328 Repositories
Python pre-commit-hook Libraries

PyTorch implementation of Octave Convolution with pre-trained Oct-ResNet and Oct-MobileNet models
octconv.pytorch PyTorch implementation of Octave Convolution in Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octa
 273 Dec 18, 2022
273 Dec 18, 2022
Find version automatically based on git tags and commit messages.
GIT-CONVENTIONAL-VERSION Find version automatically based on git tags and commit messages. The tool is very specific in its function, so it is very fl
 0 Nov 7, 2021
0 Nov 7, 2021
Official code for the paper Inverse Problems Leveraging Pre-trained Contrastive Representations.
The official code for the paper "Inverse Problems Leveraging Pre-trained Contrastive Representations" (to appear in NeurIPS 2021).
 16 Oct 24, 2021
16 Oct 24, 2021

This repository contains all source code, pre-trained models related to the paper "An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator"
An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator This is a Pytorch implementation for the paper "An Empirical Study o
 3 Nov 15, 2021
3 Nov 15, 2021
Script to quickly get the metrics from Github repos to analyze.
commit-prefix-analysis Script to quickly get the metrics from Github repos to analyze. Setup Install the Github CLI. You'll know its working when runn
 1 Dec 17, 2022
1 Dec 17, 2022
Cutting-edge GitHub page customization tool
Cutting-edge GitHub page customization tool Want to customize your GitHub user page, but don't know how? Now you can make your profile unique and attr
 32 Aug 24, 2022
32 Aug 24, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023
Implementation of Natural Language Code Search in the project CodeBERT: A Pre-Trained Model for Programming and Natural Languages.
CodeBERT-Implementation In this repo we have replicated the paper CodeBERT: A Pre-Trained Model for Programming and Natural Languages. We are interest
 4 Jul 1, 2022
4 Jul 1, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

An NLP library with Awesome pre-trained Transformer models and easy-to-use interface, supporting wide-range of NLP tasks from research to industrial applications.
简体中文 | English News [2021-10-12] PaddleNLP 2.1版本已发布!新增开箱即用的NLP任务能力、Prompt Tuning应用示例与生成任务的高性能推理! 🎉 更多详细升级信息请查看Release Note。 [2021-08-22]《千言:面向事实一致性的生
 6.9k Jan 1, 2023
6.9k Jan 1, 2023
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022

Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
 123 Dec 23, 2022
123 Dec 23, 2022
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System Authors: Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai
124 Jan 3, 2023

Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer
MT5_paddle Use PaddlePaddle to reproduce the paper:mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer English | 简体中文 mT5: A Massively
 2 Oct 17, 2021
2 Oct 17, 2021

Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
DeCLIP Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. Our paper is available in arxiv Updates ** Ou
 470 Dec 30, 2022
470 Dec 30, 2022
Self-Supervised Speech Pre-training and Representation Learning Toolkit.
What's New Sep 2021: We host a challenge in AAAI workshop: The 2nd Self-supervised Learning for Audio and Speech Processing! See SUPERB official site
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
ImageNet-CoG is a benchmark for concept generalization. It provides a full evaluation framework for pre-trained visual representations which measure how well they generalize to unseen concepts.
The ImageNet-CoG Benchmark Project Website Paper (arXiv) Code repository for the ImageNet-CoG Benchmark introduced in the paper "Concept Generalizatio
 23 Oct 9, 2022
23 Oct 9, 2022

Making self-supervised learning work on molecules by using their 3D geometry to pre-train GNNs. Implemented in DGL and Pytorch Geometric.
3D Infomax improves GNNs for Molecular Property Prediction Video | Paper We pre-train GNNs to understand the geometry of molecules given only their 2D
 95 Dec 30, 2022
95 Dec 30, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 282 Jan 9, 2023
282 Jan 9, 2023
A simple cli tool to commit Conventional Commits
convmoji A simple cli tool to commit Conventional Commits. Requirements Install pip install convmoji convmoji --help Examples A conventianal commit co
 3 Jul 4, 2022
3 Jul 4, 2022
Pre-training BERT masked language models with custom vocabulary
Pre-training BERT Masked Language Models (MLM) This repository contains the method to pre-train a BERT model using custom vocabulary. It was used to p
 14 Nov 2, 2022
14 Nov 2, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
ICLR 2021: Pre-Training for Context Representation in Conversational Semantic Parsing
SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing This repository contains code for the ICLR 2021 paper "SCoRE: Pre-Tr
28 Oct 2, 2022

DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian
 117 Jan 7, 2023
117 Jan 7, 2023
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks
Prompt-learning is the latest paradigm to adapt pre-trained language models (PLMs) to downstream NLP tasks, which modifies the input text with a textual template and directly uses PLMs to conduct pre-trained tasks. This library provides a standard, flexible and extensible framework to deploy the prompt-learning pipeline. OpenPrompt supports loading PLMs directly from huggingface transformers. In the future, we will also support PLMs implemented by other libraries.
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022
Pre-trained BERT Models for Ancient and Medieval Greek, and associated code for LaTeCH 2021 paper titled - "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek"
Ancient Greek BERT The first and only available Ancient Greek sub-word BERT model! State-of-the-art post fine-tuning on Part-of-Speech Tagging and Mor
 22 Dec 8, 2022
22 Dec 8, 2022
DziriBERT: a Pre-trained Language Model for the Algerian Dialect
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect.
117 Jan 7, 2023
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
Git Hooks Tutorial.
Git Hooks Tutorial My public talk about this project at Sberloga: Git Hooks Is All You Need 1. Git Hooks 101 Init git repo: mkdir git_repo cd git_repo
 17 Oct 12, 2022
17 Oct 12, 2022

High level network definitions with pre-trained weights in TensorFlow
TensorNets High level network definitions with pre-trained weights in TensorFlow (tested with 2.1.0 = TF = 1.4.0). Guiding principles Applicability.
 1k Dec 13, 2022
1k Dec 13, 2022
The uncompromising Python code formatter
The Uncompromising Code Formatter “Any color you like.” Black is the uncompromising Python code formatter. By using it, you agree to cede control over
 30.7k Jan 3, 2023
30.7k Jan 3, 2023
The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing".
BMC The code for the NSDI'21 paper "BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing". BibTex entry available here. B
 383 Dec 16, 2022
383 Dec 16, 2022
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
TorchGeo is a PyTorch domain library, similar to torchvision, that provides datasets, transforms, samplers, and pre-trained models specific to geospatial data.
1.3k Dec 30, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022

Search Git commits in natural language
NaLCoS - NAtural Language COmmit Search Search commit messages in your repository in natural language. NaLCoS (NAtural Language COmmit Search) is a co
 50 Mar 22, 2022
50 Mar 22, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022

A stock information collector and parser for Taiwan and US market. Automatically send LINE message if the pre-defined rules are triggered.
agastock 開發動機 就在海運飆漲的2021年7月,差點跪在地上喜迎財富自由的當下,EPS超高好消息不斷的長榮竟然套在202元一去不回,有圖有真相(哭) 忽然體會到追高殺低不是辦法,魯蛇我得靠邏輯分析也能出頭天,經過三個月無數個不出門的周末,產出簡單的爬蟲和分析工具。 上過金融研訓院的量化交易
 12 Nov 16, 2022
12 Nov 16, 2022
NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking
pretrain4ir_tutorial NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking 用作NLPIR实验室, Pre-training
 12 Apr 7, 2022
12 Apr 7, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023

The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
The code for our paper "NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task —— Next Sentence Prediction"
 201 Nov 21, 2022
201 Nov 21, 2022
Code and checkpoints for training the transformer-based Table QA models introduced in the paper TAPAS: Weakly Supervised Table Parsing via Pre-training.
End-to-end neural table-text understanding models.
 914 Jan 7, 2023
914 Jan 7, 2023

CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection
CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection Usage usage: cve-2021-26084_confluence_rce.py [-h] --url URL [--cmd CMD] [--shell] CVE-2021-2
 92 Jul 20, 2022
92 Jul 20, 2022
Binance leverage futures Hook
Simple binance futures Attention Just use leverage. The fee difference between futures and spot is not considered. For example, funding rate, etc. Onl
 26 Aug 27, 2022
26 Aug 27, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
TAPEX: Table Pre-training via Learning a Neural SQL Executor
TAPEX: Table Pre-training via Learning a Neural SQL Executor The official repository which contains the code and pre-trained models for our paper TAPE
157 Dec 28, 2022
Codes to pre-train Japanese T5 models
t5-japanese Codes to pre-train a T5 (Text-to-Text Transfer Transformer) model pre-trained on Japanese web texts. The model is available at https://hug
 37 Dec 25, 2022
37 Dec 25, 2022
This Telegram bot allows you to create direct links with pre-filled text to WhatsApp Chats
WhatsApp API Bot Telegram bot to create direct links with pre-filled text for WhatsApp Chats You can check our bot here. The bot is based on the API p
 17 Aug 20, 2022
17 Aug 20, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
 332 Dec 18, 2022
332 Dec 18, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
PyTorch implementation of the Transformer in Post-LN (Post-LayerNorm) and Pre-LN (Pre-LayerNorm).
Transformer-PyTorch A PyTorch implementation of the Transformer from the paper Attention is All You Need in both Post-LN (Post-LayerNorm) and Pre-LN (
 22 Feb 27, 2022
22 Feb 27, 2022
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS: Masked Sequence to Sequence Pre-training for Language Generation
1.1k Dec 17, 2022
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files
Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files. Mdformat is a Unix-style command-line tool as well as a Python library.
 180 Jan 6, 2023
180 Jan 6, 2023

🐥A PyTorch implementation of OpenAI's finetuned transformer language model with a script to import the weights pre-trained by OpenAI
PyTorch implementation of OpenAI's Finetuned Transformer Language Model This is a PyTorch implementation of the TensorFlow code provided with OpenAI's
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

Hook Slinger acts as a simple service that lets you send, retry, and manage event-triggered POST requests, aka webhooks
Hook Slinger acts as a simple service that lets you send, retry, and manage event-triggered POST requests, aka webhooks. It provides a fully self-contained docker image that is easy to orchestrate, manage, and scale.
 96 Jan 2, 2023
96 Jan 2, 2023
Implementation of PyTorch-based multi-task pre-trained models
mtdp Library containing implementation related to the research paper "Multi-task pre-training of deep neural networks for digital pathology" (Mormont
 27 Oct 14, 2022
27 Oct 14, 2022

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
Cross-platform .NET Core pre-commit hooks
dotnet-core-pre-commit Cross-platform .NET Core pre-commit hooks How to use Add this to your .pre-commit-config.yaml - repo: https://github.com/juan
 5 Jul 20, 2021
5 Jul 20, 2021
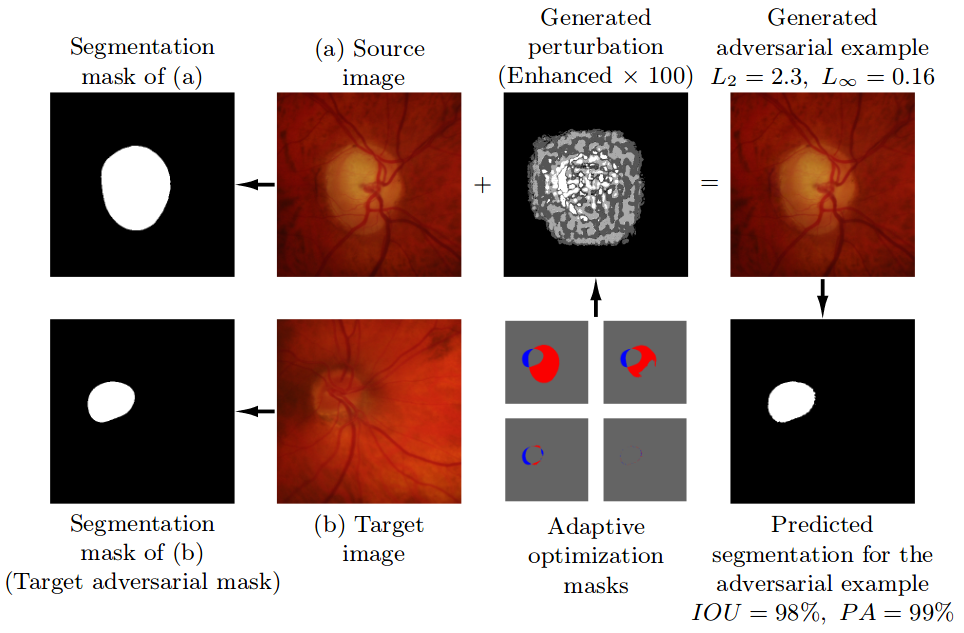
Pre-trained model, code, and materials from the paper "Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation" (MICCAI 2019).
Adaptive Segmentation Mask Attack This repository contains the implementation of the Adaptive Segmentation Mask Attack (ASMA), a targeted adversarial
 53 Jul 4, 2022
53 Jul 4, 2022

The purpose of this script is to bypass disablefund, provide some useful information, and dig the hook function of PHP extension.
The purpose of this script is to bypass disablefund, provide some useful information, and dig the hook function of PHP extension.
 14 Aug 2, 2021
14 Aug 2, 2021
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
197 Nov 26, 2022

Source code for paper: Knowledge Inheritance for Pre-trained Language Models
Knowledge-Inheritance Source code paper: Knowledge Inheritance for Pre-trained Language Models (preprint). The trained model parameters (in Fairseq fo
31 Nov 19, 2022
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption, CVPR 2021 (Oral)
TAP: Text-Aware Pre-training TAP: Text-Aware Pre-training for Text-VQA and Text-Caption by Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Flo
61 Nov 14, 2022
CVPR 2021 Official Pytorch Code for UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
UC2 UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu,
 28 Dec 30, 2022
28 Dec 30, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022

We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction
We envision models that are pre-trained on a vast range of domain-relevant tasks to become key for molecule property prediction. This repository aims to give easy access to state-of-the-art pre-trained models.
 90 Jan 8, 2023
90 Jan 8, 2023
Your missing PO formatter and linter
pofmt Your missing PO formatter and linter Features Wrap msgid and msgstr with a constant max width. Can act as a pre-commit hook. Display lint errors
 5 Mar 22, 2022
5 Mar 22, 2022
Code for CPM-2 Pre-Train
CPM-2 Pre-Train Pre-train CPM-2 此分支为110亿非 MoE 模型的预训练代码,MoE 模型的预训练代码请切换到 moe 分支 CPM-2技术报告请参考link。 0 模型下载 请在智源资源下载页面进行申请,文件介绍如下: 文件名 描述 参数大小 100000.tar
 136 Dec 28, 2022
136 Dec 28, 2022

A pre-attack hacker tool which aims to find out sensitives comments in HTML comment tag and to help on reconnaissance process
Find Out in Comment Find sensetive comment out in HTML ⚈ About This is a pre-attack hacker tool that searches for sensitives words in HTML comments ta
 8 Dec 31, 2022
8 Dec 31, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
 192 Dec 23, 2022
192 Dec 23, 2022

The official PyTorch implementation of recent paper - SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
This repository is the official PyTorch implementation of SAINT. Find the paper on arxiv SAINT: Improved Neural Networks for Tabular Data via Row Atte
 284 Dec 21, 2022
284 Dec 21, 2022
Today I Commit (1일 1커밋) 챌린지 알림 봇
Today I Commit Challenge 1일1커밋 챌린지를 위한 알림 봇 config.py github_token = "github private access key" slack_token = "slack authorization token" channel = "
 4 Nov 8, 2021
4 Nov 8, 2021
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
75 Nov 2, 2022
Pre-Auth Blind NoSQL Injection leading to Remote Code Execution in Rocket Chat 3.12.1
CVE-2021-22911 Pre-Auth Blind NoSQL Injection leading to Remote Code Execution in Rocket Chat 3.12.1 The getPasswordPolicy method is vulnerable to NoS
 47 Nov 9, 2022
47 Nov 9, 2022
![[CVPR 2021]](https://github.com/VITA-Group/CV_LTH_Pre-training/raw/main/Figs/Teaser.png)
[CVPR 2021] "The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models" Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Michael Carbin, Zhangyang Wang
The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models Codes for this paper The Lottery Tickets Hypo
 59 Dec 28, 2022
59 Dec 28, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT).
Dynamic-Vision-Transformer (Pytorch) This repo contains the official code and pre-trained models for the Dynamic Vision Transformer (DVT). Not All Ima
 210 Dec 18, 2022
210 Dec 18, 2022
Simple dotfile pre-processor with a per-file configuration
ix (eeks) Simple dotfile pre-processor with a per-file configuration Summary (TL;DR) ix.py is all you need config is an ini file. files to be processe
 12 Dec 16, 2021
12 Dec 16, 2021
Code for CPM-2 Pre-Train
CPM-2 Pre-Train Pre-train CPM-2 此分支为110亿非 MoE 模型的预训练代码,MoE 模型的预训练代码请切换到 moe 分支 CPM-2技术报告请参考link。 0 模型下载 请在智源资源下载页面进行申请,文件介绍如下: 文件名 描述 参数大小 100000.tar
136 Dec 28, 2022
Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
ImageProcessingTransformer Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
 61 Jan 1, 2023
61 Jan 1, 2023
(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
248 Dec 4, 2022
![[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning](https://github.com/researchmm/soho/raw/master/resources/soho.png)
[CVPR'21 Oral] Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning
Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning [CVPR'21, Oral] By Zhicheng Huang*, Zhaoyang Zeng*, Yupan H
 196 Dec 13, 2022
196 Dec 13, 2022
Unsupervised Pre-training for Person Re-identification (LUPerson)
LUPerson Unsupervised Pre-training for Person Re-identification (LUPerson). The repository is for our CVPR2021 paper Unsupervised Pre-training for Per
 143 Dec 24, 2022
143 Dec 24, 2022
Standalone pre-training recipe with JAX+Flax
Sabertooth Sabertooth is standalone pre-training recipe based on JAX+Flax, with data pipelines implemented in Rust. It runs on CPU, GPU, and/or TPU, b
 26 Nov 28, 2022
26 Nov 28, 2022
One Stop Anomaly Shop: Anomaly detection using two-phase approach: (a) pre-labeling using statistics, Natural Language Processing and static rules; (b) anomaly scoring using supervised and unsupervised machine learning.
One Stop Anomaly Shop (OSAS) Quick start guide Step 1: Get/build the docker image Option 1: Use precompiled image (might not reflect latest changes):
 148 Dec 26, 2022
148 Dec 26, 2022
Pytorch implementation of our paper under review — Lottery Jackpots Exist in Pre-trained Models
Lottery Jackpots Exist in Pre-trained Models (Paper Link) Requirements Python = 3.7.4 Pytorch = 1.6.1 Torchvision = 0.4.1 Reproduce the Experiment
 27 Jun 28, 2022
27 Jun 28, 2022
Official code of our work, Unified Pre-training for Program Understanding and Generation [NAACL 2021].
PLBART Code pre-release of our work, Unified Pre-training for Program Understanding and Generation accepted at NAACL 2021. Note. A detailed documentat
 138 Dec 30, 2022
138 Dec 30, 2022

A modern, geometric typeface by @chrismsimpson (last commit @ 85fa625 Jun 9, 2020 before deletion)
Metropolis A modern, geometric typeface. Influenced by other popular geometric, minimalist sans-serif typefaces of the new millenium. Designed for opt
 183 Dec 25, 2022
183 Dec 25, 2022
《K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters》(2020)
K-Adapter: Infusing Knowledge into Pre-Trained Models with Adapters This repository is the implementation of the paper "K-Adapter: Infusing Knowledge
118 Dec 13, 2022
Code for pre-training CharacterBERT models (as well as BERT models).
Pre-training CharacterBERT (and BERT) This is a repository for pre-training BERT and CharacterBERT. DISCLAIMER: The code was largely adapted from an o
 31 Dec 5, 2022
31 Dec 5, 2022