734 Repositories
Python multimodal-dataset Libraries
A 30000+ Chinese MRC dataset - Delta Reading Comprehension Dataset
Delta Reading Comprehension Dataset 台達閱讀理解資料集 Delta Reading Comprehension Dataset (DRCD) 屬於通用領域繁體中文機器閱讀理解資料集。 本資料集期望成為適用於遷移學習之標準中文閱讀理解資料集。 本資料集從2,108篇
 272 Dec 15, 2022
272 Dec 15, 2022
Open clone of OpenAI's unreleased WebText dataset scraper.
Open clone of OpenAI's unreleased WebText dataset scraper. This version uses pushshift.io files instead of the API for speed.
 471 Dec 30, 2022
471 Dec 30, 2022

Codes for “A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection”
DSAMNet The pytorch implementation for "A Deeply-supervised Attention Metric-based Network and an Open Aerial Image Dataset for Remote Sensing Change
 41 Dec 14, 2022
41 Dec 14, 2022

This repository provides data for the VAW dataset as described in the CVPR 2021 paper titled "Learning to Predict Visual Attributes in the Wild"
Visual Attributes in the Wild (VAW) This repository provides data for the VAW dataset as described in the CVPR 2021 Paper: Learning to Predict Visual
 36 Dec 30, 2022
36 Dec 30, 2022

Code for "Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals," CoRL 2021.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals This repository contains code for "Multimodal trajectory prediction conditioned
 113 Dec 28, 2022
113 Dec 28, 2022
This project consists of a collaborative filtering algorithm to predict movie reviews ratings from a dataset of Netflix ratings.
Collaborative Filtering - Netflix movie reviews Description This project consists of a collaborative filtering algorithm to predict movie reviews rati
 1 Dec 21, 2021
1 Dec 21, 2021
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction The dataset contains 3 million attribute-value annotations across 1257 unique ca
 89 Jan 8, 2023
89 Jan 8, 2023

LSTM model trained on a small dataset of 3000 names written in PyTorch
LSTM model trained on a small dataset of 3000 names. Model generates names from model by selecting one out of top 3 letters suggested by model at a time until an EOS (End Of Sentence) character is not encountered.
 1 Dec 20, 2021
1 Dec 20, 2021
Le dataset des images du projet d'IA de 2021
face-mask-dataset-ilc-2021 Le dataset des images du projet d'IA de 2021, Indiquez vos id git dans la issue pour les droits TL;DR: Choisir 200 images J
 7 Nov 15, 2021
7 Nov 15, 2021
Human Activity Recognition example using TensorFlow on smartphone sensors dataset and an LSTM RNN. Classifying the type of movement amongst six activity categories - Guillaume Chevalier
LSTMs for Human Activity Recognition Human Activity Recognition (HAR) using smartphones dataset and an LSTM RNN. Classifying the type of movement amon
 3.1k Dec 30, 2022
3.1k Dec 30, 2022

TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022

CPPE - 5 (Medical Personal Protective Equipment) is a new challenging object detection dataset
CPPE - 5 CPPE - 5 (Medical Personal Protective Equipment) is a new challenging dataset with the goal to allow the study of subordinate categorization
 53 Dec 17, 2022
53 Dec 17, 2022
🏆 • 5050 most frequent words in 109 languages
🏆 Most Common Words Multilingual 5000 most frequent words in 109 languages. Uses wordfrequency.info as a source. 🔗 License source code license data
 14 Nov 24, 2022
14 Nov 24, 2022
![[CVPR 2020] Local Class-Specific and Global Image-Level Generative Adversarial Networks for Semantic-Guided Scene Generation](https://github.com/Ha0Tang/LGGAN/raw/master/imgs/framework.jpg)
[CVPR 2020] Local Class-Specific and Global Image-Level Generative Adversarial Networks for Semantic-Guided Scene Generation
Contents Local and Global GAN Cross-View Image Translation Semantic Image Synthesis Acknowledgments Related Projects Citation Contributions Collaborat
 131 Dec 7, 2022
131 Dec 7, 2022
![[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation](https://github.com/Ha0Tang/SelectionGAN/raw/master/imgs/motivation.jpg)
[CVPR 2019 Oral] Multi-Channel Attention Selection GAN with Cascaded Semantic Guidance for Cross-View Image Translation
SelectionGAN for Guided Image-to-Image Translation CVPR Paper | Extended Paper | Guided-I2I-Translation-Papers Citation If you use this code for your
424 Dec 2, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region (Paper and DataSet). [New] Note that all the emails about the download permission o
 71 Dec 22, 2022
71 Dec 22, 2022
Tensorflow Implementation of ECCV'18 paper: Multimodal Human Motion Synthesis
MT-VAE for Multimodal Human Motion Synthesis This is the code for ECCV 2018 paper MT-VAE: Learning Motion Transformations to Generate Multimodal Human
 36 Oct 2, 2022
36 Oct 2, 2022
demir.ai Dataset Operations
demir.ai Dataset Operations With this application, you can have the empty values (nan/null) deleted or filled before giving your dataset to machine le
 8 Nov 1, 2022
8 Nov 1, 2022

The InterScript dataset contains interactive user feedback on scripts generated by a T5-XXL model.
Interscript The Interscript dataset contains interactive user feedback on a T5-11B model generated scripts. Dataset data.json contains the data in an
 8 Dec 1, 2022
8 Dec 1, 2022

ARKitScenes - A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D Data
ARKitScenes This repo accompanies the research paper, ARKitScenes - A Diverse Real-World Dataset for 3D Indoor Scene Understanding Using Mobile RGB-D
 371 Jan 5, 2023
371 Jan 5, 2023
![MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]](https://github.com/uniBruce/Mead/raw/master/Figures/mead.png)
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020] by Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wa
 112 Dec 28, 2022
112 Dec 28, 2022

A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
University1652-Baseline [Paper] [Slide] [Explore Drone-view Data] [Explore Satellite-view Data] [Explore Street-view Data] [Video Sample] [中文介绍] This
 335 Jan 6, 2023
335 Jan 6, 2023
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
An implementation of quantum convolutional neural network with MindQuantum. Huawei, classifying MNIST dataset
关于实现的一点说明 山东大学 2020级 苏博南 www.subonan.com 文件说明 tools.py 这里面主要有两个函数: resize(a, lenb) 这其实是我找同学写的一个小算法hhh。给出一个$28\times 28$的方阵a,返回一个$lenb\times lenb$的方阵。因
 2 Aug 29, 2022
2 Aug 29, 2022
Physical Anomalous Trajectory or Motion (PHANTOM) Dataset
Physical Anomalous Trajectory or Motion (PHANTOM) Dataset Description This dataset contains the six different classes as described in our paper[]. The
 0 Dec 16, 2021
0 Dec 16, 2021

Implementation of parameterized soft-exponential activation function.
Soft-Exponential-Activation-Function: Implementation of parameterized soft-exponential activation function. In this implementation, the parameters are
 1 Feb 23, 2022
1 Feb 23, 2022

Multiview Dataset Toolkit
Multiview Dataset Toolkit Using multi-view cameras is a natural way to obtain a complete point cloud. However, there is to date only one multi-view 3D
 11 Dec 22, 2022
11 Dec 22, 2022

MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions,spherical coordinates, and intensity Introduction The 3D LiDAR place recognition aim
 16 Dec 8, 2022
16 Dec 8, 2022
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
 47 Dec 26, 2022
47 Dec 26, 2022
Code repository for our paper regarding the L3D dataset.
The Large Labelled Logo Dataset (L3D): A Multipurpose and Hand-Labelled Continuously Growing Dataset Website: https://lhf-labs.github.io/tm-dataset Da
 9 Dec 14, 2022
9 Dec 14, 2022

This repository consists of Blender python scripts and corresponding assets to generate variants of the CANDLE dataset
candle-simulator This repository consists of Blender python scripts and corresponding assets to generate variants of the IITH-CANDLE dataset. The rend
 1 Dec 15, 2021
1 Dec 15, 2021
A FAIR dataset of TCV experimental results for validating edge/divertor turbulence models.
TCV-X21 validation for divertor turbulence simulations Quick links Intro Welcome to TCV-X21. We're glad you've found us! This repository is designed t
 0 Dec 18, 2021
0 Dec 18, 2021
SpaCy3Urdu: run command to setup assets(dataset from UD)
Project setup run command to setup assets(dataset from UD) spacy project assets It uses project.yml file and download the data from UD GitHub reposito
 1 Dec 14, 2021
1 Dec 14, 2021
pyreports is a python library that allows you to create complex report from various sources
pyreports pyreports is a python library that allows you to create complex reports from various sources such as databases, text files, ldap, etc. and p
 78 Dec 13, 2022
78 Dec 13, 2022
Random dataframe and database table generator
Random database/dataframe generator Authored and maintained by Dr. Tirthajyoti Sarkar, Fremont, USA Introduction Often, beginners in SQL or data scien
 249 Jan 8, 2023
249 Jan 8, 2023

Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX.
Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX. The repository combines a class agnostic object localizer to first detect the objects in the image, and next a ResNet50 model trained on ImageNet is used to label each box.
 24 Nov 14, 2022
24 Nov 14, 2022
Users can free try their models on SIDD dataset based on this code
SIDD benchmark 1 Train python train.py If you want to train your network, just modify the yaml in the options folder. 2 Validation python validation.p
 2 May 20, 2022
2 May 20, 2022
Extract data from a wide range of Internet sources into a pandas DataFrame.
pandas-datareader Up to date remote data access for pandas, works for multiple versions of pandas. Installation Install using pip pip install pandas-d
 2.5k Jan 9, 2023
2.5k Jan 9, 2023
BOVText: A Large-Scale, Multidimensional Multilingual Dataset for Video Text Spotting
BOVText: A Large-Scale, Bilingual Open World Dataset for Video Text Spotting Updated on December 10, 2021 (Release all dataset(2021 videos)) Updated o
47 Dec 26, 2022
 264 Jan 3, 2023
264 Jan 3, 2023

This repo implements a 3D segmentation task for an airport baggage dataset.
3D CT Scan Segmentation With Occupancy Network This repo implements a 3D superresolution segmentation task for an airport baggage dataset. Our final p
 2 Mar 28, 2022
2 Mar 28, 2022

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022
Machine learning Bot detection technique, based on United States election dataset
Machine learning Bot detection technique, based on United States election dataset (2020). Current github repo provides implementation described in pap
 4 Nov 20, 2022
4 Nov 20, 2022
Wikidated : An Evolving Knowledge Graph Dataset of Wikidata’s Revision History
Wikidated Wikidated 1.0 is a dataset of Wikidata’s full revision history, which encodes changes between Wikidata revisions as sets of deletions and ad
 11 Aug 16, 2022
11 Aug 16, 2022
CLDF dataset derived from Robbeets et al.'s "Triangulation Supports Agricultural Spread" from 2021
CLDF dataset derived from Robbeets et al.'s "Triangulation Supports Agricultural Spread" from 2021 How to cite If you use these data please cite the o
 2 Dec 20, 2021
2 Dec 20, 2021

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
226 Dec 7, 2022

Official Code for VideoLT: Large-scale Long-tailed Video Recognition (ICCV 2021)
Pytorch Code for VideoLT [Website][Paper] Updates [10/29/2021] Features uploaded to Google Drive, for access please send us an e-mail: zhangxing18 at
 26 Sep 18, 2022
26 Sep 18, 2022
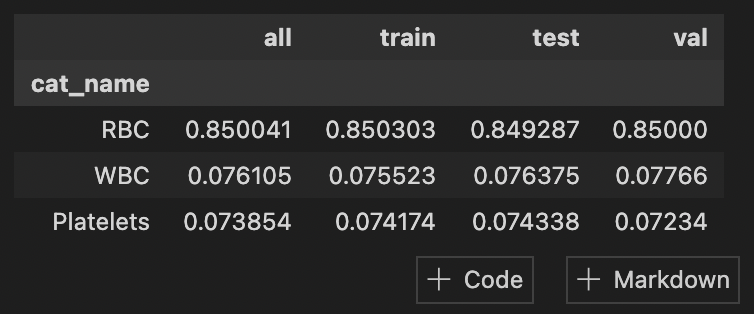
Python library for computer vision labeling tasks. The core functionality is to translate bounding box annotations between different formats-for example, from coco to yolo.
PyLabel pip install pylabel PyLabel is a Python package to help you prepare image datasets for computer vision models including PyTorch and YOLOv5. I
 176 Jan 1, 2023
176 Jan 1, 2023
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022

The Habitat-Matterport 3D Research Dataset - the largest-ever dataset of 3D indoor spaces.
Habitat-Matterport 3D Dataset (HM3D) The Habitat-Matterport 3D Research Dataset is the largest-ever dataset of 3D indoor spaces. It consists of 1,000
 62 Dec 27, 2022
62 Dec 27, 2022
JUSTICE: A Benchmark Dataset for Supreme Court’s Judgment Prediction
JUSTICE: A Benchmark Dataset for Supreme Court’s Judgment Prediction CSCI 544 Final Project done by: Mohammed Alsayed, Shaayan Syed, Mohammad Alali, S
 3 Dec 28, 2022
3 Dec 28, 2022
Codes for the compilation and visualization examples to the HIF vegetation dataset
High-impedance vegetation fault dataset This repository contains the codes that compile the "Vegetation Conduction Ignition Test Report" data, which a
 1 Dec 12, 2021
1 Dec 12, 2021
Cleaned up code for DSTC 10: SIMMC 2.0 track: subtask 2: multimodal coreference resolution
UNITER-Based Situated Coreference Resolution with Rich Multimodal Input: arXiv MMCoref_cleaned Code for the MMCoref task of the SIMMC 2.0 dataset. Pre
 2 Dec 5, 2022
2 Dec 5, 2022

Multiview 3D object detection on MultiviewC dataset through moft3d.
Voxelized 3D Feature Aggregation for Multiview Detection [arXiv] Multiview 3D object detection on MultiviewC dataset through VFA. Introduction We prop
 20 Dec 21, 2022
20 Dec 21, 2022
This is the official github repository of the Met dataset
The Met dataset This is the official github repository of the Met dataset. The official webpage of the dataset can be found here. What is it? This cod
 35 Dec 17, 2022
35 Dec 17, 2022
NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles
NewsMTSC: (Multi-)Target-dependent Sentiment Classification in News Articles NewsMTSC is a dataset for target-dependent sentiment classification (TSC)
 79 Dec 30, 2022
79 Dec 30, 2022
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021
A Simple Example for Imitation Learning with Dataset Aggregation (DAGGER) on Torcs Env
Imitation Learning with Dataset Aggregation (DAGGER) on Torcs Env This repository implements a simple algorithm for imitation learning: DAGGER. In thi
 66 Nov 23, 2022
66 Nov 23, 2022
Hierarchical Attentive Recurrent Tracking
Hierarchical Attentive Recurrent Tracking This is an official Tensorflow implementation of single object tracking in videos by using hierarchical atte
 147 Aug 7, 2021
147 Aug 7, 2021
Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning"
CAPGNN Source code and dataset of the paper "Contrastive Adaptive Propagation Graph Neural Networks forEfficient Graph Learning" Paper URL: https://ar
 1 Mar 12, 2022
1 Mar 12, 2022
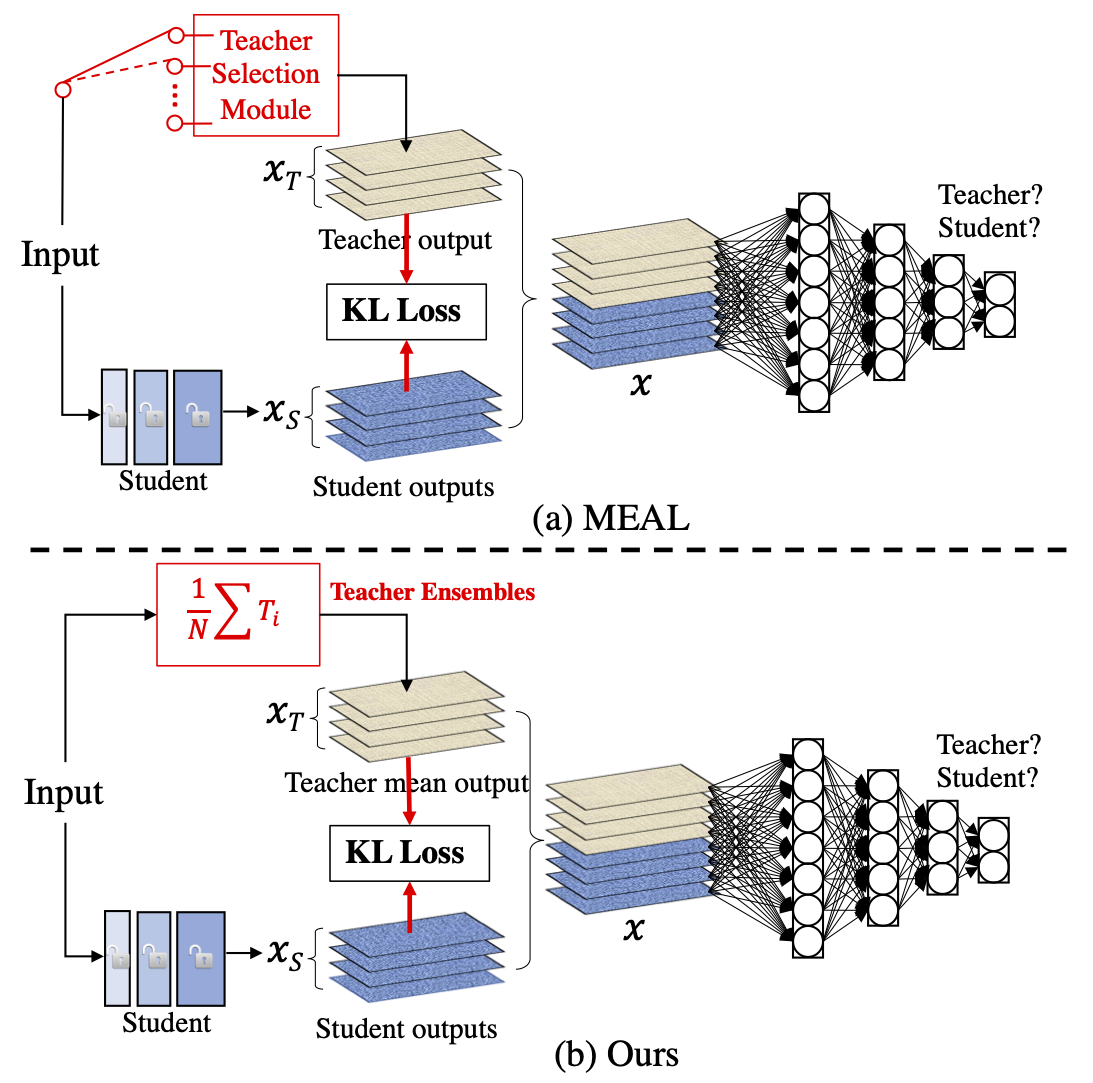
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
DaReCzech is a dataset for text relevance ranking in Czech
Dataset DaReCzech is a dataset for text relevance ranking in Czech. The dataset consists of more than 1.6M annotated query-documents pairs,
 8 Jul 26, 2022
8 Jul 26, 2022
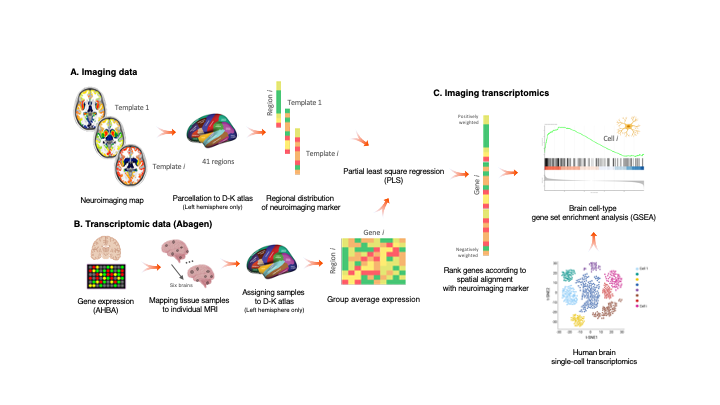
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022
public repo for ESTER dataset and modeling (EMNLP'21)
Project / Paper Introduction This is the project repo for our EMNLP'21 paper: https://arxiv.org/abs/2104.08350 Here, we provide brief descriptions of
 19 Oct 27, 2022
19 Oct 27, 2022
The official homepage of the (outdated) COCO-Stuff 10K dataset.
COCO-Stuff 10K dataset v1.1 (outdated) Holger Caesar, Jasper Uijlings, Vittorio Ferrari Overview Welcome to official homepage of the COCO-Stuff [1] da
 263 Dec 11, 2022
263 Dec 11, 2022

Simple API for UCI Machine Learning Dataset Repository (search, download, analyze)
A simple API for working with University of California, Irvine (UCI) Machine Learning (ML) repository Table of Contents Introduction About Page of the
223 Dec 5, 2022

Joint Detection and Identification Feature Learning for Person Search
Person Search Project This repository hosts the code for our paper Joint Detection and Identification Feature Learning for Person Search. The code is
 712 Dec 17, 2022
712 Dec 17, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
![[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations](https://github.com/kdexd/virtex/raw/master/docs/_static/system_figure.jpg)
[CVPR 2021] VirTex: Learning Visual Representations from Textual Annotations
VirTex: Learning Visual Representations from Textual Annotations Karan Desai and Justin Johnson University of Michigan CVPR 2021 arxiv.org/abs/2006.06
 533 Dec 24, 2022
533 Dec 24, 2022

CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
CSAW-M This repository contains code for CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer. Source code for tr
 7 Oct 11, 2022
7 Oct 11, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022
This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text"
Iconary This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text". It includes the
6 May 24, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
715 Dec 31, 2022
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
End-to-End Referring Video Object Segmentation with Multimodal Transformers
End-to-End Referring Video Object Segmentation with Multimodal Transformers This repo contains the official implementation of the paper: End-to-End Re
 608 Dec 30, 2022
608 Dec 30, 2022