TransT - Transformer Tracking [CVPR2021] Official implementation of the TransT (CVPR2021) , including training code and trained models. We are revisin
 465 Jan 6, 2023
465 Jan 6, 2023

CVPR 2021: "Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE"
Diverse Structure Inpainting ArXiv | Papar | Supplementary Material | BibTex This repository is for the CVPR 2021 paper, "Generating Diverse Structure
 152 Nov 4, 2022
152 Nov 4, 2022

(under submission) Bayesian Integration of a Generative Prior for Image Restoration
BIGPrior: Towards Decoupling Learned Prior Hallucination and Data Fidelity in Image Restoration Authors: Majed El Helou, and Sabine Süsstrunk {Note: p
 22 Dec 17, 2022
22 Dec 17, 2022
[CVPR 2021] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
[CVPR 2021] Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
 364 Jan 3, 2023
364 Jan 3, 2023

Open source code for Paper "A Co-Interactive Transformer for Joint Slot Filling and Intent Detection"
A Co-Interactive Transformer for Joint Slot Filling and Intent Detection This repository contains the PyTorch implementation of the paper: A Co-Intera
 67 Dec 5, 2022
67 Dec 5, 2022

Repository for "Exploring Sparsity in Image Super-Resolution for Efficient Inference", CVPR 2021
SMSR Reposity for "Exploring Sparsity in Image Super-Resolution for Efficient Inference" [arXiv] Highlights Locate and skip redundant computation in S
 225 Dec 26, 2022
225 Dec 26, 2022

Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
5k Jan 2, 2023

Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in PyTorch
Implementation of Analyzing and Improving the Image Quality of StyleGAN (StyleGAN 2) in PyTorch
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Old Photo Restoration (Official PyTorch Implementation)
Bringing Old Photo Back to Life (CVPR 2020 oral)
11.3k Dec 30, 2022

Simple command line tool for text to image generation using OpenAI's CLIP and Siren (Implicit neural representation network)
Simple command line tool for text to image generation using OpenAI's CLIP and Siren (Implicit neural representation network)
4.4k Jan 9, 2023
Model parallel transformers in Jax and Haiku
Mesh Transformer Jax A haiku library using the new(ly documented) xmap operator in Jax for model parallelism of transformers. See enwik8_example.py fo
 4.8k Jan 1, 2023
4.8k Jan 1, 2023
Solaris IPS: Image Packaging System
Solaris Image Packaging System Introduction The image packaging system (IPS) is a software delivery system with interaction with a network repository
 57 Dec 30, 2022
57 Dec 30, 2022

This is the code for HOI Transformer
HOI Transformer Code for CVPR 2021 accepted paper End-to-End Human Object Interaction Detection with HOI Transformer. Reproduction We recomend you to
 124 Dec 29, 2022
124 Dec 29, 2022
CoTr: Efficiently Bridging CNN and Transformer for 3D Medical Image Segmentation
CoTr: Efficient 3D Medical Image Segmentation by bridging CNN and Transformer This is the official pytorch implementation of the CoTr: Paper: CoTr: Ef
 218 Dec 25, 2022
218 Dec 25, 2022

Repo for CVPR2021 paper "QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information"
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information by Masato Tamura, Hiroki Ohashi, and Tomoaki Yosh
 105 Dec 23, 2022
105 Dec 23, 2022
![[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator](https://github.com/d-li14/involution/raw/main/fig/involution.png)
[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator
involution Official implementation of a neural operator as described in Involution: Inverting the Inherence of Convolution for Visual Recognition (CVP
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
![[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing](https://github.com/mit-han-lab/anycost-gan/raw/master/assets/figures/demo.gif)
[CVPR 2021] Anycost GANs for Interactive Image Synthesis and Editing
Anycost GAN video | paper | website Anycost GANs for Interactive Image Synthesis and Editing Ji Lin, Richard Zhang, Frieder Ganz, Song Han, Jun-Yan Zh
 726 Dec 28, 2022
726 Dec 28, 2022

This repo provides the official code for TransBTS: Multimodal Brain Tumor Segmentation Using Transformer (https://arxiv.org/pdf/2103.04430.pdf).
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer This repo is the official implementation for TransBTS: Multimodal Brain Tumor Segmenta
 247 Dec 28, 2022
247 Dec 28, 2022