243 Repositories
Python pokemon-catch-pipeline Libraries

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
This is a repository containing the backend and the frontend of a simple pokédex.
Pokémon This is a repository containing the backend and the frontend of a simple pokédex. This is a work in progress project! Project Structure 🗂 pok
 1 Nov 28, 2021
1 Nov 28, 2021
An automation bot to play Myuu Discord game
Auto selfbot Myuu is a self Discordbot, meaning it will use your TOKEN to logged as your account and take commands from yourself to play the game.
 6 Dec 15, 2022
6 Dec 15, 2022
This is a Docker-based pipeline for preparing sextractor-ready multiwavelength images
Pipeline for creating NB422-detected (ODI) catalog The repository contains a Docker-based pipeline for preprocessing observational data. The pipeline
 1 Sep 1, 2022
1 Sep 1, 2022
Pipeline to convert a haploid assembly into diploid
HapDup (haplotype duplicator) is a pipeline to convert a haploid long read assembly into a dual diploid assembly. The reconstructed haplotypes
 50 Jan 5, 2023
50 Jan 5, 2023
Scikit-Learn useful pre-defined Pipelines Hub
Scikit-Pipes Scikit-Learn useful pre-defined Pipelines Hub Usage: Install scikit-pipes It's advised to install sklearn-genetic using a virtual env, in
 1 Apr 26, 2022
1 Apr 26, 2022
📚 Papermill is a tool for parameterizing, executing, and analyzing Jupyter Notebooks.
papermill is a tool for parameterizing, executing, and analyzing Jupyter Notebooks. Papermill lets you: parameterize notebooks execute notebooks This
 5.1k Jan 3, 2023
5.1k Jan 3, 2023

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

A unified 3D Transformer Pipeline for visual synthesis
Overview This is the official repo for the paper: "NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion". NÜWA is a unified multimodal
 2.6k Jan 3, 2023
2.6k Jan 3, 2023
🧪 Cutting-edge experimental spaCy components and features
spacy-experimental: Cutting-edge experimental spaCy components and features This package includes experimental components and features for spaCy v3.x,
 65 Dec 30, 2022
65 Dec 30, 2022
flake8 plugin to catch useless `assert` statements
flake8-useless-assert flake8 plugin to catch useless assert statements Download or install on the PyPI page Violations Code Description Example ULA001
 1 Feb 12, 2022
1 Feb 12, 2022
Crypto Stats and Tweets Data Pipeline using Airflow
Crypto Stats and Tweets Data Pipeline using Airflow Introduction Project Overview This project was brought upon through Udacity's nanodegree program.
 1 Nov 24, 2021
1 Nov 24, 2021
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
 2.9k Jan 6, 2023
2.9k Jan 6, 2023

BookNLP, a natural language processing pipeline for books
BookNLP BookNLP is a natural language processing pipeline that scales to books and other long documents (in English), including: Part-of-speech taggin
 654 Jan 2, 2023
654 Jan 2, 2023
Pokemon game made in Python with open ended requirements from Codecademy
Pokemon game made in Python with open ended requirements from Codecademy. This is one of my first projects utilizing OOP and classes! -This game is a
 2 Dec 29, 2021
2 Dec 29, 2021

Predicting the usefulness of reviews given the review text and metadata surrounding the reviews.
Predicting Yelp Review Quality Table of Contents Introduction Motivation Goal and Central Questions The Data Data Storage and ETL EDA Data Pipeline Da
 3 Nov 27, 2022
3 Nov 27, 2022

Backtesting an algorithmic trading strategy using Machine Learning and Sentiment Analysis.
Trading Tesla with Machine Learning and Sentiment Analysis An interactive program to train a Random Forest Classifier to predict Tesla daily prices us
 31 Nov 17, 2022
31 Nov 17, 2022
Full automated data pipeline using docker images
Create postgres tables from CSV files This first section is only relate to creating tables from CSV files using postgres container alone. Just one of
 1 Nov 21, 2021
1 Nov 21, 2021
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
Automated Machine Learning Pipeline for tabular data. Designed for predictive maintenance applications, failure identification, failure prediction, condition monitoring, etc.
Automated Machine Learning Pipeline for tabular data. Designed for predictive maintenance applications, failure identification, failure prediction, condition monitoring, etc.
 10 May 15, 2022
10 May 15, 2022
A simple python application for running a CI pipeline locally
A simple python application for running a CI pipeline locally This app currently supports GitLab CI scripts
 0 Jan 11, 2022
0 Jan 11, 2022
Two phase pipeline + StreamlitTwo phase pipeline + Streamlit
Two phase pipeline + Streamlit This is an example project that demonstrates how to create a pipeline that consists of two phases of execution. In betw
 1 Nov 17, 2021
1 Nov 17, 2021
A data preprocessing and feature engineering script for a machine learning pipeline is prepared.
FEATURE ENGINEERING Business Problem: A data preprocessing and feature engineering script for a machine learning pipeline needs to be prepared. It is
 7 Dec 18, 2021
7 Dec 18, 2021
Required for a machine learning pipeline data preprocessing and variable engineering script needs to be prepared
Feature-Engineering Required for a machine learning pipeline data preprocessing and variable engineering script needs to be prepared. When the dataset
 5 Apr 21, 2022
5 Apr 21, 2022
A simple python application for running a CI pipeline locally This app currently supports GitLab CI scripts
🏃 Simple Local CI Runner 🏃 A simple python application for running a CI pipeline locally This app currently supports GitLab CI scripts ⚙️ Setup Inst
0 Jan 11, 2022
A deep-learning pipeline for segmentation of ambiguous microscopic images.
Welcome to Official repository of deepflash2 - a deep-learning pipeline for segmentation of ambiguous microscopic images. Quick Start in 30 seconds se
 39 Dec 19, 2022
39 Dec 19, 2022
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells.
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells. The project retrains itself after every prediction, making it more robust and generalized over time.
 2 Jul 1, 2022
2 Jul 1, 2022

Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
 2 Nov 20, 2021
2 Nov 20, 2021
Bodywork deploys machine learning projects developed in Python, to Kubernetes.
Bodywork deploys machine learning projects developed in Python, to Kubernetes. It helps you to: serve models as microservices execute batch jobs run r
 409 Jan 1, 2023
409 Jan 1, 2023
MHtyper is an end-to-end pipeline for recognized the Forensic microhaplotypes in Nanopore sequencing data.
MHtyper is an end-to-end pipeline for recognized the Forensic microhaplotypes in Nanopore sequencing data. It is implemented using Python.
 6 Jun 27, 2022
6 Jun 27, 2022
A pipeline that creates consensus sequences from a Nanopore reads. I
A pipeline that creates consensus sequences from a Nanopore reads. It clusters reads that are similar to each other and creates a consensus that is then identified using BLAST.
 2 May 15, 2022
2 May 15, 2022
Inference pipeline for our participation in the FeTA challenge 2021.
feta-inference Inference pipeline for our participation in the FeTA challenge 2021. Team name: TRABIT Installation Download the two folders in https:/
 2 Apr 13, 2022
2 Apr 13, 2022
This tool parses log data and allows to define analysis pipelines for anomaly detection.
logdata-anomaly-miner This tool parses log data and allows to define analysis pipelines for anomaly detection. It was designed to run the analysis wit
 32 Nov 27, 2022
32 Nov 27, 2022

AQP is a modular pipeline built to enable the comparison and testing of different quality metric configurations.
Audio Quality Platform - AQP An Open Modular Python Platform for Objective Speech and Audio Quality Metrics AQP is a highly modular pipeline designed
 24 Oct 1, 2022
24 Oct 1, 2022
A simple pytorch pipeline for semantic segmentation.
SegmentationPipeline -- Pytorch A simple pytorch pipeline for semantic segmentation. Requirements : torch=1.9.0 tqdm albumentations=1.0.3 opencv-pyt
 4 Feb 22, 2022
4 Feb 22, 2022
Pipeline and Dataset helpers for complex algorithm evaluation.
tpcp - Tiny Pipelines for Complex Problems A generic way to build object-oriented datasets and algorithm pipelines and tools to evaluate them pip inst
 3 Dec 7, 2022
3 Dec 7, 2022
SNV calling pipeline developed explicitly to process individual or trio vcf files obtained from Illumina based pipeline (grch37/grch38).
SNV Pipeline SNV calling pipeline developed explicitly to process individual or trio vcf files obtained from Illumina based pipeline (grch37/grch38).
 1 Nov 2, 2021
1 Nov 2, 2021
In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift.
ETL Pipeline for AWS Project Description In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift. The data is loaded from S3 t
 1 Nov 1, 2021
1 Nov 1, 2021

MLOps will help you to understand how to build a Continuous Integration and Continuous Delivery pipeline for an ML/AI project.
page_type languages products description sample python azure azure-machine-learning-service azure-devops Code which demonstrates how to set up and ope
 1 Nov 1, 2021
1 Nov 1, 2021
fMRIprep Pipeline To Machine Learning
fMRIprep Pipeline To Machine Learning(Demo) 所有配置均在config.py文件下定义 前置环境(lilab) 各个节点均安装docker,并有fmripre的镜像 可以使用conda中的base环境(相应的第三份包之后更新) 1. fmriprep scr
 3 Mar 8, 2022
3 Mar 8, 2022
PdpCLI is a pandas DataFrame processing CLI tool which enables you to build a pandas pipeline from a configuration file.
PdpCLI Quick Links Introduction Installation Tutorial Basic Usage Data Reader / Writer Plugins Introduction PdpCLI is a pandas DataFrame processing CL
 15 Jan 7, 2022
15 Jan 7, 2022
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques. arXiv: Colossal-AI: A Unified Deep Learning Syst
 7.9k Jan 8, 2023
7.9k Jan 8, 2023
DWIPrep is a robust and easy-to-use pipeline for preprocessing of diverse dMRI data.
DWIPrep: A Robust Preprocessing Pipeline for dMRI Data DWIPrep is a robust and easy-to-use pipeline for preprocessing of diverse dMRI data. The transp
 1 Jan 9, 2023
1 Jan 9, 2023
Colossal-AI: A Unified Deep Learning System for Large-Scale Parallel Training
ColossalAI An integrated large-scale model training system with efficient parallelization techniques Installation PyPI pip install colossalai Install
7.1k Jan 3, 2023
TrackTech: Real-time tracking of subjects and objects on multiple cameras
TrackTech: Real-time tracking of subjects and objects on multiple cameras This project is part of the 2021 spring bachelor final project of the Bachel
 5 Jun 17, 2022
5 Jun 17, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023
A novel pipeline framework for multi-hop complex KGQA task. About the paper title: Improving Multi-hop Embedded Knowledge Graph Question Answering by Introducing Relational Chain Reasoning
Rce-KGQA A novel pipeline framework for multi-hop complex KGQA task. This framework mainly contains two modules, answering_filtering_module and relati
 16 Nov 18, 2022
16 Nov 18, 2022

Python ML pipeline that showcases mltrace functionality.
mltrace tutorial Date: October 2021 This tutorial builds a training and testing pipeline for a toy ML prediction problem: to predict whether a passeng
 28 Nov 9, 2022
28 Nov 9, 2022
Brute-forcing (or not!) deck builder for Pokemon Trading Card Game.
PokeBot Deck Builder Brute-forcing (or not!) deck builder for Pokemon Trading Card Game. Warning: intensely not optimized and spaghetti coded Credits
 0 Jan 10, 2022
0 Jan 10, 2022
PyTorch framework for Deep Learning research and development.
Accelerated DL & RL PyTorch framework for Deep Learning research and development. It was developed with a focus on reproducibility, fast experimentati
 29 Jul 13, 2022
29 Jul 13, 2022

Tracking Pipeline helps you to solve the tracking problem more easily
Tracking_Pipeline Tracking_Pipeline helps you to solve the tracking problem more easily I integrate detection algorithms like: Yolov5, Yolov4, YoloX,
 32 Dec 21, 2022
32 Dec 21, 2022

pipeline for migrating lichess data into postgresql
How Long Does It Take Ordinary People To "Get Good" At Chess? TL;DR: According to 5.5 years of data from 2.3 million players and 450 million games, mo
 182 Nov 11, 2022
182 Nov 11, 2022
This is a practice on Airflow, which is building virtual env, installing Airflow and constructing data pipeline (DAGs)
airflow-test This is a practice on Airflow, which is Builing virtualbox env and setting Airflow on that env Installing Airflow using python virtual en
 1 Nov 1, 2021
1 Nov 1, 2021

Complete portable pipeline for masking of Aadhaar Number adhering to Govt. Privacy Guidelines.
Aadhaar Number Masking Pipeline Implementation of a complete pipeline that masks the Aadhaar Number in given images to adhere to Govt. of India's Priv
 1 Nov 6, 2021
1 Nov 6, 2021
Open source Python implementation of the HDR+ photography pipeline
hdrplus-python Open source Python implementation of the HDR+ photography pipeline, originally developped by Google and presented in a 2016 article. Th
 77 Jan 5, 2023
77 Jan 5, 2023
Multiparametric Image Analysis
Documentation The documentation is available on populse_mia's website here Installation From PyPI, for users By cloning the package, for developers Fr
 9 Dec 14, 2022
9 Dec 14, 2022
Lale is a Python library for semi-automated data science.
Lale is a Python library for semi-automated data science. Lale makes it easy to automatically select algorithms and tune hyperparameters of pipelines that are compatible with scikit-learn, in a type-safe fashion.
 293 Dec 29, 2022
293 Dec 29, 2022
Framework for the Complete Gaze Tracking Pipeline
Framework for the Complete Gaze Tracking Pipeline The figure below shows a general representation of the camera-to-screen gaze tracking pipeline [1].
 20 Jan 6, 2023
20 Jan 6, 2023
MONAI Deploy App SDK offers a framework and associated tools to design, develop and verify AI-driven applications in the healthcare imaging domain.
MONAI Deploy App SDK offers a framework and associated tools to design, develop and verify AI-driven applications in the healthcare imaging domain.
 49 Dec 23, 2022
49 Dec 23, 2022

Simple and flexible ML workflow engine.
This is a simple and flexible ML workflow engine. It helps to orchestrate events across a set of microservices and create executable flow to handle requests. Engine is designed to be configurable with any microservices. Enjoy!
 295 Jan 6, 2023
295 Jan 6, 2023

The easy way to combine mlflow, hydra and optuna into one machine learning pipeline.
mlflow_hydra_optuna_the_easy_way The easy way to combine mlflow, hydra and optuna into one machine learning pipeline. Objective TODO Usage 1. build do
 9 Sep 9, 2022
9 Sep 9, 2022

A web scraping pipeline project that retrieves TV and movie data from two sources, then transforms and stores data in a MySQL database.
New to Streaming Scraper An in-progress web scraping project built with Python, R, and SQL. The scraped data are movie and TV show information. The go
 1 Mar 28, 2022
1 Mar 28, 2022

A brand new hub for Scene Graph Generation methods based on MMdetection (2021). The pipeline of from detection, scene graph generation to downstream tasks (e.g., image cpationing) is supported. Pytorch version implementation of HetH (ECCV 2020) and TopicSG (ICCV 2021) is included.
MMSceneGraph Introduction MMSceneneGraph is an open source code hub for scene graph generation as well as supporting downstream tasks based on the sce
 39 Dec 17, 2022
39 Dec 17, 2022
A geometric deep learning pipeline for predicting protein interface contacts.
A geometric deep learning pipeline for predicting protein interface contacts.
 44 Dec 30, 2022
44 Dec 30, 2022

Multi-Branch CI/CD Pipeline using CDK Pipelines.
Using AWS CDK Pipelines and AWS Lambda for multi-branch pipeline management and infrastructure deployment. This project shows how to use the AWS CDK P
 36 Dec 23, 2022
36 Dec 23, 2022
user friendly python script who is able to catch fish in the game New World
new-world-fishing-bot release 1.1.1 click img for demonstration Download guide Click at latest release: Download and extract bot.zip: When you run fil
 297 Jan 8, 2023
297 Jan 8, 2023

Pipelines de datos, 2021.
Este repo ilustra un proceso sencillo de automatización de transformación y modelado de datos, a través de un pipeline utilizando Luigi. Stack princip
 8 May 19, 2022
8 May 19, 2022

Elementary is an open-source data reliability framework for modern data teams. The first module of the framework is data lineage.
Data lineage made simple, reliable, and automated. Effortlessly track the flow of data, understand dependencies and analyze impact. Features Visualiza
 898 Jan 9, 2023
898 Jan 9, 2023

Shotgrid Toolkit Engine for Gaffer
Shotgun toolkit engine for Gaffer Contact : Diego Garcia Huerta Overview Implementation of a shotgun engine for Gaffer. It supports the classic bootst
 12 May 21, 2022
12 May 21, 2022
Know your customer pipeline in apache air flow
KYC_pipline Know your customer pipeline in apache air flow For a successful pipeline run take these steps: Run you Airflow server Admin - connection
 4 Aug 1, 2022
4 Aug 1, 2022

An adaptable Snakemake workflow which uses GATKs best practice recommendations to perform germline mutation calling starting with BAM files
Germline Mutation Calling This Snakemake workflow follows the GATK best-practice recommandations to call small germline variants. The pipeline require
 12 Dec 24, 2022
12 Dec 24, 2022
A Multilingual Latent Dirichlet Allocation (LDA) Pipeline with Stop Words Removal, n-gram features, and Inverse Stemming, in Python.
Multilingual Latent Dirichlet Allocation (LDA) Pipeline This project is for text clustering using the Latent Dirichlet Allocation (LDA) algorithm. It
 74 Oct 7, 2022
74 Oct 7, 2022
A production-ready pipeline for text mining and subject indexing
A production-ready pipeline for text mining and subject indexing
 12 Nov 6, 2022
12 Nov 6, 2022
Project repository of Apache Airflow, deployed on Docker in Amazon EC2 via GitLab.
Airflow on Docker in EC2 + GitLab's CI/CD Personal project for simple data pipeline using Airflow. Airflow will be installed inside Docker container,
 13 Nov 29, 2022
13 Nov 29, 2022
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
 1.4k Aug 29, 2021
1.4k Aug 29, 2021
A spaCy wrapper of OpenTapioca for named entity linking on Wikidata
spaCyOpenTapioca A spaCy wrapper of OpenTapioca for named entity linking on Wikidata. Table of contents Installation How to use Local OpenTapioca Vizu
 80 Jan 3, 2023
80 Jan 3, 2023

Pokemon catch events project to demonstrate data pipeline on AWS
Pokemon Catches Data Pipeline This is a sample project to practice end-to-end data project; Terraform is used to deploy infrastructure; Kafka is the t
 4 Sep 3, 2021
4 Sep 3, 2021

Kedro is an open-source Python framework for creating reproducible, maintainable and modular data science code
A Python framework for creating reproducible, maintainable and modular data science code.
 7.9k Jan 1, 2023
7.9k Jan 1, 2023
649 Pokémon palettes as CSVs, with a Python lib to turn names/IDs into palettes, or MatPlotLib compatible ListedColormaps.
PokePalette 649 Pokémon, broken down into CSVs of their RGB colour palettes. Complete with a Python library to convert names or Pokédex IDs into eithe
 11 Dec 5, 2022
11 Dec 5, 2022

A scalable implementation of WobblyStitcher for 3D microscopy images
WobblyStitcher Introduction A scalable implementation of WobblyStitcher Dependencies $ python -m pip install numpy scikit-image Visualization ImageJ
 7 Jul 25, 2022
7 Jul 25, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

PyHook is an offensive API hooking tool written in python designed to catch various credentials within the API call.
PyHook is the python implementation of my SharpHook project, It uses various API hooks in order to give us the desired credentials. PyHook Uses
 158 Dec 22, 2022
158 Dec 22, 2022
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

CPOST is a CLI tool to assist with the proper sizing of Clara Deploy pipelines
CPOST (Clara Pipeline Operator Sizing Tool) Tool to measure resource usage of Clara Platform pipeline operators Cpost is a tool that will help you run
 5 Sep 27, 2021
5 Sep 27, 2021

pokemon-colorscripts compatible for mac
Pokemon colorscripts some scripts to print out images of pokemons to terminal. Inspired by DT's colorscripts compilation Description Prints out colore
 43 Jan 6, 2023
43 Jan 6, 2023
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022

A robust pointcloud registration pipeline based on correlation.
PHASER: A Robust and Correspondence-Free Global Pointcloud Registration Ubuntu 18.04+ROS Melodic: Overview Pointcloud registration using correspondenc
 101 Dec 1, 2022
101 Dec 1, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022
Finetuning Pipeline
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022
An ftp syncing python package that I use to sync pokemon saves between my hacked 3ds running ftpd and my server
Sync file pairs over ftp and apply patches to them. Useful for using ftpd to transfer ROM save files to and from your DS if you also play on an emulator. Setup a cron job to check for your DS's ftp server periodically to setup automatic syncing. Untested on windows. It may just work out of the box, unsure though.
 17 Jan 4, 2023
17 Jan 4, 2023
🕹 An esoteric language designed so that the program looks like the transcript of a Pokémon battle
PokéBattle is an esoteric language designed so that the program looks like the transcript of a Pokémon battle. Original inspiration and specification
 9 Jan 11, 2022
9 Jan 11, 2022

Distributed DataLoader For Pytorch Based On Ray
Dpex——用户无感知分布式数据预处理组件 一、前言 随着GPU与CPU的算力差距越来越大以及模型训练时的预处理Pipeline变得越来越复杂,CPU部分的数据预处理已经逐渐成为了模型训练的瓶颈所在,这导致单机的GPU配置的提升并不能带来期望的线性加速。预处理性能瓶颈的本质在于每个GPU能够使用的C
 23 Nov 2, 2022
23 Nov 2, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline.
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline
 193 Dec 22, 2022
193 Dec 22, 2022

This repository contains the code for our fast polygonal building extraction from overhead images pipeline.
Polygonal Building Segmentation by Frame Field Learning We add a frame field output to an image segmentation neural network to improve segmentation qu
 186 Jan 4, 2023
186 Jan 4, 2023

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
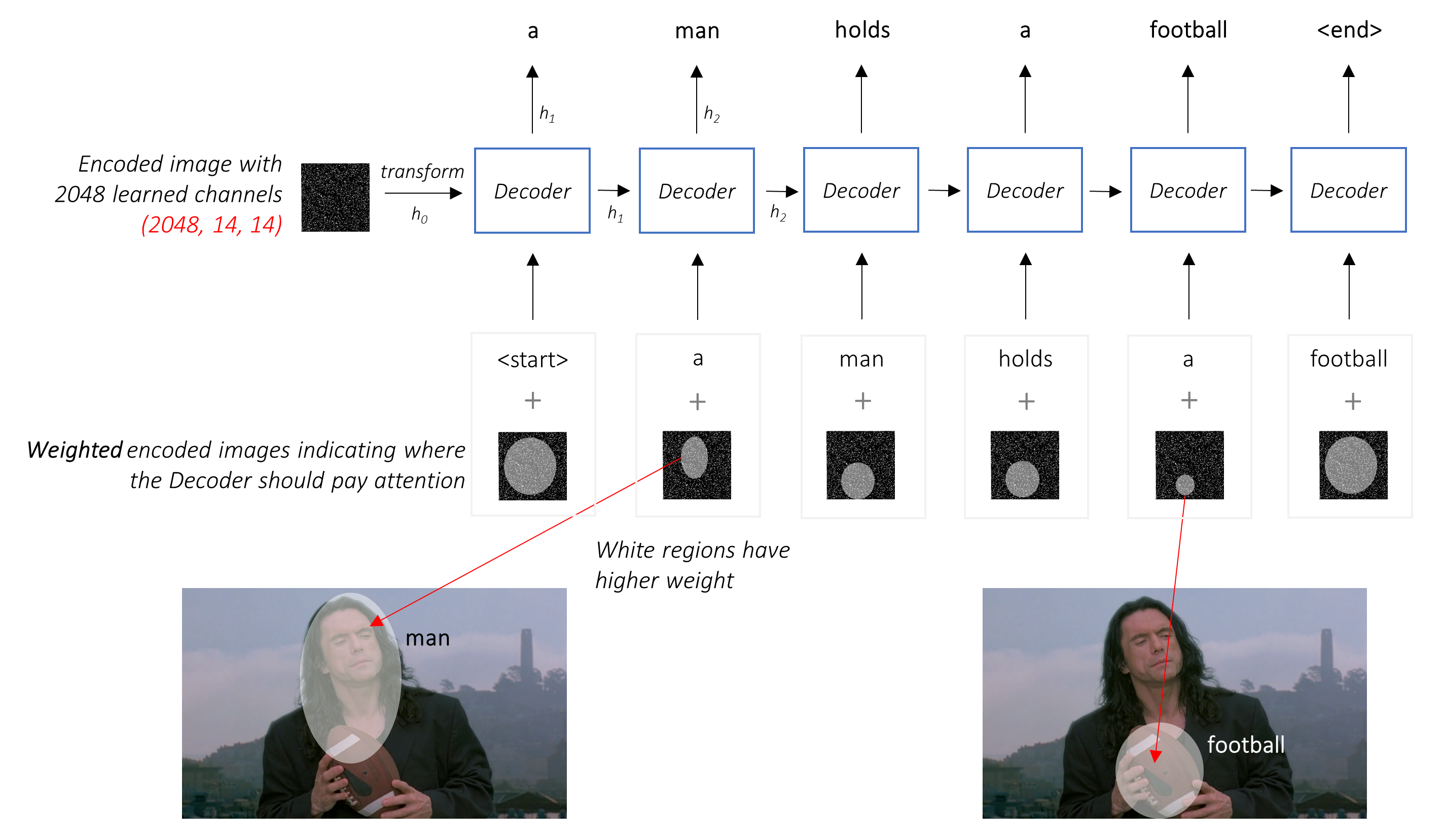
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022
Evaluation Pipeline for our ECCV2020: Journey Towards Tiny Perceptual Super-Resolution.
Journey Towards Tiny Perceptual Super-Resolution Test code for our ECCV2020 paper: https://arxiv.org/abs/2007.04356 Our x4 upscaling pre-trained model
 6 Mar 30, 2022
6 Mar 30, 2022