1609 Repositories
Python dataset-analysis Libraries

A PyTorch toolkit for 2D Human Pose Estimation.
PyTorch-Pose PyTorch-Pose is a PyTorch implementation of the general pipeline for 2D single human pose estimation. The aim is to provide the interface
 1.1k Dec 30, 2022
1.1k Dec 30, 2022

PyTorch implementation of the wavelet analysis from Torrence & Compo
Continuous Wavelet Transforms in PyTorch This is a PyTorch implementation for the wavelet analysis outlined in Torrence and Compo (BAMS, 1998). The co
 262 Dec 21, 2022
262 Dec 21, 2022

LogDeep is an open source deeplearning-based log analysis toolkit for automated anomaly detection.
LogDeep is an open source deeplearning-based log analysis toolkit for automated anomaly detection.
 279 Dec 13, 2022
279 Dec 13, 2022
This is an online course where you can learn and master the skill of low-level performance analysis and tuning.
Performance Ninja Class This is an online course where you can learn to find and fix low-level performance issues, for example CPU cache misses and br
 1.2k Dec 30, 2022
1.2k Dec 30, 2022

Synthetic LiDAR sequential point cloud dataset with point-wise annotations
SynLiDAR dataset: Learning From Synthetic LiDAR Sequential Point Cloud This is official repository of the SynLiDAR dataset. For technical details, ple
 78 Dec 27, 2022
78 Dec 27, 2022
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks (SDPoint) This repository contains the cod
 17 Jul 4, 2022
17 Jul 4, 2022
Tooling for the Common Objects In 3D dataset.
CO3D: Common Objects In 3D This repository contains a set of tools for working with the Common Objects in 3D (CO3D) dataset. Download the dataset The
 724 Jan 6, 2023
724 Jan 6, 2023

Anomaly detection on SQL data warehouses and databases
With CueObserve, you can run anomaly detection on data in your SQL data warehouses and databases. Getting Started Install via Docker docker run -p 300
 171 Dec 18, 2022
171 Dec 18, 2022
Moment-DETR code and QVHighlights dataset
Moment-DETR QVHighlights: Detecting Moments and Highlights in Videos via Natural Language Queries Jie Lei, Tamara L. Berg, Mohit Bansal For dataset de
 133 Dec 22, 2022
133 Dec 22, 2022
Reference implementation of code generation projects from Facebook AI Research. General toolkit to apply machine learning to code, from dataset creation to model training and evaluation. Comes with pretrained models.
This repository is a toolkit to do machine learning for programming languages. It implements tokenization, dataset preprocessing, model training and m
408 Jan 1, 2023

TLA - Twitter Linguistic Analysis
TLA - Twitter Linguistic Analysis Tool for linguistic analysis of communities TLA is built using PyTorch, Transformers and several other State-of-the-
 47 Aug 14, 2022
47 Aug 14, 2022
Greppin' Logs: Leveling Up Log Analysis
This repo contains sample code and example datasets from Jon Stewart and Noah Rubin's presentation at the 2021 SANS DFIR Summit titled Greppin' Logs. The talk was centered around the idea that Forensics is Data Engineering and Data Science, and should be approached as such. Jon and Noah focused on the core (Unix) command line tools useful to anyone analyzing datasets from a terminal, purpose-built tools for handling structured tabular and JSON data, Stroz Friedberg's open source multipattern search tool Lightgrep, and scaling with AWS.
 20 Sep 14, 2022
20 Sep 14, 2022

A simple python tool for explore your object detection dataset
A simple tool for explore your object detection dataset. The goal of this library is to provide simple and intuitive visualizations from your dataset and automatically find the best parameters for generating a specific grid of anchors that can fit you data characteristics
 142 Dec 25, 2022
142 Dec 25, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

Newsemble is an API that provides easy access to the current news for programmatic analysis
Newsemble is an API that provides easy access to the current news for programmatic analysis. It has been built using Python, BeautifulSoup and MongoDB.
 43 Dec 16, 2022
43 Dec 16, 2022

Implementation of QuickDraw - an online game developed by Google, combined with AirGesture - a simple gesture recognition application
QuickDraw - AirGesture Introduction Here is my python source code for QuickDraw - an online game developed by google, combined with AirGesture - a sim
 89 Dec 18, 2022
89 Dec 18, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
LiDAR R-CNN: An Efficient and Universal 3D Object Detector Introduction This is the official code of LiDAR R-CNN: An Efficient and Universal 3D Object
 295 Jan 5, 2023
295 Jan 5, 2023

A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
 75 Dec 26, 2022
75 Dec 26, 2022

Semantic Segmentation of images using PixelLib with help of Pascalvoc dataset trained with Deeplabv3+ framework.
CARscan- Approach 1 - Segmentation of images by detecting contours. It failed because in images with elements along with cars were also getting detect
 5 Jul 29, 2021
5 Jul 29, 2021

Squidpy is a tool for the analysis and visualization of spatial molecular data.
Squidpy is a tool for the analysis and visualization of spatial molecular data. It builds on top of scanpy and anndata, from which it inherits modularity and scalability. It provides analysis tools that leverages the spatial coordinates of the data, as well as tissue images if available.
 251 Dec 19, 2022
251 Dec 19, 2022

Using Tensorflow Object Detection API to detect Waymo open dataset
Waymo-2D-Object-Detection Using Tensorflow Object Detection API to detect Waymo open dataset Result CenterNet Training Loss SSD ResNet Training Loss C
 76 Dec 12, 2022
76 Dec 12, 2022
Code and dataset for ACL2018 paper "Exploiting Document Knowledge for Aspect-level Sentiment Classification"
Aspect-level Sentiment Classification Code and dataset for ACL2018 [paper] ‘‘Exploiting Document Knowledge for Aspect-level Sentiment Classification’’
 146 Nov 29, 2022
146 Nov 29, 2022
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening Introduction This is an implementation of the model used for breast
 757 Dec 30, 2022
757 Dec 30, 2022

The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
The Medical Detection Toolkit contains 2D + 3D implementations of prevalent object detectors such as Mask R-CNN, Retina Net, Retina U-Net, as well as a training and inference framework focused on dealing with medical images.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023

Manage your exceptions in Python like a PRO
A linter to manage all your python exceptions and try/except blocks (limited only for those who like dinosaurs).
 353 Dec 31, 2022
353 Dec 31, 2022

A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
A mindmap summarising Machine Learning concepts, from Data Analysis to Deep Learning.
 5.7k Dec 30, 2022
5.7k Dec 30, 2022
A linter to manage all your python exceptions and try/except blocks (limited only for those who like dinosaurs).
Manage your exceptions in Python like a PRO Currently in BETA. Inspired by this blog post. I shared the building process of this tool here. “For those
353 Dec 31, 2022

The first dataset of composite images with rationality score indicating whether the object placement in a composite image is reasonable.
Object-Placement-Assessment-Dataset-OPA Object-Placement-Assessment (OPA) is to verify whether a composite image is plausible in terms of the object p
 53 Nov 15, 2022
53 Nov 15, 2022

The first dataset on shadow generation for the foreground object in real-world scenes.
Object-Shadow-Generation-Dataset-DESOBA Object Shadow Generation is to deal with the shadow inconsistency between the foreground object and the backgr
105 Dec 30, 2022

Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
 22 Nov 8, 2022
22 Nov 8, 2022

Check the basic quality of any dataset
Data Quality Checker in Python Check the basic quality of any dataset. Sneak Peek Read full tutorial at Medium. Explore the app Requirements python 3.
 8 Feb 23, 2022
8 Feb 23, 2022
Pose Detection and Machine Learning for real-time body posture analysis during exercise to provide audiovisual feedback on improvement of form.
Posture: Pose Tracking and Machine Learning for prescribing corrective suggestions to improve posture and form while exercising. This repository conta
 10 Nov 11, 2022
10 Nov 11, 2022
Fixes 500+ mislabeled MURA images
In this repository, new csv files are provided that fixes 500+ mislabeled MURA x-rays for all categories. The mislabeled x-rays mainly had hardware in them. This project only fixes the false negatives for now.
 4 May 18, 2022
4 May 18, 2022

SDL: Synthetic Document Layout dataset
SDL is the project that synthesizes document images. It facilitates multiple-level labeling on document images and can generate in multiple languages.
 0 Oct 7, 2021
0 Oct 7, 2021
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
Visual Python is a GUI-based Python code generator, developed on the Jupyter Notebook environment as an extension.
 564 Jan 3, 2023
564 Jan 3, 2023
Large dataset storage format for Pytorch
H5Record Large dataset ( 100G, = 1T) storage format for Pytorch (wip) Support python 3 pip install h5record Why? Writing large dataset is still a
 43 Oct 22, 2022
43 Oct 22, 2022

This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations at CVPR'21. According to some product reasons, we are not planning to release the training/testing codes and models. However, we will release the dataset and the scripts to prepare the dataset.
TransFill-Reference-Inpainting This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transf
 80 Dec 8, 2022
80 Dec 8, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022

Implementation of StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation in PyTorch
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation Implementation of StyleSpace Analysis: Disentangled Controls for StyleGAN Ima
 86 Dec 7, 2022
86 Dec 7, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

A large dataset of 100k Google Satellite and matching Map images, resembling pix2pix's Google Maps dataset.
Larger Google Sat2Map dataset This dataset extends the aerial ⟷ Maps dataset used in pix2pix (Isola et al., CVPR17). The provide script download_sat2m
 34 Dec 28, 2022
34 Dec 28, 2022
BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset.
BloodCheck BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset. Installation
 16 Nov 5, 2021
16 Nov 5, 2021

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022

A Python Module That Uses ANN To Predict A Stocks Price And Also Provides Accurate Technical Analysis With Many High Potential Implementations!
Stox ⚡ A Python Module For The Stock Market ⚡ A Module to predict the "close price" for the next day and give "technical analysis". It uses a Neural N
 31 Dec 16, 2022
31 Dec 16, 2022
Gamestonk Terminal is an awesome stock and crypto market terminal
Gamestonk Terminal is an awesome stock and crypto market terminal. A FOSS alternative to Bloomberg Terminal.
 18.6k Jan 3, 2023
18.6k Jan 3, 2023

30 Days Of Machine Learning Using Pytorch
Objective of the repository is to learn and build machine learning models using Pytorch. 30DaysofML Using Pytorch
 119 Nov 24, 2022
119 Nov 24, 2022

Code for SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations
The Second Situated Interactive MultiModal Conversations (SIMMC 2.0) Challenge 2021 Welcome to the Second Situated Interactive Multimodal Conversation
81 Nov 22, 2022

Open-sourcing the Slates Dataset for recommender systems research
FINN.no Recommender Systems Slate Dataset This repository accompany the paper "Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sa
 48 Nov 28, 2022
48 Nov 28, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022
Code for our TKDE paper "Understanding WeChat User Preferences and “Wow” Diffusion"
wechat-wow-analysis Understanding WeChat User Preferences and “Wow” Diffusion. Fanjin Zhang, Jie Tang, Xueyi Liu, Zhenyu Hou, Yuxiao Dong, Jing Zhang,
 18 Sep 16, 2022
18 Sep 16, 2022

frida-based ceserver. iOS analysis is possible with Cheat Engine.
frida-ceserver frida-based ceserver. iOS analysis is possible with Cheat Engine. Original by Dark Byte. Usage Install frida on iOS. python main.py Cyd
 89 Jan 8, 2023
89 Jan 8, 2023

Official Code for ICML 2021 paper "Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline"
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline Ankit Goyal, Hei Law, Bowei Liu, Alejandro Newell, Jia Deng Internati
 115 Jan 4, 2023
115 Jan 4, 2023

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022
A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation(DANN), support Office-31 and Office-Home dataset
DANN A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation Prerequisites Linux or OSX NVIDIA GPU + CUDA (may CuDNN) and corre
 8 Apr 16, 2022
8 Apr 16, 2022
This is the dataset and code release of the OpenRooms Dataset.
This is the dataset and code release of the OpenRooms Dataset.
 95 Jan 8, 2023
95 Jan 8, 2023

🧪 Panel-Chemistry - exploratory data analysis and build powerful data and viz tools within the domain of Chemistry using Python and HoloViz Panel.
🧪📈 🐍. The purpose of the panel-chemistry project is to make it really easy for you to do DATA ANALYSIS and build powerful DATA AND VIZ APPLICATIONS within the domain of Chemistry using using Python and HoloViz Panel.
 97 Dec 8, 2022
97 Dec 8, 2022
spafe: Simplified Python Audio-Features Extraction
spafe aims to simplify features extractions from mono audio files. The library can extract of the following features: BFCC, LFCC, LPC, LPCC, MFCC, IMFCC, MSRCC, NGCC, PNCC, PSRCC, PLP, RPLP, Frequency-stats etc. It also provides various filterbank modules (Mel, Bark and Gammatone filterbanks) and other spectral statistics.
 310 Jan 1, 2023
310 Jan 1, 2023
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
Kats is a toolkit to analyze time series data, a lightweight, easy-to-use, and generalizable framework to perform time series analysis.
Kats, a kit to analyze time series data, a lightweight, easy-to-use, generalizable, and extendable framework to perform time series analysis, from understanding the key statistics and characteristics, detecting change points and anomalies, to forecasting future trends.
4.1k Dec 29, 2022

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

Segmentation and Identification of Vertebrae in CT Scans using CNN, k-means Clustering and k-NN
Segmentation and Identification of Vertebrae in CT Scans using CNN, k-means Clustering and k-NN If you use this code for your research, please cite ou
 41 Dec 8, 2022
41 Dec 8, 2022
MDAnalysis tool to calculate membrane curvature.
The MDAkit for membrane curvature analysis is part of the Google Summer of Code program and it is linked to a Code of Conduct.
 19 Oct 20, 2022
19 Oct 20, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022

NBEATSx: Neural basis expansion analysis with exogenous variables
NBEATSx: Neural basis expansion analysis with exogenous variables We extend the NBEATS model to incorporate exogenous factors. The resulting method, c
 100 Dec 31, 2022
100 Dec 31, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022
A set of functions and analysis classes for solvation structure analysis
SolvationAnalysis The macroscopic behavior of a liquid is determined by its microscopic structure. For ionic systems, like batteries and many enzymes,
19 Nov 24, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations This repository contains the data, scripts and baseline co
 51 Dec 17, 2022
51 Dec 17, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
213 Dec 26, 2022
A Dataset of Python Challenges for AI Research
Python Programming Puzzles (P3) This repo contains a dataset of python programming puzzles which can be used to teach and evaluate an AI's programming
 850 Dec 24, 2022
850 Dec 24, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

Source codes of CenterTrack++ in 2021 ICME Workshop on Big Surveillance Data Processing and Analysis
MOT Tracked object bounding box association (CenterTrack++) New association method based on CenterTrack. Two new branches (Tracked Size and IOU) are a
 36 Oct 4, 2022
36 Oct 4, 2022

Code implementation of "Sparsity Probe: Analysis tool for Deep Learning Models"
Sparsity Probe: Analysis tool for Deep Learning Models This repository is a limited implementation of Sparsity Probe: Analysis tool for Deep Learning
 3 Jun 9, 2021
3 Jun 9, 2021

InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
InsightFace: 2D and 3D Face Analysis Project on MXNet and PyTorch
 13.2k Jan 6, 2023
13.2k Jan 6, 2023
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
 75 Nov 2, 2022
75 Nov 2, 2022
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023

Pytorch implementation of MaskFlownet
MaskFlownet-Pytorch Unofficial PyTorch implementation of MaskFlownet (https://github.com/microsoft/MaskFlownet). Tested with: PyTorch 1.5.0 CUDA 10.1
 84 Nov 2, 2022
84 Nov 2, 2022
![[CVPR 2021] Monocular depth estimation using wavelets for efficiency](https://github.com/nianticlabs/wavelet-monodepth/raw/main/assets/combo_kitti.gif)
[CVPR 2021] Monocular depth estimation using wavelets for efficiency
Single Image Depth Prediction with Wavelet Decomposition Michaël Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit and Daniyar Turmukhambeto
 205 Jan 2, 2023
205 Jan 2, 2023
Paddle implementation for "Highly Efficient Knowledge Graph Embedding Learning with Closed-Form Orthogonal Procrustes Analysis" (NAACL 2021)
ProcrustEs-KGE Paddle implementation for Highly Efficient Knowledge Graph Embedding Learning with Orthogonal Procrustes Analysis 🙈 A more detailed re
 4 Jun 9, 2021
4 Jun 9, 2021
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022
Symbolic Parallel Adaptive Importance Sampling for Probabilistic Program Analysis in JAX
SYMPAIS: Symbolic Parallel Adaptive Importance Sampling for Probabilistic Program Analysis Overview | Installation | Documentation | Examples | Notebo
 4 Sep 13, 2022
4 Sep 13, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022
🔬 A curated list of awesome machine learning strategies & tools in financial market.
🔬 A curated list of awesome machine learning strategies & tools in financial market.
 1.6k Dec 30, 2022
1.6k Dec 30, 2022
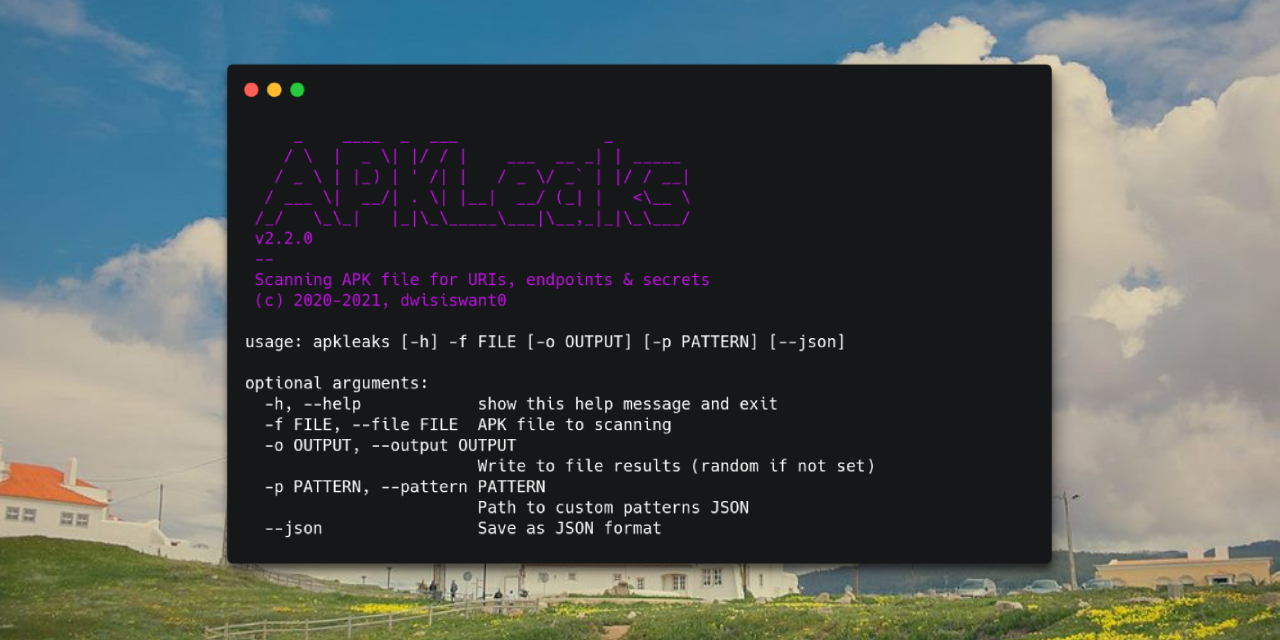
APKLeaks - Scanning APK file for URIs, endpoints & secrets.
APKLeaks - Scanning APK file for URIs, endpoints & secrets.
 3.5k Jan 9, 2023
3.5k Jan 9, 2023

Official repository for "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems"
Action-Based Conversations Dataset (ABCD) This respository contains the code and data for ABCD (Chen et al., 2021) Introduction Whereas existing goal-
 49 Oct 9, 2022
49 Oct 9, 2022

(AAAI2020)Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing
Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing This repository contains pytorch source code for AAAI2020 oral paper: Grapy-ML
 54 Aug 4, 2022
54 Aug 4, 2022
Solve various integral equations using numerical methods in Python
Solve Volterra and Fredholm integral equations This Python package estimates Volterra and Fredholm integral equations using known techniques. Installa
 18 Nov 28, 2022
18 Nov 28, 2022
A Python Module That Uses ANN To Predict A Stocks Price And Also Provides Accurate Technical Analysis With Many High Potential Implementations!
Stox A Module to predict the "close price" for the next day and give "technical analysis". It uses a Neural Network and the LSTM algorithm to predict
 31 Dec 16, 2022
31 Dec 16, 2022
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023