181 Repositories
Python multimodal-fusion Libraries
MGFN: Multi-Graph Fusion Networks for Urban Region Embedding was accepted by IJCAI-2022.
Multi-Graph Fusion Networks for Urban Region Embedding (IJCAI-22) This is the implementation of Multi-Graph Fusion Networks for Urban Region Embedding
 202 Nov 18, 2022
202 Nov 18, 2022

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
 565 Dec 30, 2022
565 Dec 30, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

MAGMA - a GPT-style multimodal model that can understand any combination of images and language
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning Authors repo (alphabetical) Constantin (CoEich), Mayukh (Mayukh
 331 Jan 3, 2023
331 Jan 3, 2023
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
TorchMultimodal (Alpha Release) Introduction TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
 663 Jan 6, 2023
663 Jan 6, 2023
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

The implementation of "Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement"
SF-Net for fullband SE This is the repo of the manuscript "Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Ban
 36 Dec 2, 2022
36 Dec 2, 2022
NAACL 2022: MCSE: Multimodal Contrastive Learning of Sentence Embeddings
MCSE: Multimodal Contrastive Learning of Sentence Embeddings This repository contains code and pre-trained models for our NAACL-2022 paper MCSE: Multi
 39 Nov 15, 2022
39 Nov 15, 2022

Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion"
MKGFormer Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion" Model Architecture Illu
 68 Dec 28, 2022
68 Dec 28, 2022
![[LREC] MMChat: Multi-Modal Chat Dataset on Social Media](https://github.com/silverriver/MMChat/raw/main/bin/sample.jpg)
[LREC] MMChat: Multi-Modal Chat Dataset on Social Media
MMChat This repo contains the code and data for the LREC2022 paper MMChat: Multi-Modal Chat Dataset on Social Media. Dataset MMChat is a large-scale d
 47 Jan 3, 2023
47 Jan 3, 2023
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Code for Findings of ACL 2022 Paper "Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors"
SWRM Code for Findings of ACL 2022 Paper "Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors" Clone Clone th
 14 Jan 3, 2023
14 Jan 3, 2023

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022

KinectFusion implemented in Python with PyTorch
KinectFusion implemented in Python with PyTorch This is a lightweight Python implementation of KinectFusion. All the core functions (TSDF volume, fram
 80 Jan 3, 2023
80 Jan 3, 2023

Python code to fuse multiple RGB-D images into a TSDF voxel volume.
Volumetric TSDF Fusion of RGB-D Images in Python This is a lightweight python script that fuses multiple registered color and depth images into a proj
 845 Jan 3, 2023
845 Jan 3, 2023
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation This reposi
 1 Aug 21, 2022
1 Aug 21, 2022

MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition Paper: MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition accepted fo
 64 Dec 18, 2022
64 Dec 18, 2022
Official implementation of NeuralFusion: Online Depth Map Fusion in Latent Space
NeuralFusion This is the official implementation of NeuralFusion: Online Depth Map Fusion in Latent Space. We provide code to train the proposed pipel
 53 Jan 1, 2023
53 Jan 1, 2023
Speech Emotion Recognition with Fusion of Acoustic- and Linguistic-Feature-Based Decisions
APSIPA-SER-with-A-and-T This code is the implementation of Speech Emotion Recognition (SER) with acoustic and linguistic features. The network model i
 3 Jan 4, 2023
3 Jan 4, 2023

DFFNet: An IoT-perceptive Dual Feature Fusion Network for General Real-time Semantic Segmentation
DFFNet Paper DFFNet: An IoT-perceptive Dual Feature Fusion Network for General Real-time Semantic Segmentation. Xiangyan Tang, Wenxuan Tu, Keqiu Li, J
 4 Sep 23, 2022
4 Sep 23, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Code for Multimodal Neural SLAM for Interactive Instruction Following
Code for Multimodal Neural SLAM for Interactive Instruction Following Code structure The code is adapted from E.T. and most training as well as data p
 7 Dec 7, 2022
7 Dec 7, 2022

Official code of Team Yao at Multi-Modal-Fact-Verification-2022
Official code of Team Yao at Multi-Modal-Fact-Verification-2022 A Multi-Modal Fact Verification dataset released as part of the De-Factify workshop in
 11 Nov 15, 2022
11 Nov 15, 2022
Pytorch implement of 'Unmixing based PAN guided fusion network for hyperspectral imagery'
Pgnet There's a improved version compared with the publication in Tgrs with the modification in the deduction of the PDIN block: https://arxiv.org/abs
 5 Jul 1, 2022
5 Jul 1, 2022

AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
AirPose AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation Check the teaser video This repository contains the code of A
 41 Dec 5, 2022
41 Dec 5, 2022
Evidential Softmax for Sparse Multimodal Distributions in Deep Generative Models
Evidential Softmax for Sparse Multimodal Distributions in Deep Generative Models Abstract Many applications of generative models rely on the marginali
 9 Jun 6, 2022
9 Jun 6, 2022

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022
Conditional Generative Adversarial Networks (CGAN) for Mobility Data Fusion
This code implements the paper, Kim et al. (2021). Imputing Qualitative Attributes for Trip Chains Extracted from Smart Card Data Using a Conditional Generative Adversarial Network. Transportation Research Part C. Under Review.
 2 Feb 3, 2022
2 Feb 3, 2022
Implementation of "With a Little Help from my Temporal Context: Multimodal Egocentric Action Recognition, BMVC, 2021" in PyTorch
Multimodal Temporal Context Network (MTCN) This repository implements the model proposed in the paper: Evangelos Kazakos, Jaesung Huh, Arsha Nagrani,
 13 Nov 24, 2022
13 Nov 24, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022
Image Fusion Transformer
Image-Fusion-Transformer Platform Python 3.7 Pytorch =1.0 Training Dataset MS-COCO 2014 (T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ram
 68 Dec 23, 2022
68 Dec 23, 2022
![[CVPR 2021]](https://github.com/decisionforce/mmTransformer/raw/main/figs/model.png)
[CVPR 2021] "Multimodal Motion Prediction with Stacked Transformers": official code implementation and project page.
mmTransformer Introduction This repo is official implementation for mmTransformer in pytorch. Currently, the core code of mmTransformer is implemented
 232 Dec 31, 2022
232 Dec 31, 2022
A High-Level Fusion Scheme for Circular Quantities published at the 20th International Conference on Advanced Robotics
Monte Carlo Simulation to the Paper A High-Level Fusion Scheme for Circular Quantities published at the 20th International Conference on Advanced Robotics
 0 Dec 6, 2021
0 Dec 6, 2021

MINOS: Multimodal Indoor Simulator
MINOS Simulator MINOS is a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environ
 194 Dec 27, 2022
194 Dec 27, 2022

A simple baseline for the 2022 IEEE GRSS Data Fusion Contest (DFC2022)
DFC2022 Baseline A simple baseline for the 2022 IEEE GRSS Data Fusion Contest (DFC2022) This repository uses TorchGeo, PyTorch Lightning, and Segmenta
 24 Nov 28, 2022
24 Nov 28, 2022
Image-retrieval-baseline - MUGE Multimodal Retrieval Baseline
MUGE Multimodal Retrieval Baseline This repo is implemented based on the open_cl
 47 Dec 16, 2022
47 Dec 16, 2022
Alignment Attention Fusion framework for Few-Shot Object Detection
AAF framework Framework generalities This repository contains the code of the AAF framework proposed in this paper. The main idea behind this work is
 20 Dec 16, 2022
20 Dec 16, 2022
Paper Title: Heterogeneous Knowledge Distillation for Simultaneous Infrared-Visible Image Fusion and Super-Resolution
HKDnet Paper Title: "Heterogeneous Knowledge Distillation for Simultaneous Infrared-Visible Image Fusion and Super-Resolution" Email: 18186470991@163.
 11 Nov 12, 2022
11 Nov 12, 2022
NeuralTalk is a Python+numpy project for learning Multimodal Recurrent Neural Networks that describe images with sentences.
#NeuralTalk Warning: Deprecated. Hi there, this code is now quite old and inefficient, and now deprecated. I am leaving it on Github for educational p
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
Code for the paper: Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution
Fusformer Code for the paper: "Fusformer: A Transformer-based Fusion Approach for Hyperspectral Image Super-resolution" Plateform Python 3.8.5 + Pytor
 11 Dec 12, 2022
11 Dec 12, 2022
![[ECCV 2020] XingGAN for Person Image Generation](https://github.com/Ha0Tang/XingGAN/raw/master/imgs/framework.jpg)
[ECCV 2020] XingGAN for Person Image Generation
Contents XingGAN or CrossingGAN Installation Dataset Preparation Generating Images Using Pretrained Model Train and Test New Models Evaluation Acknowl
 218 Oct 29, 2022
218 Oct 29, 2022
Code release for Convolutional Two-Stream Network Fusion for Video Action Recognition
Convolutional Two-Stream Network Fusion for Video Action Recognition
 676 Dec 31, 2022
676 Dec 31, 2022
Sigma coding youtube - This is a collection of all the code that can be found on my YouTube channel Sigma Coding.
Sigma Coding Tutorials & Resources YouTube • Facebook Support Sigma Coding Patreon • GitHub Sponsor • Shop Amazon Table of Contents Overview Topics Re
 927 Jan 8, 2023
927 Jan 8, 2023

LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
LAVT: Language-Aware Vision Transformer for Referring Image Segmentation Where we are ? 12.27 目前和原论文仍有1%左右得差距,但已经力压很多SOTA了 ckpt__448_epoch_25.pth mIoU
 60 Dec 11, 2022
60 Dec 11, 2022

PyTorch code for training MM-DistillNet for multimodal knowledge distillation
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge MM-DistillNet is a
 51 Dec 20, 2022
51 Dec 20, 2022

Project of 'TBEFN: A Two-branch Exposure-fusion Network for Low-light Image Enhancement '
TBEFN: A Two-branch Exposure-fusion Network for Low-light Image Enhancement Codes for TMM20 paper "TBEFN: A Two-branch Exposure-fusion Network for Low
 31 Nov 6, 2022
31 Nov 6, 2022

Code for "Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals," CoRL 2021.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals This repository contains code for "Multimodal trajectory prediction conditioned
 113 Dec 28, 2022
113 Dec 28, 2022

SE-MSCNN: A Lightweight Multi-scaled Fusion Network for Sleep Apnea Detection Using Single-Lead ECG Signals
SE-MSCNN: A Lightweight Multi-scaled Fusion Network for Sleep Apnea Detection Using Single-Lead ECG Signals Abstract Sleep apnea (SA) is a common slee
 9 Dec 21, 2022
9 Dec 21, 2022
Tensorflow Implementation of ECCV'18 paper: Multimodal Human Motion Synthesis
MT-VAE for Multimodal Human Motion Synthesis This is the code for ECCV 2018 paper MT-VAE: Learning Motion Transformations to Generate Multimodal Human
 36 Oct 2, 2022
36 Oct 2, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
a practicable framework used in Deep Learning. So far UDL only provide DCFNet implementation for the ICCV paper (Dynamic Cross Feature Fusion for Remote Sensing Pansharpening)
UDL UDL is a practicable framework used in Deep Learning (computer vision). Benchmark codes, results and models are available in UDL, please contact @
 11 Sep 30, 2022
11 Sep 30, 2022

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Cleaned up code for DSTC 10: SIMMC 2.0 track: subtask 2: multimodal coreference resolution
UNITER-Based Situated Coreference Resolution with Rich Multimodal Input: arXiv MMCoref_cleaned Code for the MMCoref task of the SIMMC 2.0 dataset. Pre
 2 Dec 5, 2022
2 Dec 5, 2022

Edge-aware Guidance Fusion Network for RGB-Thermal Scene Parsing
EGFNet Edge-aware Guidance Fusion Network for RGB-Thermal Scene Parsing Dataset and Results Test maps: 百度网盘 提取码:zust Citation @ARTICLE{ author={Zhou,
 10 Dec 8, 2022
10 Dec 8, 2022
Confidence Propagation Cluster aims to replace NMS-based methods as a better box fusion framework in 2D/3D Object detection
CP-Cluster Confidence Propagation Cluster aims to replace NMS-based methods as a better box fusion framework in 2D/3D Object detection, Instance Segme
 41 Dec 8, 2022
41 Dec 8, 2022
Official PyTorch implementation of our AAAI22 paper: TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework via Self-Supervised Multi-Task Learning. Code will be available soon.
Official-PyTorch-Implementation-of-TransMEF Official PyTorch implementation of our AAAI22 paper: TransMEF: A Transformer-Based Multi-Exposure Image Fu
 117 Dec 27, 2022
117 Dec 27, 2022
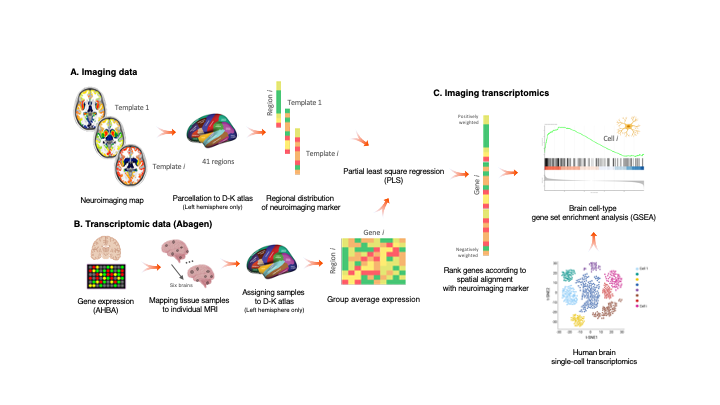
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023
Fusion-in-Decoder Distilling Knowledge from Reader to Retriever for Question Answering
This repository contains code for: Fusion-in-Decoder models Distilling Knowledge from Reader to Retriever Dependencies Python 3 PyTorch (currently tes
323 Dec 19, 2022
ShuttleNet: Position-aware Fusion of Rally Progress and Player Styles for Stroke Forecasting in Badminton (AAAI'22)
ShuttleNet: Position-aware Rally Progress and Player Styles Fusion for Stroke Forecasting in Badminton (AAAI 2022) Official code of the paper ShuttleN
11 Nov 30, 2022
This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text"
Iconary This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text". It includes the
 6 May 24, 2022
6 May 24, 2022
ShuttleNet: Position-aware Fusion of Rally Progress and Player Styles for Stroke Forecasting in Badminton (AAAI 2022)
ShuttleNet: Position-aware Rally Progress and Player Styles Fusion for Stroke Forecasting in Badminton (AAAI 2022) Official code of the paper ShuttleN
11 Nov 30, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method.
Set of methods to ensemble boxes from different object detection models, including implementation of "Weighted boxes fusion (WBF)" method.
 1.4k Jan 5, 2023
1.4k Jan 5, 2023
End-to-End Referring Video Object Segmentation with Multimodal Transformers
End-to-End Referring Video Object Segmentation with Multimodal Transformers This repo contains the official implementation of the paper: End-to-End Re
 608 Dec 30, 2022
608 Dec 30, 2022
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
 206 Dec 28, 2022
206 Dec 28, 2022
MMDA - multimodal document analysis
MMDA - multimodal document analysis
75 Jan 4, 2023
alfred-py: A deep learning utility library for **human**
Alfred Alfred is command line tool for deep-learning usage. if you want split an video into image frames or combine frames into a single video, then a
 800 Jan 3, 2023
800 Jan 3, 2023

Code release for Local Light Field Fusion at SIGGRAPH 2019
Local Light Field Fusion Project | Video | Paper Tensorflow implementation for novel view synthesis from sparse input images. Local Light Field Fusion
 748 Nov 27, 2021
748 Nov 27, 2021
HybVIO visual-inertial odometry and SLAM system
HybVIO A visual-inertial odometry system with an optional SLAM module. This is a research-oriented codebase, which has been published for the purposes
 320 Jan 3, 2023
320 Jan 3, 2023

Multimodal commodity image retrieval 多模态商品图像检索
Multimodal commodity image retrieval 多模态商品图像检索 Not finished yet... introduce explain:The specific description of the project and the product image dat
 8 Nov 25, 2022
8 Nov 25, 2022

Official Code for Cross-Modality Fusion Transformer for Multispectral Object Detection.
Multispectral-Object-Detection Intro Official Code for Cross-Modality Fusion Transformer for Multispectral Object Detection. Multispectral Object Dete
 14 Nov 24, 2021
14 Nov 24, 2021
This repository contains the official implementation code of the paper Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis
This repository contains the official implementation code of the paper Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis, accepted at ACMMM 2021.
 10 Sep 30, 2022
10 Sep 30, 2022

A Collection of LiDAR-Camera-Calibration Papers, Toolboxes and Notes
A Collection of LiDAR-Camera-Calibration Papers, Toolboxes and Notes
 443 Jan 6, 2023
443 Jan 6, 2023
Code release for Local Light Field Fusion at SIGGRAPH 2019
Local Light Field Fusion Project | Video | Paper Tensorflow implementation for novel view synthesis from sparse input images. Local Light Field Fusion
1.1k Dec 27, 2022

Official pytorch implementation of "DSPoint: Dual-scale Point Cloud Recognition with High-frequency Fusion"
DSPoint Official implementation of "DSPoint: Dual-scale Point Cloud Recognition with High-frequency Fusion". Paper link: https://arxiv.org/abs/2111.10
 10 Nov 24, 2021
10 Nov 24, 2021

Creating multimodal multitask models
Fusion Brain Challenge The English version of the document can be found here. Обновления 01.11 Мы выкладываем пример данных, аналогичных private test
 43 Nov 28, 2022
43 Nov 28, 2022
Official pytorch implementation of "DSPoint: Dual-scale Point Cloud Recognition with High-frequency Fusion"
DSPoint Official pytorch implementation of "DSPoint: Dual-scale Point Cloud Recognition with High-frequency Fusion" Coming soon, as soon as I finish a
14 Feb 26, 2022
Clinica is a software platform for clinical research studies involving patients with neurological and psychiatric diseases and the acquisition of multimodal data
Clinica Software platform for clinical neuroimaging studies Homepage | Documentation | Paper | Forum | See also: AD-ML, AD-DL ClinicaDL About The Proj
 165 Dec 29, 2022
165 Dec 29, 2022

A robust camera and Lidar fusion based velocity estimator to undistort the pointcloud.
Lidar with Velocity A robust camera and Lidar fusion based velocity estimator to undistort the pointcloud. related paper: Lidar with Velocity : Motion
 164 Dec 30, 2022
164 Dec 30, 2022

Toward Multimodal Image-to-Image Translation
BicycleGAN Project Page | Paper | Video Pytorch implementation for multimodal image-to-image translation. For example, given the same night image, our
 1.4k Dec 22, 2022
1.4k Dec 22, 2022
Self-supervised Multi-modal Hybrid Fusion Network for Brain Tumor Segmentation
JBHI-Pytorch This repository contains a reference implementation of the algorithms described in our paper "Self-supervised Multi-modal Hybrid Fusion N
 5 Dec 13, 2021
5 Dec 13, 2021
Code of Classification Saliency-Based Rule for Visible and Infrared Image Fusion
CSF Code of Classification Saliency-Based Rule for Visible and Infrared Image Fusion Tips: For testing: CUDA_VISIBLE_DEVICES=0 python main.py For trai
 14 Oct 31, 2022
14 Oct 31, 2022

Fusion 360 Add-in that creates a pair of toothed curves that can be used to split a body and create two pieces that slide and lock together.
Fusion-360-Add-In-PuzzleSpline Fusion 360 Add-in that creates a pair of toothed curves that can be used to split a body and create two pieces that sli
 1 Nov 15, 2021
1 Nov 15, 2021

the official code for ICRA 2021 Paper: "Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation"
G2S This is the official code for ICRA 2021 Paper: Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation by Hemang
 4 Jul 27, 2022
4 Jul 27, 2022

History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
 46 Nov 23, 2022
46 Nov 23, 2022

Turning pixels into virtual points for multimodal 3D object detection.
Multimodal Virtual Point 3D Detection Turning pixels into virtual points for multimodal 3D object detection. Multimodal Virtual Point 3D Detection, Ti
 204 Jan 8, 2023
204 Jan 8, 2023

MediaPipe is a an open-source framework from Google for building multimodal
MediaPipe is a an open-source framework from Google for building multimodal (eg. video, audio, any time series data), cross platform (i.e Android, iOS, web, edge devices) applied ML pipelines. It is performance optimized with end-to-end on device inference in mind.
 3 Sep 30, 2022
3 Sep 30, 2022
History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
46 Nov 23, 2022

This repo. is an implementation of ACFFNet, which is accepted for in Image and Vision Computing.
Attention-Guided-Contextual-Feature-Fusion-Network-for-Salient-Object-Detection This repo. is an implementation of ACFFNet, which is accepted for in I
 5 Nov 21, 2022
5 Nov 21, 2022
Code for "FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation".
FPS-Net Code for "FPS-Net: A convolutional fusion network for large-scale LiDAR point cloud segmentation", accepted by ISPRS journal of Photogrammetry
 15 Nov 30, 2022
15 Nov 30, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
87 Jan 5, 2023

Perception-aware multi-sensor fusion for 3D LiDAR semantic segmentation (ICCV 2021)
Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation (ICCV 2021) [中文|EN] 概述 本工作主要探索一种高效的多传感器(激光雷达和摄像头)融合点云语义分割方法。现有的多传感器融合方法主要将点云投影
 126 Dec 30, 2022
126 Dec 30, 2022
METER: Multimodal End-to-end TransformER
METER Code and pre-trained models will be publicized soon. Citation @article{dou2021meter, title={An Empirical Study of Training End-to-End Vision-a
 257 Jan 6, 2023
257 Jan 6, 2023
Repository for Multimodal AutoML Benchmark
Benchmarking Multimodal AutoML for Tabular Data with Text Fields Repository for the NeurIPS 2021 Dataset Track Submission "Benchmarking Multimodal Aut
 44 Nov 24, 2022
44 Nov 24, 2022
[CVPR 2021] NormalFusion: Real-Time Acquisition of Surface Normals for High-Resolution RGB-D Scanning
NormalFusion: Real-Time Acquisition of Surface Normals for High-Resolution RGB-D Scanning Project Page | Paper | Supplemental material #1 | Supplement
 49 Nov 24, 2022
49 Nov 24, 2022