2794 Repositories
Python data-transfer Libraries
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022
Data collection, enhancement, and metrics calculation.
l3_data_collection Data collection, enhancement, and metrics calculation. Summary Repository containing code for QuantDAO's JDT data collection task.
 3 Dec 23, 2022
3 Dec 23, 2022

Data App Performance Tests
Data App Performance Tests My hypothesis is that The different architectures of
 6 Dec 14, 2022
6 Dec 14, 2022
Implementation of Axial attention - attending to multi-dimensional data efficiently
Axial Attention Implementation of Axial attention in Pytorch. A simple but powerful technique to attend to multi-dimensional data efficiently. It has
 250 Dec 25, 2022
250 Dec 25, 2022

learn python in 100 days, a simple step could be follow from beginner to master of every aspect of python programming and project also include side project which you can use as demo project for your personal portfolio
learn python in 100 days, a simple step could be follow from beginner to master of every aspect of python programming and project also include side project which you can use as demo project for your personal portfolio
 6 Nov 5, 2022
6 Nov 5, 2022
Completed task 1 and task 2 at LetsGrowMore as a data science intern.
LetsGrowMore-Internship Completed task 1 and task 2 at LetsGrowMore as a data science intern. Task 1- Task 2- Creating a Decision Tree classifier and
 1 Jan 16, 2022
1 Jan 16, 2022
100 Days of Code The Complete Python Pro Bootcamp for 2022
100-Day-With-Python 100 Days of Code - The Complete Python Pro Bootcamp for 2022. In this course, I spend with python language over 100 days, and I up
 8 Jun 22, 2022
8 Jun 22, 2022
Python data processing, analysis, visualization, and data operations
Python This is a Python data processing, analysis, visualization and data operations of the source code warehouse, book ISBN: 9787115527592 Descriptio
 1 Jan 16, 2022
1 Jan 16, 2022
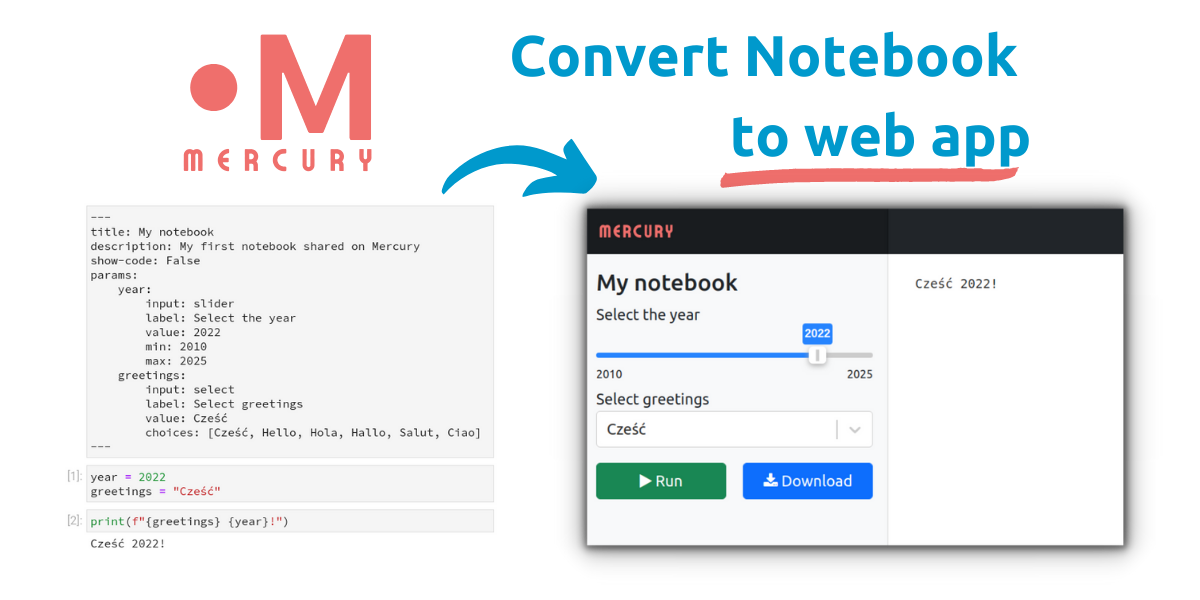
Mercury: easily convert Python notebook to web app and share with others
Mercury Share your Python notebooks with others Easily convert your Python notebooks into interactive web apps by adding parameters in YAML. Simply ad
 2.2k Dec 27, 2022
2.2k Dec 27, 2022
NW 2022 Hackathon Project by Angelique Clara Hanzel, Aryan Sonik, Damien Fung, Ramit Brata Biswas
Spiral-Data-Visualizer NW 2022 Hackathon Project by Angelique Clara Hanzell, Aryan Sonik, Damien Fung, Ramit Brata Biswas Description This project vis
 2 Jan 16, 2022
2 Jan 16, 2022

Dimension Reduced Turbulent Flow Data From Deep Vector Quantizers
Dimension Reduced Turbulent Flow Data From Deep Vector Quantizers This is an implementation of A Physics-Informed Vector Quantized Autoencoder for Dat
 3 Sep 12, 2022
3 Sep 12, 2022
This repository gives an example on how to preprocess the data of the HECKTOR challenge
HECKTOR 2021 challenge This repository gives an example on how to preprocess the data of the HECKTOR challenge. Any other preprocessing is welcomed an
 56 Dec 1, 2022
56 Dec 1, 2022
Code and data (Incidents Dataset) for ECCV 2020 Paper "Detecting natural disasters, damage, and incidents in the wild".
Incidents Dataset See the following pages for more details: Project page: IncidentsDataset.csail.mit.edu. ECCV 2020 Paper "Detecting natural disasters
 67 Dec 27, 2022
67 Dec 27, 2022
This repo generates the training data and the model for Morpheus-Deblend
Morpheus-Deblend This repo generates the training data and the model for Morpheus-Deblend. This is the active development repo for the project and as
 2 Apr 18, 2022
2 Apr 18, 2022
Deeplearning project at The Technological University of Denmark (DTU) about Neural ODEs for finding dynamics in ordinary differential equations and real world time series data
Authors Marcus Lenler Garsdal, [email protected] Valdemar Søgaard, [email protected] Simon Moe Sørensen, [email protected] Introduction This repo contains the
 6 Sep 5, 2022
6 Sep 5, 2022
Accurate identification of bacteriophages from metagenomic data using Transformer
PhaMer is a python library for identifying bacteriophages from metagenomic data. PhaMer is based on a Transorfer model and rely on protein-based vocab
 9 Nov 30, 2022
9 Nov 30, 2022

Fully Adaptive Bayesian Algorithm for Data Analysis (FABADA) is a new approach of noise reduction methods. In this repository is shown the package developed for this new method based on \citepaper.
Fully Adaptive Bayesian Algorithm for Data Analysis FABADA FABADA is a novel non-parametric noise reduction technique which arise from the point of vi
 18 Oct 20, 2022
18 Oct 20, 2022

Data-driven reduced order modeling for nonlinear dynamical systems
SSMLearn Data-driven Reduced Order Models for Nonlinear Dynamical Systems This package perform data-driven identification of reduced order model based
 27 Dec 13, 2022
27 Dec 13, 2022

A curated list of awesome open source libraries to deploy, monitor, version and scale your machine learning
Awesome production machine learning This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, versi
 12.9k Jan 4, 2023
12.9k Jan 4, 2023
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023

An awesome Data Science repository to learn and apply for real world problems.
AWESOME DATA SCIENCE An open source Data Science repository to learn and apply towards solving real world problems. This is a shortcut path to start s
 20.3k Jan 9, 2023
20.3k Jan 9, 2023
📚 Papers & tech blogs by companies sharing their work on data science & machine learning in production.
applied-ml Curated papers, articles, and blogs on data science & machine learning in production. ⚙️ Figuring out how to implement your ML project? Lea
 22.1k Jan 3, 2023
22.1k Jan 3, 2023
A curated list of awesome DataOps tools
Awesome DataOps A curated list of awesome DataOps tools. Awesome DataOps Data Catalog Data Exploration Data Ingestion Data Lake Data Processing Data Q
 40 Dec 23, 2022
40 Dec 23, 2022
Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord.
numpy2tfrecord Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord. Installation
 2 Jan 16, 2022
2 Jan 16, 2022

DeepAmandine is an artificial intelligence that allows you to talk to it for hours, you won't know the difference.
DeepAmandine This is an artificial intelligence based on GPT-3 that you can chat with, it is very nice and makes a lot of jokes. We wish you a good ex
 3 Apr 19, 2022
3 Apr 19, 2022
Drobo Status is a python program that will connect to your Drobo and return JSON data regarding your Drobo
This is a simple python script that will run a docker container to pull data from Drobo. It will give information like (Name, serial, firmware, disk-total, disk-used, disk-free and individual disk status). I have an older Drobo FS 8 disk array. Please let me know if anyone can test. The results are outputted via JSON
 1 Jan 15, 2022
1 Jan 15, 2022
This project consists of data analysis and data visualization (done using python)of all IPL seasons from 2008 to 2019 and answering the most asked questions about the IPL.
IPL-data-analysis This project consists of data analysis and data visualization of all IPL seasons from 2008 to 2019 and answering the most asked ques
 2 Feb 8, 2022
2 Feb 8, 2022

Astrostatistics class for the MSc degree in Astrophysics at the University of Milan-Bicocca (Italy)
Astrostatistics Davide Gerosa - [email protected] University of Milano-Bicocca, 2022. Schedule Introduction Probability and Statistics I Probabi
 25 Jan 2, 2023
25 Jan 2, 2023
An open-source outlier detection package by Getcontact Data Team
pyfbad The pyfbad library supports anomaly detection projects. An end-to-end anomaly detection application can be written using the source codes of th
 41 Dec 27, 2022
41 Dec 27, 2022

Pizza Orders Data Pipeline Usecase Solved by SQL, Sqoop, HDFS, Hive, Airflow.
PizzaOrders_DataPipeline There is a Tony who is owning a New Pizza shop. He knew that pizza alone was not going to help him get seed funding to expand
 4 Jun 5, 2022
4 Jun 5, 2022
The final project of "Applying AI to 2D Medical Imaging Data" of "AI for Healthcare" nanodegree - Udacity.
Pneumonia Detection from X-Rays Project Overview In this project, you will apply the skills that you have acquired in this 2D medical imaging course t
 1 Jan 14, 2022
1 Jan 14, 2022
Credit EDA Case Study Using Python
This case study aims to identify patterns which indicate if a client has difficulty paying their installments which may be used for taking actions such as denying the loan, reducing the amount of loan, lending (to risky applicants) at a higher interest rate, etc
 1 Jan 14, 2022
1 Jan 14, 2022

The final project for "Applying AI to Wearable Device Data" course from "AI for Healthcare" - Udacity.
Motion Compensated Pulse Rate Estimation Overview This project has 2 main parts. Develop a Pulse Rate Algorithm on the given training data. Then Test
2 Oct 25, 2022
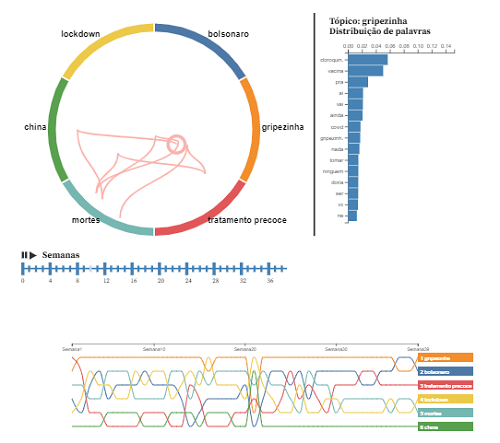
Project for the discipline of Visual Data Analysis at EMAp FGV.
Analysis of the dissemination of fake news about COVID-19 on Twitter This project was the final work for the discipline of Visual Data Analysis of the
 2 Jan 17, 2022
2 Jan 17, 2022
The final project of "Applying AI to EHR Data" of "AI for Healthcare" nanodegree - Udacity.
Patient Selection for Diabetes Drug Testing Project Overview EHR data is becoming a key source of real-world evidence (RWE) for the pharmaceutical ind
1 Jan 14, 2022

The final project of "Applying AI to 3D Medical Imaging Data" from "AI for Healthcare" nanodegree - Udacity.
Quantifying Hippocampus Volume for Alzheimer's Progression Background Alzheimer's disease (AD) is a progressive neurodegenerative disorder that result
1 Jan 14, 2022
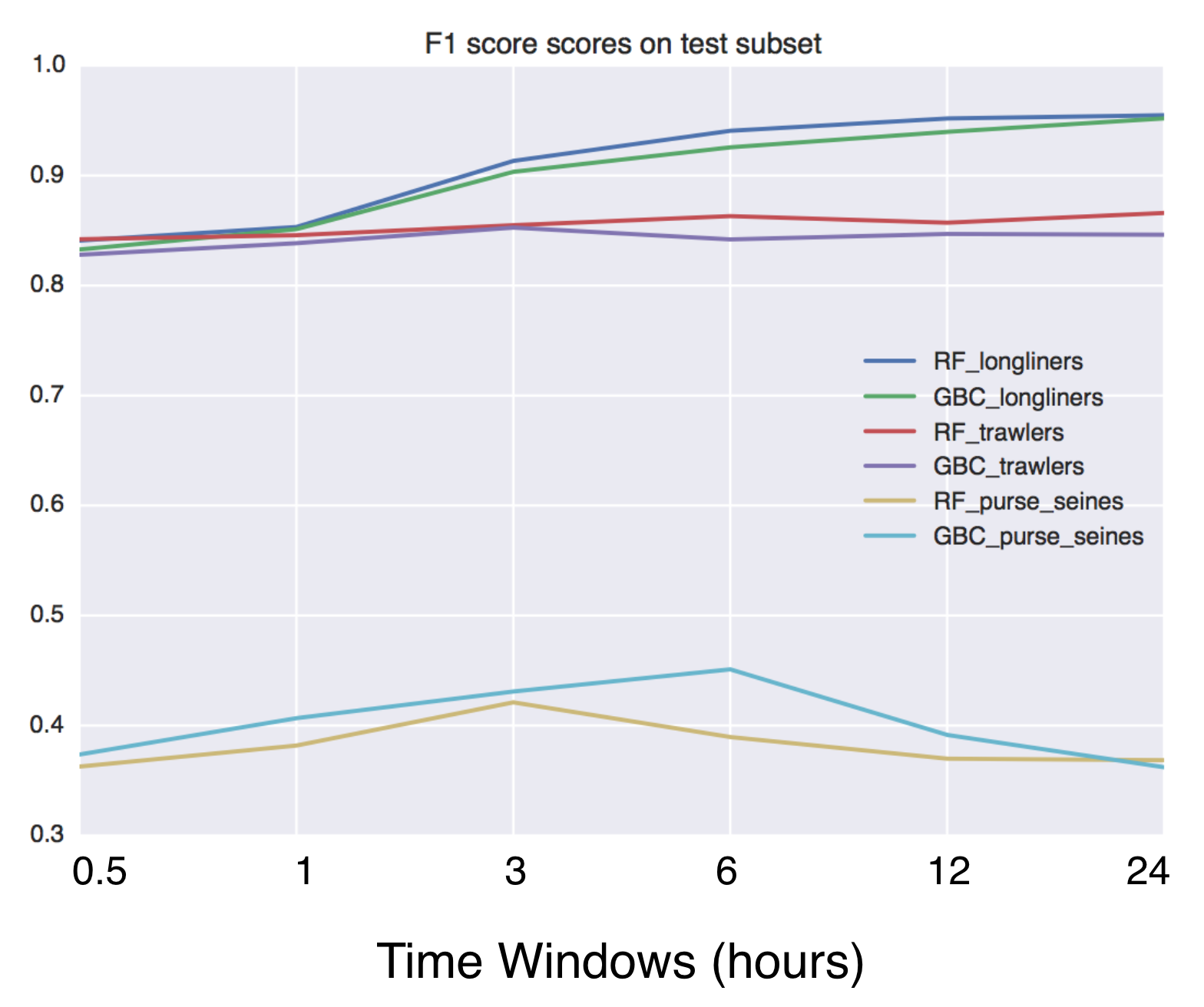
Using Global fishing watch's data to build a machine learning model that can identify illegal fishing and poaching activities through satellite and geo-location data.
Using Global fishing watch's data to build a machine learning model that can identify illegal fishing and poaching activities through satellite and geo-location data.
 3 May 6, 2022
3 May 6, 2022
A list of Python Bots used to extract data from several websites
A list of Python Bots used to extract data from several websites. Data extraction is for products on e-commerce (ecommerce) websites. Data fetched i
 1 Jan 14, 2022
1 Jan 14, 2022
MOOSE (Multi-organ objective segmentation) a data-centric AI solution that generates multilabel organ segmentations to facilitate systemic TB whole-person research
MOOSE (Multi-organ objective segmentation) a data-centric AI solution that generates multilabel organ segmentations to facilitate systemic TB whole-person research.The pipeline is based on nn-UNet and has the capability to segment 120 unique tissue classes from a whole-body 18F-FDG PET/CT image.
 30 Jan 1, 2023
30 Jan 1, 2023

A simple baseline for the 2022 IEEE GRSS Data Fusion Contest (DFC2022)
DFC2022 Baseline A simple baseline for the 2022 IEEE GRSS Data Fusion Contest (DFC2022) This repository uses TorchGeo, PyTorch Lightning, and Segmenta
 24 Nov 28, 2022
24 Nov 28, 2022
Calendar heatmaps from Pandas time series data
Note: See MarvinT/calmap for the maintained version of the project. That is also the version that gets published to PyPI and it has received several f
 195 Dec 22, 2022
195 Dec 22, 2022
Unauthenticated Sqlinjection that leads to dump data base but this one impersonated Admin and drops a interactive shell
Unauthenticated Sqlinjection that leads to dump database but this one impersonated Admin and drops a interactive shell
 16 Nov 9, 2022
16 Nov 9, 2022
Med to csv - A simple way to parse MedAssociate output file in tidy data
MedAssociates to CSV file A simple way to parse MedAssociate output file in tidy
 5 Sep 9, 2022
5 Sep 9, 2022

This project is related to a No-SQL database, whose data are referred to autoctone botanic species
This project is related to a No-SQL database, whose data are referred to autoctone botanic species. The final goal is creating a function that performs the estimation of the ornamental value, given the specific characteristics of a single species.
 2 Mar 8, 2022
2 Mar 8, 2022
CellRank's reproducibility repository.
CellRank's reproducibility repository We believe that reproducibility is key and have made it as simple as possible to reproduce our results. Please e
 8 Oct 8, 2022
8 Oct 8, 2022
Data-Uncertainty Guided Multi-Phase Learning for Semi-supervised Object Detection
An official implementation of paper Data-Uncertainty Guided Multi-Phase Learning for Semi-supervised Object Detection
 11 Nov 23, 2022
11 Nov 23, 2022
ALSPAC data analysis studying links between screen-usage and mental health issues in children. Provided data has been synthesised.
ADSMH - Mental Health and Screen Time Group coursework for Applied Data Science at the University of Bristol. Overview The data set that you have was
 1 Jan 13, 2022
1 Jan 13, 2022
The repository is my code for various types of data visualization cases based on the Matplotlib library.
ScienceGallery The repository is my code for various types of data visualization cases based on the Matplotlib library. It summarizes the code and cas
 2 Apr 20, 2022
2 Apr 20, 2022
STARCH compuets regional extreme storm physical characteristics and moisture balance based on spatiotemporal precipitation data from reanalysis or climate model data.
STARCH (Storm Tracking And Regional CHaracterization) STARCH computes regional extreme storm physical and moisture balance characteristics based on sp
 7 Oct 20, 2022
7 Oct 20, 2022

 1 Jan 14, 2022
1 Jan 14, 2022

This repository introduces a short project about Transfer Learning for Classification of MRI Images.
Transfer Learning for MRI Images Classification This repository introduces a short project made during my stay at Neuromatch Summer School 2021. This
 3 Nov 15, 2022
3 Nov 15, 2022
Data aggregated from the reports found at the MCPS COVID Dashboard into a set of visualizations.
Montgomery County Public Schools COVID-19 Visualizer Contents About this project Data Support this project About this project Data All data we use can
 3 Jan 19, 2022
3 Jan 19, 2022
This is the course project of AI3602: Data Mining of SJTU
This is the course project of AI3602: Data Mining of SJTU. Group Members include Jinghao Feng, Mingyang Jiang and Wenzhong Zheng.
 2 Jan 13, 2022
2 Jan 13, 2022
Automatically pick a winner who Retweeted, Commented, and Followed your Twitter account!
AutomaticTwitterGiveaways automates selecting winners for "Retweet, Comment, Follow" type Twitter giveaways.
 1 Jan 13, 2022
1 Jan 13, 2022

We present a regularized self-labeling approach to improve the generalization and robustness properties of fine-tuning.
Overview This repository provides the implementation for the paper "Improved Regularization and Robustness for Fine-tuning in Neural Networks", which
 21 Sep 8, 2022
21 Sep 8, 2022

K Closest Points and Maximum Clique Pruning for Efficient and Effective 3D Laser Scan Matching (To appear in RA-L 2022)
KCP The official implementation of KCP: k Closest Points and Maximum Clique Pruning for Efficient and Effective 3D Laser Scan Matching, accepted for p
 109 Dec 14, 2022
109 Dec 14, 2022

Python data loader for Solar Orbiter's (SolO) Energetic Particle Detector (EPD).
Data loader (and downloader) for Solar Orbiter/EPD energetic charged particle sensors EPT, HET, and STEP. Supports level 2 and low latency data provided by ESA's Solar Orbiter Archive.
 9 Dec 16, 2022
9 Dec 16, 2022
Data Analytics on Genomes and Genetics
Data Analytics performed on On genomes and Genetics dataset to predict genetic disorder and disorder subclass. DONE by TEAM SIGMA!
 1 Jan 12, 2022
1 Jan 12, 2022
Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages.
Video Games Web Scraper Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages. This
 1 Jan 12, 2022
1 Jan 12, 2022
Predict the Site EUI, given the characteristics of the building and the weather data for the location of the building.
wids_datathon_2022 Description: Contains a data pipeline used to predict energy EUI Goals: Dataset exploration Automating the parameter fitting, gener
 1 Mar 25, 2022
1 Mar 25, 2022
In this project , I play with the YouTube data API and extract trending videos in Nigeria on a particular day
YouTubeTrendingVideosAnalysis In this project , I played with the YouTube data API and extracted trending videos in Nigeria on a particular day. This
 1 Jan 11, 2022
1 Jan 11, 2022

This repository structures data in title, summary, tags, sentiment given a fragment of a conversation
Understand-conversation-AI This repository structures data in title, summary, tags, sentiment given a fragment of a conversation How to install: pip i
 1 Jan 11, 2022
1 Jan 11, 2022
Kinetics-Data-Preprocessing
Kinetics-Data-Preprocessing Kinetics-400 and Kinetics-600 are common video recognition datasets used by popular video understanding projects like Slow
 7 Oct 27, 2022
7 Oct 27, 2022
Python Machine Learning Jupyter Notebooks (ML website)
Python Machine Learning Jupyter Notebooks (ML website) Dr. Tirthajyoti Sarkar, Fremont, California (Please feel free to connect on LinkedIn here) Also
 2.6k Jan 3, 2023
2.6k Jan 3, 2023
Semi-Automated Data Processing
Perform semi automated exploratory data analysis, feature engineering and feature selection on provided dataset by visualizing every possibilities on each step and assisting the user to make a meaningful decision to achieve a low-bias and low-variance model.
 1 Jan 17, 2022
1 Jan 17, 2022
The bidirectional mapping library for Python.
bidict The bidirectional mapping library for Python. Status bidict: has been used for many years by several teams at Google, Venmo, CERN, Bank of Amer
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
Python Library to get fast extensive Dummy Data for testing
Dumda Python Library to get fast extensive Dummy Data for testing https://pypi.org/project/dumda/ Installation pip install dumda Usage: Cities from d
 0 Dec 27, 2021
0 Dec 27, 2021

Displaying plot of death rates from past years in Poland. Data source from these years is in readme
Average-Death-Rate Displaying plot of death rates from past years in Poland The goal collect the data from a CSV file count the ADR (Average Death Rat
 0 Sep 12, 2021
0 Sep 12, 2021

Advanced raster and geometry manipulations
buzzard In a nutshell, the buzzard library provides powerful abstractions to manipulate together images and geometries that come from different kind o
 30 Jun 20, 2022
30 Jun 20, 2022
Download and process GOES-16 and GOES-17 data from NOAA's archive on AWS using Python.
Download and display GOES-East and GOES-West data GOES-East and GOES-West satellite data are made available on Amazon Web Services through NOAA's Big
 88 Dec 16, 2022
88 Dec 16, 2022

Shelf DB is a tiny document database for Python to stores documents or JSON-like data
Shelf DB Introduction Shelf DB is a tiny document database for Python to stores documents or JSON-like data. Get it $ pip install shelfdb shelfquery S
 35 Nov 3, 2022
35 Nov 3, 2022
Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle.
2019-indian-election-eda Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle. This project is a part of the Cou
 5 Oct 10, 2022
5 Oct 10, 2022

DCM is a set of tools that helps you to keep your data in your Django Models consistent.
Django Consistency Model DCM is a set of tools that helps you to keep your data in your Django Models consistent. Motivation You have a lot of legacy
 59 Dec 21, 2022
59 Dec 21, 2022
To design and implement the Identification of Iris Flower species using machine learning using Python and the tool Scikit-Learn.
To design and implement the Identification of Iris Flower species using machine learning using Python and the tool Scikit-Learn.
 1 Jan 11, 2022
1 Jan 11, 2022
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
 50 Dec 22, 2022
50 Dec 22, 2022

Data Science Course at Dept. of Computer Engineering, Chula 2022
2110446 Data Science Course at Chula 2022 Short links for exercises: Week1: Intro to Numpy, Pandas Numpy: https://colab.research.google.com/github/kao
 17 Nov 27, 2022
17 Nov 27, 2022

Udacity - Data Analyst Nanodegree - Project 4 - Wrangle and Analyze Data
WeRateDogs Twitter Data from 2015 to 2017 Udacity - Data Analyst Nanodegree - Project 4 - Wrangle and Analyze Data Table of Contents Introduction Proj
 1 Jan 12, 2022
1 Jan 12, 2022
BSDotPy, A module to get a bombsquad player's account data.
BSDotPy BSDotPy, A module to get a bombsquad player's account data from bombsquad's servers. Badges Provided By: shields.io Acknowledgements Issues Pu
 3 Feb 17, 2022
3 Feb 17, 2022

Using knowledge-informed machine learning on the PRONOSTIA (FEMTO) and IMS bearing data sets. Predict remaining-useful-life (RUL).
Knowledge Informed Machine Learning using a Weibull-based Loss Function Exploring the concept of knowledge-informed machine learning with the use of a
 43 Dec 14, 2022
43 Dec 14, 2022
Orange Chicken: Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation
Orange Chicken: Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation This repository contains code and data f
 0 Jan 7, 2022
0 Jan 7, 2022

Classification of Long Sequential Data using Circular Dilated Convolutional Neural Networks
Classification of Long Sequential Data using Circular Dilated Convolutional Neural Networks arXiv preprint: https://arxiv.org/abs/2201.02143. Architec
 19 Nov 30, 2022
19 Nov 30, 2022
Source code for the plant extraction workflow introduced in the paper “Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision”
Plant extraction workflow Source code for the plant extraction workflow introduced in the paper "Agricultural Plant Cataloging and Establishment of a
 0 Apr 22, 2022
0 Apr 22, 2022
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data. Flexible EM-Inspired Discriminant Analysis is a robust supervised classification algorithm that performs well in noisy and contaminated datasets.
 0 Sep 6, 2022
0 Sep 6, 2022
Active Transport Analytics Model: A new strategic transport modelling and data visualization framework
{ATAM} Active Transport Analytics Model Active Transport Analytics Model (“ATAM”
 2 Dec 21, 2022
2 Dec 21, 2022
Historic weather - Home Assistant custom component for accessing historic weather data
Historic Weather for Home Assistant (CC) 2022 by Andreas Frisch github@fraxinas.
 1 Jan 10, 2022
1 Jan 10, 2022
In this repo, I will put all the code related to data science using python libraries like Numpy, Pandas, Matplotlib, Seaborn and many more.
Python-for-DS In this repo, I will put all the code related to data science using python libraries like Numpy, Pandas, Matplotlib, Seaborn and many mo
 1 Jan 10, 2022
1 Jan 10, 2022
This repository contains answers of the Shopify Summer 2022 Data Science Intern Challenge.
Data-Science-Intern-Challenge This repository contains answers of the Shopify Summer 2022 Data Science Intern Challenge. Summer 2022 Data Science Inte
 1 Jan 11, 2022
1 Jan 11, 2022
Active Transport Analytics Model (ATAM) is a new strategic transport modelling and data visualization framework for Active Transport as well as emerging micro-mobility modes
{ATAM} Active Transport Analytics Model Active Transport Analytics Model (“ATAM”) is a new strategic transport modelling and data visualization framew
 0 Jan 12, 2022
0 Jan 12, 2022
Validate arbitrary image uploads from incoming data urls while preserving file integrity but removing EXIF and unwanted artifacts and RCE exploit potential
Validate arbitrary base64-encoded image uploads as incoming data urls while preserving image integrity but removing EXIF and unwanted artifacts and mitigating RCE-exploit potential.
 1 Jan 10, 2022
1 Jan 10, 2022
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
 1 Jan 10, 2022
1 Jan 10, 2022
Deep learning with TensorFlow and earth observation data.
Deep Learning with TensorFlow and EO Data Complete file set for Jupyter Book Autor: Development Seed Date: 04 October 2021 ISBN: (to come) Notebook tu
 20 Nov 16, 2022
20 Nov 16, 2022
Big Data & Cloud Computing for Oceanography
DS2 Class 2022, Big Data & Cloud Computing for Oceanography Home of the 2022 ISblue Big Data & Cloud Computing for Oceanography class (IMT-A, ENSTA, I
 5 Mar 19, 2022
5 Mar 19, 2022
Generating new names based on trends in data using GPT2 (Transformer network)
MLOpsNameGenerator Overall Goal The goal of the project is to develop a model that is capable of creating Pokémon names based on its description, usin
 2 Jan 10, 2022
2 Jan 10, 2022
Official git for "CTAB-GAN: Effective Table Data Synthesizing"
CTAB-GAN This is the official git paper CTAB-GAN: Effective Table Data Synthesizing. The paper is published on Asian Conference on Machine Learning (A
 30 Dec 26, 2022
30 Dec 26, 2022
A Python package that can be used to download post and comment data from Reddit.
Reddit Data Collector Reddit Data Collector is a Python package that allows a user to collect post and comment data from Reddit. It is built on top of
 3 Jul 26, 2022
3 Jul 26, 2022
A practical ML pipeline for data labeling with experiment tracking using DVC.
Auto Label Pipeline A practical ML pipeline for data labeling with experiment tracking using DVC Goals: Demonstrate reproducible ML Use DVC to build a
 4 Mar 8, 2022
4 Mar 8, 2022

A vanilla 3D face modeling on pose-invariant and multi-lightning image data
3D-Face-Modeling A vanilla 3D face modeling on pose-invariant and multi-lightning image data Table of Contents Background Install Usage Contributing B
 1 Mar 12, 2022
1 Mar 12, 2022
🎁 3,000,000+ Unsplash images made available for research and machine learning
The Unsplash Dataset The Unsplash Dataset is made up of over 250,000+ contributing global photographers and data sourced from hundreds of millions of
 2k Jan 3, 2023
2k Jan 3, 2023
A collection of machine learning examples and tutorials.
machine_learning_examples A collection of machine learning examples and tutorials.
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

Always know what to expect from your data.
Great Expectations Always know what to expect from your data. Introduction Great Expectations helps data teams eliminate pipeline debt, through data t
 7.8k Jan 5, 2023
7.8k Jan 5, 2023