674 Repositories
Python korean-nlp Libraries

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

Data augmentation for NLP, accepted at EMNLP 2021 Findings
AEDA: An Easier Data Augmentation Technique for Text Classification This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Techni
 81 Dec 9, 2022
81 Dec 9, 2022
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks A Transformer-based library for SocialNLP classification tasks. Currently
 298 Jan 7, 2023
298 Jan 7, 2023

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022
pysentimiento: A Python toolkit for Sentiment Analysis and Social NLP tasks
A Python multilingual toolkit for Sentiment Analysis and Social NLP tasks
297 Dec 29, 2022
Collection of NLP model explanations and accompanying analysis tools
Thermostat is a large collection of NLP model explanations and accompanying analysis tools. Combines explainability methods from the captum library wi
 126 Nov 22, 2022
126 Nov 22, 2022
Ray-based parallel data preprocessing for NLP and ML.
Wrangl Ray-based parallel data preprocessing for NLP and ML. pip install wrangl # for latest pip install git+https://github.com/vzhong/wrangl See exa
 33 Dec 27, 2022
33 Dec 27, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
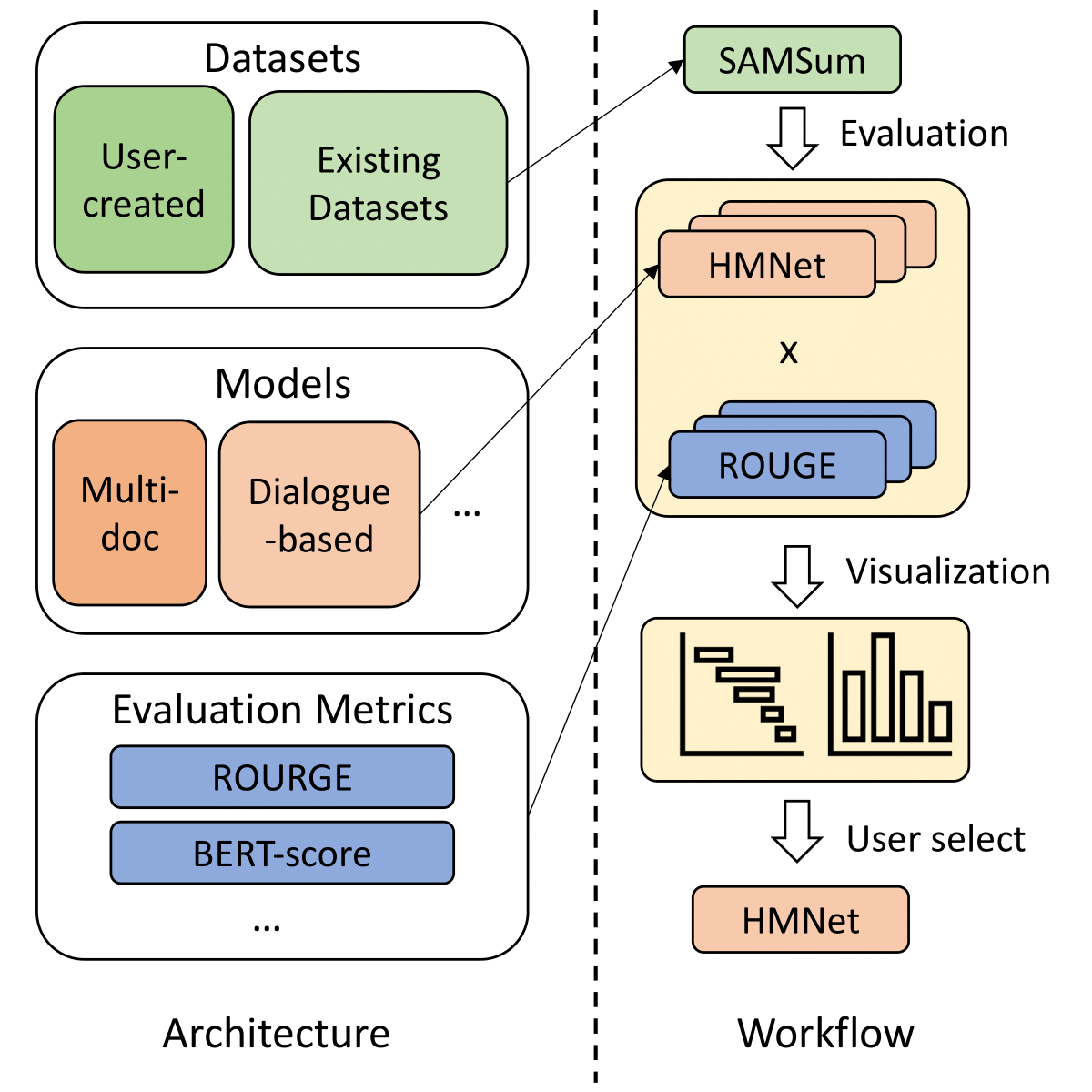
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

Türkçe küfürlü içerikleri bulan bir yapay zeka kütüphanesi / An ML library for profanity detection in Turkish sentences
"Kötü söz sahibine aittir." -Anonim Nedir? sinkaf uygunsuz yorumların bulunmasını sağlayan bir python kütüphanesidir. Farkı nedir? Diğer algoritmalard
 4 Feb 18, 2022
4 Feb 18, 2022
Ask for weather information like a human
weather-nlp About Ask for weather information like a human. Goals Understand typical questions like: Hourly temperatures in Potsdam on 2020-09-15. Rai
 5 Oct 29, 2022
5 Oct 29, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
This repo is to provide a list of literature regarding Deep Learning on Graphs for NLP
 230 Nov 22, 2022
230 Nov 22, 2022
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics.
Simple tool/toolkit for evaluating NLG (Natural Language Generation) offering various automated metrics. Jury offers a smooth and easy-to-use interface. It uses datasets for underlying metric computation, and hence adding custom metric is easy as adopting datasets.Metric.
 129 Jan 6, 2023
129 Jan 6, 2023

A BERT-based reverse dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end / back-end 임용
 94 Dec 8, 2022
94 Dec 8, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022

A complete NLP guideline for enthusiasts
NLP-NINJA A complete guide for Natural Language Processing in Python Table of Contents S.No. Topic Level Meaning 1 Tokenization 🤍 Beginner 2 Stemming
 22 Dec 27, 2022
22 Dec 27, 2022
Natural Language Processing library built with AllenNLP 🌲🌱
Custom Natural Language Processing with big and small models 🌲🌱
65 Sep 13, 2022

FairyTailor: Multimodal Generative Framework for Storytelling
FairyTailor: Multimodal Generative Framework for Storytelling
 172 Dec 30, 2022
172 Dec 30, 2022
Code for ACL 21: Generating Query Focused Summaries from Query-Free Resources
marge This repository releases the code for Generating Query Focused Summaries from Query-Free Resources. Please cite the following paper [bib] if you
 28 Nov 10, 2022
28 Nov 10, 2022
This repository contains the code for "Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP".
Self-Diagnosis and Self-Debiasing This repository contains the source code for Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based
 62 Dec 12, 2022
62 Dec 12, 2022
open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
中文开放信息抽取系统, open-information-extraction-system, build open-knowledge-graph(SPO, subject-predicate-object) by pyltp(version==3.4.0)
 7 Nov 2, 2022
7 Nov 2, 2022
Code for "Finetuning Pretrained Transformers into Variational Autoencoders"
transformers-into-vaes Code for Finetuning Pretrained Transformers into Variational Autoencoders (our submission to NLP Insights Workshop 2021). Gathe
 22 Nov 26, 2022
22 Nov 26, 2022
Machine learning models from Singapore's NLP research community
SG-NLP Machine learning models from Singapore's natural language processing (NLP) research community. sgnlp is a Python package that allows you to eas
 21 Dec 17, 2022
21 Dec 17, 2022

Scraping and analysis of leetcode-compensations page.
Leetcode compensations report Scraping and analysis of leetcode-compensations page.
 96 Jan 1, 2023
96 Jan 1, 2023
自然言語で書かれた時間情報表現を抽出/規格化するルールベースの解析器
ja-timex 自然言語で書かれた時間情報表現を抽出/規格化するルールベースの解析器 概要 ja-timex は、現代日本語で書かれた自然文に含まれる時間情報表現を抽出しTIMEX3と呼ばれるアノテーション仕様に変換することで、プログラムが利用できるような形に規格化するルールベースの解析器です。
 116 Nov 9, 2022
116 Nov 9, 2022
Code Repo for the ACL21 paper "Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning"
Common Sense Beyond English: Evaluating and Improving Multilingual LMs for Commonsense Reasoning This is the Github repository of our paper, "Common S
 19 Nov 30, 2022
19 Nov 30, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

NLPShala , the best IDE for all Natural language processing tasks.
The revolutionary IDE for all NLP (Natural language processing) stuffs on the internet.
 3 Aug 8, 2021
3 Aug 8, 2021
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
47 Sep 5, 2022

A text augmentation tool for named entity recognition.
neraug This python library helps you with augmenting text data for named entity recognition. Augmentation Example Reference from An Analysis of Simple
 48 Oct 11, 2022
48 Oct 11, 2022
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 3, 2023
77.2k Jan 3, 2023

Implementation of character based convolutional neural network
Character Based CNN This repo contains a PyTorch implementation of a character-level convolutional neural network for text classification. The model a
248 Nov 21, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
 203 Dec 20, 2022
203 Dec 20, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
Universal Adversarial Triggers for Attacking and Analyzing NLP (EMNLP 2019)
Universal Adversarial Triggers for Attacking and Analyzing NLP This is the official code for the EMNLP 2019 paper, Universal Adversarial Triggers for
 248 Dec 17, 2022
248 Dec 17, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 286 Jan 2, 2023
286 Jan 2, 2023
🛠 All-in-one web-based IDE specialized for machine learning and data science.
All-in-one web-based development environment for machine learning Getting Started • Features & Screenshots • Support • Report a Bug • FAQ • Known Issu
 2.9k Jan 9, 2023
2.9k Jan 9, 2023
A repo for open resources & information for people to succeed in PhD in CS & career in AI / NLP
A repo for open resources & information for people to succeed in PhD in CS & career in AI / NLP
 420 Dec 28, 2022
420 Dec 28, 2022

🤗 Push your spaCy pipelines to the Hugging Face Hub
spacy-huggingface-hub: Push your spaCy pipelines to the Hugging Face Hub This package provides a CLI command for uploading any trained spaCy pipeline
 30 Oct 9, 2022
30 Oct 9, 2022
Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
MLP Singer Official implementation of MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis. Audio samples are available on our demo page.
 103 Dec 23, 2022
103 Dec 23, 2022
Use different orders of N-gram model to play Hangman game.
Hangman game The Hangman game is a game whereby one person thinks of a word, which is kept secret from another person, who tries to guess the word one
 4 Oct 11, 2022
4 Oct 11, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022

ACL'2021: Learning Dense Representations of Phrases at Scale
DensePhrases DensePhrases is an extractive phrase search tool based on your natural language inputs. From 5 million Wikipedia articles, it can search
 540 Dec 30, 2022
540 Dec 30, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 9, 2023
1.2k Jan 9, 2023
Graph4nlp is the library for the easy use of Graph Neural Networks for NLP
Graph4NLP Graph4NLP is an easy-to-use library for R&D at the intersection of Deep Learning on Graphs and Natural Language Processing (i.e., DLG4NLP).
1.5k Dec 23, 2022

A BERT-based reverse-dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end Quick Start C
 94 Dec 8, 2022
94 Dec 8, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
 99 Dec 23, 2022
99 Dec 23, 2022
Meta-learning for NLP
Self-Supervised Meta-Learning for Few-Shot Natural Language Classification Tasks Code for training the meta-learning models and fine-tuning on downstr
 43 Nov 8, 2022
43 Nov 8, 2022
CausaLM: Causal Model Explanation Through Counterfactual Language Models
CausaLM: Causal Model Explanation Through Counterfactual Language Models Authors: Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart Abstract: Understan
 39 Jul 10, 2022
39 Jul 10, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

Sequence model architectures from scratch in PyTorch
This repository implements a variety of sequence model architectures from scratch in PyTorch. Effort has been put to make the code well structured so that it can serve as learning material. The training loop implements the learner design pattern from fast.ai in pure PyTorch, with access to the loop provided through callbacks. Detailed logging and graphs are also provided with python logging and wandb. Additional implementations will be added.
 11 Mar 28, 2022
11 Mar 28, 2022
Deep Learning for Natural Language Processing - Lectures 2021
This repository contains slides for the course "20-00-0947: Deep Learning for Natural Language Processing" (Technical University of Darmstadt, Summer term 2021).
 0 Feb 21, 2022
0 Feb 21, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable.
CausalNLP CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable. Install pip install -U
 95 Jan 3, 2023
95 Jan 3, 2023
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources (NAACL-2021).
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources Description This is the repository for the paper Unifying Cross-
 16 Sep 9, 2022
16 Sep 9, 2022

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022
Baseline code for Korean open domain question answering(ODQA)
Open-Domain Question Answering(ODQA)는 다양한 주제에 대한 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task입니다. 이때 사용자 질의에 답변하기 위해 주어지는 지문이 따로 존재하지 않습니다. 따라서 사전에 구축되어있는 Knowl
 69 Nov 4, 2022
69 Nov 4, 2022
Load What You Need: Smaller Multilingual Transformers for Pytorch and TensorFlow 2.0.
Smaller Multilingual Transformers This repository shares smaller versions of multilingual transformers that keep the same representations offered by t
 79 Dec 28, 2022
79 Dec 28, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
Repository for the COLING 2020 paper "Explainable Automated Fact-Checking: A Survey."
Explainable Fact Checking: A Survey This repository and the accompanying webpage contain resources for the paper "Explainable Fact Checking: A Survey"
 42 Nov 17, 2022
42 Nov 17, 2022
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023

An IVR Chatbot which can exponentially reduce the burden of companies as well as can improve the consumer/end user experience.
IVR-Chatbot Achievements 🏆 Team Uhtred won the Maverick 2.0 Bot-a-thon 2021 organized by AbInbev India. ❓ Problem Statement As we all know that, lot
 9 Dec 8, 2022
9 Dec 8, 2022
A collection of Korean Text Datasets ready to use using Tensorflow-Datasets.
tfds-korean A collection of Korean Text Datasets ready to use using Tensorflow-Datasets. TensorFlow-Datasets를 이용한 한국어/한글 데이터셋 모음입니다. Dataset Catalog |
 20 Jul 11, 2022
20 Jul 11, 2022
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
:hot_pepper: R²SQL: "Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing." (AAAI 2021)
R²SQL The PyTorch implementation of paper Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing. (AAAI 2021) Requirement
 60 Dec 31, 2022
60 Dec 31, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Pytorch NLP library based on FastAI
Quick NLP Quick NLP is a deep learning nlp library inspired by the fast.ai library It follows the same api as fastai and extends it allowing for quick
 283 Nov 21, 2022
283 Nov 21, 2022
Interpretable Models for NLP using PyTorch
This repo is deprecated. Please find the updated package here. https://github.com/EdGENetworks/anuvada Anuvada: Interpretable Models for NLP using PyT
 19 Dec 17, 2022
19 Dec 17, 2022
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
17k Jan 1, 2023
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
43 Dec 16, 2022

QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
 152 Jan 2, 2023
152 Jan 2, 2023
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
152 Jan 2, 2023

COVID-19 Related NLP Papers
COVID-19 outbreak has become a global pandemic. NLP researchers are fighting the epidemic in their own way.
 28 Oct 30, 2022
28 Oct 30, 2022
![NAACL'2021: Factual Probing Is [MASK]: Learning vs. Learning to Recall](https://github.com/princeton-nlp/OptiPrompt/raw/main/figure/optiprompt.png)
NAACL'2021: Factual Probing Is [MASK]: Learning vs. Learning to Recall
OptiPrompt This is the PyTorch implementation of the paper Factual Probing Is [MASK]: Learning vs. Learning to Recall. We propose OptiPrompt, a simple
150 Dec 20, 2022
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
🤗 The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools
15k Jan 2, 2023
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
NLPretext packages in a unique library all the text preprocessing functions you need to ease your NLP project.
 114 Dec 15, 2022
114 Dec 15, 2022