2733 Repositories
Python ims-bearing-data-set Libraries
Set of tools to analyze Tinynuke samples
tinynuke-toolset You'll find in that repository a set of tools and scripts I developped to analyze Tinynuke samples. Dll extractor: script used to ext
 14 Aug 18, 2022
14 Aug 18, 2022
Obsidian tools - a Python package for analysing an Obsidian.md vault
obsidiantools is a Python package for getting structured metadata about your Obsidian.md notes and analysing your vault.
 153 Jan 4, 2023
153 Jan 4, 2023
A demo of a data science project using Kedro
iris Overview This is your new Kedro project, which was generated using Kedro 0.17.4. Take a look at the Kedro documentation to get started. Rules and
 14 Oct 14, 2022
14 Oct 14, 2022
django-dashing is a customisable, modular dashboard application framework for Django to visualize interesting data about your project. Inspired in the dashboard framework Dashing
django-dashing django-dashing is a customisable, modular dashboard application framework for Django to visualize interesting data about your project.
 703 Dec 22, 2022
703 Dec 22, 2022
Integrated set of Django applications addressing authentication, registration, account management as well as 3rd party (social) account authentication.
Welcome to django-allauth! Integrated set of Django applications addressing authentication, registration, account management as well as 3rd party (soc
 7.7k Jan 3, 2023
7.7k Jan 3, 2023
OnTime is a small python that you set a time and on that time, app will send you notification and also play an alarm.
OnTime Always be OnTime! What is OnTime? OnTime is a small python that you set a time and on that time, app will send you notification and also play a
 11 Jan 16, 2022
11 Jan 16, 2022
Produces a summary CSV report of an Amber Electric customer's energy consumption and cost data.
Amber Electric Usage Summary This is a command line tool that produces a summary CSV report of an Amber Electric customer's energy consumption and cos
 12 May 26, 2022
12 May 26, 2022

Rafael Project- Classifying rockets to different types using data science algorithms.
Rocket-Classify Rafael Project- Classifying rockets to different types using data science algorithms. In this project we received data base with data
 5 Sep 18, 2021
5 Sep 18, 2021
![[ArXiv 2021] Data-Efficient Instance Generation from Instance Discrimination](https://github.com/genforce/insgen/raw/main/docs/assets/framework.jpg)
[ArXiv 2021] Data-Efficient Instance Generation from Instance Discrimination
InsGen - Data-Efficient Instance Generation from Instance Discrimination Data-Efficient Instance Generation from Instance Discrimination Ceyuan Yang,
 93 Dec 25, 2022
93 Dec 25, 2022
Shape Matching of Real 3D Object Data to Synthetic 3D CADs (3DV project @ ETHZ)
Real2CAD-3DV Shape Matching of Real 3D Object Data to Synthetic 3D CADs (3DV project @ ETHZ) Group Member: Yue Pan, Yuanwen Yue, Bingxin Ke, Yujie He
 24 Jun 22, 2022
24 Jun 22, 2022
A daily updated JSON dataset of all the Open House London venues, events, and metadata
Open House London listings data All of it. Automatically scraped hourly with updates committed to git, autogenerated per-day CSV's, and autogenerated
 4 Jan 1, 2022
4 Jan 1, 2022
A set of tools for converting a darknet dataset to COCO format working with YOLOX
darknet格式数据→COCO darknet训练数据目录结构(详情参见dataset/darknet): darknet ├── class.names ├── gen_config.data ├── gen_train.txt ├── gen_valid.txt └── images
 148 Jan 3, 2023
148 Jan 3, 2023
lightweight, fast and robust columnar dataframe for data analytics with online update
streamdf Streamdf is a lightweight data frame library built on top of the dictionary of numpy array, developed for Kaggle's time-series code competiti
 23 May 19, 2022
23 May 19, 2022
CS 506 - Computational Tools for Data Science
CS 506 - Computational Tools for Data Science Code, slides, and notes for Boston University CS506 Fall 2021 The Final Project Repository can be found
 14 Mar 23, 2022
14 Mar 23, 2022
An all-inclusive Python framework for the Riot Games League of Legends API. We focus on making the data easy and fun to work with, while providing all the tools necessary to create a website or do data analysis.
Cassiopeia A Python adaptation of the Riot Games League of Legends API (https://developer.riotgames.com/). Cassiopeia is the sister library to Orianna
 473 Jan 7, 2023
473 Jan 7, 2023
Learn how to responsibly deliver value with ML.
Made With ML Applied ML · MLOps · Production Join 30K+ developers in learning how to responsibly deliver value with ML. 🔥 Among the top MLOps reposit
 32k Dec 30, 2022
32k Dec 30, 2022

Visions provides an extensible suite of tools to support common data analysis operations
Visions And these visions of data types, they kept us up past the dawn. Visions provides an extensible suite of tools to support common data analysis
 168 Dec 28, 2022
168 Dec 28, 2022
An open-source Python project series where beginners can contribute and practice coding.
Python Mini Projects A collection of easy Python small projects to help you improve your programming skills. Table Of Contents Aim Of The Project Cont
 491 Jan 4, 2023
491 Jan 4, 2023
An unofficial python API for trading on the DeGiro platform, with the ability to get real time data and historical data.
DegiroAPI An unofficial API for the trading platform Degiro written in Python with the ability to get real time data and historical data for products.
 5 Dec 16, 2022
5 Dec 16, 2022
jsoooooooon derulo - Make sure your 'jason derulo' is featured as the first part of your json data
jsonderulo Make sure your 'jason derulo' is featured as the first part of your json data Install: # python pip install jsonderulo poetry add jsonderul
 3 Sep 13, 2021
3 Sep 13, 2021
A set of Python scripts to surpass human limits in accomplishing simple tasks.
Human benchmark fooler Summary A set of Python scripts with Selenium designed to surpass human limits in accomplishing simple tasks available on https
 3 Feb 10, 2022
3 Feb 10, 2022
Tools to help record data from Qiskit jobs
archiver4qiskit Tools to help record data from Qiskit jobs. Install with pip install git+https://github.com/NCCR-SPIN/archiver4qiskit.git Import the
 0 Dec 10, 2021
0 Dec 10, 2021
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
This reporistory contains the test-dev data of the paper "xGQA: Cross-lingual Visual Question Answering".
 18 Dec 9, 2022
18 Dec 9, 2022

“Data Augmentation for Cross-Domain Named Entity Recognition” (EMNLP 2021)
Data Augmentation for Cross-Domain Named Entity Recognition Authors: Shuguang Chen, Gustavo Aguilar, Leonardo Neves and Thamar Solorio This repository
 18 Sep 10, 2022
18 Sep 10, 2022

Python solutions to Codeforces problems
CodeForces This repository is dedicated to my Python solutions for CodeForces problems. Feel free to copy, contribute and/or comment. If you find any
 15 Dec 20, 2022
15 Dec 20, 2022
Python code written to utilize the Korlan usb2can hardware to send and receive data over the can-bus on a 2008 Nissan 350z
nissan_ecu_hacking Python code written to utilize the Korlan usb2can hardware to send and receive data over the can-bus on a 2008 Nissan 350z My goal
 11 Sep 24, 2022
11 Sep 24, 2022

Pokemon catch events project to demonstrate data pipeline on AWS
Pokemon Catches Data Pipeline This is a sample project to practice end-to-end data project; Terraform is used to deploy infrastructure; Kafka is the t
 4 Sep 3, 2021
4 Sep 3, 2021
Sample project showing reliable data ingestion application using FastAPI and dramatiq
Create and deploy a reliable data ingestion service with FastAPI, SQLModel and Dramatiq This is the source code for the data ingestion service explain
 31 Nov 30, 2022
31 Nov 30, 2022

Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code
A Python framework for creating reproducible, maintainable and modular data science code.
 7.9k Jan 1, 2023
7.9k Jan 1, 2023

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022

A simple script & container to pull COVID data from covidlive.com.au and post a summary to a slack channel
CovidLive AU Summary Slackbot This bot is a very simple slackbot that pulls data, summarises and posts up to date AU COVID stats to a provided slack c
 3 Dec 18, 2021
3 Dec 18, 2021
Related resources for our EMNLP 2021 paper Plan-then-Generate: Controlled Data-to-Text Generation via Planning
Plan-then-Generate: Controlled Data-to-Text Generation via Planning Authors: Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier Code
 61 Jan 3, 2023
61 Jan 3, 2023
This repository contains a set of codes to run (i.e., train, perform inference with, evaluate) a diarization method called EEND-vector-clustering.
EEND-vector clustering The EEND-vector clustering (End-to-End-Neural-Diarization-vector clustering) is a speaker diarization framework that integrates
 45 Dec 26, 2022
45 Dec 26, 2022

A visualization of people a user follows on Twitter
Twitter-Map This software allows the user to create maps of Twitter accounts. Installation git clone [email protected]:OGreenwood672/Twitter-Map.git cd T
 12 Jul 20, 2022
12 Jul 20, 2022
DYA ( Ditch YouTube API ) is a package created to power the user with YouTube Data API functionality without any API Key
Ditch YouTubeAPI (BETA) DYA ( Ditch YouTube API ) is a package created to power the user with YouTube Data API functionality without any API Key Detai
 23 Dec 22, 2022
23 Dec 22, 2022

Using Python to scrape some basic player information from www.premierleague.com and then use Pandas to analyse said data.
PremiershipPlayerAnalysis Using Python to scrape some basic player information from www.premierleague.com and then use Pandas to analyse said data. No
 5 Sep 6, 2021
5 Sep 6, 2021
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
Selene is a Python library and command line interface for training deep neural networks from biological sequence data such as genomes.
 323 Jan 1, 2023
323 Jan 1, 2023
Home Assistant integration for energy consumption data from UK SMETS (Smart) meters using the Hildebrand Glow API.
Hildebrand Glow (DCC) Integration Home Assistant integration for energy consumption data from UK SMETS (Smart) meters using the Hildebrand Glow API. T
 153 Dec 30, 2022
153 Dec 30, 2022
Fix datetime EXIF data in photos downloaded from Google Takeout
fix-google-takeout Warning Use at your own risk. Backup your photos. Overview Google takeout for photos
 20 Nov 5, 2022
20 Nov 5, 2022

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
load .txt to train YOLOX, same as Yolo others
YOLOX train your data you need generate data.txt like follow format (per line- one image). prepare one data.txt like this: img_path1 x1,y1,x2,y2,clas
 18 Aug 18, 2022
18 Aug 18, 2022

A simple Python library to integrate with the Heron Data API
Heron Python This library provides easy access to the Heron Data API from applications written in Python. Documentation No language-specific docs are
 11 Nov 11, 2022
11 Nov 11, 2022
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
Real-ESRGAN Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data Ported from https://github.com/xinntao/Real-ESRGAN Depend
 44 Dec 27, 2022
44 Dec 27, 2022

G-NIA model from "Single Node Injection Attack against Graph Neural Networks" (CIKM 2021)
Single Node Injection Attack against Graph Neural Networks This repository is our Pytorch implementation of our paper: Single Node Injection Attack ag
 18 Nov 21, 2022
18 Nov 21, 2022

Fully reproducible, Dockerized, step-by-step, tutorial on how to mock a "real-time" Kafka data stream from a timestamped csv file. Detailed blog post published on Towards Data Science.
time-series-kafka-demo Mock stream producer for time series data using Kafka. I walk through this tutorial and others here on GitHub and on my Medium
 26 Nov 15, 2022
26 Nov 15, 2022

Lux Academy & Data Science East Africa Python Boot Camp, Building and Deploying Flask Application Using Docker Demo App.
Flask and Docker Application Demo A Docker image is a read-only, inert template that comes with instructions for deploying containers. In Docker, ever
 11 Oct 29, 2022
11 Oct 29, 2022

A simple, configurable application and set of services to monitor multiple raspberry pi's on a network.
rpi-info-monitor A simple, configurable application and set of services to monitor multiple raspberry pi's on a network. It can be used in a terminal
 11 May 22, 2022
11 May 22, 2022

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
A library for interacting with Path of Exile game and economy data, and a unique loot filter generation framework.
wraeblast A library for interfacing with Path of Exile game and economy data, and a set of item filters geared towards trade league players. Filter Ge
 29 Aug 28, 2022
29 Aug 28, 2022
We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. 🕵️
Pardus Lookout We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. The application i
 19 Nov 18, 2022
19 Nov 18, 2022
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
Functional Data Analysis, or FDA, is the field of Statistics that analyses data that depend on a continuous parameter.
Functional Data Analysis Python package
 184 Dec 27, 2022
184 Dec 27, 2022
The FinQA dataset from paper: FinQA: A Dataset of Numerical Reasoning over Financial Data
Data and code for EMNLP 2021 paper "FinQA: A Dataset of Numerical Reasoning over Financial Data"
 114 Dec 29, 2022
114 Dec 29, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
Bot for Telegram data Analysis
Bot Scraper for telegram This bot use an AI to Work powered by BOG Team you must do the following steps to make the bot functional: Install the requir
 8 Nov 28, 2022
8 Nov 28, 2022
Kyrie Eleison - The best and unique way to encrypt some data or a file safely
Encrypt your important data and files easily and safely with Kyrie Eleison.
 39 Oct 27, 2022
39 Oct 27, 2022

 8 Nov 26, 2022
8 Nov 26, 2022

This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Technique for Text Classification
The baseline code is for EDA: Easy Data Augmentation techniques for boosting performance on text classification tasks
 81 Dec 9, 2022
81 Dec 9, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
81 Dec 9, 2022
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that data.
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that
 29 Aug 9, 2022
29 Aug 9, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023

FLAML is a lightweight Python library that finds accurate machine learning models automatically, efficiently and economically
FLAML - Fast and Lightweight AutoML
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

skimpy is a light weight tool that provides summary statistics about variables in data frames within the console.
skimpy Welcome Welcome to skimpy! skimpy is a light weight tool that provides summary statistics about variables in data frames within the console. Th
 267 Dec 29, 2022
267 Dec 29, 2022

The Devils Eye is an OSINT tool that searches the Darkweb for onion links and descriptions that match with the users query without requiring the use for Tor.
The Devil's Eye searches the darkweb for information relating to the user's query and returns the results including .onion links and their description
 135 Dec 31, 2022
135 Dec 31, 2022

Python based tool to extract forensic info from EventTranscript.db (Windows Diagnostic Data)
EventTranscriptParser EventTranscriptParser is python based tool to extract forensically useful details from EventTranscript.db (Windows Diagnostic Da
 24 Nov 18, 2022
24 Nov 18, 2022
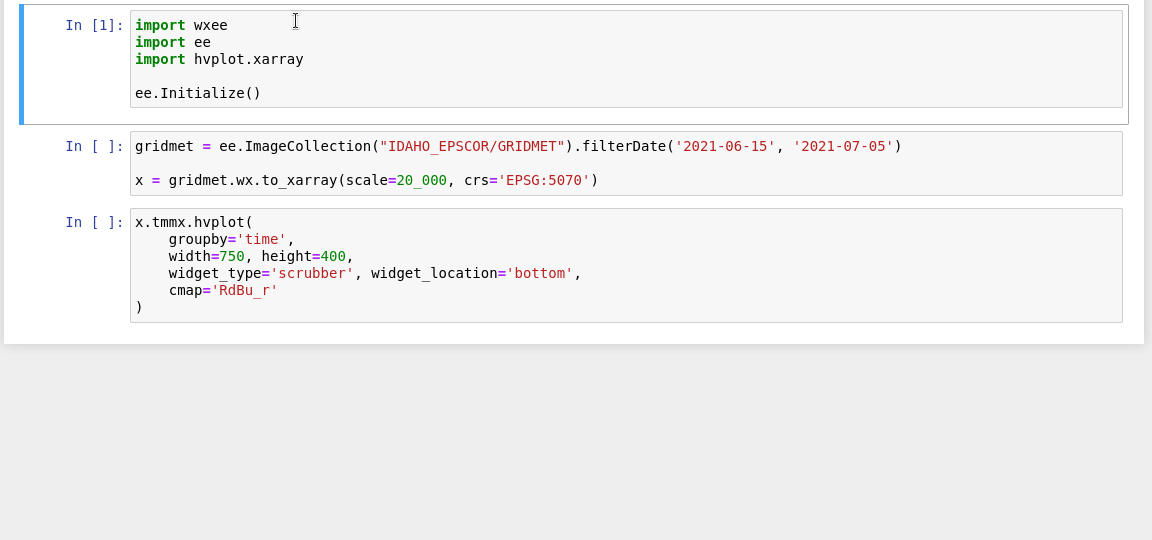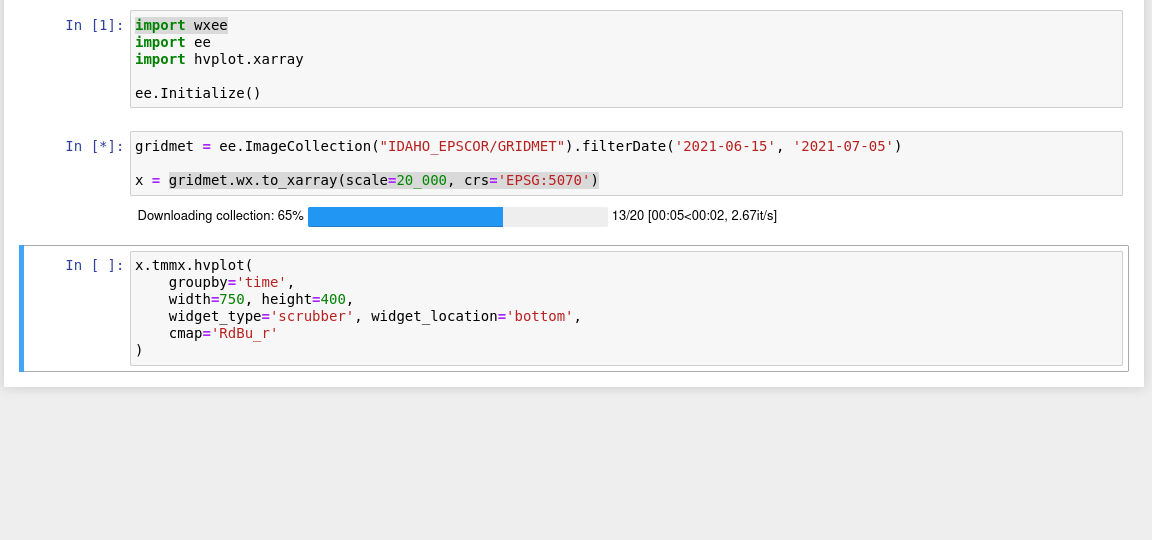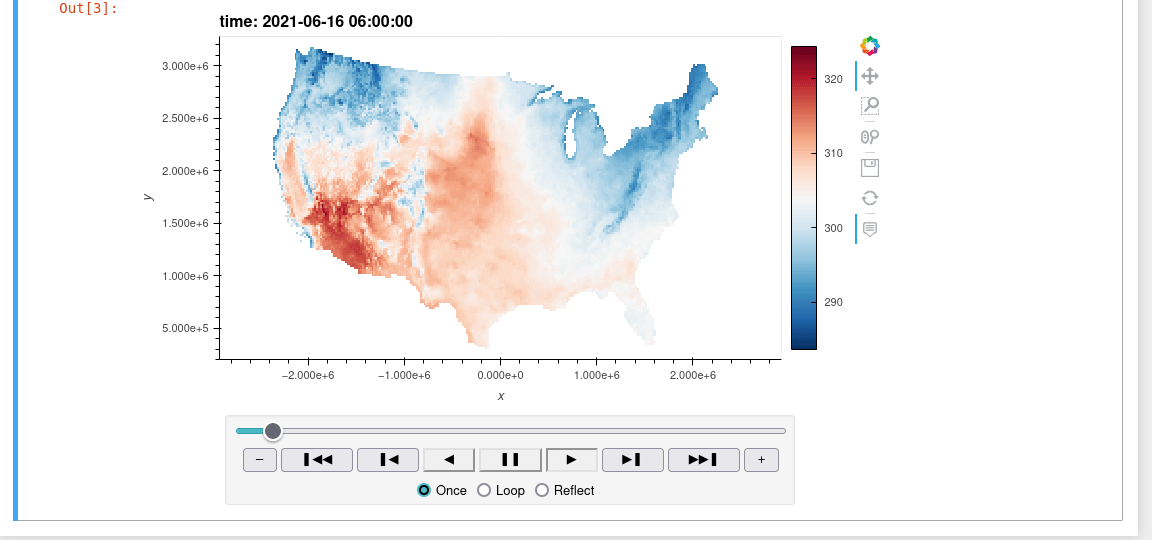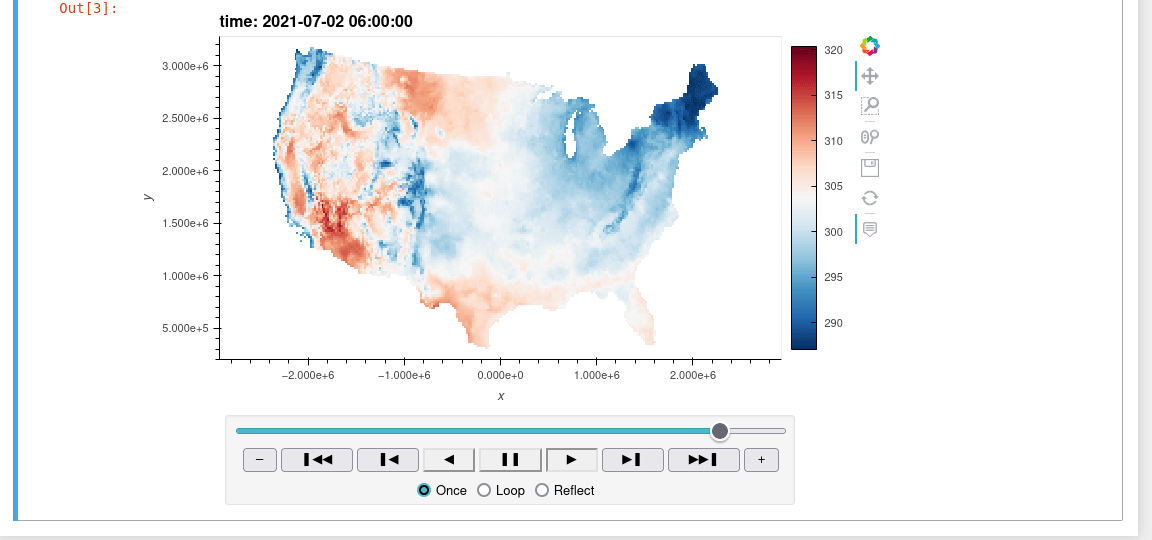
A Python interface between Earth Engine and xarray for processing weather and climate data
wxee What is wxee? wxee was built to make processing gridded, mesoscale time series weather and climate data quick and easy by integrating the data ca
 160 Dec 31, 2022
160 Dec 31, 2022

A data parser for the internal syncing data format used by Fog of World.
A data parser for the internal syncing data format used by Fog of World. The parser is not designed to be a well-coded library with good performance, it is more like a demo for showing the data structure.
 40 Dec 12, 2022
40 Dec 12, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
code for paper "Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning" by Zhongzheng Ren*, Raymond A. Yeh*, Alexander G. Schwing.
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning Overview This code is for paper: Not All Unlabeled Data are Equa
 22 Nov 23, 2022
22 Nov 23, 2022

Goblyn is a Python tool focused to enumeration and capture of website files metadata.
Goblyn Metadata Enumeration What's Goblyn? Goblyn is a tool focused to enumeration and capture of website files metadata. How it works? Goblyn will se
 46 Nov 22, 2022
46 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Coming soon!
ToxiChat Code and data for the EMNLP 2021 paper "Just Say No: Analyzing the Stance of Neural Dialogue Generation in Offensive Contexts". Install depen
 11 Jan 1, 2023
11 Jan 1, 2023
Framework for creating efficient data processing pipelines
Aqueduct Framework for creating efficient data processing pipelines. Contact Feel free to ask questions in telegram t.me/avito-ml Key Features Increas
 137 Dec 29, 2022
137 Dec 29, 2022
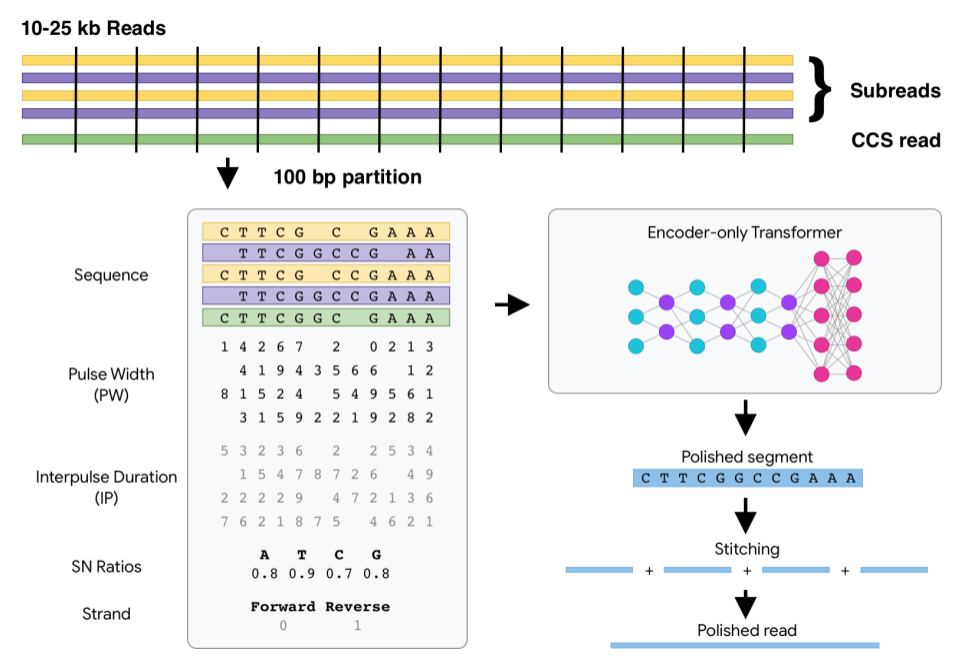
DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS) data.
DeepConsensus DeepConsensus uses gap-aware sequence transformers to correct errors in Pacific Biosciences (PacBio) Circular Consensus Sequencing (CCS)
 149 Dec 19, 2022
149 Dec 19, 2022
Ranking Models in Unlabeled New Environments (iccv21)
Ranking Models in Unlabeled New Environments Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch 1.7.0 + torchivision 0.8.1
 14 Dec 17, 2021
14 Dec 17, 2021
Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad to your characters in Modo.
Applicator Kit for Modo Applicator Kit for Modo allow you to apply Apple ARKit Face Tracking data from your iPhone or iPad with a TrueDepth camera to
 3 Aug 24, 2021
3 Aug 24, 2021

A Red Team tool for exfiltrating sensitive data from Jira tickets.
Jir-thief This Module will connect to Jira's API using an access token, export to a word .doc, and download the Jira issues that the target has access
 82 Dec 12, 2022
82 Dec 12, 2022
pywinauto is a set of python modules to automate the Microsoft Windows GUI
pywinauto is a set of python modules to automate the Microsoft Windows GUI. At its simplest it allows you to send mouse and keyboard actions to windows dialogs and controls, but it has support for more complex actions like getting text data.
 3.8k Jan 6, 2023
3.8k Jan 6, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022

Official Python wrapper for the Quantel Finance API
Quantel is a powerful financial data and insights API. It provides easy access to world-class financial information. Quantel goes beyond just financial statements, giving users valuable information like insider transactions, major shareholder transactions, share ownership, peers, and so much more.
 47 Oct 16, 2022
47 Oct 16, 2022

Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown.
Evidence enables analysts to deliver a polished business intelligence system using SQL and markdown
 915 Dec 26, 2022
915 Dec 26, 2022

prettymaps - A minimal Python library to draw customized maps from OpenStreetMap data.
A small set of Python functions to draw pretty maps from OpenStreetMap data. Based on osmnx, matplotlib and shapely libraries.
 9k Jan 8, 2023
9k Jan 8, 2023
Auto-updating data to assist in investment to NEPSE
Symbol Ratios Summary Sector LTP Undervalued Bonus % MEGA Strong Commercial Banks 368 5 10 JBBL Strong Development Banks 568 5 10 SIFC Strong Finance
 16 Nov 1, 2022
16 Nov 1, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
Public API client for GETTR, a "non-bias [sic] social network," designed for data archival and analysis.
GoGettr GoGettr is an API client for GETTR, a "non-bias [sic] social network." (We will not reward their domain with a hyperlink.) GoGettr is built an
 72 Dec 14, 2022
72 Dec 14, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
Code for the KDD 2021 paper 'Filtration Curves for Graph Representation'
Filtration Curves for Graph Representation This repository provides the code from the KDD'21 paper Filtration Curves for Graph Representation. Depende
 16 Oct 16, 2022
16 Oct 16, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Generative Models as a Data Source for Multiview Representation Learning
GenRep Project Page | Paper Generative Models as a Data Source for Multiview Representation Learning Ali Jahanian, Xavier Puig, Yonglong Tian, Phillip
 81 Dec 3, 2022
81 Dec 3, 2022

Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database
SpiderFoot Neo4j Tools Import, visualize, and analyze SpiderFoot OSINT data in Neo4j, a graph database Step 1: Installation NOTE: This installs the sf
 42 Dec 26, 2022
42 Dec 26, 2022

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023
Low code JSON to extract data in one line
JSON Inline Low code JSON to extract data in one line ENG RU Installation pip install json-inline Usage Rules Modificator Description ?key:value Searc
 12 Mar 9, 2022
12 Mar 9, 2022
A Pythonic Data Catalog powered by Ray that brings exabyte-level scalability and fast, ACID-compliant, change-data-capture to your big data workloads.
DeltaCAT DeltaCAT is a Pythonic Data Catalog powered by Ray. Its data storage model allows you to define and manage fast, scalable, ACID-compliant dat
 45 Oct 15, 2022
45 Oct 15, 2022
Doing set operations on files considered as sets of lines
CLI tool that can be used to do set operations like union on files considering them as a set of lines. Notes It ignores all empty lines with whitespac
 11 Sep 6, 2022
11 Sep 6, 2022

Data Preparation, Processing, and Visualization for MoVi Data
MoVi-Toolbox Data Preparation, Processing, and Visualization for MoVi Data, https://www.biomotionlab.ca/movi/ MoVi is a large multipurpose dataset of
 51 Nov 27, 2022
51 Nov 27, 2022

Part-Aware Data Augmentation for 3D Object Detection in Point Cloud
Part-Aware Data Augmentation for 3D Object Detection in Point Cloud This repository contains a reference implementation of our Part-Aware Data Augment
 62 Jan 3, 2023
62 Jan 3, 2023
Official repository with code and data accompanying the NAACL 2021 paper "Hurdles to Progress in Long-form Question Answering" (https://arxiv.org/abs/2103.06332).
Hurdles to Progress in Long-form Question Answering This repository contains the official scripts and datasets accompanying our NAACL 2021 paper, "Hur
 41 Nov 8, 2022
41 Nov 8, 2022