860 Repositories
Python science-research Libraries

Open-Source CI/CD platform for ML teams. Deliver ML products, better & faster. ⚡️🧑🔧
Deliver ML products, better & faster Giskard is an Open-Source CI/CD platform for ML teams. Inspect ML models visually from your Python notebook 📗 Re
 335 Jan 4, 2023
335 Jan 4, 2023

Course materials for: Geospatial Data Science
Course materials for: Geospatial Data Science These course materials cover the lectures for the course held for the first time in spring 2022 at IT Un
 266 Jan 2, 2023
266 Jan 2, 2023

Forecasting for knowable future events using Bayesian informative priors (forecasting with judgmental-adjustment).
What is judgyprophet? judgyprophet is a Bayesian forecasting algorithm based on Prophet, that enables forecasting while using information known by the
 56 Oct 26, 2022
56 Oct 26, 2022
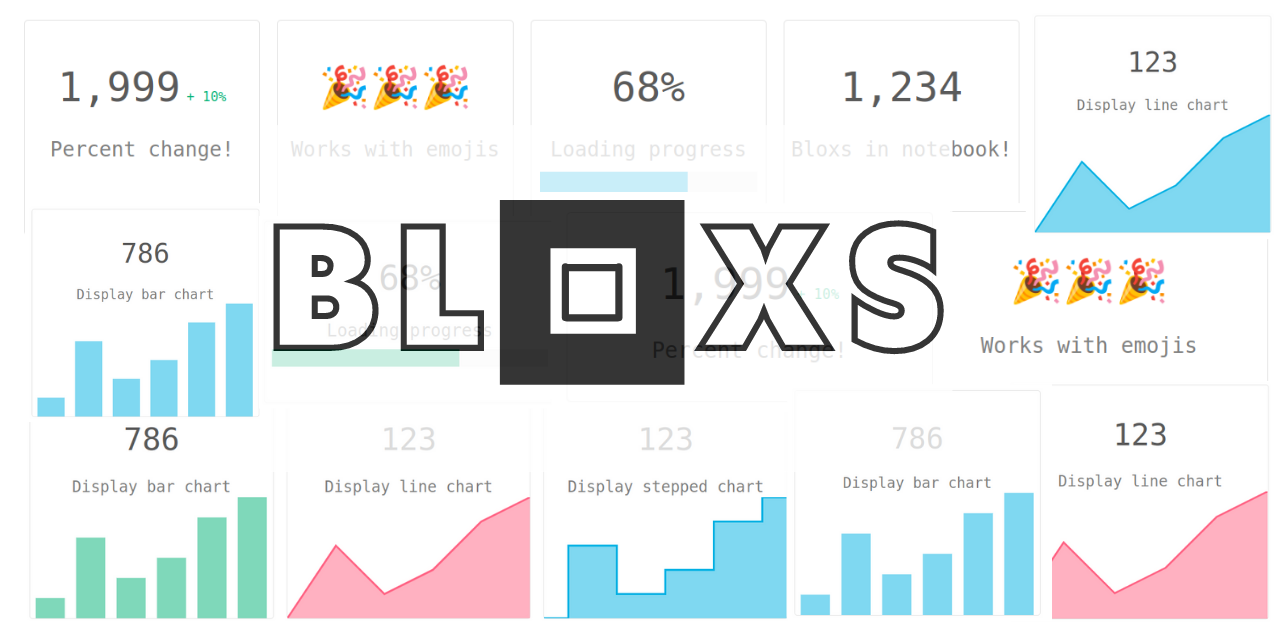
Display your data in an attractive way in your notebook!
Bloxs Bloxs is a simple python package that helps you display information in an attractive way (formed in blocks). Perfect for building dashboards, re
 192 Dec 28, 2022
192 Dec 28, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022
Sample code and notebooks for Vertex AI, the end-to-end machine learning platform on Google Cloud
Google Cloud Vertex AI Samples Welcome to the Google Cloud Vertex AI sample repository. Overview The repository contains notebooks and community conte
 560 Dec 31, 2022
560 Dec 31, 2022
Write python locally, execute SQL in your data warehouse
RasgoQL Write python locally, execute SQL in your data warehouse ≪ Read the Docs · Join Our Slack » RasgoQL is a Python package that enables you to ea
 265 Nov 21, 2022
265 Nov 21, 2022

This repository contains all the data analytics projects that I've worked on in python.
93_Python_Data_Analytics_Projects This repository contains all the data analytics projects that I've worked on in python. No. Name 01 001_Cervical_Can
 267 Jan 6, 2023
267 Jan 6, 2023
This repository contains implementations of all Machine Learning Algorithms from scratch in Python. Mathematics required for ML and many projects have also been included.
👏 Pre- requisites to Machine Learning
 147 Jan 7, 2023
147 Jan 7, 2023
My Solutions to 120 commonly asked data science interview questions.
Data_Science_Interview_Questions Introduction 👋 Here are the answers to 120 Data Science Interview Questions The above answer some is modified based
181 Dec 31, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
Implementation of RITA (Real Intelligence Threat Analytics) in Jupyter Notebook with improved scoring algorithm.
RITA (Real Intelligence Threat Analytics) in Jupyter Notebook RITA is an open source framework for network traffic analysis sponsored by Active Counte
 157 Nov 24, 2022
157 Nov 24, 2022
Sionna: An Open-Source Library for Next-Generation Physical Layer Research
Sionna: An Open-Source Library for Next-Generation Physical Layer Research Sionna™ is an open-source Python library for link-level simulations of digi
 313 Dec 22, 2022
313 Dec 22, 2022
Repositório para o #alurachallengedatascience1
1° Challenge de Dados - Alura A Alura Voz é uma empresa de telecomunicação que nos contratou para atuar como cientistas de dados na equipe de vendas.
 16 Nov 10, 2022
16 Nov 10, 2022
Exploration & Research into cross-domain MEV. Initial focus on ETH/POLYGON.
xMEV, an apt exploration This is a small exploration on the xMEV opportunities between Polygon and Ethereum. It's a data analysis exercise on a few pa
 7 Oct 18, 2022
7 Oct 18, 2022

Detecting silent model failure. NannyML estimates performance with an algorithm called Confidence-based Performance estimation (CBPE), developed by core contributors. It is the only open-source algorithm capable of fully capturing the impact of data drift on performance.
Website • Docs • Community Slack 💡 What is NannyML? NannyML is an open-source python library that allows you to estimate post-deployment model perfor
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022
TigerLily: Finding drug interactions in silico with the Graph.
Drug Interaction Prediction with Tigerlily Documentation | Example Notebook | Youtube Video | Project Report Tigerlily is a TigerGraph based system de
 91 Dec 30, 2022
91 Dec 30, 2022
Ana's Portfolio
Ana's Portfolio ✌️ Welcome to my Portfolio! You will find here different Projects I have worked on (from scratch) 💪 Projects 💻 1️⃣ Hangman game (Mad
 9 Mar 15, 2022
9 Mar 15, 2022
DLO8012: Natural Language Processing & CSL804: Computational Lab - II Semester VIII
NATURAL-LANGUAGE-PROCESSING-AND-COMPUTATIONAL-LAB-II DLO8012: NLP & CSL804: CL-II [SEMESTER VIII] Syllabus NLP - Reference Books THE WALL MEGA SATISH
 7 Apr 28, 2022
7 Apr 28, 2022
Resources complimenting the Machine Learning Course led in the Faculty of mathematics and informatics part of Sofia University.
Machine Learning and Data Mining, Summer 2021-2022 How to learn data science and machine learning? Programming. Learn Python. Basic Statistics. Take a
 8 Oct 4, 2022
8 Oct 4, 2022
On Uncertainty, Tempering, and Data Augmentation in Bayesian Classification
Understanding Bayesian Classification This repository hosts the code to reproduce the results presented in the paper On Uncertainty, Tempering, and Da
 18 Nov 17, 2022
18 Nov 17, 2022
This repository contains helper functions which can help you generate additional data points depending on your NLP task.
NLP Albumentations For Data Augmentation This repository contains helper functions which can help you generate additional data points depending on you
 6 May 22, 2022
6 May 22, 2022

Machine learning beginner to Kaggle competitor in 30 days. Non-coders welcome. The program starts Monday, August 2, and lasts four weeks. It's designed for people who want to learn machine learning.
30-Days-of-ML-Kaggle 🔥 About the Hands On Program 💻 Machine learning beginner → Kaggle competitor in 30 days. Non-coders welcome The program starts
 145 Jan 1, 2023
145 Jan 1, 2023
Tutorial repo for an end-to-end Data Science project
End-to-end Data Science project This is the repo with the notebooks, code, and additional material used in the ITI's workshop. The goal of the session
 127 Dec 30, 2022
127 Dec 30, 2022
AI Summer's complete catalog of articles
Learn Deep Learning with AI Summer A collection of all articles (almost 100) written for the AI Summer blog organized by topic. Deep Learning Theory M
 95 Dec 29, 2022
95 Dec 29, 2022
1000+ ready code templates to kickstart your next AI experiment
AI Seed Projects Start with ready code for your next AI experiment. Choose from 1000+ code templates, across a wide variety of use cases. All examples
 98 Jan 3, 2023
98 Jan 3, 2023

This is a repo of basic Machine Learning!
Basic Machine Learning This repository contains a topic-wise curated list of Machine Learning and Deep Learning tutorials, articles and other resource
 53 Dec 31, 2022
53 Dec 31, 2022
Research on Tabular Deep Learning (Python package & papers)
Research on Tabular Deep Learning For paper implementations, see the section "Papers and projects". rtdl is a PyTorch-based package providing a user-f
 510 Dec 30, 2022
510 Dec 30, 2022
Hacktoberfest 2021 contribution repository✨
🎃 HacktoberFest-2021 🎃 Repository for Hacktoberfest Note: Although, We are actively focusing on Machine Learning, Data Science and Tricky Python pro
 42 Dec 11, 2022
42 Dec 11, 2022

As we all know the BGMI Loot Crate comes with so many resources for the gamers, this ML Crate will be the hub of various ML projects which will be the resources for the ML enthusiasts! Open Source Program: SWOC 2021 and JWOC 2022.
Machine Learning Loot Crate 💻 🧰 🔴 Welcome contributors! As we all know the BGMI Loot Crate comes with so many resources for the gamers, this ML Cra
 89 Dec 28, 2022
89 Dec 28, 2022

Learn Data Science with focus on adding value with the most efficient tech stack.
DataScienceWithPython Get started with Data Science with Python An engaging journey to become a Data Scientist with Python TL;DR Download all Jupyter
 110 Dec 22, 2022
110 Dec 22, 2022

Data Inspector is an open-source python library that brings 15++ types of different functions to make EDA, data cleaning easier.
Data Inspector Data Inspector is an open-source python library that brings 15 types of different functions to make EDA, data cleaning easier. Author:
 38 Nov 24, 2022
38 Nov 24, 2022
Threat research and reporting from IronNet's Threat Research Teams
IronNet Threat Research 🕵️ Overview This repository contains IronNet's Threat Research. Research & Reporting 📝 Project Description Cobalt Strike Res
 36 Dec 2, 2022
36 Dec 2, 2022
A python script that discovers hidden YouTube API clients. Just a research project.
YouTube-Internal-Clients A script that discovers hidden internal clients of the YouTube (Innertube) API using bruteforce methods. The script tries cli
 97 Jan 2, 2023
97 Jan 2, 2023

A Flask Sentiment Analysis API, with visual implementation
The Sentiment Analysis Api was created using python flask module,it allows users to parse a text or sentence throught the (?text) arguement, then view the sentiment analysis of that sentence. It can be implementable into a web application.
 10 Jul 17, 2022
10 Jul 17, 2022
DataAnalysis: Some data analysis projects in charles_pikachu
DataAnalysis DataAnalysis: Some data analysis projects in charles_pikachu You can star this repository to keep track of the project if it's helpful fo
 9 Nov 4, 2022
9 Nov 4, 2022
This project aims to conduct a text information retrieval and text mining on medical research publication regarding Covid19 - treatments and vaccinations.
Project: Text Analysis - This project aims to conduct a text information retrieval and text mining on medical research publication regarding Covid19 -
 1 Mar 14, 2022
1 Mar 14, 2022
Udacity's CS101: Intro to Computer Science - Building a Search Engine
Udacity's CS101: Intro to Computer Science - Building a Search Engine All soluti
 0 Feb 26, 2022
0 Feb 26, 2022
Nflmetrics - Johns Hopkins Spring 2022 Sports Analytics research project about NFL Draft Metrics
nflmetrics GitHub repo for Johns Hopkins Spring 2022 Sports Analytics research p
 4 Feb 24, 2022
4 Feb 24, 2022
Lightweight mmm - Lightweight (Bayesian) Media Mix Model
Lightweight (Bayesian) Media Mix Model This is not an official Google product. L
 342 Jan 3, 2023
342 Jan 3, 2023
LotteryBuyPredictionWebApp - Lottery Purchase Prediction Model
Lottery Purchase Prediction Model Objective and Goal Predict the lottery type th
 2 Feb 14, 2022
2 Feb 14, 2022
Explore-bikeshare-data - GitHub project as part of the Programming for Data Science with Python Nanodegree from Udacity
Date created February 10, 2022 Project Title Explore US Bikeshare Data Descripti
 1 Feb 14, 2022
1 Feb 14, 2022
The LaTeX and Python code for generating the paper, experiments' results and visualizations reported in each paper is available (whenever possible) in the paper's directory
This repository contains the software implementation of most algorithms used or developed in my research. The LaTeX and Python code for generating the
 3 Jan 3, 2023
3 Jan 3, 2023
Collection of TensorFlow2 implementations of Generative Adversarial Network varieties presented in research papers.
TensorFlow2-GAN Collection of tf2.0 implementations of Generative Adversarial Network varieties presented in research papers. Model architectures will
 41 Apr 28, 2022
41 Apr 28, 2022
Skforecast is a python library that eases using scikit-learn regressors as multi-step forecasters
Skforecast is a python library that eases using scikit-learn regressors as multi-step forecasters. It also works with any regressor compatible with the scikit-learn API (pipelines, CatBoost, LightGBM, XGBoost, Ranger...).
 297 Jan 9, 2023
297 Jan 9, 2023

Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track)
Kcse-Data-Analysis Data science project for exploratory analysis on the kcse grades dataset (Kamilimu Data Science Track) Findings The performance of
 1 Feb 23, 2022
1 Feb 23, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022
Data science/Analysis Health Care Portfolio
Health-Care-DS-Projects Data Science/Analysis Health Care Portfolio Consists Of 3 Projects: Mexico Covid-19 project, analyze the patient medical histo
 1 Feb 13, 2022
1 Feb 13, 2022
This is my research project for the Irving Center for Cancer Dynamics/Azizi Lab, Columbia University.
bayesian_uncertainty This is my research project for the Irving Center for Cancer Dynamics/Azizi Lab, Columbia University. In this project I build a s
 1 Feb 13, 2022
1 Feb 13, 2022
LightGBM + Optuna: no brainer
AutoLGBM LightGBM + Optuna: no brainer auto train lightgbm directly from CSV files auto tune lightgbm using optuna auto serve best lightgbm model usin
 22 Dec 15, 2022
22 Dec 15, 2022

Image-to-image regression with uncertainty quantification in PyTorch
Image-to-image regression with uncertainty quantification in PyTorch. Take any dataset and train a model to regress images to images with rigorous, distribution-free uncertainty quantification.
 25 Dec 26, 2022
25 Dec 26, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
Reading list for research topics in Masked Image Modeling
awesome-MIM Reading list for research topics in Masked Image Modeling(MIM). We list the most popular methods for MIM, if I missed something, please su
 231 Dec 7, 2022
231 Dec 7, 2022
Course materials for Fall 2021 "CIS6930 Topics in Computing for Data Science" at New College of Florida
Fall 2021 CIS6930 Topics in Computing for Data Science This repository hosts course materials used for a 13-week course "CIS6930 Topics in Computing f
 101 Nov 30, 2022
101 Nov 30, 2022

Geospatial data-science analysis on reasons behind delay in Grab ride-share services
Grab x Pulis Detailed analysis done to investigate possible reasons for delay in Grab services for NUS Data Analytics Competition 2022, to be found in
 6 Jun 7, 2022
6 Jun 7, 2022

metedraw is a project mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors
It is mainly for data visualization projects of Atmospheric Science, Marine Science, Environmental Science or other majors.
 11 Jul 5, 2022
11 Jul 5, 2022

A research of IT labor market based especially on hh.ru. Salaries, rate of technologies and etc.
hh_ru_research Проект реализован в учебных целях анализа рынка труда, в особенности по hh.ru Input data В качестве входных данных используются сериали
 3 Sep 7, 2022
3 Sep 7, 2022

Implementation of SOMs (Self-Organizing Maps) with neighborhood-based map topologies.
py-self-organizing-maps Simple implementation of self-organizing maps (SOMs) A SOM is an unsupervised method for learning a mapping from a discrete ne
 6 Nov 22, 2022
6 Nov 22, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022
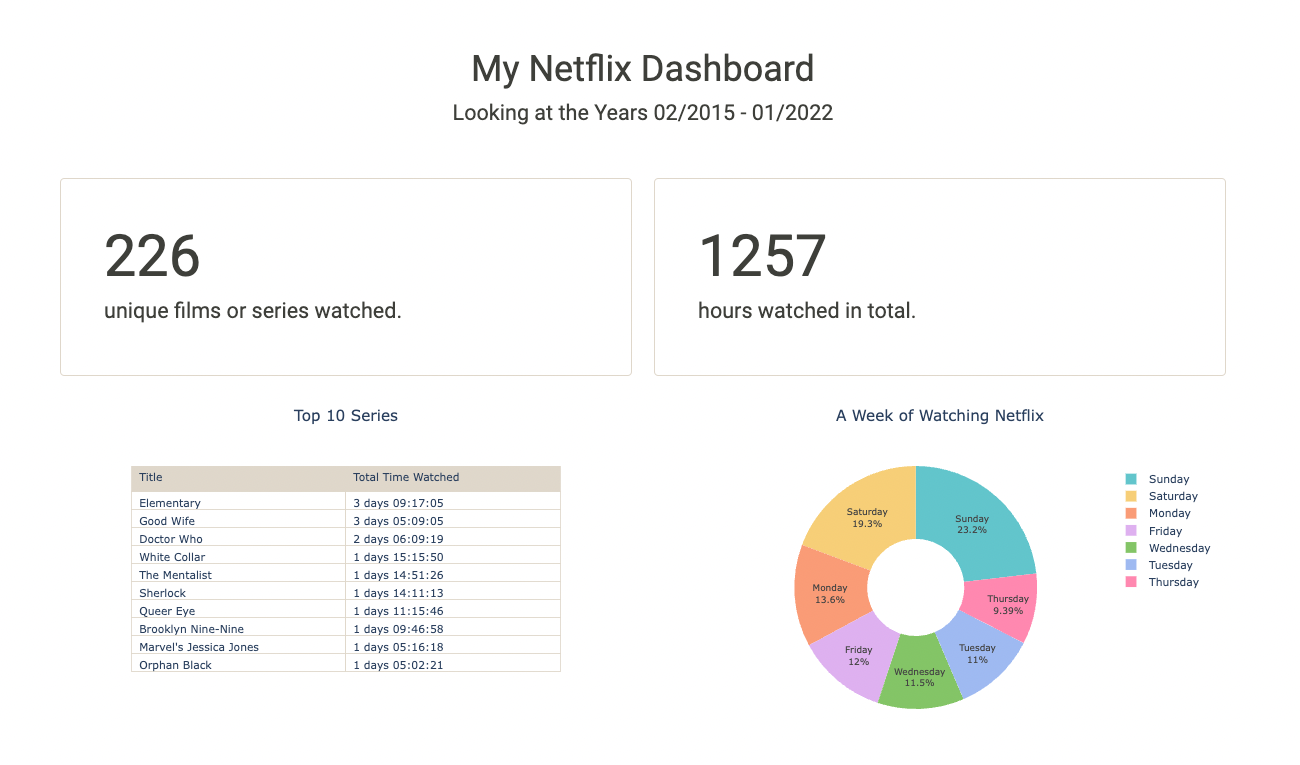
Project: Netflix Data Analysis and Visualization with Python
Project: Netflix Data Analysis and Visualization with Python Table of Contents General Info Installation Demo Usage and Main Functionalities Contribut
 2 Feb 13, 2022
2 Feb 13, 2022
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model About This repository contains the code to replicate the syn
 12 Dec 7, 2022
12 Dec 7, 2022
Python package for concise, transparent, and accurate predictive modeling
Python package for concise, transparent, and accurate predictive modeling. All sklearn-compatible and easy to use. 📚 docs • 📖 demo notebooks Modern
 983 Jan 1, 2023
983 Jan 1, 2023
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python
Definitive Guide to Creating a SQL Database on Cloud with AWS and Python An easy-to-follow comprehensive guide on integrating Amazon RDS, MySQL Workbe
 6 Aug 17, 2022
6 Aug 17, 2022

Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression
Regression Transformer Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression . Development se
 27 Jan 5, 2023
27 Jan 5, 2023
This repository contains numerical implementation for the paper Intertemporal Pricing under Reference Effects: Integrating Reference Effects and Consumer Heterogeneity.
This repository contains numerical implementation for the paper Intertemporal Pricing under Reference Effects: Integrating Reference Effects and Consumer Heterogeneity.
 6 Nov 18, 2022
6 Nov 18, 2022

Open source simulator for autonomous vehicles built on Unreal Engine / Unity, from Microsoft AI & Research
Welcome to AirSim AirSim is a simulator for drones, cars and more, built on Unreal Engine (we now also have an experimental Unity release). It is open
 13.8k Jan 3, 2023
13.8k Jan 3, 2023
Conducted ANOVA and Logistic regression analysis using matplot library to visualize the result.
Intro-to-Data-Science Conducted ANOVA and Logistic regression analysis. Project ANOVA The main aim of this project is to perform One-Way ANOVA analysi
 1 Feb 6, 2022
1 Feb 6, 2022
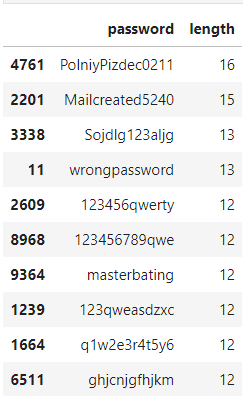
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
 7 Sep 4, 2022
7 Sep 4, 2022
Python script for crawling ResearchGate.net papers✨⭐️📎
ResearchGate Crawler Python script for crawling ResearchGate.net papers About the script This code start crawling process by urls in start.txt and giv
 4 Aug 30, 2022
4 Aug 30, 2022
LabGraph is a a Python-first framework used to build sophisticated research systems with real-time streaming, graph API, and parallelism.
LabGraph is a a Python-first framework used to build sophisticated research systems with real-time streaming, graph API, and parallelism.
 7 Oct 5, 2022
7 Oct 5, 2022

Convert monolithic Jupyter notebooks into Ploomber pipelines.
Soorgeon Join our community | Newsletter | Contact us | Blog | Website | YouTube Convert monolithic Jupyter notebooks into Ploomber pipelines. soorgeo
 65 Dec 16, 2022
65 Dec 16, 2022
Research using python - Guide for development of research code (using Anaconda Python)
Guide for development of research code (using Anaconda Python) TL;DR: One time s
 1 Feb 1, 2022
1 Feb 1, 2022
Our product DrLeaf which not only makes the work easier but also reduces the effort and expenditure of the farmer to identify the disease and its treatment methods.
Our product DrLeaf which not only makes the work easier but also reduces the effort and expenditure of the farmer to identify the disease and its treatment methods. We have to upload the image of an affected plant’s leaf through our website and our plant disease prediction model predicts and returns the disease name. And along with the disease name, we also provide the best suitable methods to cure the disease.
 2 Feb 2, 2022
2 Feb 2, 2022
Learning -- Numpy January 2022 - winter'22
Numerical-Python Numpy NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along
 0 Mar 12, 2022
0 Mar 12, 2022

To-Be is a machine learning challenge on CodaLab Platform about Mortality Prediction
To-Be is a machine learning challenge on CodaLab Platform about Mortality Prediction. The challenge aims to adress the problems of medical imbalanced data classification.
 1 Jan 31, 2022
1 Jan 31, 2022
Template repository for managing machine learning research projects built with PyTorch-Lightning
Tutorial Repository with a minimal example for showing how to deploy training across various compute infrastructure.
 3 Feb 11, 2022
3 Feb 11, 2022
Driver Analysis with Factors and Forests: An Automated Data Science Tool using Python
Driver Analysis with Factors and Forests: An Automated Data Science Tool using Python 📊
 2 May 26, 2022
2 May 26, 2022

Repository for the Demo of using DVC with PyCaret & MLOps (DVC Office Hours - 20th Jan, 2022)
Using DVC with PyCaret & FastAPI (Demo) This repo contains all the resources for my demo explaining how to use DVC along with other interesting tools
 6 Jul 22, 2022
6 Jul 22, 2022
The mitosheet package, trymito.io, and other public Mito code.
Mito Monorepo Mito is a spreadsheet that lives inside your JupyterLab notebooks. It allows you to edit Pandas dataframes like an Excel file, and gener
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
CMSC320 - Introduction to Data Science - Fall 2021
CMSC320 - Introduction to Data Science - Fall 2021 Instructors: Elias Jonatan Gonzalez and José Manuel Calderón Trilla Lectures: MW 3:30-4:45 & 5:00-6
 6 Sep 12, 2022
6 Sep 12, 2022
TIANCHI Purchase Redemption Forecast Challenge
TIANCHI Purchase Redemption Forecast Challenge
 4 Aug 26, 2022
4 Aug 26, 2022
FedML: A Research Library and Benchmark for Federated Machine Learning
FedML: A Research Library and Benchmark for Federated Machine Learning 📄 https://arxiv.org/abs/2007.13518 News 2021-02-01 (Award): #NeurIPS 2020# Fed
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Machine Learning e Data Science com Python
Machine Learning e Data Science com Python Arquivos do curso de Data Science e Machine Learning com Python na Udemy, cliqe aqui para acessá-lo. O prin
 1 Jan 27, 2022
1 Jan 27, 2022
repro_eval is a collection of measures to evaluate the reproducibility/replicability of system-oriented IR experiments
repro_eval repro_eval is a collection of measures to evaluate the reproducibility/replicability of system-oriented IR experiments. The measures were d
 9 May 25, 2022
9 May 25, 2022
This repository contains the implementation of the HealthGen model, a generative model to synthesize realistic EHR time series data with missingness
HealthGen: Conditional EHR Time Series Generation This repository contains the implementation of the HealthGen model, a generative model to synthesize
 0 Jan 20, 2022
0 Jan 20, 2022
Source code related to the article submitted to the International Conference on Computational Science ICCS 2022 in London
POTHER: Patch-Voted Deep Learning-based Chest X-ray Bias Analysis for COVID-19 Detection Source code related to the article submitted to the Internati
 1 Apr 29, 2022
1 Apr 29, 2022
Adaptable tools to make reinforcement learning and evolutionary computation algorithms.
Pearl The Parallel Evolutionary and Reinforcement Learning Library (Pearl) is a pytorch based package with the goal of being excellent for rapid proto
 38 Jan 1, 2023
38 Jan 1, 2023
CSPML (crystal structure prediction with machine learning-based element substitution)
CSPML (crystal structure prediction with machine learning-based element substitution) CSPML is a unique methodology for the crystal structure predicti
 8 Dec 20, 2022
8 Dec 20, 2022

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
Melanoma Skin Cancer Detection using Convolutional Neural Networks and Transfer Learning🕵🏻♂️
This is a Kaggle competition in which we have to identify if the given lesion image is malignant or not for Melanoma which is a type of skin cancer.
 1 Jan 27, 2022
1 Jan 27, 2022
Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included.
open(LARGE) Storing, versioning, and downloading files from S3 made as easy as using open() in Python. Caching included. Motivation Oftentimes, especi
 2 Jan 30, 2022
2 Jan 30, 2022
This library provides an abstraction to perform Model Versioning using Weight & Biases.
Description This library provides an abstraction to perform Model Versioning using Weight & Biases. Features Version a new trained model Promote a mod
 2 Jan 28, 2022
2 Jan 28, 2022
Aalto-cs-msc-theses - Listing of M.Sc. Theses of the Department of Computer Science at Aalto University
Aalto-CS-MSc-Theses Listing of M.Sc. Theses of the Department of Computer Scienc
 3 Jan 27, 2022
3 Jan 27, 2022
Compute execution plan: A DAG representation of work that you want to get done. Individual nodes of the DAG could be simple python or shell tasks or complex deeply nested parallel branches or embedded DAGs themselves.
Hello from magnus Magnus provides four capabilities for data teams: Compute execution plan: A DAG representation of work that you want to get done. In
 12 Feb 8, 2022
12 Feb 8, 2022

FairLens is an open source Python library for automatically discovering bias and measuring fairness in data
FairLens FairLens is an open source Python library for automatically discovering bias and measuring fairness in data. The package can be used to quick
 69 Dec 15, 2022
69 Dec 15, 2022
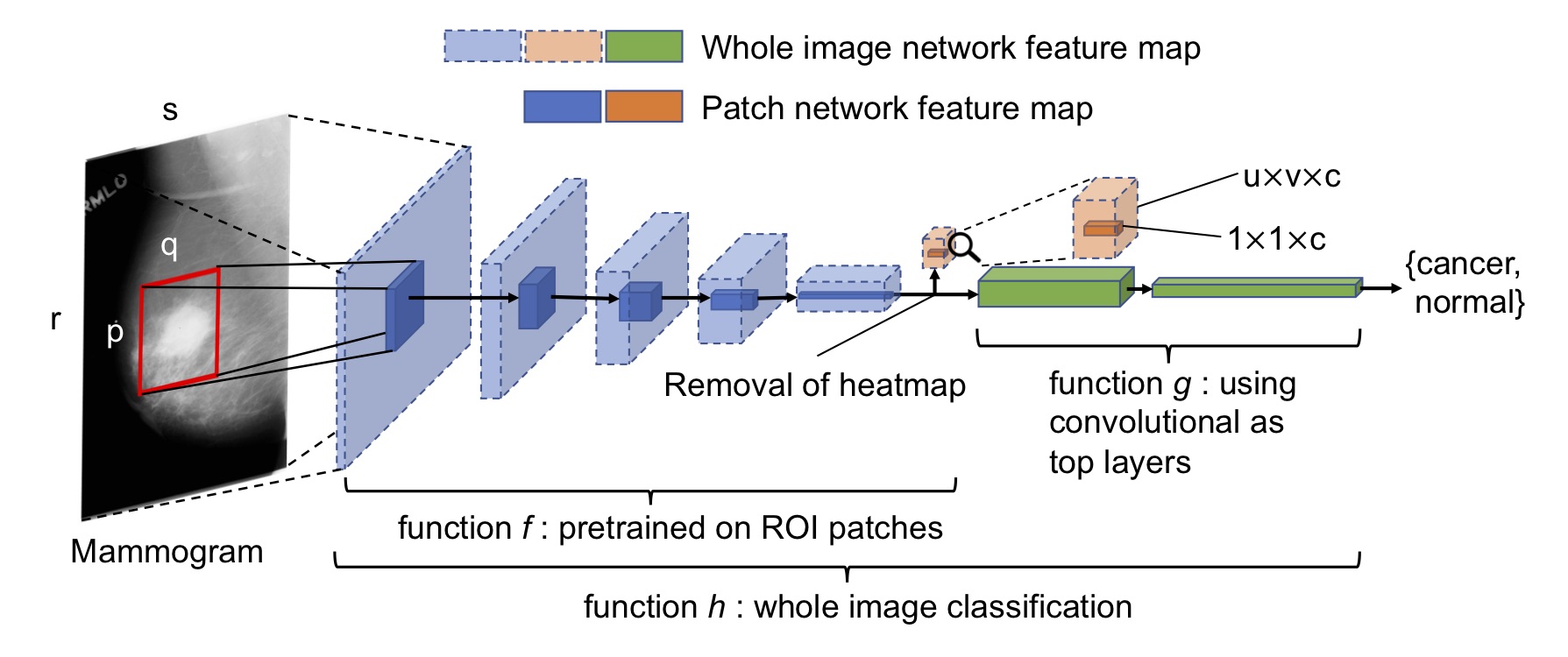
Deep Learning to Improve Breast Cancer Detection on Screening Mammography
Shield: This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. Deep Learning to Improve Breast
 305 Jan 3, 2023
305 Jan 3, 2023
Contains modeling practice materials and homework for the Computational Neuroscience course at Okinawa Institute of Science and Technology
A310 Computational Neuroscience - Okinawa Institute of Science and Technology, 2022 This repository contains modeling practice materials and homework
 1 Jan 24, 2022
1 Jan 24, 2022
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences
Synthetic data need to preserve the statistical properties of real data in terms of their individual behavior and (inter-)dependences. Copula and functional Principle Component Analysis (fPCA) are statistical models that allow these properties to be simulated (Joe 2014). As such, copula generated data have shown potential to improve the generalization of machine learning (ML) emulators (Meyer et al. 2021) or anonymize real-data datasets (Patki et al. 2016).
 32 Dec 20, 2022
32 Dec 20, 2022
An easy-to-use feature store
A feature store is a data storage system for data science and machine-learning. It can store raw data and also transformed features, which can be fed straight into an ML model or training script.
 48 Dec 9, 2022
48 Dec 9, 2022