628 Repositories
Python class-attention Libraries
Class to connect to XAMPP MySQL Database
MySQL-DB-Connection-Class Class to connect to XAMPP MySQL Database Basta fazer o download o mysql_connect.py e modificar os parâmetros que quiser. E d
 4 Jul 12, 2021
4 Jul 12, 2021
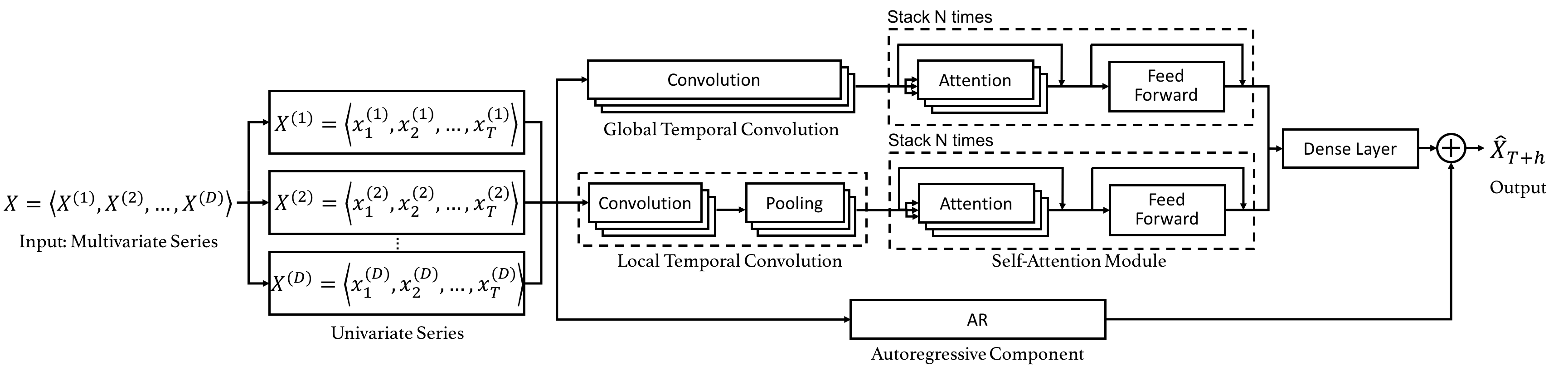
Code for the CIKM 2019 paper "DSANet: Dual Self-Attention Network for Multivariate Time Series Forecasting".
Dual Self-Attention Network for Multivariate Time Series Forecasting 20.10.26 Update: Due to the difficulty of installation and code maintenance cause
 223 Dec 16, 2022
223 Dec 16, 2022

Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement (NeurIPS 2020)
MTTS-CAN: Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement Paper Xin Liu, Josh Fromm, Shwetak Patel, Daniel M
 106 Dec 30, 2022
106 Dec 30, 2022
convert a dict-list object from / to a typed object(class instance with type annotation)
objtyping 带类型定义的对象转换器 由来 Python不是强类型语言,开发人员没有给数据定义类型的习惯。这样虽然灵活,但处理复杂业务逻辑的时候却不够方便——缺乏类型检查可能导致很难发现错误,在IDE里编码时也没
 15 Dec 22, 2022
15 Dec 22, 2022

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022

Shared Attention for Multi-label Zero-shot Learning
Shared Attention for Multi-label Zero-shot Learning Overview This repository contains the implementation of Shared Attention for Multi-label Zero-shot
 26 Dec 14, 2022
26 Dec 14, 2022

codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification
DLCF-DCA codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification. submitted t
 15 Aug 30, 2022
15 Aug 30, 2022
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks This is our implementation for the paper: FinGAT: A Financial Graph At
 64 Dec 13, 2022
64 Dec 13, 2022
MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data
This repository is the official PyTorch implementation of Meta-Balance. Find the paper on arxiv MetaBalance: High-Performance Neural Networks for Clas
 20 Oct 18, 2021
20 Oct 18, 2021
Neighborhood Contrastive Learning for Novel Class Discovery
Neighborhood Contrastive Learning for Novel Class Discovery This repository contains the official implementation of our paper: Neighborhood Contrastiv
 56 Dec 9, 2022
56 Dec 9, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

LieTransformer: Equivariant Self-Attention for Lie Groups
LieTransformer This repository contains the implementation of the LieTransformer used for experiments in the paper LieTransformer: Equivariant Self-At
 50 Dec 28, 2022
50 Dec 28, 2022

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
 72 Dec 19, 2022
72 Dec 19, 2022

Shuffle Attention for MobileNetV3
SA-MobileNetV3 Shuffle Attention for MobileNetV3 Train Run the following command for train model on your own dataset: python train.py --dataset mnist
 36 Dec 28, 2022
36 Dec 28, 2022
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network This repo contains the official Pytorch implementaion code and conf
 175 Jan 7, 2023
175 Jan 7, 2023
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
 192 Dec 23, 2022
192 Dec 23, 2022
FANet - Real-time Semantic Segmentation with Fast Attention
FANet Real-time Semantic Segmentation with Fast Attention Ping Hu, Federico Perazzi, Fabian Caba Heilbron, Oliver Wang, Zhe Lin, Kate Saenko , Stan Sc
 42 Nov 30, 2022
42 Nov 30, 2022
Code for weakly supervised segmentation of a single class
SingleClassRL Implementation of weak single object segmentation from paper "Regularized Loss for Weakly Supervised Single Class Semantic Segmentation"
 16 Nov 14, 2022
16 Nov 14, 2022

Official implement of "CAT: Cross Attention in Vision Transformer".
CAT: Cross Attention in Vision Transformer This is official implement of "CAT: Cross Attention in Vision Transformer". Abstract Since Transformer has
 100 Dec 15, 2022
100 Dec 15, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023

The official PyTorch implementation of recent paper - SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
This repository is the official PyTorch implementation of SAINT. Find the paper on arxiv SAINT: Improved Neural Networks for Tabular Data via Row Atte
 284 Dec 21, 2022
284 Dec 21, 2022
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time.
 360 Dec 28, 2022
360 Dec 28, 2022

Unofficial PyTorch implementation of Attention Free Transformer (AFT) layers by Apple Inc.
aft-pytorch Unofficial PyTorch implementation of Attention Free Transformer's layers by Zhai, et al. [abs, pdf] from Apple Inc. Installation You can i
 184 Dec 12, 2022
184 Dec 12, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022
What Do Deep Nets Learn? Class-wise Patterns Revealed in the Input Space
What Do Deep Nets Learn? Class-wise Patterns Revealed in the Input Space Introduction: Environment: Python3.6.5, PyTorch1.5.0 Dataset: CIFAR-10, Image
 8 Mar 23, 2022
8 Mar 23, 2022
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 EAMLP will come soon Jitto
 357 Dec 11, 2022
357 Dec 11, 2022

Code for the paper "How Attentive are Graph Attention Networks?"
How Attentive are Graph Attention Networks? This repository is the official implementation of How Attentive are Graph Attention Networks?. The PyTorch
 175 Dec 29, 2022
175 Dec 29, 2022

Attention-driven Robot Manipulation (ARM) which includes Q-attention
Attention-driven Robotic Manipulation (ARM) This codebase is home to: Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation I
 84 Dec 29, 2022
84 Dec 29, 2022
Implements MLP-Mixer: An all-MLP Architecture for Vision.
MLP-Mixer-CIFAR10 This repository implements MLP-Mixer as proposed in MLP-Mixer: An all-MLP Architecture for Vision. The paper introduces an all MLP (
 51 Jan 4, 2023
51 Jan 4, 2023

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022
An implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks in PyTorch.
Neural Attention Distillation This is an implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep
 84 Jan 4, 2023
84 Jan 4, 2023

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
12.6k Jan 9, 2023
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022
The implementation of the algorithm in the paper "Safe Deep Semi-Supervised Learning for Unseen-Class Unlabeled Data" published in ICML 2020.
DS3L This is the code for paper "Safe Deep Semi-Supervised Learning for Unseen-Class Unlabeled Data" published in ICML 2020. Setups The code is implem
 36 Oct 19, 2022
36 Oct 19, 2022
Official implementation for (Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching, AAAI-2021)
Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching Official pytorch implementation of "Show, Attend and Distill: Kn
 80 Dec 16, 2022
80 Dec 16, 2022

Deep functional residue identification
DeepFRI Deep functional residue identification Citing @article {Gligorijevic2019, author = {Gligorijevic, Vladimir and Renfrew, P. Douglas and Koscio
 156 Dec 25, 2022
156 Dec 25, 2022
Local Attention - Flax module for Jax
Local Attention - Flax Autoregressive Local Attention - Flax module for Jax Install $ pip install local-attention-flax Usage from jax import random fr
16 Jun 16, 2022
Implementation of Bidirectional Recurrent Independent Mechanisms (Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules)
BRIMs Bidirectional Recurrent Independent Mechanisms Implementation of the paper Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neura
 26 May 26, 2022
26 May 26, 2022
PyTorch code for our paper "Attention in Attention Network for Image Super-Resolution"
Under construction... Attention in Attention Network for Image Super-Resolution (A2N) This repository is an PyTorch implementation of the paper "Atten
 71 Dec 30, 2022
71 Dec 30, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
 170 Dec 27, 2022
170 Dec 27, 2022
Contains code for the paper "Vision Transformers are Robust Learners".
Vision Transformers are Robust Learners This repository contains the code for the paper Vision Transformers are Robust Learners by Sayak Paul* and Pin
103 Jan 5, 2023

Drone-based Joint Density Map Estimation, Localization and Tracking with Space-Time Multi-Scale Attention Network
DroneCrowd Paper Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark. Introduction This paper proposes a space-time multi-scale atte
 98 Nov 16, 2022
98 Nov 16, 2022
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 Jittor code will come soon
357 Dec 11, 2022
My sister is a GR of her class. She had to mark attendance of students from screenshots of teams meeting on an excel sheet. I resolved her problem by reading names from screenshots using PyTesseract and marking them present on the excel using Pandas in Python. It took me 1hr to write the code and it is saving half an hour everyday.
auto-team-attandance Don't judge the code, this is not the best way to write code. I was learning tkinter that is why GUI is bad. Here's the Mega link
 25 Sep 4, 2022
25 Sep 4, 2022

Exploring whether attention is necessary for vision transformers
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet Paper/Report TL;DR We replace the attention layer in a v
 461 Jan 7, 2023
461 Jan 7, 2023

Reformer, the efficient Transformer, in Pytorch
Reformer, the Efficient Transformer, in Pytorch This is a Pytorch implementation of Reformer https://openreview.net/pdf?id=rkgNKkHtvB It includes LSH
1.8k Dec 30, 2022

Twins: Revisiting the Design of Spatial Attention in Vision Transformers
Twins: Revisiting the Design of Spatial Attention in Vision Transformers Very recently, a variety of vision transformer architectures for dense predic
 482 Dec 18, 2022
482 Dec 18, 2022
Reimplementation of the paper `Human Attention Maps for Text Classification: Do Humans and Neural Networks Focus on the Same Words? (ACL2020)`
Human Attention for Text Classification Re-implementation of the paper Human Attention Maps for Text Classification: Do Humans and Neural Networks Foc
 15 Dec 13, 2021
15 Dec 13, 2021
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
Sequence-to-sequence framework with a focus on Neural Machine Translation based on Apache MXNet
 1000 Apr 19, 2021
1000 Apr 19, 2021

Implementation of Convolutional enhanced image Transformer
CeiT : Convolutional enhanced image Transformer This is an unofficial PyTorch implementation of Incorporating Convolution Designs into Visual Transfor
82 Dec 13, 2022

Implementation of Perceiver, General Perception with Iterative Attention in TensorFlow
Perceiver This Python package implements Perceiver: General Perception with Iterative Attention by Andrew Jaegle in TensorFlow. This model builds on t
 84 Oct 15, 2022
84 Oct 15, 2022
The official pytorch implementation of our paper "Is Space-Time Attention All You Need for Video Understanding?"
TimeSformer This is an official pytorch implementation of Is Space-Time Attention All You Need for Video Understanding?. In this repository, we provid
1k Dec 31, 2022
Neural style transfer as a class in PyTorch
pt-styletransfer Neural style transfer as a class in PyTorch Based on: https://github.com/alexis-jacq/Pytorch-Tutorials Adds: StyleTransferNet as a cl
 31 Jun 27, 2022
31 Jun 27, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022

Implementation of Cross Transformer for spatially-aware few-shot transfer, in Pytorch
Cross Transformers - Pytorch (wip) Implementation of Cross Transformer for spatially-aware few-shot transfer, in Pytorch Install $ pip install cross-t
40 Dec 22, 2022

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
Implementation of TransGanFormer, an all-attention GAN that combines the finding from the recent GanFormer and TransGan paper
TransGanFormer (wip) Implementation of TransGanFormer, an all-attention GAN that combines the finding from the recent GansFormer and TransGan paper. I
146 Dec 6, 2022

Official PyTorch implementation for Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers, a novel method to visualize any Transformer-based network. Including examples for DETR, VQA.
PyTorch Implementation of Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers 1 Using Colab Please notic
 489 Jan 7, 2023
489 Jan 7, 2023
Code for the paper "Graph Attention Tracking". (CVPR2021)
SiamGAT 1. Environment setup This code has been tested on Ubuntu 16.04, Python 3.5, Pytorch 1.2.0, CUDA 9.0. Please install related libraries before r
 122 Dec 24, 2022
122 Dec 24, 2022

Implementation of the Swin Transformer in PyTorch.
Swin Transformer - PyTorch Implementation of the Swin Transformer architecture. This paper presents a new vision Transformer, called Swin Transformer,
 597 Jan 3, 2023
597 Jan 3, 2023

Implementation of STAM (Space Time Attention Model), a pure and simple attention model that reaches SOTA for video classification
STAM - Pytorch Implementation of STAM (Space Time Attention Model), yet another pure and simple SOTA attention model that bests all previous models in
109 Dec 28, 2022
Implementation of LambdaNetworks, a new approach to image recognition that reaches SOTA with less compute
Lambda Networks - Pytorch Implementation of λ Networks, a new approach to image recognition that reaches SOTA on ImageNet. The new method utilizes λ l
1.5k Jan 7, 2023

An implementation of Performer, a linear attention-based transformer, in Pytorch
Performer - Pytorch An implementation of Performer, a linear attention-based transformer variant with a Fast Attention Via positive Orthogonal Random
900 Dec 22, 2022
Reformer, the efficient Transformer, in Pytorch
Reformer, the Efficient Transformer, in Pytorch This is a Pytorch implementation of Reformer https://openreview.net/pdf?id=rkgNKkHtvB It includes LSH
1.8k Jan 6, 2023
git《Self-Attention Attribution: Interpreting Information Interactions Inside Transformer》(AAAI 2021) GitHub:
Self-Attention Attribution This repository contains the implementation for AAAI-2021 paper Self-Attention Attribution: Interpreting Information Intera
 60 Dec 29, 2022
60 Dec 29, 2022

The open source code of SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation.
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation(ICPR 2020) Overview This code is for the paper: Spatial Attention U-Net for Retinal V
 151 Dec 28, 2022
151 Dec 28, 2022

Implementation of the 😇 Attention layer from the paper, Scaling Local Self-Attention For Parameter Efficient Visual Backbones
HaloNet - Pytorch Implementation of the Attention layer from the paper, Scaling Local Self-Attention For Parameter Efficient Visual Backbones. This re
189 Nov 22, 2022
Visual Attention based OCR
Attention-OCR Authours: Qi Guo and Yuntian Deng Visual Attention based OCR. The model first runs a sliding CNN on the image (images are resized to hei
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
A Tensorflow model for text recognition (CNN + seq2seq with visual attention) available as a Python package and compatible with Google Cloud ML Engine.
Attention-based OCR Visual attention-based OCR model for image recognition with additional tools for creating TFRecords datasets and exporting the tra
 933 Dec 29, 2022
933 Dec 29, 2022
🖺 OCR using tensorflow with attention
tensorflow-ocr 🖺 OCR using tensorflow with attention, batteries included Installation git clone --recursive http://github.com/pannous/tensorflow-ocr
 646 Nov 11, 2022
646 Nov 11, 2022

Single Shot Text Detector with Regional Attention
Single Shot Text Detector with Regional Attention Introduction SSTD is initially described in our ICCV 2017 spotlight paper. A third-party implementat
 215 Dec 7, 2022
215 Dec 7, 2022
Implement 'Single Shot Text Detector with Regional Attention, ICCV 2017 Spotlight'
SSTDNet Implement 'Single Shot Text Detector with Regional Attention, ICCV 2017 Spotlight' using pytorch. This code is work for general object detecti
 84 Jan 5, 2022
84 Jan 5, 2022

textspotter - An End-to-End TextSpotter with Explicit Alignment and Attention
An End-to-End TextSpotter with Explicit Alignment and Attention This is initially described in our CVPR 2018 paper. Getting Started Installation Clone
 323 Nov 10, 2022
323 Nov 10, 2022

Pytorch implementation of PSEnet with Pyramid Attention Network as feature extractor
Scene Text-Spotting based on PSEnet+CRNN Pytorch implementation of an end to end Text-Spotter with a PSEnet text detector and CRNN text recognizer. We
 62 Oct 10, 2022
62 Oct 10, 2022

MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition
MORAN: A Multi-Object Rectified Attention Network for Scene Text Recognition Python 2.7 Python 3.6 MORAN is a network with rectification mechanism for
 595 Dec 27, 2022
595 Dec 27, 2022
Adaptive Attention Span for Reinforcement Learning
Adaptive Transformers in RL Official implementation of Adaptive Transformers in RL In this work we replicate several results from Stabilizing Transfor
 100 Nov 15, 2022
100 Nov 15, 2022

CVPR 2021: "Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE"
Diverse Structure Inpainting ArXiv | Papar | Supplementary Material | BibTex This repository is for the CVPR 2021 paper, "Generating Diverse Structure
 152 Nov 4, 2022
152 Nov 4, 2022
![[ICLR 2021] Is Attention Better Than Matrix Decomposition?](https://github.com/Gsunshine/Enjoy-Hamburger/raw/main/assets/Hamburger.jpg)
[ICLR 2021] Is Attention Better Than Matrix Decomposition?
Enjoy-Hamburger 🍔 Official implementation of Hamburger, Is Attention Better Than Matrix Decomposition? (ICLR 2021) Under construction. Introduction T
 271 Dec 29, 2022
271 Dec 29, 2022

Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
Implementation / replication of DALL-E, OpenAI's Text to Image Transformer, in Pytorch
5k Jan 2, 2023
Official implementation of Self-supervised Graph Attention Networks (SuperGAT), ICLR 2021.
SuperGAT Official implementation of Self-supervised Graph Attention Networks (SuperGAT). This model is presented at How to Find Your Friendly Neighbor
 127 Dec 28, 2022
127 Dec 28, 2022

Object-Centric Learning with Slot Attention
Slot Attention This is a re-implementation of "Object-Centric Learning with Slot Attention" in PyTorch (https://arxiv.org/abs/2006.15055). Requirement
 72 Jan 2, 2023
72 Jan 2, 2023

Code for our CVPR2021 paper coordinate attention
Coordinate Attention for Efficient Mobile Network Design (preprint) This repository is a PyTorch implementation of our coordinate attention (will appe
 726 Jan 5, 2023
726 Jan 5, 2023

Implementation of Perceiver, General Perception with Iterative Attention, in Pytorch
Perceiver - Pytorch Implementation of Perceiver, General Perception with Iterative Attention, in Pytorch Install $ pip install perceiver-pytorch Usage
876 Dec 29, 2022
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
 1.4k Dec 22, 2022
1.4k Dec 22, 2022

Implementation of OmniNet, Omnidirectional Representations from Transformers, in Pytorch
Omninet - Pytorch Implementation of OmniNet, Omnidirectional Representations from Transformers, in Pytorch. The authors propose that we should be atte
48 Nov 21, 2022
GANsformer: Generative Adversarial Transformers Drew A
GANsformer: Generative Adversarial Transformers Drew A. Hudson* & C. Lawrence Zitnick *I wish to thank Christopher D. Manning for the fruitf
 1.2k Jan 2, 2023
1.2k Jan 2, 2023

Implementation of Transformer in Transformer, pixel level attention paired with patch level attention for image classification, in Pytorch
Transformer in Transformer Implementation of Transformer in Transformer, pixel level attention paired with patch level attention for image c
272 Dec 23, 2022
An attempt at the implementation of Glom, Geoffrey Hinton's new idea that integrates neural fields, predictive coding, top-down-bottom-up, and attention (consensus between columns)
GLOM - Pytorch (wip) An attempt at the implementation of Glom, Geoffrey Hinton's new idea that integrates neural fields, predictive coding,
173 Dec 14, 2022
Implementation of E(n)-Transformer, which extends the ideas of Welling's E(n)-Equivariant Graph Neural Network to attention
E(n)-Equivariant Transformer (wip) Implementation of E(n)-Equivariant Transformer, which extends the ideas from Welling's E(n)-Equivariant G
132 Jan 2, 2023
A simple scheduler tool that provides desktop notifications about classes and opens their meet links in the browser automatically at the start of the class.
This application provides desktop notifications about classes and opens their meet links in browser automatically at the start of the class.
 14 Jun 29, 2022
14 Jun 29, 2022

Pytorch Code for "Medical Transformer: Gated Axial-Attention for Medical Image Segmentation"
Medical-Transformer Pytorch Code for the paper "Medical Transformer: Gated Axial-Attention for Medical Image Segmentation" About this repo: This repo
 615 Dec 25, 2022
615 Dec 25, 2022
A Python class for controlling the Pimoroni RGB Keypad for Raspberry Pi Pico
rgbkeypad A Python class for controlling the Pimoroni RGB Keypad for the Raspberry Pi Pico. Compatible with MicroPython and CircuitPython. keypad = RG
 43 Nov 11, 2022
43 Nov 11, 2022

Implementation of TimeSformer, a pure attention-based solution for video classification
TimeSformer - Pytorch Implementation of TimeSformer, a pure and simple attention-based solution for reaching SOTA on video classification.
602 Jan 3, 2023

Implementation of Nyström Self-attention, from the paper Nyströmformer
Nyström Attention Implementation of Nyström Self-attention, from the paper Nyströmformer. Yannic Kilcher video Install $ pip install nystrom-attention
95 Jan 2, 2023
The first machine learning framework that encourages learning ML concepts instead of memorizing class functions.
SeaLion is designed to teach today's aspiring ml-engineers the popular machine learning concepts of today in a way that gives both intuition and ways of application. We do this through concise algorithms that do the job in the least jargon possible and examples to guide you through every step of the way.
 324 Dec 27, 2022
324 Dec 27, 2022
MiniJVM is simple java virtual machine written by python language, it can load class file from file system and run it.
MiniJVM MiniJVM是一款使用python编写的简易JVM,能够从本地加载class文件并且执行绝大多数指令。 支持的功能 1.从本地磁盘加载class并解析 2.支持绝大多数指令集的执行 3.支持虚拟机内存分区以及对象的创建 4.支持方法的调用和参数传递 5.支持静态代码块的初始化 不支
 60 Apr 1, 2022
60 Apr 1, 2022

Implementation of self-attention mechanisms for general purpose. Focused on computer vision modules. Ongoing repository.
Self-attention building blocks for computer vision applications in PyTorch Implementation of self attention mechanisms for computer vision in PyTorch
 962 Dec 23, 2022
962 Dec 23, 2022
计算机视觉中用到的注意力模块和其他即插即用模块PyTorch Implementation Collection of Attention Module and Plug&Play Module
PyTorch实现多种计算机视觉中网络设计中用到的Attention机制,还收集了一些即插即用模块。由于能力有限精力有限,可能很多模块并没有包括进来,有任何的建议或者改进,可以提交issue或者进行PR。
 599 Dec 23, 2022
599 Dec 23, 2022