843 Repositories
Python audio-generation Libraries

Official code for CVPR2022 paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
📖 Depth-Aware Generative Adversarial Network for Talking Head Video Generation (CVPR 2022) 🔥 If DaGAN is helpful in your photos/projects, please hel
 503 Jan 4, 2023
503 Jan 4, 2023

Official Pytorch and JAX implementation of "Efficient-VDVAE: Less is more"
The Official Pytorch and JAX implementation of "Efficient-VDVAE: Less is more" Arxiv preprint Louay Hazami · Rayhane Mama · Ragavan Thurairatn
 144 Dec 23, 2022
144 Dec 23, 2022

Rank 3 : Source code for OPPO 6G Data Generation Challenge
OPPO 6G Data Generation with an E2E Framework Homepage of OPPO 6G Data Generation Challenge Datasets H1_32T4R.mat H2_32T4R.mat Please put the original
 97 Jan 7, 2023
97 Jan 7, 2023

Code for CVPR 2022 paper "Bailando: 3D dance generation via Actor-Critic GPT with Choreographic Memory"
Bailando Code for CVPR 2022 (oral) paper "Bailando: 3D dance generation via Actor-Critic GPT with Choreographic Memory" [Paper] | [Project Page] | [Vi
 237 Dec 29, 2022
237 Dec 29, 2022

Pytorch implementation of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Make-A-Scene - PyTorch Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/
 259 Dec 28, 2022
259 Dec 28, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022
Parallel and High-Fidelity Text-to-Lip Generation; AAAI 2022 ; Official code
Parallel and High-Fidelity Text-to-Lip Generation This repository is the official PyTorch implementation of our AAAI-2022 paper, in which we propose P
 77 Dec 21, 2022
77 Dec 21, 2022

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

The official implementation of Autoregressive Image Generation using Residual Quantization (CVPR '22)
Autoregressive Image Generation using Residual Quantization (CVPR 2022) The official implementation of "Autoregressive Image Generation using Residual
 529 Dec 30, 2022
529 Dec 30, 2022
HugsVision is a easy to use huggingface wrapper for state-of-the-art computer vision
HugsVision is an open-source and easy to use all-in-one huggingface wrapper for computer vision. The goal is to create a fast, flexible and user-frien
 166 Nov 27, 2022
166 Nov 27, 2022

Replicating Minecraft World Generation in Python
Minecraft World Generation in Python This is an attempt to replicate Minecraft world generation in Python. This is part of an article published on Med
 159 Dec 19, 2022
159 Dec 19, 2022

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023
Sionna: An Open-Source Library for Next-Generation Physical Layer Research
Sionna: An Open-Source Library for Next-Generation Physical Layer Research Sionna™ is an open-source Python library for link-level simulations of digi
 313 Dec 22, 2022
313 Dec 22, 2022
![[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars](https://github.com/hongfz16/AvatarCLIP/raw/main/assets/tallandskinny_femalesoldier_arguing.gif)
[SIGGRAPH 2022 Journal Track] AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars Fangzhou Hong1* Mingyuan Zhang1* Liang Pan1 Zhongang Cai1,2,3 Lei Yang2
 749 Jan 4, 2023
749 Jan 4, 2023

Official PyTorch implementation of the paper "TEMOS: Generating diverse human motions from textual descriptions"
TEMOS: TExt to MOtionS Generating diverse human motions from textual descriptions Description Official PyTorch implementation of the paper "TEMOS: Gen
 187 Dec 27, 2022
187 Dec 27, 2022
Converts python code into c++ by using OpenAI CODEX.
🦾 codex_py2cpp 🤖 OpenAI Codex Python to C++ Code Generator Your Python Code is too slow? 🐌 You want to speed it up but forgot how to code in C++? ⌨
 423 Jan 1, 2023
423 Jan 1, 2023

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Towards Implicit Text-Guided 3D Shape Generation (CVPR2022)
Towards Implicit Text-Guided 3D Shape Generation Towards Implicit Text-Guided 3D Shape Generation (CVPR2022) Code for the paper [Towards Implicit Text
 55 Dec 16, 2022
55 Dec 16, 2022
Repository for the paper: VoiceMe: Personalized voice generation in TTS
🗣 VoiceMe: Personalized voice generation in TTS Abstract Novel text-to-speech systems can generate entirely new voices that were not seen during trai
 80 Dec 29, 2022
80 Dec 29, 2022
[CVPR 2022] Structured Sparse R-CNN for Direct Scene Graph Generation
Structured Sparse R-CNN for Direct Scene Graph Generation Our paper Structured Sparse R-CNN for Direct Scene Graph Generation has been accepted by CVP
 44 Dec 23, 2022
44 Dec 23, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space"
MotionCLIP Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space". Please visit our webpage for mor
 173 Dec 26, 2022
173 Dec 26, 2022

Implementation of GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation (ICLR 2022).
GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation [OpenReview] [arXiv] [Code] The official implementation of GeoDiff: A Geome
 155 Dec 26, 2022
155 Dec 26, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023

StyleGAN-Human: A Data-Centric Odyssey of Human Generation
StyleGAN-Human: A Data-Centric Odyssey of Human Generation Abstract: Unconditional human image generation is an important task in vision and graphics,
 762 Jan 8, 2023
762 Jan 8, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023

The PyTorch implementation for paper "Neural Texture Extraction and Distribution for Controllable Person Image Synthesis" (CVPR2022 Oral)
ArXiv | Get Start Neural-Texture-Extraction-Distribution The PyTorch implementation for our paper "Neural Texture Extraction and Distribution for Cont
 111 Dec 10, 2022
111 Dec 10, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022
Code for our paper "Graph Pre-training for AMR Parsing and Generation" in ACL2022
AMRBART An implementation for ACL2022 paper "Graph Pre-training for AMR Parsing and Generation". You may find our paper here (Arxiv). Requirements pyt
 60 Jan 3, 2023
60 Jan 3, 2023
Implementation of Retrieval-Augmented Denoising Diffusion Probabilistic Models in Pytorch
Retrieval-Augmented Denoising Diffusion Probabilistic Models (wip) Implementation of Retrieval-Augmented Denoising Diffusion Probabilistic Models in P
 55 Jan 1, 2023
55 Jan 1, 2023
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

This repository contains the data and code for the paper "Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors" (SPNLP@ACL2022)
GP-VAE This repository provides datasets and code for preprocessing, training and testing models for the paper: Diverse Text Generation via Variationa
 18 Dec 29, 2022
18 Dec 29, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022

Author: Wenhao Yu ([email protected]). ACL 2022. Commonsense Reasoning on Knowledge Graph for Text Generation
Diversifying Commonsense Reasoning Generation on Knowledge Graph Introduction -- This is the pytorch implementation of our ACL 2022 paper "Diversifyin
 61 Dec 30, 2022
61 Dec 30, 2022
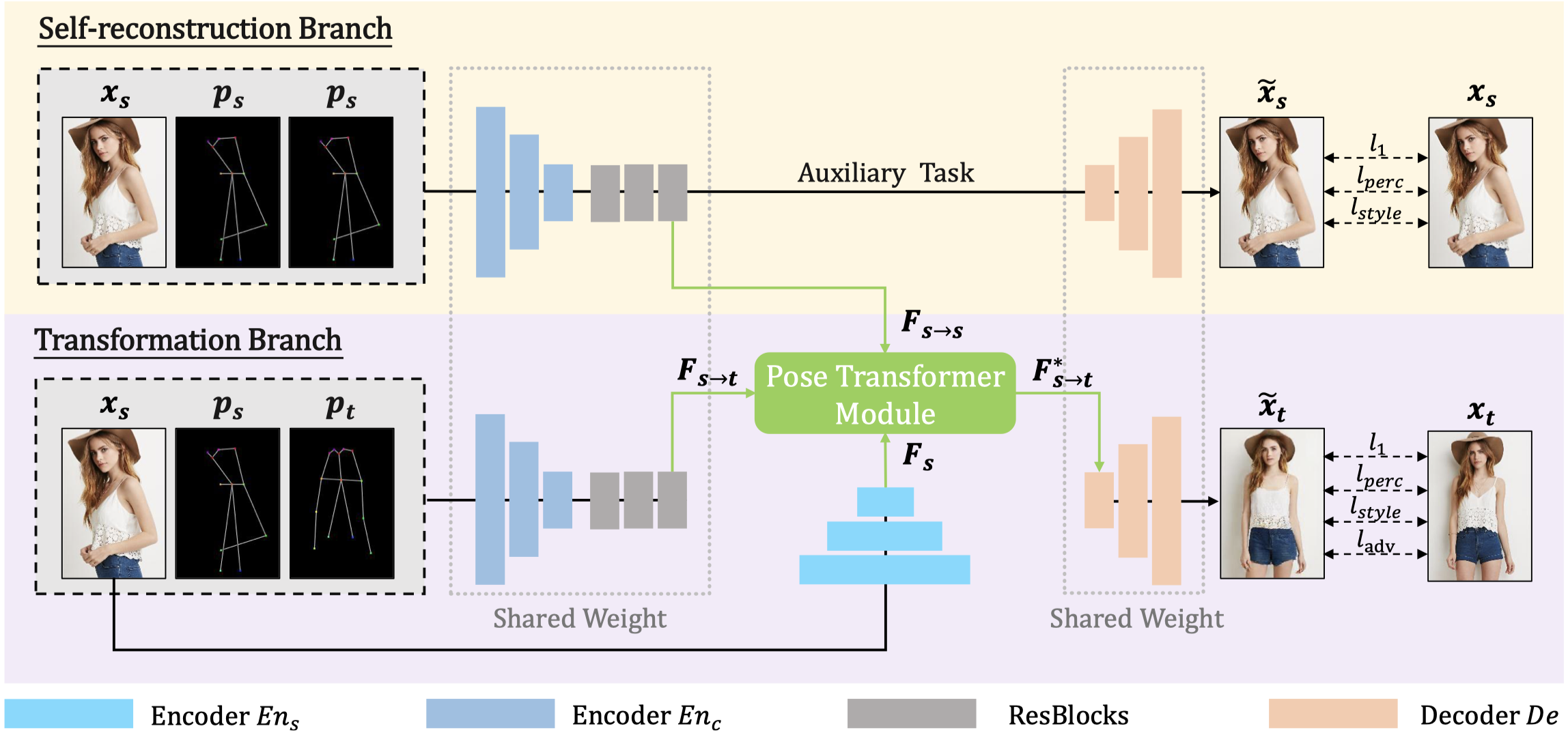
Exploring the Dual-task Correlation for Pose Guided Person Image Generation
Dual-task Pose Transformer Network The source code for our paper "Exploring Dual-task Correlation for Pose Guided Person Image Generation“ (CVPR2022)
 63 Dec 15, 2022
63 Dec 15, 2022
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023

Pdraw - Generate Deterministic, Procedural Artwork from Arbitrary Text
pdraw.py: Generate Deterministic, Procedural Artwork from Arbitrary Text pdraw a
 2 Sep 12, 2022
2 Sep 12, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022

Digan - Official PyTorch implementation of Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
DIGAN (ICLR 2022) Official PyTorch implementation of "Generating Videos with Dyn
 147 Dec 31, 2022
147 Dec 31, 2022
SimCTG - A Contrastive Framework for Neural Text Generation
A Contrastive Framework for Neural Text Generation Authors: Yixuan Su, Tian Lan,
345 Jan 3, 2023

Wordle-solver - Wordle answer generation program in python
🟨 Wordle Solver 🟩 Wordle answer generation program in python ✔️ Requirements U
 4 May 28, 2022
4 May 28, 2022
Image generation API.
Image Generator API This is an api im working on Currently its just a test project Im trying to make custom readme images with your discord account pr
 2 Feb 19, 2022
2 Feb 19, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022

🕹️ Official Implementation of Conditional Motion In-betweening (CMIB) 🏃
Conditional Motion In-Betweening (CMIB) Official implementation of paper: Conditional Motion In-betweeening. Paper(arXiv) | Project Page | YouTube in-
 81 Dec 22, 2022
81 Dec 22, 2022

PyTorch Implementation of our paper Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation
PyTorch Implementation of our paper Explain Me the Painting: Multi-Topic Knowledgeable Art Description Generation
 12 Jul 8, 2022
12 Jul 8, 2022
GT4SD, an open-source library to accelerate hypothesis generation in the scientific discovery process.
The GT4SD (Generative Toolkit for Scientific Discovery) is an open-source platform to accelerate hypothesis generation in the scientific discovery process. It provides a library for making state-of-the-art generative AI models easier to use.
 142 Dec 24, 2022
142 Dec 24, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022
Large-scale Knowledge Graph Construction with Prompting
Large-scale Knowledge Graph Construction with Prompting across tasks (predictive and generative), and modalities (language, image, vision + language, etc.)
 161 Dec 28, 2022
161 Dec 28, 2022
FIRA: Fine-Grained Graph-Based Code Change Representation for Automated Commit Message Generation
FIRA is a learning-based commit message generation approach, which first represents code changes via fine-grained graphs and then learns to generate commit messages automatically.
 21 Dec 30, 2022
21 Dec 30, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
This repository contains the code for Direct Molecular Conformation Generation (DMCG).
Direct Molecular Conformation Generation This repository contains the code for Direct Molecular Conformation Generation (DMCG). Dataset Download rdkit
 25 Dec 20, 2022
25 Dec 20, 2022

Code for ML, domain generation, graph generation of ABC dataset
This is the repository for codes for ML, domain generation, graph generation of Asymmetric Buckling Columns (ABC) dataset in the paper "Learning Mechanically Driven Emergent Behavior with Message Passing Neural Networks".
 0 Jan 28, 2022
0 Jan 28, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression
Regression Transformer Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression . Development se
 27 Jan 5, 2023
27 Jan 5, 2023

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
A collection of Jupyter notebooks to play with NVIDIA's StyleGAN3 and OpenAI's CLIP for a text-based guided image generation.
StyleGAN3 CLIP-based guidance StyleGAN3 + CLIP StyleGAN3 + inversion + CLIP This repo is a collection of Jupyter notebooks made to easily play with St
 176 Dec 30, 2022
176 Dec 30, 2022

Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included.
pixel_character_generator Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included. Dataset TinyHero D
 88 Nov 17, 2022
88 Nov 17, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023

Harmonious Textual Layout Generation over Natural Images via Deep Aesthetics Learning
Harmonious Textual Layout Generation over Natural Images via Deep Aesthetics Learning Code for the paper Harmonious Textual Layout Generation over Nat
 7 Aug 9, 2022
7 Aug 9, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Computer Vision Paper Reviews with Key Summary of paper, End to End Code Practice and Jupyter Notebook converted papers
Computer-Vision-Paper-Reviews Computer Vision Paper Reviews with Key Summary along Papers & Codes. Jonathan Choi 2021 The repository provides 100+ Pap
 2 Mar 17, 2022
2 Mar 17, 2022

Diaformer: Automatic Diagnosis via Symptoms Sequence Generation
Diaformer Diaformer: Automatic Diagnosis via Symptoms Sequence Generation (AAAI 2022) Diaformer is an efficient model for automatic diagnosis via symp
 20 Dec 13, 2022
20 Dec 13, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
2 telegram-bots: for image recognition and for text generation
💻 📱 Telegram_Bots 🔎 & 📖 2 telegram-bots: for image recognition and for text generation. About Image recognition bot: User sends a photo and bot de
 1 Jan 27, 2022
1 Jan 27, 2022
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
Leaf: Multiple-Choice Question Generation
Leaf: Multiple-Choice Question Generation Easy to use and understand multiple-choice question generation algorithm using T5 Transformers. The applicat
 62 Dec 20, 2022
62 Dec 20, 2022

Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network This is the official implementation of
 2 Jul 9, 2022
2 Jul 9, 2022

Which Style Makes Me Attractive? Interpretable Control Discovery and Counterfactual Explanation on StyleGAN
Interpretable Control Exploration and Counterfactual Explanation (ICE) on StyleGAN Which Style Makes Me Attractive? Interpretable Control Discovery an
 11 Dec 1, 2022
11 Dec 1, 2022

CvT2DistilGPT2 is an encoder-to-decoder model that was developed for chest X-ray report generation.
CvT2DistilGPT2 Improving Chest X-Ray Report Generation by Leveraging Warm-Starting This repository houses the implementation of CvT2DistilGPT2 from [1
 21 Dec 28, 2022
21 Dec 28, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022

PCGNN - Procedural Content Generation with NEAT and Novelty
PCGNN - Procedural Content Generation with NEAT and Novelty Generation Approach — Metrics — Paper — Poster — Examples PCGNN - Procedural Content Gener
 8 Dec 10, 2022
8 Dec 10, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022

Leveraging OpenAI's Codex to solve cornerstone problems in Music
Music-Codex Leveraging OpenAI's Codex to solve cornerstone problems in Music Please NOTE: Presented generated samples were created by OpenAI's Codex P
 2 Mar 11, 2022
2 Mar 11, 2022

Instantaneous Motion Generation for Robots and Machines.
Ruckig Instantaneous Motion Generation for Robots and Machines. Ruckig generates trajectories on-the-fly, allowing robots and machines to react instan
 374 Dec 23, 2022
374 Dec 23, 2022
Automatic generation of crypto-arts based on image layers
NFT Generator Автоматическая генерация крипто-артов на основе слоев изображения. Установка pip3 install -r requirements.txt rm -rf result/* Как это ра
 31 Dec 29, 2022
31 Dec 29, 2022

This repository is for our EMNLP 2021 paper "Automated Generation of Accurate & Fluent Medical X-ray Reports"
Introduction: X-Ray Report Generation This repository is for our EMNLP 2021 paper "Automated Generation of Accurate & Fluent Medical X-ray Reports". O
 36 Dec 16, 2022
36 Dec 16, 2022
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation The reference code of Improving Factual Completeness and C
 46 Dec 15, 2022
46 Dec 15, 2022

This project generates news headlines using a Long Short-Term Memory (LSTM) neural network.
News Headlines Generator bunnysaini/Generate-Headlines Goal This project aims to generate news headlines using a Long Short-Term Memory (LSTM) neural
 1 Jan 24, 2022
1 Jan 24, 2022
A tool for retrieving audio in the past
Rewinder A tool for retrieving audio in the past. Ever felt like, I need to remember that discussion which happened 10 min back. Now you can! Rewind a
 1 Jan 24, 2022
1 Jan 24, 2022
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences. Copula and functional Principle Component Analysis (fPCA) are statistical models that allow these properties to be simulated (Joe 2014). As such, copula generated data have shown potential to improve the generalization of machine learning (ML) emulators (Meyer et al. 2021) or anonymize real-data datasets (Patki et al. 2016).
 32 Dec 20, 2022
32 Dec 20, 2022

Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution
Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution Figure: Example visualization of the method and baseline as a
 16 Dec 23, 2022
16 Dec 23, 2022
A simple Python script for generating a variety of hashes from safe urandom entropy.
Hashgen A simple Python script for generating a variety of hashes from safe urandom entropy. For whenever you need a random hash (e.g. generating an a
 1 Feb 17, 2022
1 Feb 17, 2022

Audio2Face - Audio To Face With Python
Audio2Face Discription We create a project that transforms audio to blendshape w
724 Dec 26, 2022
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning My
 3 Apr 10, 2022
3 Apr 10, 2022
Grover is a model for Neural Fake News -- both generation and detectio
Grover is a model for Neural Fake News -- both generation and detection. However, it probably can also be used for other generation tasks.
 856 Dec 24, 2022
856 Dec 24, 2022