321 Repositories
Python gpu-memory Libraries

Neural Turing Machine (NTM) & Differentiable Neural Computer (DNC) with pytorch & visdom
Neural Turing Machine (NTM) & Differentiable Neural Computer (DNC) with pytorch & visdom Sample on-line plotting while training(avg loss)/testing(writ
 269 Nov 15, 2022
269 Nov 15, 2022

A3C LSTM Atari with Pytorch plus A3G design
NEWLY ADDED A3G A NEW GPU/CPU ARCHITECTURE OF A3C FOR SUBSTANTIALLY ACCELERATED TRAINING!! RL A3C Pytorch NEWLY ADDED A3G!! New implementation of A3C
 532 Jan 2, 2023
532 Jan 2, 2023
A memory-efficient implementation of DenseNets
efficient_densenet_pytorch A PyTorch =1.0 implementation of DenseNets, optimized to save GPU memory. Recent updates Now works on PyTorch 1.0! It uses
 1.4k Dec 25, 2022
1.4k Dec 25, 2022

Exploring Classification Equilibrium in Long-Tailed Object Detection, ICCV2021
Exploring Classification Equilibrium in Long-Tailed Object Detection (LOCE, ICCV 2021) Paper Introduction The conventional detectors tend to make imba
 52 Nov 21, 2022
52 Nov 21, 2022
Tool for generating Memory.scan() compatible instruction search patterns
scanpat Tool for generating Frida Memory.scan() compatible instruction search patterns. Powered by r2. Examples $ ./scanpat.py arm.ks:64 'sub sp, sp,
 13 Sep 19, 2022
13 Sep 19, 2022
Run Effective Large Batch Contrastive Learning on Limited Memory GPU
Gradient Cache Gradient Cache is a simple technique for unlimitedly scaling contrastive learning batch far beyond GPU memory constraint. This means tr
 198 Dec 29, 2022
198 Dec 29, 2022

Differentiable Neural Computers, Sparse Access Memory and Sparse Differentiable Neural Computers, for Pytorch
Differentiable Neural Computers and family, for Pytorch Includes: Differentiable Neural Computers (DNC) Sparse Access Memory (SAM) Sparse Differentiab
 302 Dec 14, 2022
302 Dec 14, 2022
A modified version of DeepMind's Alphafold2 to divide CPU part (MSA and template searching) and GPU part (prediction model)
ParallelFold Author: Bozitao Zhong This is a modified version of DeepMind's Alphafold2 to divide CPU part (MSA and template searching) and GPU part (p
 77 Dec 22, 2022
77 Dec 22, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022
Continuum Learning with GEM: Gradient Episodic Memory
Gradient Episodic Memory for Continual Learning Source code for the paper: @inproceedings{GradientEpisodicMemory, title={Gradient Episodic Memory
 360 Dec 27, 2022
360 Dec 27, 2022

In-Place Activated BatchNorm for Memory-Optimized Training of DNNs
In-Place Activated BatchNorm In-Place Activated BatchNorm for Memory-Optimized Training of DNNs In-Place Activated BatchNorm (InPlace-ABN) is a novel
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks
GPU-accelerated PyTorch implementation of Zero-shot User Intent Detection via Capsule Neural Networks This repository implements a capsule model Inten
 15 Dec 24, 2022
15 Dec 24, 2022
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
STMTrack This is the official implementation of the paper: STMTrack: Template-free Visual Tracking with Space-time Memory Networks. Setup Prepare Anac
 62 Dec 21, 2022
62 Dec 21, 2022

The MLOps platform for innovators 🚀
DS2.ai is an integrated AI operation solution that supports all stages from custom AI development to deployment. It is an AI-specialized platform service that collects data, builds a training dataset through data labeling, and enables automatic development of artificial intelligence and easy deployment and operation.
 9 Jan 3, 2023
9 Jan 3, 2023
Convert Python 3 code to CUDA code.
Py2CUDA Convert python code to CUDA. Usage To convert a python file say named py_file.py to CUDA, run python generate_cuda.py --file py_file.py --arch
 3 Jul 14, 2021
3 Jul 14, 2021

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023

A community run, 5-day PyTorch Deep Learning Bootcamp
Deep Learning Winter School, November 2107. Tel Aviv Deep Learning Bootcamp : http://deep-ml.com. About Tel-Aviv Deep Learning Bootcamp is an intensiv
 1.3k Sep 4, 2021
1.3k Sep 4, 2021

A very simple and small path tracer written in pytorch meant to be run on the GPU
MentisOculi Pytorch Path Tracer A very simple and small path tracer written in pytorch meant to be run on the GPU Why use pytorch and not some other c
 222 Dec 1, 2022
222 Dec 1, 2022

ocaml-torch provides some ocaml bindings for the PyTorch tensor library.
ocaml-torch provides some ocaml bindings for the PyTorch tensor library. This brings to OCaml NumPy-like tensor computations with GPU acceleration and tape-based automatic differentiation.
 369 Jan 3, 2023
369 Jan 3, 2023
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023

MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift
MemStream Implementation of MemStream: Memory-Based Anomaly Detection in Multi-Aspect Streams with Concept Drift . Siddharth Bhatia, Arjit Jain, Shivi
 61 Dec 2, 2022
61 Dec 2, 2022
QPT-Quick packaging tool 前项式Python环境快捷封装工具
QPT - Quick packaging tool 快捷封装工具 GitHub主页 | Gitee主页 QPT是一款可以“模拟”开发环境的多功能封装工具,一行命令即可将普通的Python脚本打包成EXE可执行程序,与此同时还可轻松引入CUDA等深度学习加速库, 尽可能在用户使用时复现您的开发环境。
 545 Dec 28, 2022
545 Dec 28, 2022
Complete U-net Implementation with keras
U Net Lowered with Keras Complete U-net Implementation with keras Original Paper Link : https://arxiv.org/abs/1505.04597 Special Implementations : The
 14 Oct 10, 2022
14 Oct 10, 2022
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
 27 Aug 19, 2022
27 Aug 19, 2022
Request based Python module(s) to help with the Newegg raffle.
Newegg Shuffle Python module(s) to help you with the Newegg raffle How to use $ git clone https://github.com/Matthew17-21/Newegg-Shuffle $ cd Newegg-S
 45 Dec 1, 2022
45 Dec 1, 2022
🔮 Execution time predictions for deep neural network training iterations across different GPUs.
Habitat: A Runtime-Based Computational Performance Predictor for Deep Neural Network Training Habitat is a tool that predicts a deep neural network's
 44 Dec 27, 2022
44 Dec 27, 2022
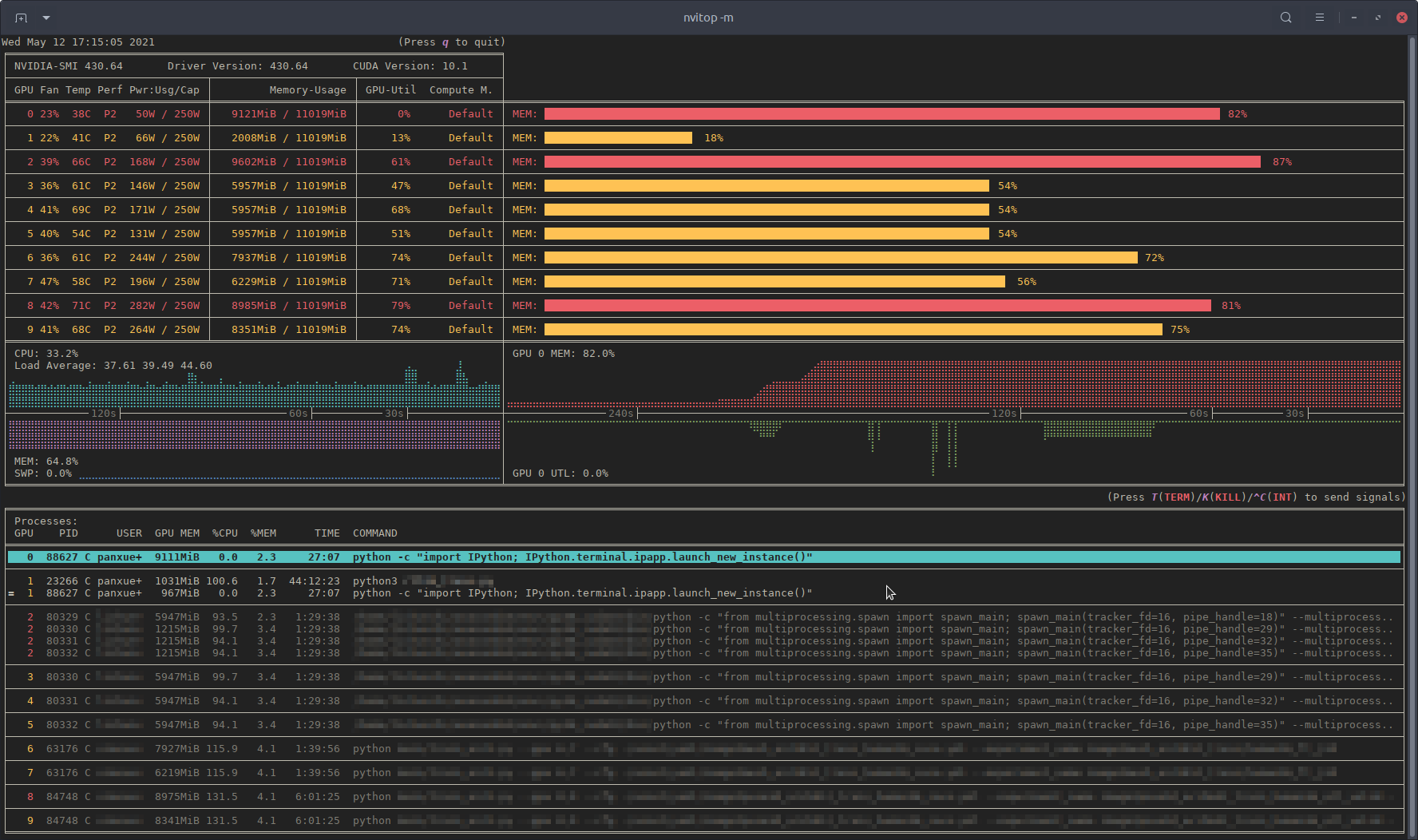
nvitop, an interactive NVIDIA-GPU process viewer, the one-stop solution for GPU process management
An interactive NVIDIA-GPU process viewer, the one-stop solution for GPU process management.
 1.3k Jan 2, 2023
1.3k Jan 2, 2023
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022
PyTorch Code of "Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spatiotemporal Dynamics"
Memory In Memory Networks It is based on the paper Memory In Memory: A Predictive Neural Network for Learning Higher-Order Non-Stationarity from Spati
 12 May 30, 2022
12 May 30, 2022
Official code repository of the paper Learning Associative Inference Using Fast Weight Memory by Schlag et al.
Learning Associative Inference Using Fast Weight Memory This repository contains the offical code for the paper Learning Associative Inference Using F
 18 Oct 12, 2022
18 Oct 12, 2022
A lightweight (serverless) native python parallel processing framework based on simple decorators and call graphs.
A lightweight (serverless) native python parallel processing framework based on simple decorators and call graphs, supporting both control flow and dataflow execution paradigms as well as de-centralized CPU & GPU scheduling.
 102 Jan 6, 2023
102 Jan 6, 2023

ActNN: Reducing Training Memory Footprint via 2-Bit Activation Compressed Training
ActNN : Activation Compressed Training This is the official project repository for ActNN: Reducing Training Memory Footprint via 2-Bit Activation Comp
 178 Jan 5, 2023
178 Jan 5, 2023
Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be streamed
iterable-subprocess Python utility function to communicate with a subprocess using iterables: for when data is too big to fit in memory and has to be
 5 Jul 10, 2022
5 Jul 10, 2022

Elara DB is an easy to use, lightweight NoSQL database that can also be used as a fast in-memory cache.
Elara DB is an easy to use, lightweight NoSQL database written for python that can also be used as a fast in-memory cache for JSON-serializable data. Includes various methods and features to manipulate data structures in-memory, protect database files and export data.
 101 Jan 4, 2023
101 Jan 4, 2023
Python function to stream unzip all the files in a ZIP archive: without loading the entire ZIP file or any of its files into memory at once
Python function to stream unzip all the files in a ZIP archive: without loading the entire ZIP file or any of its files into memory at once
206 Jan 2, 2023
This is a pytorch implementation of the NeurIPS paper GAN Memory with No Forgetting.
GAN Memory for Lifelong learning This is a pytorch implementation of the NeurIPS paper GAN Memory with No Forgetting. Please consider citing our paper
 43 Dec 27, 2022
43 Dec 27, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
 8.4k Jan 1, 2023
8.4k Jan 1, 2023
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022

TorchPQ is a python library for Approximate Nearest Neighbor Search (ANNS) and Maximum Inner Product Search (MIPS) on GPU using Product Quantization (PQ) algorithm.
Efficient implementations of Product Quantization and its variants using Pytorch and CUDA
 146 Dec 28, 2022
146 Dec 28, 2022

Official pytorch implementation of Rainbow Memory (CVPR 2021)
Rainbow Memory: Continual Learning with a Memory of Diverse Samples
 91 Dec 17, 2022
91 Dec 17, 2022

Training code of Spatial Time Memory Network. Semi-supervised video object segmentation.
Training-code-of-STM This repository fully reproduces Space-Time Memory Networks Performance on Davis17 val set&Weights backbone training stage traini
 128 Dec 11, 2022
128 Dec 11, 2022
A simple way to train and use PyTorch models with multi-GPU, TPU, mixed-precision
🤗 Accelerate was created for PyTorch users who like to write the training loop of PyTorch models but are reluctant to write and maintain the boilerplate code needed to use multi-GPUs/TPU/fp16.
 3.5k Jan 8, 2023
3.5k Jan 8, 2023
Learn computer graphics by writing GPU shaders!
This repo contains a selection of projects designed to help you learn the basics of computer graphics. We'll be writing shaders to render interactive two-dimensional and three-dimensional scenes.
 1.9k Jan 2, 2023
1.9k Jan 2, 2023

Visualization Toolbox for Long Short Term Memory networks (LSTMs)
Visualization Toolbox for Long Short Term Memory networks (LSTMs)
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
Segcache: a memory-efficient and scalable in-memory key-value cache for small objects
Segcache: a memory-efficient and scalable in-memory key-value cache for small objects This repo contains the code of Segcache described in the followi
 78 Jan 7, 2023
78 Jan 7, 2023
![[Open Source]. The improved version of AnimeGAN. Landscape photos/videos to anime](https://github.com/TachibanaYoshino/AnimeGANv2/raw/master/AnimeGANv2.png)
[Open Source]. The improved version of AnimeGAN. Landscape photos/videos to anime
[Open Source]. The improved version of AnimeGAN. Landscape photos/videos to anime
 4.4k Dec 27, 2022
4.4k Dec 27, 2022
Asynchronous Client for the worlds fastest in-memory geo-database Tile38
This is an asynchonous Python client for Tile38 that allows for fast and easy interaction with the worlds fastest in-memory geodatabase Tile38.
 53 Dec 29, 2022
53 Dec 29, 2022

Learning recognition/segmentation models without end-to-end training. 40%-60% less GPU memory footprint. Same training time. Better performance.
InfoPro-Pytorch The Information Propagation algorithm for training deep networks with local supervision. (ICLR 2021) Revisiting Locally Supervised Lea
 78 Dec 27, 2022
78 Dec 27, 2022
monolish: MONOlithic Liner equation Solvers for Highly-parallel architecture
monolish is a linear equation solver library that monolithically fuses variable data type, matrix structures, matrix data format, vendor specific data transfer APIs, and vendor specific numerical algebra libraries.
 179 Dec 21, 2022
179 Dec 21, 2022

An open-source library of algorithms to analyse time series in GPU and CPU.
An open-source library of algorithms to analyse time series in GPU and CPU.
 216 Dec 30, 2022
216 Dec 30, 2022

PINCE is a front-end/reverse engineering tool for the GNU Project Debugger (GDB), focused on games.
PINCE is a front-end/reverse engineering tool for the GNU Project Debugger (GDB), focused on games. However, it can be used for any reverse-engi
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
Guide: Finetune GPT2-XL (1.5 Billion Parameters) and GPT-NEO (2.7 B) on a single 16 GB VRAM V100 Google Cloud instance with Huggingface Transformers using DeepSpeed
Guide: Finetune GPT2-XL (1.5 Billion Parameters) and GPT-NEO (2.7 Billion Parameters) on a single 16 GB VRAM V100 Google Cloud instance with Huggingfa
 289 Jan 6, 2023
289 Jan 6, 2023
A highly efficient and modular implementation of Gaussian Processes in PyTorch
GPyTorch GPyTorch is a Gaussian process library implemented using PyTorch. GPyTorch is designed for creating scalable, flexible, and modular Gaussian
 3k Jan 2, 2023
3k Jan 2, 2023

Differentiable SDE solvers with GPU support and efficient sensitivity analysis.
PyTorch Implementation of Differentiable SDE Solvers This library provides stochastic differential equation (SDE) solvers with GPU support and efficie
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

Differentiable ODE solvers with full GPU support and O(1)-memory backpropagation.
PyTorch Implementation of Differentiable ODE Solvers This library provides ordinary differential equation (ODE) solvers implemented in PyTorch. Backpr
 4.4k Jan 4, 2023
4.4k Jan 4, 2023
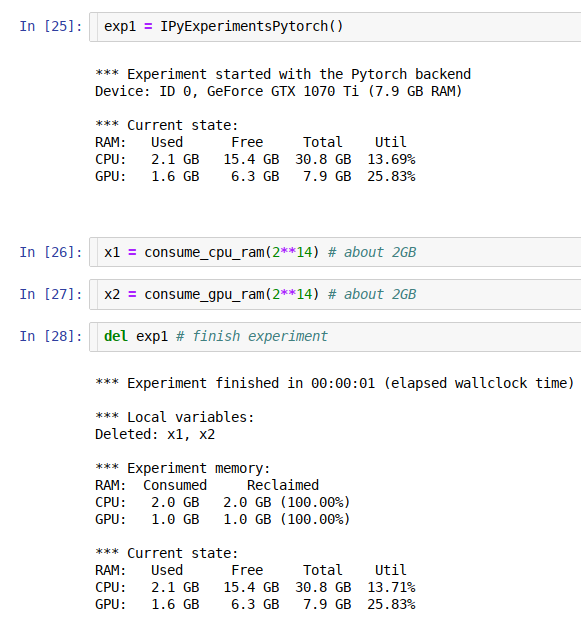
jupyter/ipython experiment containers for GPU and general RAM re-use
ipyexperiments jupyter/ipython experiment containers and utils for profiling and reclaiming GPU and general RAM, and detecting memory leaks. About Thi
 153 Dec 7, 2022
153 Dec 7, 2022
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
A Python module for getting the GPU status from NVIDA GPUs using nvidia-smi programmically in Python
GPUtil GPUtil is a Python module for getting the GPU status from NVIDA GPUs using nvidia-smi. GPUtil locates all GPUs on the computer, determines thei
 927 Dec 8, 2022
927 Dec 8, 2022

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases.
Vulkan Kompute The general purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabl
 1k Dec 26, 2022
1k Dec 26, 2022
BlazingSQL is a lightweight, GPU accelerated, SQL engine for Python. Built on RAPIDS cuDF.
A lightweight, GPU accelerated, SQL engine built on the RAPIDS.ai ecosystem. Get Started on app.blazingsql.com Getting Started | Documentation | Examp
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
cuML - RAPIDS Machine Learning Library
cuML - GPU Machine Learning Algorithms cuML is a suite of libraries that implement machine learning algorithms and mathematical primitives functions t
 3.1k Jan 4, 2023
3.1k Jan 4, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
 4.2k Jan 8, 2023
4.2k Jan 8, 2023
Python 3 Bindings for NVML library. Get NVIDIA GPU status inside your program.
py3nvml Documentation also available at readthedocs. Python 3 compatible bindings to the NVIDIA Management Library. Can be used to query the state of
 212 Jan 4, 2023
212 Jan 4, 2023
cuDF - GPU DataFrame Library
cuDF - GPU DataFrames NOTE: For the latest stable README.md ensure you are on the main branch. Resources cuDF Reference Documentation: Python API refe
5.2k Jan 8, 2023
Python interface to GPU-powered libraries
Package Description scikit-cuda provides Python interfaces to many of the functions in the CUDA device/runtime, CUBLAS, CUFFT, and CUSOLVER libraries
 924 Dec 26, 2022
924 Dec 26, 2022
ArrayFire: a general purpose GPU library.
ArrayFire is a general-purpose library that simplifies the process of developing software that targets parallel and massively-parallel architectures i
 4k Dec 29, 2022
4k Dec 29, 2022
CUDA integration for Python, plus shiny features
PyCUDA lets you access Nvidia's CUDA parallel computation API from Python. Several wrappers of the CUDA API already exist-so what's so special about P
 1.4k Jan 2, 2023
1.4k Jan 2, 2023

📊 A simple command-line utility for querying and monitoring GPU status
gpustat Just less than nvidia-smi? NOTE: This works with NVIDIA Graphics Devices only, no AMD support as of now. Contributions are welcome! Self-Promo
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A NumPy-compatible array library accelerated by CUDA
CuPy : A NumPy-compatible array library accelerated by CUDA Website | Docs | Install Guide | Tutorial | Examples | API Reference | Forum CuPy is an im
 6.6k Jan 5, 2023
6.6k Jan 5, 2023
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective. 10x Larger Models 10x Faster Trainin
8.4k Dec 30, 2022
Time series forecasting with PyTorch
Our article on Towards Data Science introduces the package and provides background information. Pytorch Forecasting aims to ease state-of-the-art time
 2.5k Jan 2, 2023
2.5k Jan 2, 2023
High-performance TensorFlow library for quantitative finance.
TF Quant Finance: TensorFlow based Quant Finance Library Table of contents Introduction Installation TensorFlow training Development roadmap Examples
 3.5k Jan 1, 2023
3.5k Jan 1, 2023
Tensorflow 2 Object Detection API kurulumu, GPU desteği, custom model hazırlama
Tensorflow 2 Object Detection API Bu tutorial, TensorFlow 2.x'in kararlı sürümü olan TensorFlow 2.3'ye yöneliktir. Bu, görüntülerde / videoda nesne a
 46 Nov 20, 2022
46 Nov 20, 2022
A Genetic Programming platform for Python with TensorFlow for wicked-fast CPU and GPU support.
Karoo GP Karoo GP is an evolutionary algorithm, a genetic programming application suite written in Python which supports both symbolic regression and
 149 Jan 9, 2023
149 Jan 9, 2023
A highly efficient and modular implementation of Gaussian Processes in PyTorch
GPyTorch GPyTorch is a Gaussian process library implemented using PyTorch. GPyTorch is designed for creating scalable, flexible, and modular Gaussian
3k Jan 2, 2023
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022

Out-of-Core DataFrames for Python, ML, visualize and explore big tabular data at a billion rows per second 🚀
What is Vaex? Vaex is a high performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular data
 7.7k Jan 1, 2023
7.7k Jan 1, 2023
cuDF - GPU DataFrame Library
cuDF - GPU DataFrames NOTE: For the latest stable README.md ensure you are on the main branch. Built based on the Apache Arrow columnar memory format,
5.2k Dec 31, 2022
ThunderGBM: Fast GBDTs and Random Forests on GPUs
Documentations | Installation | Parameters | Python (scikit-learn) interface What's new? ThunderGBM won 2019 Best Paper Award from IEEE Transactions o
 648 Dec 16, 2022
648 Dec 16, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
1.4k Dec 22, 2022
50% faster, 50% less RAM Machine Learning. Numba rewritten Sklearn. SVD, NNMF, PCA, LinearReg, RidgeReg, Randomized, Truncated SVD/PCA, CSR Matrices all 50+% faster
[Due to the time taken @ uni, work + hell breaking loose in my life, since things have calmed down a bit, will continue commiting!!!] [By the way, I'm
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
cuML - RAPIDS Machine Learning Library
cuML - GPU Machine Learning Algorithms cuML is a suite of libraries that implement machine learning algorithms and mathematical primitives functions t
3.1k Dec 28, 2022

Lazy Profiler is a simple utility to collect CPU, GPU, RAM and GPU Memory stats while the program is running.
lazyprofiler Lazy Profiler is a simple utility to collect CPU, GPU, RAM and GPU Memory stats while the program is running. Installation Use the packag
 28 Dec 9, 2022
28 Dec 9, 2022

BitPack is a practical tool to efficiently save ultra-low precision/mixed-precision quantized models.
BitPack is a practical tool that can efficiently save quantized neural network models with mixed bitwidth.
 36 Dec 2, 2022
36 Dec 2, 2022
DeepSpeech is an open source embedded (offline, on-device) speech-to-text engine which can run in real time on devices ranging from a Raspberry Pi 4 to high power GPU servers.
Project DeepSpeech DeepSpeech is an open-source Speech-To-Text engine, using a model trained by machine learning techniques based on Baidu's Deep Spee
 20.8k Jan 3, 2023
20.8k Jan 3, 2023
Ivy is a templated deep learning framework which maximizes the portability of deep learning codebases.
Ivy is a templated deep learning framework which maximizes the portability of deep learning codebases. Ivy wraps the functional APIs of existing frameworks. Framework-agnostic functions, libraries and layers can then be written using Ivy, with simultaneous support for all frameworks. Ivy currently supports Jax, TensorFlow, PyTorch, MXNet and Numpy. Check out the docs for more info!
 8.2k Jan 2, 2023
8.2k Jan 2, 2023
Numenta Platform for Intelligent Computing is an implementation of Hierarchical Temporal Memory (HTM), a theory of intelligence based strictly on the neuroscience of the neocortex.
NuPIC Numenta Platform for Intelligent Computing The Numenta Platform for Intelligent Computing (NuPIC) is a machine intelligence platform that implem
 6.2k Feb 12, 2021
6.2k Feb 12, 2021
ThunderGBM: Fast GBDTs and Random Forests on GPUs
Documentations | Installation | Parameters | Python (scikit-learn) interface What's new? ThunderGBM won 2019 Best Paper Award from IEEE Transactions o
647 Jan 4, 2023
ThunderSVM: A Fast SVM Library on GPUs and CPUs
What's new We have recently released ThunderGBM, a fast GBDT and Random Forest library on GPUs. add scikit-learn interface, see here Overview The miss
1.4k Dec 22, 2022

A flexible framework of neural networks for deep learning
Chainer: A deep learning framework Website | Docs | Install Guide | Tutorials (ja) | Examples (Official, External) | Concepts | ChainerX Forum (en, ja
 5.5k Feb 12, 2021
5.5k Feb 12, 2021
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021
Composable transformations of Python+NumPy programs: differentiate, vectorize, JIT to GPU/TPU, and more
JAX: Autograd and XLA Quickstart | Transformations | Install guide | Neural net libraries | Change logs | Reference docs | Code search News: JAX tops
11.4k Feb 13, 2021

The fastai deep learning library
Welcome to fastai fastai simplifies training fast and accurate neural nets using modern best practices Important: This documentation covers fastai v2,
 20.4k Feb 12, 2021
20.4k Feb 12, 2021
Tensors and Dynamic neural networks in Python with strong GPU acceleration
PyTorch is a Python package that provides two high-level features: Tensor computation (like NumPy) with strong GPU acceleration Deep neural networks b
 46.1k Feb 13, 2021
46.1k Feb 13, 2021
Monitor Memory usage of Python code
Memory Profiler This is a python module for monitoring memory consumption of a process as well as line-by-line analysis of memory consumption for pyth
 80 Nov 18, 2022
80 Nov 18, 2022
Diamond is a python daemon that collects system metrics and publishes them to Graphite (and others). It is capable of collecting cpu, memory, network, i/o, load and disk metrics. Additionally, it features an API for implementing custom collectors for gathering metrics from almost any source.
Diamond Diamond is a python daemon that collects system metrics and publishes them to Graphite (and others). It is capable of collecting cpu, memory,
 1.7k Jan 5, 2023
1.7k Jan 5, 2023

Scalene: a high-performance, high-precision CPU and memory profiler for Python
scalene: a high-performance CPU and memory profiler for Python by Emery Berger 中文版本 (Chinese version) About Scalene % pip install -U scalene Scalen
 138 Dec 30, 2022
138 Dec 30, 2022
Development tool to measure, monitor and analyze the memory behavior of Python objects in a running Python application.
README for pympler Before installing Pympler, try it with your Python version: python setup.py try If any errors are reported, check whether your Pyt
 996 Jan 1, 2023
996 Jan 1, 2023