3466 Repositories
Python data-pre-processing Libraries
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
 65 Sep 13, 2022
65 Sep 13, 2022

Python ELT Studio, an application for building ELT (and ETL) data flows.
The Python Extract, Load, Transform Studio is an application for performing ELT (and ETL) tasks. Under the hood the application consists of a two parts.
 55 Nov 18, 2022
55 Nov 18, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
 332 Dec 18, 2022
332 Dec 18, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
Test django schema and data migrations, including migrations' order and best practices.
django-test-migrations Features Allows to test django schema and data migrations Allows to test both forward and rollback migrations Allows to test th
 382 Dec 27, 2022
382 Dec 27, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022

A light-weight image labelling tool for Python designed for creating segmentation data sets.
An image labelling tool for creating segmentation data sets, for Django and Flask.
 117 Nov 21, 2022
117 Nov 21, 2022
Download history data from binance and save to dataframe or csv file
Binance history data downloader Download history data from binance and save to dataframe or csv file
 10 Dec 2, 2022
10 Dec 2, 2022

Slack bot for monitoring your Metaflow flows!
Metaflowbot - Slack Bot for your Metaflow flows! Metaflowbot makes it fun and easy to monitor your Metaflow runs, past and present. Imagine starting a
 21 Dec 7, 2022
21 Dec 7, 2022
Creates a C array from a hex-string or a stream of binary data.
hex2array-c Creates a C array from a hex-string. Usage Usage: python3 hex2array_c.py HEX_STRING [-h|--help] Use '-' to read the hex string from STDIN.
 3 Nov 24, 2022
3 Nov 24, 2022
Implementation of "Selection via Proxy: Efficient Data Selection for Deep Learning" from ICLR 2020.
Selection via Proxy: Efficient Data Selection for Deep Learning This repository contains a refactored implementation of "Selection via Proxy: Efficien
 70 Nov 16, 2022
70 Nov 16, 2022
Data from "HateCheck: Functional Tests for Hate Speech Detection Models" (Röttger et al., ACL 2021)
In this repo, you can find the data from our ACL 2021 paper "HateCheck: Functional Tests for Hate Speech Detection Models". "test_suite_cases.csv" con
 43 Nov 11, 2022
43 Nov 11, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

Codes for processing meeting summarization datasets AMI and ICSI.
Meeting Summarization Dataset Meeting plays an essential part in our daily life, which allows us to share information and collaborate with others. Wit
 39 Dec 14, 2022
39 Dec 14, 2022

esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch.
esguard esguard provides a Python decorator that waits for processing while monitoring the load of Elasticsearch. Quick Start You need to launch elast
 5 Dec 8, 2021
5 Dec 8, 2021

Amazon Scraper: A command-line tool for scraping Amazon product data
Amazon Product Scraper: 2021 Description A command-line tool for scraping Amazon product data to CSV or JSON format(s). Requirements Python 3 pip3 Ins
 49 Nov 15, 2021
49 Nov 15, 2021

A Data Annotation Tool for Semantic Segmentation, Object Detection and Lane Line Detection.(In Development Stage)
Data-Annotation-Tool How to Run this Tool? To run this software, follow the steps: git clone https://github.com/Autonomous-Car-Project/Data-Annotation
 13 Aug 18, 2022
13 Aug 18, 2022
Scraping Thailand COVID-19 data from the DDC's tableau dashboard
Scraping COVID-19 data from DDC Dashboard Scraping Thailand COVID-19 data from the DDC's tableau dashboard. Data is updated at 07:30 and 08:00 daily.
 5 Jan 4, 2022
5 Jan 4, 2022
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN
DenseClus is a Python module for clustering mixed type data using UMAP and HDBSCAN. Allowing for both categorical and numerical data, DenseClus makes it possible to incorporate all features in clustering.
 53 Dec 8, 2022
53 Dec 8, 2022
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
ml4h is a toolkit for machine learning on clinical data of all kinds including genetics, labs, imaging, clinical notes, and more
 65 Dec 20, 2022
65 Dec 20, 2022

Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation
Implicit Internal Video Inpainting Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation paper | project
 202 Dec 30, 2022
202 Dec 30, 2022
This repository is home to the Optimus data transformation plugins for various data processing needs.
Transformers Optimus's transformation plugins are implementations of Task and Hook interfaces that allows execution of arbitrary jobs in optimus. To i
 37 Dec 14, 2022
37 Dec 14, 2022

Minimal Ethereum fee data viewer for the terminal, contained in a single python script.
Minimal Ethereum fee data viewer for the terminal, contained in a single python script. Connects to your node and displays some metrics in real-time.
 48 Dec 5, 2022
48 Dec 5, 2022

This solution helps you deploy Data Lake Infrastructure on AWS using CDK Pipelines.
CDK Pipelines for Data Lake Infrastructure Deployment This solution helps you deploy data lake infrastructure on AWS using CDK Pipelines. This is base
 66 Nov 23, 2022
66 Nov 23, 2022

Google Project: Search and auto-complete sentences within given input text files, manipulating data with complex data-structures.
Auto-Complete Google Project In this project there is an implementation for one feature of Google's search engines - AutoComplete. Autocomplete, or wo
 10 Jun 20, 2022
10 Jun 20, 2022
[ICCV, 2021] Cloud Transformers: A Universal Approach To Point Cloud Processing Tasks
Cloud Transformers: A Universal Approach To Point Cloud Processing Tasks This is an official PyTorch code repository of the paper "Cloud Transformers:
 27 Dec 15, 2022
27 Dec 15, 2022
This repository contains data used in the NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deployment in Text to Speech Systems
Proteno This is the data release associated with the corresponding NAACL 2021 Paper - Proteno: Text Normalization with Limited Data for Fast Deploymen
 37 Dec 4, 2022
37 Dec 4, 2022

Data and Code for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning"
Introduction Code and data for ACL 2021 Paper "Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning". We cons
 81 Dec 27, 2022
81 Dec 27, 2022
OpenGAN: Open-Set Recognition via Open Data Generation
OpenGAN: Open-Set Recognition via Open Data Generation ICCV 2021 (oral) Real-world machine learning systems need to analyze novel testing data that di
 90 Jan 6, 2023
90 Jan 6, 2023
PyTorch implementation of the Transformer in Post-LN (Post-LayerNorm) and Pre-LN (Pre-LayerNorm).
Transformer-PyTorch A PyTorch implementation of the Transformer from the paper Attention is All You Need in both Post-LN (Post-LayerNorm) and Pre-LN (
 22 Feb 27, 2022
22 Feb 27, 2022
Code release for our paper, "SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo"
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo Thomas Kollar, Michael Laskey, Kevin Stone, Brijen Thananjeyan
 68 Dec 14, 2022
68 Dec 14, 2022
MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space
Update (20 Jan 2020): MODALS on text data is avialable MODALS MODALS: Modality-agnostic Automated Data Augmentation in the Latent Space Table of Conte
 38 Dec 15, 2022
38 Dec 15, 2022
A PyTorch implementation of Radio Transformer Networks from the paper "An Introduction to Deep Learning for the Physical Layer".
An Introduction to Deep Learning for the Physical Layer An usable PyTorch implementation of the noisy autoencoder infrastructure in the paper "An Intr
 120 Nov 21, 2022
120 Nov 21, 2022

performing moving objects segmentation using image processing techniques with opencv and numpy
Moving Objects Segmentation On this project I tried to perform moving objects segmentation using background subtraction technique. the introduced meth
 15 Dec 12, 2022
15 Dec 12, 2022
Extract Thailand COVID-19 Cluster data from daily briefing pdf.
Thailand COVID-19 Cluster Data Extraction About Extract Clusters from Thailand Daily COVID-19 briefing PDF Download latest data Here. Data will be upd
5 Sep 27, 2021
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

Evidently helps analyze machine learning models during validation or production monitoring
Evidently helps analyze machine learning models during validation or production monitoring. The tool generates interactive visual reports and JSON profiles from pandas DataFrame or csv files. Currently 6 reports are available.
 3.1k Jan 7, 2023
3.1k Jan 7, 2023

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
1.1k Dec 17, 2022
Collect super-resolution related papers, data, repositories
Collect super-resolution related papers, data, repositories
 1.7k Jan 3, 2023
1.7k Jan 3, 2023
Active learning for text classification in Python
Active Learning allows you to efficiently label training data in a small-data scenario.
 375 Dec 28, 2022
375 Dec 28, 2022
Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in order to find the highest performing cryptocurrencies historically
crypto-performance-tracker Use this script to track the gains of cryptocurrencies using historical data and display it on a super-imposed chart in ord
 25 Aug 31, 2022
25 Aug 31, 2022
Automated data scraper for Thailand COVID-19 data
The Researcher COVID data Automated data scraper for Thailand COVID-19 data Accessing the Data 1st Dose Provincial Vaccination Data 2nd Dose Provincia
 31 Apr 17, 2022
31 Apr 17, 2022

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Image Deblurring using Generative Adversarial Networks
DeblurGAN arXiv Paper Version Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. Our netwo
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Random Erasing Data Augmentation. Experiments on CIFAR10, CIFAR100 and Fashion-MNIST
Random Erasing Data Augmentation =============================================================== black white random This code has the source code for
 654 Dec 26, 2022
654 Dec 26, 2022
This repository contains the source code and data for reproducing results of Deep Continuous Clustering paper
Deep Continuous Clustering Introduction This is a Pytorch implementation of the DCC algorithms presented in the following paper (paper): Sohil Atul Sh
 197 Nov 29, 2022
197 Nov 29, 2022

PyTorch implementation of the wavelet analysis from Torrence & Compo
Continuous Wavelet Transforms in PyTorch This is a PyTorch implementation for the wavelet analysis outlined in Torrence and Compo (BAMS, 1998). The co
 262 Dec 21, 2022
262 Dec 21, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files. Mdformat is a Unix-style command-line tool as well as a Python library.
 180 Jan 6, 2023
180 Jan 6, 2023

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

NLPShala , the best IDE for all Natural language processing tasks.
The revolutionary IDE for all NLP (Natural language processing) stuffs on the internet.
 3 Aug 8, 2021
3 Aug 8, 2021
A curated list of amazingly awesome Cybersecurity datasets
A curated list of amazingly awesome Cybersecurity datasets
 758 Dec 28, 2022
758 Dec 28, 2022

A python application for manipulating pandas data frames from the comfort of your web browser
A python application for manipulating pandas data frames from the comfort of your web browser. Data flows are represented as a Directed Acyclic Graph, and nodes can be ran individually as the user sees fit.
161 Jan 4, 2023
Write reproducible code for getting and processing ChEMBL
chembl_downloader Don't worry about downloading/extracting ChEMBL or versioning - just use chembl_downloader to write code that knows how to download
 34 Dec 25, 2022
34 Dec 25, 2022

Code release for "Self-Tuning for Data-Efficient Deep Learning" (ICML 2021)
Self-Tuning for Data-Efficient Deep Learning This repository contains the implementation code for paper: Self-Tuning for Data-Efficient Deep Learning
 101 Dec 11, 2022
101 Dec 11, 2022
MoviePy is a Python library for video editing, can read and write all the most common audio and video formats
MoviePy is a Python library for video editing: cutting, concatenations, title insertions, video compositing (a.k.a. non-linear editing), video processing, and creation of custom effects. See the gallery for some examples of use.
 10k Jan 8, 2023
10k Jan 8, 2023

Anomaly detection on SQL data warehouses and databases
With CueObserve, you can run anomaly detection on data in your SQL data warehouses and databases. Getting Started Install via Docker docker run -p 300
 171 Dec 18, 2022
171 Dec 18, 2022
IDRLnet, a Python toolbox for modeling and solving problems through Physics-Informed Neural Network (PINN) systematically.
IDRLnet IDRLnet is a machine learning library on top of PyTorch. Use IDRLnet if you need a machine learning library that solves both forward and inver
 105 Dec 17, 2022
105 Dec 17, 2022

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
Implementation of PyTorch-based multi-task pre-trained models
mtdp Library containing implementation related to the research paper "Multi-task pre-training of deep neural networks for digital pathology" (Mormont
 27 Oct 14, 2022
27 Oct 14, 2022

ICML 21 - Voice2Series: Reprogramming Acoustic Models for Time Series Classification
Voice2Series-Reprogramming Voice2Series: Reprogramming Acoustic Models for Time Series Classification International Conference on Machine Learning (IC
 49 Jan 3, 2023
49 Jan 3, 2023
![[IJCAI-2021] A benchmark of data-free knowledge distillation from paper](https://github.com/zju-vipa/DataFree/raw/main/assets/cmi.png)
[IJCAI-2021] A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation"
DataFree A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation" Authors: Gongfa
 47 Jan 9, 2023
47 Jan 9, 2023
Deduplicating Training Data Makes Language Models Better
Deduplicating Training Data Makes Language Models Better This repository contains code to deduplicate language model datasets as descrbed in the paper
 431 Dec 27, 2022
431 Dec 27, 2022
[ICML 2021] Towards Understanding and Mitigating Social Biases in Language Models
Towards Understanding and Mitigating Social Biases in Language Models This repo contains code and data for evaluating and mitigating bias from generat
 42 Jan 3, 2023
42 Jan 3, 2023
Code release for our paper, "SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo"
SimNet: Enabling Robust Unknown Object Manipulation from Pure Synthetic Data via Stereo Thomas Kollar, Michael Laskey, Kevin Stone, Brijen Thananjeyan
68 Dec 14, 2022
Utility functions for working with data from Nix in Python
Pynixutil - Utility functions for working with data from Nix in Python Examples Base32 encoding/decoding import pynixutil input = "v5sv61sszx301i0x6x
 11 Dec 16, 2022
11 Dec 16, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022
Python package for machine learning for healthcare using a OMOP common data model
This library was developed in order to facilitate rapid prototyping in Python of predictive machine-learning models using longitudinal medical data from an OMOP CDM-standard database.
 75 Jan 3, 2023
75 Jan 3, 2023
NeuralCompression is a Python repository dedicated to research of neural networks that compress data
NeuralCompression is a Python repository dedicated to research of neural networks that compress data. The repository includes tools such as JAX-based entropy coders, image compression models, video compression models, and metrics for image and video evaluation.
 297 Jan 6, 2023
297 Jan 6, 2023

Rubrix is a free and open-source tool for exploring and iterating on data for artificial intelligence projects.
Open-source tool for exploring, labeling, and monitoring data for AI projects
1.5k Jan 7, 2023

A pytorch reproduction of { Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation }.
A PyTorch Reproduction of HCN Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation. Ch
 210 Dec 31, 2022
210 Dec 31, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
77.2k Jan 3, 2023

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
 248 Nov 21, 2022
248 Nov 21, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
Athena is an open-source implementation of end-to-end speech processing engine.
Athena is an open-source implementation of end-to-end speech processing engine. Our vision is to empower both industrial application and academic research on end-to-end models for speech processing. To make speech processing available to everyone, we're also releasing example implementation and recipe on some opensource dataset for various tasks (Automatic Speech Recognition, Speech Synthesis, Voice Conversion, Speaker Recognition, etc).
 34 Sep 8, 2022
34 Sep 8, 2022
DrQ-v2: Improved Data-Augmented Reinforcement Learning
DrQ-v2: Improved Data-Augmented RL Agent Method DrQ-v2 is a model-free off-policy algorithm for image-based continuous control. DrQ-v2 builds on DrQ,
234 Jan 1, 2023
Data exploration done quick.
Pandas Tab Implementation of Stata's tabulate command in Pandas for extremely easy to type one-way and two-way tabulations. Support: Python 3.7 and 3.
 20 Aug 27, 2022
20 Aug 27, 2022

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022
A library for generating fake data and populating database tables.
Knockoff Factory A library for generating mock data and creating database fixtures that can be used for unit testing. Table of content Installation Ch
 30 Sep 23, 2022
30 Sep 23, 2022
PIX is an image processing library in JAX, for JAX.
PIX PIX is an image processing library in JAX, for JAX. Overview JAX is a library resulting from the union of Autograd and XLA for high-performance ma
 294 Jan 8, 2023
294 Jan 8, 2023
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
Kaldi-compatible feature extraction with PyTorch, supporting CUDA, batch processing, chunk processing, and autograd
 119 Jan 3, 2023
119 Jan 3, 2023

Moving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data
LiDAR-MOS: Moving Object Segmentation in 3D LiDAR Data This repo contains the code for our paper: Moving Object Segmentation in 3D LiDAR Data: A Learn
 394 Dec 29, 2022
394 Dec 29, 2022
code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology"
GIANT Code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology" https://arxiv.org/pdf/2004.02118.pdf Please cite our paper if this pr
 39 Dec 29, 2022
39 Dec 29, 2022

A new data augmentation method for extreme lighting conditions.
Random Shadows and Highlights This repo has the source code for the paper: Random Shadows and Highlights: A new data augmentation method for extreme l
 35 Nov 26, 2022
35 Nov 26, 2022

MicRank is a Learning to Rank neural channel selection framework where a DNN is trained to rank microphone channels.
MicRank: Learning to Rank Microphones for Distant Speech Recognition Application Scenario Many applications nowadays envision the presence of multiple
 20 Nov 10, 2022
20 Nov 10, 2022

Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference
RawVSR This repo contains the official codes for our paper: Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference Xiaoh
 23 Oct 8, 2022
23 Oct 8, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
MachineLearningStocks is designed to be an intuitive and highly extensible template project applying machine learning to making stock predictions.
Using python and scikit-learn to make stock predictions
 1.3k Jan 3, 2023
1.3k Jan 3, 2023

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023
Raganarok X: Next Generation Data Dump
Raganarok X Data Dump Raganarok X: Next Generation Data Dump More interesting Files File Name Contains en_langs All the variables you need in English
 14 Jul 15, 2022
14 Jul 15, 2022

A Python library for reading, writing and visualizing the OMEGA Format
A Python library for reading, writing and visualizing the OMEGA Format, targeted towards storing reference and perception data in the automotive context on an object list basis with a focus on an urban use case.
 12 Sep 1, 2022
12 Sep 1, 2022
Cross-platform .NET Core pre-commit hooks
dotnet-core-pre-commit Cross-platform .NET Core pre-commit hooks How to use Add this to your .pre-commit-config.yaml - repo: https://github.com/juan
 5 Jul 20, 2021
5 Jul 20, 2021

Squidpy is a tool for the analysis and visualization of spatial molecular data.
Squidpy is a tool for the analysis and visualization of spatial molecular data. It builds on top of scanpy and anndata, from which it inherits modularity and scalability. It provides analysis tools that leverages the spatial coordinates of the data, as well as tissue images if available.
 251 Dec 19, 2022
251 Dec 19, 2022
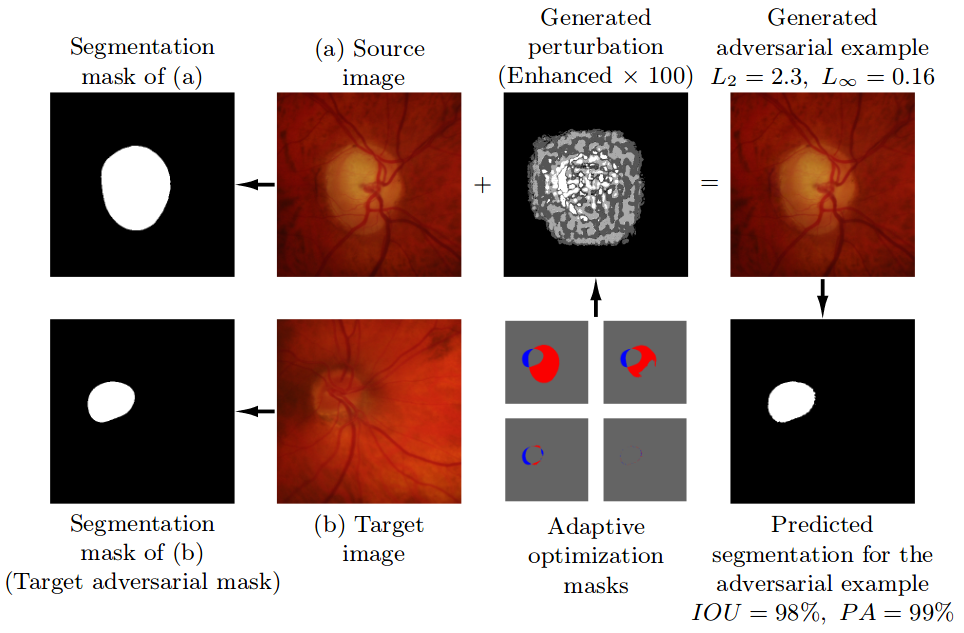
Pre-trained model, code, and materials from the paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation" (MICCAI 2019).
Adaptive Segmentation Mask Attack This repository contains the implementation of the Adaptive Segmentation Mask Attack (ASMA), a targeted adversarial
 53 Jul 4, 2022
53 Jul 4, 2022
deep learning model that learns to code with drawing in the Processing language
sketchnet sketchnet - processing code generator can we teach a computer to draw pictures with code. We use Processing and java/jruby code paired with
 41 Dec 12, 2022
41 Dec 12, 2022