130 Repositories
Python p-tuning Libraries
Code for T-Few from "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning"
T-Few This repository contains the official code for the paper: "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learni
 220 Dec 31, 2022
220 Dec 31, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022
Includes PyTorch - Keras model porting code for ConvNeXt family of models with fine-tuning and inference notebooks.
ConvNeXt-TF This repository provides TensorFlow / Keras implementations of different ConvNeXt [1] variants. It also provides the TensorFlow / Keras mo
87 Dec 6, 2022
Prompt tuning toolkit for GPT-2 and GPT-Neo
mkultra mkultra is a prompt tuning toolkit for GPT-2 and GPT-Neo. Prompt tuning injects a string of 20-100 special tokens into the context in order to
 61 Jan 1, 2023
61 Jan 1, 2023
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022

Repository for fine-tuning Transformers 🤗 based seq2seq speech models in JAX/Flax.
Seq2Seq Speech in JAX A JAX/Flax repository for combining a pre-trained speech encoder model (e.g. Wav2Vec2, HuBERT, WavLM) with a pre-trained text de
 21 Dec 14, 2022
21 Dec 14, 2022

Code for the Findings of NAACL 2022(Long Paper): AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks
AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks arXiv link: upcoming To be published in Findings of NA
 16 Nov 12, 2022
16 Nov 12, 2022
Code for our SIGIR 2022 accepted paper : P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-based Learning and Pre-finetuning
P3 Ranker Implementation for our SIGIR2022 accepted paper: P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-bas
 14 Jan 4, 2023
14 Jan 4, 2023

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022

Under the hood working of transformers, fine-tuning GPT-3 models, DeBERTa, vision models, and the start of Metaverse, using a variety of NLP platforms: Hugging Face, OpenAI API, Trax, and AllenNLP
Transformers-for-NLP-2nd-Edition @copyright 2022, Packt Publishing, Denis Rothman Contact me for any question you have on LinkedIn Get the book on Ama
 150 Dec 23, 2022
150 Dec 23, 2022

Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning
Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning This repository is official Tensorflow implementation of paper: Ensemb
 12 Oct 18, 2022
12 Oct 18, 2022
code for the ICLR'22 paper: On Robust Prefix-Tuning for Text Classification
On Robust Prefix-Tuning for Text Classification Prefix-tuning has drawed much attention as it is a parameter-efficient and modular alternative to adap
 12 Nov 30, 2022
12 Nov 30, 2022
Codes for "Template-free Prompt Tuning for Few-shot NER".
EntLM The source codes for EntLM. Dependencies: Cuda 10.1, python 3.6.5 To install the required packages by following commands: $ pip3 install -r requ
 77 Dec 27, 2022
77 Dec 27, 2022

SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING - The Facebook paper about fine tuning RoBERTa with contrastive loss
"# SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING" i
 28 Dec 12, 2022
28 Dec 12, 2022
OpenDelta - An Open-Source Framework for Paramter Efficient Tuning.
OpenDelta is a toolkit for parameter efficient methods (we dub it as delta tuning), by which users could flexibly assign (or add) a small amount parameters to update while keeping the most paramters frozen. By using OpenDelta, users could easily implement prefix-tuning, adapters, Lora, or any other types of delta tuning with preferred PTMs.
 386 Dec 26, 2022
386 Dec 26, 2022
SAGE: Sensitivity-guided Adaptive Learning Rate for Transformers
SAGE: Sensitivity-guided Adaptive Learning Rate for Transformers This repo contains our codes for the paper "No Parameters Left Behind: Sensitivity Gu
 23 Nov 7, 2022
23 Nov 7, 2022
Large-scale Knowledge Graph Construction with Prompting
Large-scale Knowledge Graph Construction with Prompting across tasks (predictive and generative), and modalities (language, image, vision + language, etc.)
 161 Dec 28, 2022
161 Dec 28, 2022
Pytorch Performace Tuning, WandB, AMP, Multi-GPU, TensorRT, Triton
Plant Pathology 2020 FGVC7 Introduction A deep learning model pipeline for training, experimentaiton and deployment for the Kaggle Competition, Plant
 0 Feb 25, 2022
0 Feb 25, 2022
Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners
DART Implementation for ICLR2022 paper Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. Environment [email protected] Use pi
83 Dec 27, 2022
Generate fine-tuning samples & Fine-tuning the model & Generate samples by transferring Note On
UPMT Generate fine-tuning samples & Fine-tuning the model & Generate samples by transferring Note On See main.py as an example: from model import PopM
 7 Sep 1, 2022
7 Sep 1, 2022

Hyperparameters tuning and features selection are two common steps in every machine learning pipeline.
shap-hypetune A python package for simultaneous Hyperparameters Tuning and Features Selection for Gradient Boosting Models. Overview Hyperparameters t
 422 Jan 8, 2023
422 Jan 8, 2023
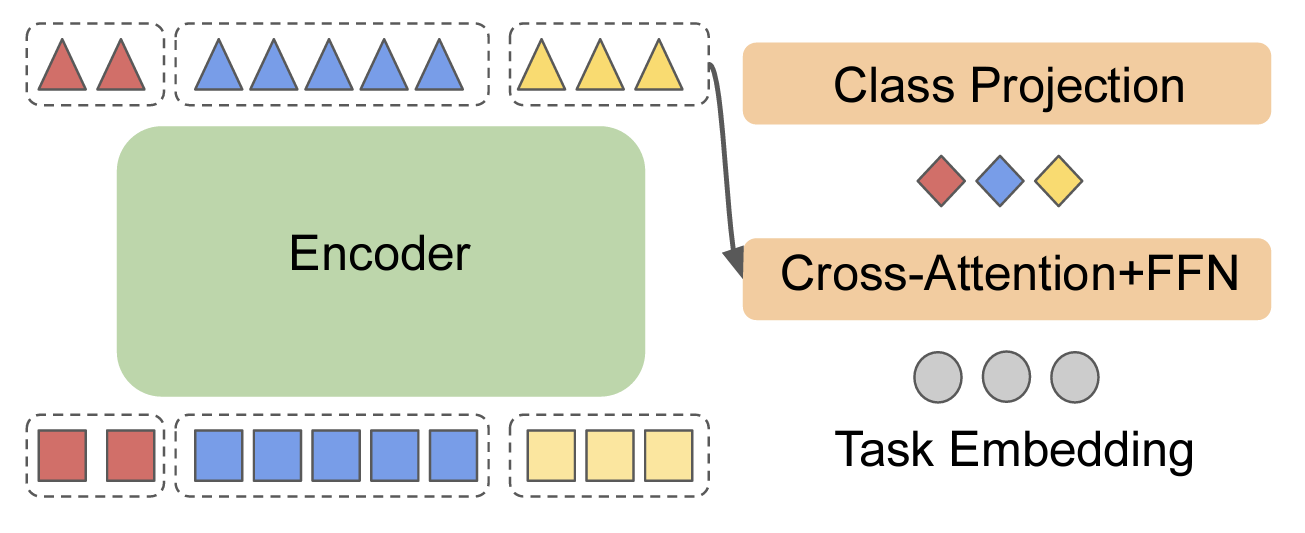
EncT5: Fine-tuning T5 Encoder for Non-autoregressive Tasks
EncT5 (Unofficial) Pytorch Implementation of EncT5: Fine-tuning T5 Encoder for Non-autoregressive Tasks About Finetune T5 model for classification & r
 34 Jan 1, 2023
34 Jan 1, 2023
This repository contains FEDOT - an open-source framework for automated modeling and machine learning (AutoML)
package tests docs license stats support This repository contains FEDOT - an open-source framework for automated modeling and machine learning (AutoML
 482 Dec 26, 2022
482 Dec 26, 2022
Original Implementation of Prompt Tuning from Lester, et al, 2021
Prompt Tuning This is the code to reproduce the experiments from the EMNLP 2021 paper "The Power of Scale for Parameter-Efficient Prompt Tuning" (Lest
 282 Dec 28, 2022
282 Dec 28, 2022
A handy tool for common machine learning models' hyper-parameter tuning.
Common machine learning models' hyperparameter tuning This repo is for a collection of hyper-parameter tuning for "common" machine learning models, in
 2 Jan 27, 2022
2 Jan 27, 2022

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022
Source code for paper "Black-Box Tuning for Language-Model-as-a-Service"
Black-Box-Tuning Source code for paper "Black-Box Tuning for Language-Model-as-a-Service". Being busy recently, the code in this repo and this tutoria
 27 Jan 14, 2022
27 Jan 14, 2022
Black-Box-Tuning - Black-Box Tuning for Language-Model-as-a-Service
Black-Box-Tuning Source code for paper "Black-Box Tuning for Language-Model-as-a
149 Jan 4, 2023

We present a regularized self-labeling approach to improve the generalization and robustness properties of fine-tuning.
Overview This repository provides the implementation for the paper "Improved Regularization and Robustness for Fine-tuning in Neural Networks", which
 21 Sep 8, 2022
21 Sep 8, 2022

Intel® Neural Compressor is an open-source Python library running on Intel CPUs and GPUs
Intel® Neural Compressor targeting to provide unified APIs for network compression technologies, such as low precision quantization, sparsity, pruning, knowledge distillation, across different deep learning frameworks to pursue optimal inference performance.
 846 Jan 4, 2023
846 Jan 4, 2023

Open-source implementation of Google Vizier for hyper parameters tuning
Advisor Introduction Advisor is the hyper parameters tuning system for black box optimization. It is the open-source implementation of Google Vizier w
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022
Calibrated Hyperspectral Image Reconstruction via Graph-based Self-Tuning Network.
mask-uncertainty-in-HSI This repository contains the testing code and pre-trained models for the paper Calibrated Hyperspectral Image Reconstruction v
 9 Dec 29, 2022
9 Dec 29, 2022

Distributed Grid Descent: an algorithm for hyperparameter tuning guided by Bayesian inference, designed to run on multiple processes and potentially many machines with no central point of control
Distributed Grid Descent: an algorithm for hyperparameter tuning guided by Bayesian inference, designed to run on multiple processes and potentially many machines with no central point of control.
 1 Jan 1, 2022
1 Jan 1, 2022

Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning And private Server services
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
Notes, programming assignments and quizzes from all courses within the Coursera Deep Learning specialization offered by deeplearning.ai
Coursera-deep-learning-specialization - Notes, programming assignments and quizzes from all courses within the Coursera Deep Learning specialization offered by deeplearning.ai: (i) Neural Networks and Deep Learning; (ii) Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization; (iii) Structuring Machine Learning Projects; (iv) Convolutional Neural Networks; (v) Sequence Models
 1.7k Jan 8, 2023
1.7k Jan 8, 2023
Implementation of hyperparameter optimization/tuning methods for machine learning & deep learning models
Hyperparameter Optimization of Machine Learning Algorithms This code provides a hyper-parameter optimization implementation for machine learning algor
 1.1k Dec 19, 2022
1.1k Dec 19, 2022

Hyperopt for solving CIFAR-100 with a convolutional neural network (CNN) built with Keras and TensorFlow, GPU backend
Hyperopt for solving CIFAR-100 with a convolutional neural network (CNN) built with Keras and TensorFlow, GPU backend This project acts as both a tuto
 103 Jul 22, 2022
103 Jul 22, 2022

CCCL: Contrastive Cascade Graph Learning.
CCGL: Contrastive Cascade Graph Learning This repo provides a reference implementation of Contrastive Cascade Graph Learning (CCGL) framework as descr
 19 Dec 5, 2022
19 Dec 5, 2022
Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking."
Expert-Linking Pytorch implementation of the paper "COAD: Contrastive Pre-training with Adversarial Fine-tuning for Zero-shot Expert Linking." This is
 12 Jan 1, 2023
12 Jan 1, 2023
Implementation of the paper "Fine-Tuning Transformers: Vocabulary Transfer"
Transformer-vocabulary-transfer Implementation of the paper "Fine-Tuning Transfo
 13 Nov 30, 2022
13 Nov 30, 2022

Implementation of paper "Towards a Unified View of Parameter-Efficient Transfer Learning"
A Unified Framework for Parameter-Efficient Transfer Learning This is the official implementation of the paper: Towards a Unified View of Parameter-Ef
 216 Dec 29, 2022
216 Dec 29, 2022
Implementation of "The Power of Scale for Parameter-Efficient Prompt Tuning"
Prompt-Tuning Implementation of "The Power of Scale for Parameter-Efficient Prompt Tuning" Currently, we support the following huggigface models: Bart
 36 Dec 19, 2022
36 Dec 19, 2022

Robust fine-tuning of zero-shot models
Robust fine-tuning of zero-shot models This repository contains code for the paper Robust fine-tuning of zero-shot models by Mitchell Wortsman*, Gabri
 224 Dec 29, 2022
224 Dec 29, 2022

scikit-learn models hyperparameters tuning and feature selection, using evolutionary algorithms.
Sklearn-genetic-opt scikit-learn models hyperparameters tuning and feature selection, using evolutionary algorithms. This is meant to be an alternativ
 180 Dec 20, 2022
180 Dec 20, 2022
A high-level yet extensible library for fast language model tuning via automatic prompt search
ruPrompts ruPrompts is a high-level yet extensible library for fast language model tuning via automatic prompt search, featuring integration with Hugg
 37 Dec 7, 2022
37 Dec 7, 2022
Fine-tuning scripts for evaluating transformer-based models on KLEJ benchmark.
The KLEJ Benchmark Baselines The KLEJ benchmark (Kompleksowa Lista Ewaluacji Językowych) is a set of nine evaluation tasks for the Polish language und
 17 Oct 18, 2022
17 Oct 18, 2022
Artifacts for paper "MMO: Meta Multi-Objectivization for Software Configuration Tuning"
MMO: Meta Multi-Objectivization for Software Configuration Tuning This repository contains the data and code for the following paper that is currently
 0 Nov 17, 2021
0 Nov 17, 2021
DOP-Tuning(Domain-Oriented Prefix-tuning model)
DOP-Tuning DOP-Tuning(Domain-Oriented Prefix-tuning model)代码基于Prefix-Tuning改进. Files ├── seq2seq # Code for encoder-decoder arch
5 Nov 2, 2022
BERTMap: A BERT-Based Ontology Alignment System
BERTMap: A BERT-based Ontology Alignment System Important Notices The relevant paper was accepted in AAAI-2022. Arxiv version is available at: https:/
 36 Dec 24, 2022
36 Dec 24, 2022
Prompt Tuning with Rules
PTR Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification" If you use the code, please cite the following paper: @art
118 Dec 30, 2022
Research code for the paper "Fine-tuning wav2vec2 for speaker recognition"
Fine-tuning wav2vec2 for speaker recognition This is the code used to run the experiments in https://arxiv.org/abs/2109.15053. Detailed logs of each t
 103 Dec 26, 2022
103 Dec 26, 2022

Automatic learning-rate scheduler
AutoLRS This is the PyTorch code implementation for the paper AutoLRS: Automatic Learning-Rate Schedule by Bayesian Optimization on the Fly published
 33 Nov 18, 2022
33 Nov 18, 2022

Milano is a tool for automating hyper-parameters search for your models on a backend of your choice.
Milano (This is a research project, not an official NVIDIA product.) Documentation https://nvidia.github.io/Milano Milano (Machine learning autotuner
 147 Dec 17, 2022
147 Dec 17, 2022
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization (ACL 2021)
Structured Super Lottery Tickets in BERT This repo contains our codes for the paper "Super Tickets in Pre-Trained Language Models: From Model Compress
16 Dec 11, 2022

Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators This is our Pytorch implementation for t
 12 Jul 22, 2022
12 Jul 22, 2022
PyTorch implementation of the ACL, 2021 paper Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks.
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks This repo contains the PyTorch implementation of the ACL, 2021 pa
 98 Dec 28, 2022
98 Dec 28, 2022

ACL'2021: LM-BFF: Better Few-shot Fine-tuning of Language Models
LM-BFF (Better Few-shot Fine-tuning of Language Models) This is the implementation of the paper Making Pre-trained Language Models Better Few-shot Lea
 607 Jan 7, 2023
607 Jan 7, 2023
Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF shows significant improvements over baseline fine-tuning without data filtration.
Information Gain Filtration Information Gain Filtration (IGF) is a method for filtering domain-specific data during language model finetuning. IGF sho
 4 Jul 28, 2022
4 Jul 28, 2022
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022

An optimized prompt tuning strategy comparable to fine-tuning across model scales and tasks.
P-tuning v2 P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks An optimized prompt tuning strategy achievi
 162 Nov 29, 2021
162 Nov 29, 2021
Large scale and asynchronous Hyperparameter Optimization at your fingertip.
Syne Tune This package provides state-of-the-art distributed hyperparameter optimizers (HPO) where trials can be evaluated with several backend option
 236 Jan 1, 2023
236 Jan 1, 2023

BinTuner is a cost-efficient auto-tuning framework, which can deliver a near-optimal binary code that reveals much more differences than -Ox settings.
BinTuner is a cost-efficient auto-tuning framework, which can deliver a near-optimal binary code that reveals much more differences than -Ox settings. it also can assist the binary code analysis research in generating more diversified datasets for training and testing. The BinTuner framework is based on OpenTuner, thanks to all contributors for their contributions.
 42 Dec 16, 2022
42 Dec 16, 2022
Machine Learning Framework for Operating Systems - Brings ML to Linux kernel
KML: A Machine Learning Framework for Operating Systems & Storage Systems Storage systems and their OS components are designed to accommodate a wide v
 186 Nov 24, 2022
186 Nov 24, 2022
fastai ulmfit - Pretraining the Language Model, Fine-Tuning and training a Classifier
fast.ai ULMFiT with SentencePiece from pretraining to deployment Motivation: Why even bother with a non-BERT / Transformer language model? Short answe
 26 May 27, 2022
26 May 27, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
MixRNet(Using mixup as regularization and tuning hyper-parameters for ResNets)
MixRNet(Using mixup as regularization and tuning hyper-parameters for ResNets) Using mixup data augmentation as reguliraztion and tuning the hyper par
 2 Jan 16, 2022
2 Jan 16, 2022
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models. Hyperactive: is very easy to lear
 422 Jan 4, 2023
422 Jan 4, 2023

Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models.
Backprop makes it simple to use, finetune, and deploy state-of-the-art ML models. Solve a variety of tasks with pre-trained models or finetune them in
 227 Dec 10, 2022
227 Dec 10, 2022
Hyperparameter tuning for humans
KerasTuner KerasTuner is an easy-to-use, scalable hyperparameter optimization framework that solves the pain points of hyperparameter search. Easily c
 2.6k Dec 27, 2022
2.6k Dec 27, 2022
This repository contains Prior-RObust Bayesian Optimization (PROBO) as introduced in our paper "Accounting for Gaussian Process Imprecision in Bayesian Optimization"
Prior-RObust Bayesian Optimization (PROBO) Introduction, TOC This repository contains Prior-RObust Bayesian Optimization (PROBO) as introduced in our
 2 Mar 19, 2022
2 Mar 19, 2022
Source code for our EMNLP'21 paper 《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》
Child-Tuning Source code for EMNLP 2021 Long paper: Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning. 1. Environ
 46 Dec 12, 2022
46 Dec 12, 2022
Time Series Cross-Validation -- an extension for scikit-learn
TSCV: Time Series Cross-Validation This repository is a scikit-learn extension for time series cross-validation. It introduces gaps between the traini
 222 Jan 1, 2023
222 Jan 1, 2023
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
NNI Doc | 简体中文 NNI (Neural Network Intelligence) is a lightweight but powerful toolkit to help users automate Feature Engineering, Neural Architecture
 12.4k Dec 31, 2022
12.4k Dec 31, 2022
Black box hyperparameter optimization made easy.
BBopt BBopt aims to provide the easiest hyperparameter optimization you'll ever do. Think of BBopt like Keras (back when Theano was still a thing) for
 70 Nov 3, 2022
70 Nov 3, 2022
We present a regularized self-labeling approach to improve the generalization and robustness properties of fine-tuning.
Overview This repository provides the implementation for the paper "Improved Regularization and Robustness for Fine-tuning in Neural Networks", which
21 Sep 8, 2022
Complete the code of prefix-tuning in low data setting
Prefix Tuning Note: 作者在论文中提到使用真实的word去初始化prefix的操作(Initializing the prefix with activations of real words,significantly improves generation)。我在使用作者提供的
4 Jul 11, 2022
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
 143 Jan 1, 2023
143 Jan 1, 2023
An Open-Source Toolkit for Prompt-Learning.
An Open-Source Framework for Prompt-learning. Overview • Installation • How To Use • Docs • Paper • Citation • What's New? Nov 2021: Now we have relea
2.3k Jan 7, 2023

Distributing Deep Learning Hyperparameter Tuning for 3D Medical Image Segmentation
DistMIS Distributing Deep Learning Hyperparameter Tuning for 3D Medical Image Segmentation. DistriMIS Distributing Deep Learning Hyperparameter Tuning
 2 Sep 9, 2022
2 Sep 9, 2022
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
DSEE Codes for [Preprint] DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models Xuxi Chen, Tianlong Chen, Yu Cheng, Weizhu Ch
 4 Dec 27, 2021
4 Dec 27, 2021
Facilitating Database Tuning with Hyper-ParameterOptimization: A Comprehensive Experimental Evaluation
A Comprehensive Experimental Evaluation for Database Configuration Tuning This is the source code to the paper "Facilitating Database Tuning with Hype
 9 Oct 29, 2022
9 Oct 29, 2022

Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker
Example Of Fine-Tuning BERT For Named-Entity Recognition Task And Preparing For Cloud Deployment Using Flask, React, And Docker This repository contai
 12 Dec 14, 2022
12 Dec 14, 2022

This repository is the official implementation of Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning (NeurIPS21).
Core-tuning This repository is the official implementation of ``Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regular
 18 Dec 17, 2022
18 Dec 17, 2022
Code and datasets for the paper "KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction"
KnowPrompt Code and datasets for our paper "KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction" Requireme
137 Dec 31, 2022

Fine-tuning StyleGAN2 for Cartoon Face Generation
Cartoon-StyleGAN 🙃 : Fine-tuning StyleGAN2 for Cartoon Face Generation Abstract Recent studies have shown remarkable success in the unsupervised imag
 520 Jan 4, 2023
520 Jan 4, 2023

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 4, 2023
3.1k Jan 4, 2023

Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
 794 Dec 31, 2022
794 Dec 31, 2022
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Prefix Tuning Files: . ├── gpt2 # Code for GPT2 style autoregressive LM │ ├── train_e2e.py # high-level script
 530 Jan 4, 2023
530 Jan 4, 2023

Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
 18 Nov 28, 2022
18 Nov 28, 2022
Lale is a Python library for semi-automated data science.
Lale is a Python library for semi-automated data science. Lale makes it easy to automatically select algorithms and tune hyperparameters of pipelines that are compatible with scikit-learn, in a type-safe fashion.
 293 Dec 29, 2022
293 Dec 29, 2022

P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks
P-tuning v2 P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks An optimized prompt tuning strategy for sma
540 Dec 30, 2022

Hypernets: A General Automated Machine Learning framework to simplify the development of End-to-end AutoML toolkits in specific domains.
A General Automated Machine Learning framework to simplify the development of End-to-end AutoML toolkits in specific domains.
 216 Dec 23, 2022
216 Dec 23, 2022

Official codebase for Legged Robots that Keep on Learning: Fine-Tuning Locomotion Policies in the Real World
Legged Robots that Keep on Learning Official codebase for Legged Robots that Keep on Learning: Fine-Tuning Locomotion Policies in the Real World, whic
 70 Dec 7, 2022
70 Dec 7, 2022

p-tuning for few-shot NLU task
p-tuning_NLU Overview 这个小项目是受乐于分享的苏剑林大佬这篇p-tuning 文章启发,也实现了个使用P-tuning进行NLU分类的任务, 思路是一样的,prompt实现方式有不同,这里是将[unused*]的embeddings参数抽取出用于初始化prompt_embed后
 3 Dec 29, 2022
3 Dec 29, 2022

TLDR; Train custom adaptive filter optimizers without hand tuning or extra labels.
AutoDSP TLDR; Train custom adaptive filter optimizers without hand tuning or extra labels. About Adaptive filtering algorithms are commonplace in sign
 48 Sep 19, 2022
48 Sep 19, 2022
🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
3.1k Jan 2, 2023
![A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]](https://user-images.githubusercontent.com/33194443/104581604-2592cb00-56a2-11eb-9610-5eaa0afb6e1f.png)
A repository that shares tuning results of trained models generated by TensorFlow / Keras. Post-training quantization (Weight Quantization, Integer Quantization, Full Integer Quantization, Float16 Quantization), Quantization-aware training. TensorFlow Lite. OpenVINO. CoreML. TensorFlow.js. TF-TRT. MediaPipe. ONNX. [.tflite,.h5,.pb,saved_model,tfjs,tftrt,mlmodel,.xml/.bin, .onnx]
PINTO_model_zoo Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts ar
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
Example of network fine-tuning in pytorch for the kaggle competition Dogs vs. Cats Redux: Kernels Edition
Example of network fine-tuning in pytorch for the kaggle competition Dogs vs. Cats Redux: Kernels Edition Currently
 70 Sep 22, 2022
70 Sep 22, 2022
easyopt is a super simple yet super powerful optuna-based Hyperparameters Optimization Framework that requires no coding.
easyopt is a super simple yet super powerful optuna-based Hyperparameters Optimization Framework that requires no coding.
 9 Feb 4, 2022
9 Feb 4, 2022