462 Repositories
Python monotonic-attention Libraries

Implementation for our ICCV 2021 paper: Dual-Camera Super-Resolution with Aligned Attention Modules
DCSR: Dual Camera Super-Resolution Implementation for our ICCV 2021 oral paper: Dual-Camera Super-Resolution with Aligned Attention Modules paper | pr
 110 Dec 20, 2022
110 Dec 20, 2022

An implementation of Fastformer: Additive Attention Can Be All You Need in TensorFlow
Fast Transformer This repo implements Fastformer: Additive Attention Can Be All You Need by Wu et al. in TensorFlow. Fast Transformer is a Transformer
 139 Dec 28, 2022
139 Dec 28, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022

Official code of ICCV2021 paper "Residual Attention: A Simple but Effective Method for Multi-Label Recognition"
CSRA This is the official code of ICCV 2021 paper: Residual Attention: A Simple But Effective Method for Multi-Label Recoginition Demo, Train and Vali
 163 Dec 22, 2022
163 Dec 22, 2022

🌈 PyTorch Implementation for EMNLP'21 Findings "Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer"
SGLKT-VisDial Pytorch Implementation for the paper: Reasoning Visual Dialog with Sparse Graph Learning and Knowledge Transfer Gi-Cheon Kang, Junseok P
 9 Jul 5, 2022
9 Jul 5, 2022

Unofficial PyTorch implementation of Fastformer based on paper "Fastformer: Additive Attention Can Be All You Need"."
Fastformer-PyTorch Unofficial PyTorch implementation of Fastformer based on paper Fastformer: Additive Attention Can Be All You Need. Usage : import t
 126 Dec 6, 2022
126 Dec 6, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
[ICCV 2021] Official Pytorch implementation for Discriminative Region-based Multi-Label Zero-Shot Learning SOTA results on NUS-WIDE and OpenImages
Discriminative Region-based Multi-Label Zero-Shot Learning (ICCV 2021) [arXiv][Project page coming soon] Sanath Narayan*, Akshita Gupta*, Salman Kh
 54 Nov 21, 2022
54 Nov 21, 2022

Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
 167 Dec 27, 2022
167 Dec 27, 2022
[ICCV 2021] Official Pytorch implementation for Discriminative Region-based Multi-Label Zero-Shot Learning SOTA results on NUS-WIDE and OpenImages
Discriminative Region-based Multi-Label Zero-Shot Learning (ICCV 2021) [arXiv][Project page coming soon] Sanath Narayan*, Akshita Gupta*, Salman Kh
54 Nov 21, 2022
Intent parsing and slot filling in PyTorch with seq2seq + attention
PyTorch Seq2Seq Intent Parsing Reframing intent parsing as a human - machine translation task. Work in progress successor to torch-seq2seq-intent-pars
 159 Apr 4, 2022
159 Apr 4, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022

Official code for "Focal Self-attention for Local-Global Interactions in Vision Transformers"
Focal Transformer This is the official implementation of our Focal Transformer -- "Focal Self-attention for Local-Global Interactions in Vision Transf
 486 Dec 20, 2022
486 Dec 20, 2022
![[ICCV'21] NEAT: Neural Attention Fields for End-to-End Autonomous Driving](https://github.com/autonomousvision/neat/raw/main/neat/assets/neat_clip.GIF)
[ICCV'21] NEAT: Neural Attention Fields for End-to-End Autonomous Driving
NEAT: Neural Attention Fields for End-to-End Autonomous Driving Paper | Supplementary | Video | Poster | Blog This repository is for the ICCV 2021 pap
 254 Jan 2, 2023
254 Jan 2, 2023

Context Axial Reverse Attention Network for Small Medical Objects Segmentation
CaraNet: Context Axial Reverse Attention Network for Small Medical Objects Segmentation This repository contains the implementation of a novel attenti
 401 Dec 23, 2022
401 Dec 23, 2022

PyTorch code for our ECCV 2018 paper "Image Super-Resolution Using Very Deep Residual Channel Attention Networks"
PyTorch code for our ECCV 2018 paper "Image Super-Resolution Using Very Deep Residual Channel Attention Networks"
 1.2k Dec 26, 2022
1.2k Dec 26, 2022
LONG-TERM SERIES FORECASTING WITH QUERYSELECTOR – EFFICIENT MODEL OF SPARSEATTENTION
Query Selector Here you can find code and data loaders for the paper https://arxiv.org/pdf/2107.08687v1.pdf . Query Selector is a novel approach to sp
 62 Dec 17, 2022
62 Dec 17, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023

Stacked Hourglass Network with a Multi-level Attention Mechanism: Where to Look for Intervertebral Disc Labeling
⚠️ A more recent and actively-maintained version of this code is available in ivadomed Stacked Hourglass Network with a Multi-level Attention Mech
 14 Oct 24, 2022
14 Oct 24, 2022

Official code for "Stereo Waterdrop Removal with Row-wise Dilated Attention (IROS2021)"
Stereo-Waterdrop-Removal-with-Row-wise-Dilated-Attention This repository includes official codes for "Stereo Waterdrop Removal with Row-wise Dilated A
 29 Oct 1, 2022
29 Oct 1, 2022

PyTorch implementation of paper: AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer, ICCV 2021.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer [Paper] [PyTorch Implementation] [Paddle Implementation] Overview This reposit
 148 Dec 30, 2022
148 Dec 30, 2022

Investigating Attention Mechanism in 3D Point Cloud Object Detection (arXiv 2021)
Investigating Attention Mechanism in 3D Point Cloud Object Detection (arXiv 2021) This repository is for the following paper: "Investigating Attention
 52 Nov 19, 2022
52 Nov 19, 2022
Scenic: A Jax Library for Computer Vision and Beyond
Scenic Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop c
 1.6k Dec 27, 2022
1.6k Dec 27, 2022

Code for paper "ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation"
ASAP-Net This project implements ASAP-Net of paper ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation (BMVC2020). Overview We i
 26 Aug 25, 2022
26 Aug 25, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023
An efficient PyTorch implementation of the winning entry of the 2017 VQA Challenge.
Bottom-Up and Top-Down Attention for Visual Question Answering An efficient PyTorch implementation of the winning entry of the 2017 VQA Challenge. The
 731 Jan 3, 2023
731 Jan 3, 2023
pytorch implementation of Attention is all you need
A Pytorch Implementation of the Transformer: Attention Is All You Need Our implementation is largely based on Tensorflow implementation Requirements N
 230 Dec 7, 2022
230 Dec 7, 2022

Train an RL agent to execute natural language instructions in a 3D Environment (PyTorch)
Gated-Attention Architectures for Task-Oriented Language Grounding This is a PyTorch implementation of the AAAI-18 paper: Gated-Attention Architecture
 234 Nov 5, 2022
234 Nov 5, 2022

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022

Bilinear attention networks for visual question answering
Bilinear Attention Networks This repository is the implementation of Bilinear Attention Networks for the visual question answering and Flickr30k Entit
 506 Nov 29, 2022
506 Nov 29, 2022

A PyTorch Implementation of the Luna: Linear Unified Nested Attention
Unofficial PyTorch implementation of Luna: Linear Unified Nested Attention The quadratic computational and memory complexities of the Transformer’s at
 32 Nov 7, 2022
32 Nov 7, 2022

Implementation of H-Transformer-1D, Hierarchical Attention for Sequence Learning
H-Transformer-1D Implementation of H-Transformer-1D, Transformer using hierarchical Attention for sequence learning with subquadratic costs. For now,
123 Nov 17, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023
This is an official implementation of "Polarized Self-Attention: Towards High-quality Pixel-wise Regression"
Polarized Self-Attention: Towards High-quality Pixel-wise Regression This is an official implementation of: Huajun Liu, Fuqiang Liu, Xinyi Fan and Don
 212 Jan 8, 2023
212 Jan 8, 2023

PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
 67 Nov 14, 2022
67 Nov 14, 2022

Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Context Terms
LESA Introduction This repository contains the official implementation of Locally Enhanced Self-Attention: Rethinking Self-Attention as Local and Cont
 20 Dec 31, 2021
20 Dec 31, 2021
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022

Pytorch implementation of face attention network
Face Attention Network Pytorch implementation of face attention network as described in Face Attention Network: An Effective Face Detector for the Occ
 312 Dec 9, 2022
312 Dec 9, 2022

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
 303 Dec 9, 2022
303 Dec 9, 2022

A PyTorch implementation of "Signed Graph Convolutional Network" (ICDM 2018).
SGCN ⠀ A PyTorch implementation of Signed Graph Convolutional Network (ICDM 2018). Abstract Due to the fact much of today's data can be represented as
251 Nov 30, 2022

A PyTorch implementation of "Graph Classification Using Structural Attention" (KDD 2018).
GAM ⠀⠀ A PyTorch implementation of Graph Classification Using Structural Attention (KDD 2018). Abstract Graph classification is a problem with practic
259 Dec 5, 2022

A PyTorch implementation of "SimGNN: A Neural Network Approach to Fast Graph Similarity Computation" (WSDM 2019).
SimGNN ⠀⠀⠀ A PyTorch implementation of SimGNN: A Neural Network Approach to Fast Graph Similarity Computation (WSDM 2019). Abstract Graph similarity s
534 Dec 25, 2022

A PyTorch implementation of "Predict then Propagate: Graph Neural Networks meet Personalized PageRank" (ICLR 2019).
APPNP ⠀ A PyTorch implementation of Predict then Propagate: Graph Neural Networks meet Personalized PageRank (ICLR 2019). Abstract Neural message pass
329 Dec 30, 2022

An implementation of "MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing" (ICML 2019).
MixHop and N-GCN ⠀ A PyTorch implementation of "MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing" (ICML 2019)
393 Dec 13, 2022

A PyTorch implementation of "Capsule Graph Neural Network" (ICLR 2019).
CapsGNN ⠀⠀ A PyTorch implementation of Capsule Graph Neural Network (ICLR 2019). Abstract The high-quality node embeddings learned from the Graph Neur
1.2k Jan 2, 2023
PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
VAENAR-TTS - PyTorch Implementation PyTorch Implementation of VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis.
67 Nov 14, 2022
Weighted QMIX: Expanding Monotonic Value Function Factorisation
This repo contains the cleaned-up code that was used in "Weighted QMIX: Expanding Monotonic Value Function Factorisation"
 82 Dec 29, 2022
82 Dec 29, 2022

Implementation of Invariant Point Attention, used for coordinate refinement in the structure module of Alphafold2, as a standalone Pytorch module
Invariant Point Attention - Pytorch Implementation of Invariant Point Attention as a standalone module, which was used in the structure module of Alph
113 Jan 5, 2023
Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral)
DSA^2 F: Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion (CVPR'2021, Oral) This repo is the official imp
 46 Dec 21, 2022
46 Dec 21, 2022
PyTorch code for our ECCV 2020 paper "Single Image Super-Resolution via a Holistic Attention Network"
HAN PyTorch code for our ECCV 2020 paper "Single Image Super-Resolution via a Holistic Attention Network" This repository is for HAN introduced in the
 140 Nov 23, 2022
140 Nov 23, 2022
Plug and play transformer you can find network structure and official complete code by clicking List
Plug-and-play Module Plug and play transformer you can find network structure and official complete code by clicking List The following is to quickly
 8 Mar 27, 2022
8 Mar 27, 2022

A collection of 100 Deep Learning images and visualizations
A collection of Deep Learning images and visualizations. The project has been developed by the AI Summer team and currently contains almost 100 images.
 65 Sep 12, 2022
65 Sep 12, 2022

PyTorch code for our paper "Image Super-Resolution with Non-Local Sparse Attention" (CVPR2021).
Image Super-Resolution with Non-Local Sparse Attention This repository is for NLSN introduced in the following paper "Image Super-Resolution with Non-
 143 Dec 28, 2022
143 Dec 28, 2022
A collection of 100 Deep Learning images and visualizations
A collection of Deep Learning images and visualizations. The project has been developed by the AI Summer team and currently contains almost 100 images.
65 Sep 12, 2022

Official PyTorch implementation of UACANet: Uncertainty Aware Context Attention for Polyp Segmentation
UACANet: Uncertainty Aware Context Attention for Polyp Segmentation Official pytorch implementation of UACANet: Uncertainty Aware Context Attention fo
 85 Dec 14, 2022
85 Dec 14, 2022

2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation
2021-MICCAI-Progressively Normalized Self-Attention Network for Video Polyp Segmentation Authors: Ge-Peng Ji*, Yu-Cheng Chou*, Deng-Ping Fan, Geng Che
 85 Dec 30, 2022
85 Dec 30, 2022

Codes for TS-CAM: Token Semantic Coupled Attention Map for Weakly Supervised Object Localization.
TS-CAM: Token Semantic Coupled Attention Map for Weakly SupervisedObject Localization This is the official implementaion of paper TS-CAM: Token Semant
 112 Jan 2, 2023
112 Jan 2, 2023
Selective Wavelet Attention Learning for Single Image Deraining
SWAL Code for Paper "Selective Wavelet Attention Learning for Single Image Deraining" Prerequisites Python 3 PyTorch Models We provide the models trai
 9 Jun 17, 2022
9 Jun 17, 2022
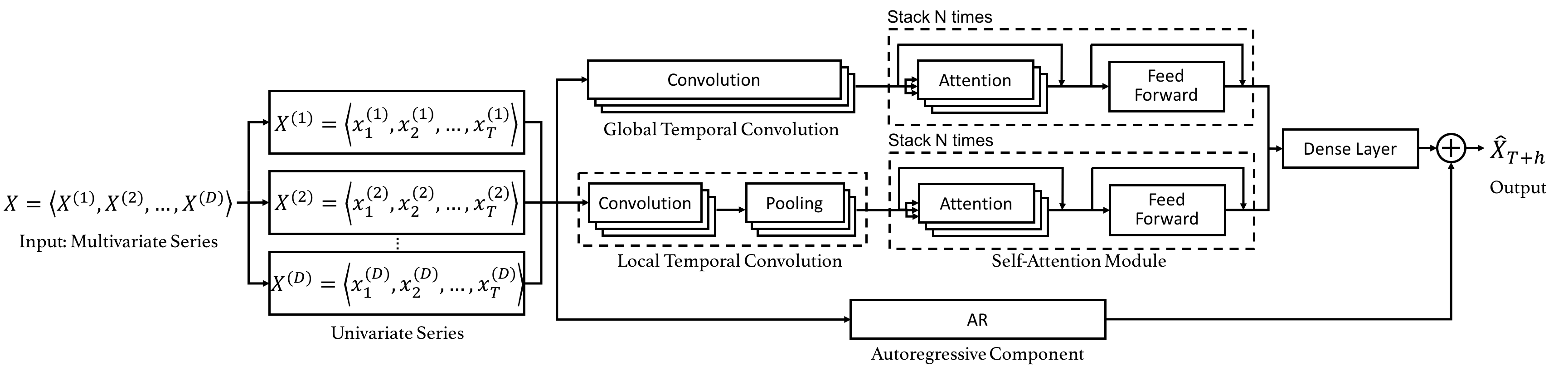
Code for the CIKM 2019 paper "DSANet: Dual Self-Attention Network for Multivariate Time Series Forecasting".
Dual Self-Attention Network for Multivariate Time Series Forecasting 20.10.26 Update: Due to the difficulty of installation and code maintenance cause
 223 Dec 16, 2022
223 Dec 16, 2022

Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement (NeurIPS 2020)
MTTS-CAN: Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement Paper Xin Liu, Josh Fromm, Shwetak Patel, Daniel M
 106 Dec 30, 2022
106 Dec 30, 2022

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022

Shared Attention for Multi-label Zero-shot Learning
Shared Attention for Multi-label Zero-shot Learning Overview This repository contains the implementation of Shared Attention for Multi-label Zero-shot
 26 Dec 14, 2022
26 Dec 14, 2022

codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification
DLCF-DCA codes for paper Combining Dynamic Local Context Focus and Dependency Cluster Attention for Aspect-level sentiment classification. submitted t
 15 Aug 30, 2022
15 Aug 30, 2022
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks
FinGAT: A Financial Graph Attention Networkto Recommend Top-K Profitable Stocks This is our implementation for the paper: FinGAT: A Financial Graph At
 64 Dec 13, 2022
64 Dec 13, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

LieTransformer: Equivariant Self-Attention for Lie Groups
LieTransformer This repository contains the implementation of the LieTransformer used for experiments in the paper LieTransformer: Equivariant Self-At
 50 Dec 28, 2022
50 Dec 28, 2022

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
72 Dec 19, 2022

Shuffle Attention for MobileNetV3
SA-MobileNetV3 Shuffle Attention for MobileNetV3 Train Run the following command for train model on your own dataset: python train.py --dataset mnist
 36 Dec 28, 2022
36 Dec 28, 2022
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network This repo contains the official Pytorch implementaion code and conf
 175 Jan 7, 2023
175 Jan 7, 2023
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
 192 Dec 23, 2022
192 Dec 23, 2022
FANet - Real-time Semantic Segmentation with Fast Attention
FANet Real-time Semantic Segmentation with Fast Attention Ping Hu, Federico Perazzi, Fabian Caba Heilbron, Oliver Wang, Zhe Lin, Kate Saenko , Stan Sc
 42 Nov 30, 2022
42 Nov 30, 2022

Official implement of "CAT: Cross Attention in Vision Transformer".
CAT: Cross Attention in Vision Transformer This is official implement of "CAT: Cross Attention in Vision Transformer". Abstract Since Transformer has
 100 Dec 15, 2022
100 Dec 15, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023

The official PyTorch implementation of recent paper - SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
This repository is the official PyTorch implementation of SAINT. Find the paper on arxiv SAINT: Improved Neural Networks for Tabular Data via Row Atte
 284 Dec 21, 2022
284 Dec 21, 2022
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time.
 360 Dec 28, 2022
360 Dec 28, 2022

Unofficial PyTorch implementation of Attention Free Transformer (AFT) layers by Apple Inc.
aft-pytorch Unofficial PyTorch implementation of Attention Free Transformer's layers by Zhai, et al. [abs, pdf] from Apple Inc. Installation You can i
 184 Dec 12, 2022
184 Dec 12, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 EAMLP will come soon Jitto
 357 Dec 11, 2022
357 Dec 11, 2022

Code for the paper "How Attentive are Graph Attention Networks?"
How Attentive are Graph Attention Networks? This repository is the official implementation of How Attentive are Graph Attention Networks?. The PyTorch
 175 Dec 29, 2022
175 Dec 29, 2022

Attention-driven Robot Manipulation (ARM) which includes Q-attention
Attention-driven Robotic Manipulation (ARM) This codebase is home to: Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation I
 84 Dec 29, 2022
84 Dec 29, 2022
Implements MLP-Mixer: An all-MLP Architecture for Vision.
MLP-Mixer-CIFAR10 This repository implements MLP-Mixer as proposed in MLP-Mixer: An all-MLP Architecture for Vision. The paper introduces an all MLP (
 51 Jan 4, 2023
51 Jan 4, 2023

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022
An implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks in PyTorch.
Neural Attention Distillation This is an implementation demo of the ICLR 2021 paper Neural Attention Distillation: Erasing Backdoor Triggers from Deep
 84 Jan 4, 2023
84 Jan 4, 2023

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
12.6k Jan 9, 2023
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022
Official implementation for (Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching, AAAI-2021)
Show, Attend and Distill: Knowledge Distillation via Attention-based Feature Matching Official pytorch implementation of "Show, Attend and Distill: Kn
 80 Dec 16, 2022
80 Dec 16, 2022
Local Attention - Flax module for Jax
Local Attention - Flax Autoregressive Local Attention - Flax module for Jax Install $ pip install local-attention-flax Usage from jax import random fr
16 Jun 16, 2022
Implementation of Bidirectional Recurrent Independent Mechanisms (Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neural Networks with Attention over Modules)
BRIMs Bidirectional Recurrent Independent Mechanisms Implementation of the paper Learning to Combine Top-Down and Bottom-Up Signals in Recurrent Neura
 26 May 26, 2022
26 May 26, 2022
PyTorch code for our paper "Attention in Attention Network for Image Super-Resolution"
Under construction... Attention in Attention Network for Image Super-Resolution (A2N) This repository is an PyTorch implementation of the paper "Atten
 71 Dec 30, 2022
71 Dec 30, 2022

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
Contains code for the paper "Vision Transformers are Robust Learners".
Vision Transformers are Robust Learners This repository contains the code for the paper Vision Transformers are Robust Learners by Sayak Paul* and Pin
103 Jan 5, 2023

Drone-based Joint Density Map Estimation, Localization and Tracking with Space-Time Multi-Scale Attention Network
DroneCrowd Paper Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark. Introduction This paper proposes a space-time multi-scale atte
 98 Nov 16, 2022
98 Nov 16, 2022
External Attention Network
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks paper : https://arxiv.org/abs/2105.02358 Jittor code will come soon
357 Dec 11, 2022

Exploring whether attention is necessary for vision transformers
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet Paper/Report TL;DR We replace the attention layer in a v
 461 Jan 7, 2023
461 Jan 7, 2023

Reformer, the efficient Transformer, in Pytorch
Reformer, the Efficient Transformer, in Pytorch This is a Pytorch implementation of Reformer https://openreview.net/pdf?id=rkgNKkHtvB It includes LSH
1.8k Dec 30, 2022

Twins: Revisiting the Design of Spatial Attention in Vision Transformers
Twins: Revisiting the Design of Spatial Attention in Vision Transformers Very recently, a variety of vision transformer architectures for dense predic
 482 Dec 18, 2022
482 Dec 18, 2022