3574 Repositories
Python text-data Libraries
Predict the Site EUI, given the characteristics of the building and the weather data for the location of the building.
wids_datathon_2022 Description: Contains a data pipeline used to predict energy EUI Goals: Dataset exploration Automating the parameter fitting, gener
 1 Mar 25, 2022
1 Mar 25, 2022
In this project , I play with the YouTube data API and extract trending videos in Nigeria on a particular day
YouTubeTrendingVideosAnalysis In this project , I played with the YouTube data API and extracted trending videos in Nigeria on a particular day. This
 1 Jan 11, 2022
1 Jan 11, 2022

This repository structures data in title, summary, tags, sentiment given a fragment of a conversation
Understand-conversation-AI This repository structures data in title, summary, tags, sentiment given a fragment of a conversation How to install: pip i
 1 Jan 11, 2022
1 Jan 11, 2022
Kinetics-Data-Preprocessing
Kinetics-Data-Preprocessing Kinetics-400 and Kinetics-600 are common video recognition datasets used by popular video understanding projects like Slow
 7 Oct 27, 2022
7 Oct 27, 2022
Python Machine Learning Jupyter Notebooks (ML website)
Python Machine Learning Jupyter Notebooks (ML website) Dr. Tirthajyoti Sarkar, Fremont, California (Please feel free to connect on LinkedIn here) Also
 2.6k Jan 3, 2023
2.6k Jan 3, 2023
Semi-Automated Data Processing
Perform semi automated exploratory data analysis, feature engineering and feature selection on provided dataset by visualizing every possibilities on each step and assisting the user to make a meaningful decision to achieve a low-bias and low-variance model.
 1 Jan 17, 2022
1 Jan 17, 2022
The bidirectional mapping library for Python.
bidict The bidirectional mapping library for Python. Status bidict: has been used for many years by several teams at Google, Venmo, CERN, Bank of Amer
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
Python Library to get fast extensive Dummy Data for testing
Dumda Python Library to get fast extensive Dummy Data for testing https://pypi.org/project/dumda/ Installation pip install dumda Usage: Cities from d
 0 Dec 27, 2021
0 Dec 27, 2021

Displaying plot of death rates from past years in Poland. Data source from these years is in readme
Average-Death-Rate Displaying plot of death rates from past years in Poland The goal collect the data from a CSV file count the ADR (Average Death Rat
 0 Sep 12, 2021
0 Sep 12, 2021

Advanced raster and geometry manipulations
buzzard In a nutshell, the buzzard library provides powerful abstractions to manipulate together images and geometries that come from different kind o
 30 Jun 20, 2022
30 Jun 20, 2022
Download and process GOES-16 and GOES-17 data from NOAA's archive on AWS using Python.
Download and display GOES-East and GOES-West data GOES-East and GOES-West satellite data are made available on Amazon Web Services through NOAA's Big
 88 Dec 16, 2022
88 Dec 16, 2022

Shelf DB is a tiny document database for Python to stores documents or JSON-like data
Shelf DB Introduction Shelf DB is a tiny document database for Python to stores documents or JSON-like data. Get it $ pip install shelfdb shelfquery S
 35 Nov 3, 2022
35 Nov 3, 2022
Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle.
2019-indian-election-eda Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle. This project is a part of the Cou
 5 Oct 10, 2022
5 Oct 10, 2022

DCM is a set of tools that helps you to keep your data in your Django Models consistent.
Django Consistency Model DCM is a set of tools that helps you to keep your data in your Django Models consistent. Motivation You have a lot of legacy
 59 Dec 21, 2022
59 Dec 21, 2022
To design and implement the Identification of Iris Flower species using machine learning using Python and the tool Scikit-Learn.
To design and implement the Identification of Iris Flower species using machine learning using Python and the tool Scikit-Learn.
 1 Jan 11, 2022
1 Jan 11, 2022
A Telegram bot written in python.
telegram_bot This bot is currently a beta project. Features A telegram bot which can: Send current COVID-19 cases/stats of Germany Send current worth
 1 Jan 11, 2022
1 Jan 11, 2022
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
The RAP community of practice includes all analysts and data scientists who are interested in adopting the working practices included in reproducible analytical pipelines (RAP) at NHS Digital.
 50 Dec 22, 2022
50 Dec 22, 2022

Data Science Course at Dept. of Computer Engineering, Chula 2022
2110446 Data Science Course at Chula 2022 Short links for exercises: Week1: Intro to Numpy, Pandas Numpy: https://colab.research.google.com/github/kao
 17 Nov 27, 2022
17 Nov 27, 2022

Udacity - Data Analyst Nanodegree - Project 4 - Wrangle and Analyze Data
WeRateDogs Twitter Data from 2015 to 2017 Udacity - Data Analyst Nanodegree - Project 4 - Wrangle and Analyze Data Table of Contents Introduction Proj
 1 Jan 12, 2022
1 Jan 12, 2022
BSDotPy, A module to get a bombsquad player's account data.
BSDotPy BSDotPy, A module to get a bombsquad player's account data from bombsquad's servers. Badges Provided By: shields.io Acknowledgements Issues Pu
 3 Feb 17, 2022
3 Feb 17, 2022

Using knowledge-informed machine learning on the PRONOSTIA (FEMTO) and IMS bearing data sets. Predict remaining-useful-life (RUL).
Knowledge Informed Machine Learning using a Weibull-based Loss Function Exploring the concept of knowledge-informed machine learning with the use of a
 43 Dec 14, 2022
43 Dec 14, 2022
Multi-Stage Episodic Control for Strategic Exploration in Text Games
XTX: eXploit - Then - eXplore Requirements First clone this repo using git clone https://github.com/princeton-nlp/XTX.git Please create two conda envi
 9 May 24, 2022
9 May 24, 2022
Orange Chicken: Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation
Orange Chicken: Data-driven Model Generalizability in Crosslinguistic Low-resource Morphological Segmentation This repository contains code and data f
 0 Jan 7, 2022
0 Jan 7, 2022

Classification of Long Sequential Data using Circular Dilated Convolutional Neural Networks
Classification of Long Sequential Data using Circular Dilated Convolutional Neural Networks arXiv preprint: https://arxiv.org/abs/2201.02143. Architec
 19 Nov 30, 2022
19 Nov 30, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool by
 13 Jan 11, 2022
13 Jan 11, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022
Source code for the plant extraction workflow introduced in the paper “Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision”
Plant extraction workflow Source code for the plant extraction workflow introduced in the paper "Agricultural Plant Cataloging and Establishment of a
 0 Apr 22, 2022
0 Apr 22, 2022
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data
FEMDA: Robust classification with Flexible Discriminant Analysis in heterogeneous data. Flexible EM-Inspired Discriminant Analysis is a robust supervised classification algorithm that performs well in noisy and contaminated datasets.
 0 Sep 6, 2022
0 Sep 6, 2022
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Convolutional Recurrent Neural Network + CTCLoss | STAR-Net Code for paper "Towards Boosting the Accuracy of Non-Latin Scene Text Recognition" Depende
 7 Aug 7, 2022
7 Aug 7, 2022
Active Transport Analytics Model: A new strategic transport modelling and data visualization framework
{ATAM} Active Transport Analytics Model Active Transport Analytics Model (“ATAM”
 2 Dec 21, 2022
2 Dec 21, 2022
Historic weather - Home Assistant custom component for accessing historic weather data
Historic Weather for Home Assistant (CC) 2022 by Andreas Frisch github@fraxinas.
 1 Jan 10, 2022
1 Jan 10, 2022
In this repo, I will put all the code related to data science using python libraries like Numpy, Pandas, Matplotlib, Seaborn and many more.
Python-for-DS In this repo, I will put all the code related to data science using python libraries like Numpy, Pandas, Matplotlib, Seaborn and many mo
 1 Jan 10, 2022
1 Jan 10, 2022
This repository contains answers of the Shopify Summer 2022 Data Science Intern Challenge.
Data-Science-Intern-Challenge This repository contains answers of the Shopify Summer 2022 Data Science Intern Challenge. Summer 2022 Data Science Inte
 1 Jan 11, 2022
1 Jan 11, 2022
Active Transport Analytics Model (ATAM) is a new strategic transport modelling and data visualization framework for Active Transport as well as emerging micro-mobility modes
{ATAM} Active Transport Analytics Model Active Transport Analytics Model (“ATAM”) is a new strategic transport modelling and data visualization framew
 0 Jan 12, 2022
0 Jan 12, 2022
Validate arbitrary image uploads from incoming data urls while preserving file integrity but removing EXIF and unwanted artifacts and RCE exploit potential
Validate arbitrary base64-encoded image uploads as incoming data urls while preserving image integrity but removing EXIF and unwanted artifacts and mitigating RCE-exploit potential.
 1 Jan 10, 2022
1 Jan 10, 2022
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
 1 Jan 10, 2022
1 Jan 10, 2022
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
 2 Jan 20, 2022
2 Jan 20, 2022
This is an AI that is supposed to say you if your text is formal or not
This is an AI that is supposed to say you if your text is formal or not. It's written in Python 3 and has some german examples (because I'm german yk) in the text.json file. This file contains the text which the AI. The TXT-file isn't important but necessary.
 1 Jan 12, 2022
1 Jan 12, 2022
Deep learning with TensorFlow and earth observation data.
Deep Learning with TensorFlow and EO Data Complete file set for Jupyter Book Autor: Development Seed Date: 04 October 2021 ISBN: (to come) Notebook tu
 20 Nov 16, 2022
20 Nov 16, 2022
Big Data & Cloud Computing for Oceanography
DS2 Class 2022, Big Data & Cloud Computing for Oceanography Home of the 2022 ISblue Big Data & Cloud Computing for Oceanography class (IMT-A, ENSTA, I
 5 Mar 19, 2022
5 Mar 19, 2022
Generating new names based on trends in data using GPT2 (Transformer network)
MLOpsNameGenerator Overall Goal The goal of the project is to develop a model that is capable of creating Pokémon names based on its description, usin
 2 Jan 10, 2022
2 Jan 10, 2022
Official git for "CTAB-GAN: Effective Table Data Synthesizing"
CTAB-GAN This is the official git paper CTAB-GAN: Effective Table Data Synthesizing. The paper is published on Asian Conference on Machine Learning (A
 30 Dec 26, 2022
30 Dec 26, 2022
A Python package that can be used to download post and comment data from Reddit.
Reddit Data Collector Reddit Data Collector is a Python package that allows a user to collect post and comment data from Reddit. It is built on top of
 3 Jul 26, 2022
3 Jul 26, 2022
A practical ML pipeline for data labeling with experiment tracking using DVC.
Auto Label Pipeline A practical ML pipeline for data labeling with experiment tracking using DVC Goals: Demonstrate reproducible ML Use DVC to build a
 4 Mar 8, 2022
4 Mar 8, 2022
Send SMS text messages via email with as many accounts as you want :)
SMS-Spammer Send SMS text messages via email with as many accounts as you want :) Example Set Up Guide! To start log into the gmail account you would
 10 Oct 25, 2022
10 Oct 25, 2022

A vanilla 3D face modeling on pose-invariant and multi-lightning image data
3D-Face-Modeling A vanilla 3D face modeling on pose-invariant and multi-lightning image data Table of Contents Background Install Usage Contributing B
 1 Mar 12, 2022
1 Mar 12, 2022

Text classification on IMDB dataset using Keras and Bi-LSTM network
Text classification on IMDB dataset using Keras and Bi-LSTM Text classification on IMDB dataset using Keras and Bi-LSTM network. Usage python3 main.py
 2 Sep 27, 2022
2 Sep 27, 2022
🎁 3,000,000+ Unsplash images made available for research and machine learning
The Unsplash Dataset The Unsplash Dataset is made up of over 250,000+ contributing global photographers and data sourced from hundreds of millions of
 2k Jan 3, 2023
2k Jan 3, 2023
A collection of machine learning examples and tutorials.
machine_learning_examples A collection of machine learning examples and tutorials.
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
A text file containing 479k English words for all your dictionary/word-based projects e.g: auto-completion / autosuggestion
List Of English Words A text file containing over 466k English words. While searching for a list of english words (for an auto-complete tutorial) I fo
 8.5k Jan 3, 2023
8.5k Jan 3, 2023

Always know what to expect from your data.
Great Expectations Always know what to expect from your data. Introduction Great Expectations helps data teams eliminate pipeline debt, through data t
 7.8k Jan 5, 2023
7.8k Jan 5, 2023
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022

macOS development environment setup: Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process.
dev-setup Motivation Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process. dev-setup aims to simplify the process w
 5.9k Jan 2, 2023
5.9k Jan 2, 2023
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
Code and data accompanying Natural Language Processing with PyTorch
Natural Language Processing with PyTorch Build Intelligent Language Applications Using Deep Learning By Delip Rao and Brian McMahan Welcome. This is a
 1.8k Jan 1, 2023
1.8k Jan 1, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
100 data puzzles for pandas, ranging from short and simple to super tricky (60% complete)
100 pandas puzzles Puzzles notebook Solutions notebook Inspired by 100 Numpy exerises, here are 100* short puzzles for testing your knowledge of panda
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
FMA: A Dataset For Music Analysis
FMA: A Dataset For Music Analysis Michaël Defferrard, Kirell Benzi, Pierre Vandergheynst, Xavier Bresson. International Society for Music Information
 1.8k Dec 29, 2022
1.8k Dec 29, 2022

Python for downloading model data (HRRR, RAP, GFS, NBM, etc.) from NOMADS, NOAA's Big Data Program partners (Amazon, Google, Microsoft), and the University of Utah Pando Archive System.
Python for downloading model data (HRRR, RAP, GFS, NBM, etc.) from NOMADS, NOAA's Big Data Program partners (Amazon, Google, Microsoft), and the University of Utah Pando Archive System.
194 Jan 2, 2023
Predictive Modeling & Analytics on Home Equity Line of Credit
Predictive Modeling & Analytics on Home Equity Line of Credit Data (Python) HMEQ Data Set In this assignment we will use Python to examine a data set
 1 Jan 9, 2022
1 Jan 9, 2022
Implements a fake news detection program using classifiers.
Fake news detection Implements a fake news detection program using classifiers for Data Mining course at UoA. Description The project is the categoriz
 1 Jan 9, 2022
1 Jan 9, 2022
A collection of data structures and algorithms I'm writing while learning
Data Structures and Algorithms: This is a collection of data structures and algorithms that I write while learning the subject Stack: stack.py A stack
 1 Jan 9, 2022
1 Jan 9, 2022

Repository for the paper : Meta-FDMixup: Cross-Domain Few-Shot Learning Guided byLabeled Target Data
1 Meta-FDMIxup Repository for the paper : Meta-FDMixup: Cross-Domain Few-Shot Learning Guided byLabeled Target Data. (ACM MM 2021) paper News! the rep
 44 Nov 18, 2022
44 Nov 18, 2022

Code for "Multi-Time Attention Networks for Irregularly Sampled Time Series", ICLR 2021.
Multi-Time Attention Networks (mTANs) This repository contains the PyTorch implementation for the paper Multi-Time Attention Networks for Irregularly
 68 Dec 17, 2022
68 Dec 17, 2022

Moji sends text and fun facts from different APIs wit da use of a notification deamon
Moji sends text and fun facts from different APIs wit da use of a notification deamon. Can be runned via dmenu or rofi.
 2 Jan 12, 2022
2 Jan 12, 2022

Text editor on python to convert english text to malayalam(Romanization/Transiteration).
Manglish Text Editor This is a simple transiteration (romanization ) program which is used to convert manglish to malayalam (converts njaan to ഞാൻ ).
 1 May 11, 2022
1 May 11, 2022

Script that allows to download data with satellite's orbit height and create CSV with their change in time.
Satellite orbit height ◾ Requirements Python = 3.8 Packages listen in reuirements.txt (run pip install -r requirements.txt) Account on Space Track ◾
 2 Jan 17, 2022
2 Jan 17, 2022
A tool for RaceRoom Racing Experience which shows you launch data
R3E Launch Tool A tool for RaceRoom Racing Experience which shows you launch data. Usage Run the tool, change the Stop Speed to whatever you want, and
 2 Feb 1, 2022
2 Feb 1, 2022

This is a web scraper, using Python framework Scrapy, built to extract data from the Deals of the Day section on Mercado Livre website.
Deals of the Day This is a web scraper, using the Python framework Scrapy, built to extract data such as price and product name from the Deals of the
 1 Jan 12, 2022
1 Jan 12, 2022
A Simple Key-Value Data-store written in Python
mercury-db This is a File Based Key-Value Datastore that supports basic CRUD (Create, Read, Update, Delete) operations developed using Python. The dat
 1 Jan 9, 2022
1 Jan 9, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
To attract customers, the hotel chain has added to its website the ability to book a room without prepayment
To attract customers, the hotel chain has added to its website the ability to book a room without prepayment. We need to predict whether the customer is going to reject the booking or not. Since in case of refusal, the hotel incurs losses.
 0 Aug 4, 2022
0 Aug 4, 2022
LSTM built using Keras Python package to predict time series steps and sequences. Includes sin wave and stock market data
LSTM Neural Network for Time Series Prediction LSTM built using the Keras Python package to predict time series steps and sequences. Includes sine wav
 4.1k Jan 2, 2023
4.1k Jan 2, 2023

The Wearables Development Toolkit - a development environment for activity recognition applications with sensor signals
Wearables Development Toolkit (WDK) The Wearables Development Toolkit (WDK) is a framework and set of tools to facilitate the iterative development of
 114 Nov 27, 2022
114 Nov 27, 2022

DeltaPy - Tabular Data Augmentation (by @firmai)
DeltaPy — Tabular Data Augmentation & Feature Engineering Finance Quant Machine Learning ML-Quant.com - Automated Research Repository Introduction T
 470 Dec 28, 2022
470 Dec 28, 2022
A Python package for time series augmentation
tsaug tsaug is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to conn
 278 Jan 1, 2023
278 Jan 1, 2023
Supervised forecasting of sequential data in Python.
Supervised forecasting of sequential data in Python. Intro Supervised forecasting is the machine learning task of making predictions for sequential da
 54 Nov 15, 2022
54 Nov 15, 2022
Algorithms for outlier, adversarial and drift detection
Alibi Detect is an open source Python library focused on outlier, adversarial and drift detection. The package aims to cover both online and offline d
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
An API-first distributed deployment system of deep learning models using timeseries data to analyze and predict systems behaviour
Gordo Building thousands of models with timeseries data to monitor systems. Table of content About Examples Install Uninstall Developer manual How to
 26 Dec 27, 2022
26 Dec 27, 2022
Survival analysis in Python
What is survival analysis and why should I learn it? Survival analysis was originally developed and applied heavily by the actuarial and medical commu
 2k Jan 8, 2023
2k Jan 8, 2023
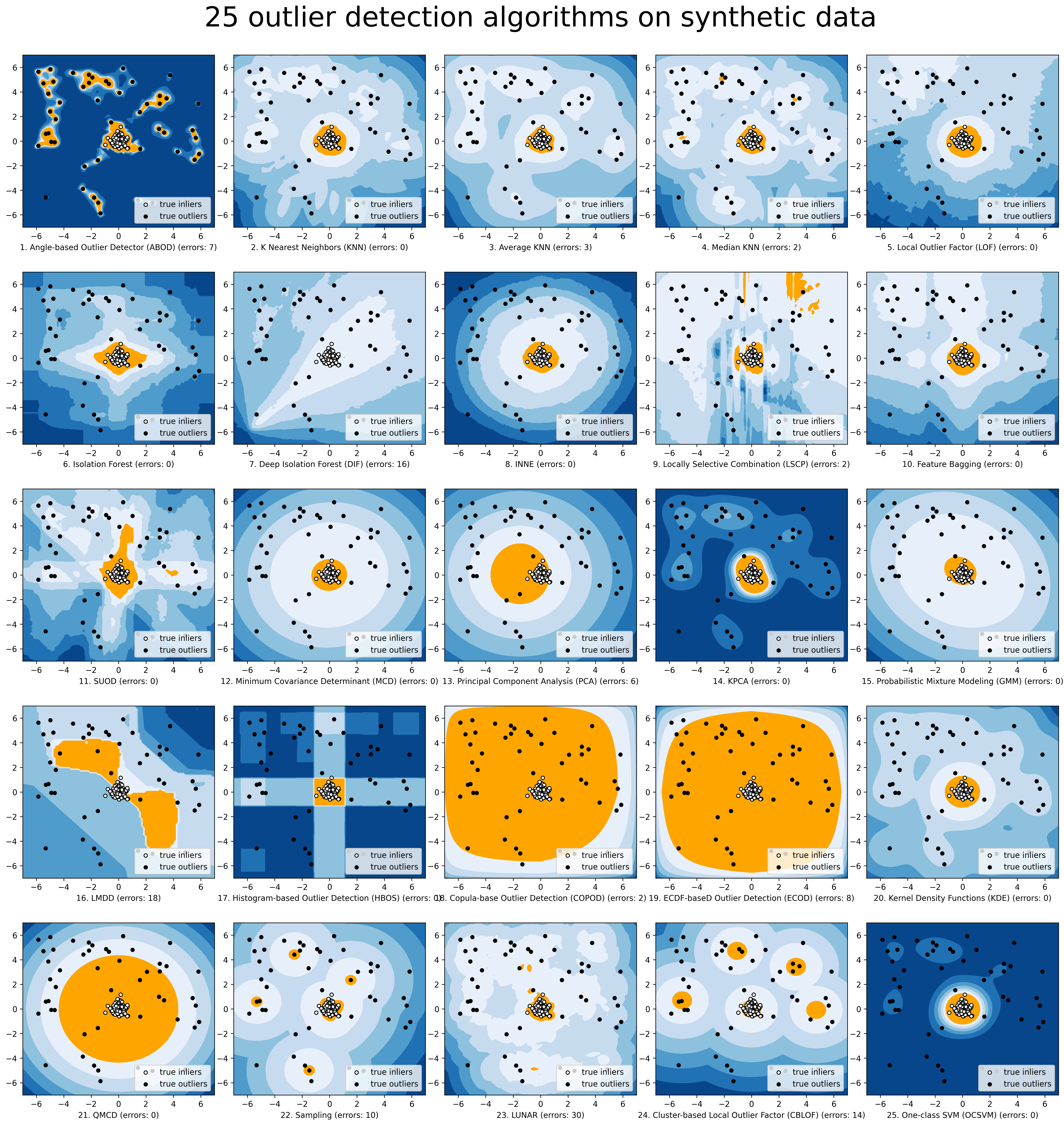
(JMLR' 19) A Python Toolbox for Scalable Outlier Detection (Anomaly Detection)
Python Outlier Detection (PyOD) Deployment & Documentation & Stats & License PyOD is a comprehensive and scalable Python toolkit for detecting outlyin
 6.6k Jan 5, 2023
6.6k Jan 5, 2023
Forecast dynamically at scale with this unique package. pip install scalecast
🌄 Scalecast: Dynamic Forecasting at Scale About This package uses a scaleable forecasting approach in Python with common scikit-learn and statsmodels
 158 Jan 3, 2023
158 Jan 3, 2023
Hierarchical Time Series Forecasting with a familiar API
scikit-hts Hierarchical Time Series with a familiar API. This is the result from not having found any good implementations of HTS on-line, and my work
 204 Dec 17, 2022
204 Dec 17, 2022
An open source python library for automated feature engineering
"One of the holy grails of machine learning is to automate more and more of the feature engineering process." ― Pedro Domingos, A Few Useful Things to
 6.4k Jan 3, 2023
6.4k Jan 3, 2023
An intuitive library to extract features from time series
Time Series Feature Extraction Library Intuitive time series feature extraction This repository hosts the TSFEL - Time Series Feature Extraction Libra
 589 Jan 4, 2023
589 Jan 4, 2023
The Turing Change Point Detection Benchmark: An Extensive Benchmark Evaluation of Change Point Detection Algorithms on real-world data
Turing Change Point Detection Benchmark Welcome to the repository for the Turing Change Point Detection Benchmark, a benchmark evaluation of change po
85 Dec 28, 2022
Python binding for Khiva library.
Khiva-Python Build Documentation Build Linux and Mac OS Build Windows Code Coverage README This is the Khiva Python binding, it allows the usage of Kh
 46 Oct 16, 2022
46 Oct 16, 2022
Timeseries analysis for neuroscience data
=================================================== Nitime: timeseries analysis for neuroscience data ===============================================
 212 Dec 9, 2022
212 Dec 9, 2022
Python package for downloading ECMWF reanalysis data and converting it into a time series format.
ecmwf_models Readers and converters for data from the ECMWF reanalysis models. Written in Python. Works great in combination with pytesmo. Citation If
 31 Dec 26, 2022
31 Dec 26, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023

A way of looking at COVID-19 data that I haven't seen before.
Visualizing Omicron: COVID-19 Deaths vs. Cases Click here for other countries. Data is from Our World in Data/Johns Hopkins University. About this pro
 1 Jan 10, 2022
1 Jan 10, 2022
Analyzed the data of VISA applicants to build a predictive model to facilitate the process of VISA approvals.
Analyzed the data of Visa applicants, built a predictive model to facilitate the process of visa approvals, and based on important factors that significantly influence the Visa status recommended a suitable profile for the applicants for whom the visa should be certified or denied.
 1 Jan 8, 2022
1 Jan 8, 2022
Medical appointments No-Show classifier
Medical Appointments No-shows Why do 20% of patients miss their scheduled appointments? A person makes a doctor appointment, receives all the instruct
 4 Apr 20, 2022
4 Apr 20, 2022
Arquivos do curso online sobre a estatística voltada para ciência de dados e aprendizado de máquina.
Estatistica para Ciência de Dados e Machine Learning Arquivos do curso online sobre a estatística voltada para ciência de dados e aprendizado de máqui
 1 Jan 10, 2022
1 Jan 10, 2022
Prometheus Exporter for data scraped from datenplattform.darmstadt.de
darmstadt-opendata-exporter Scrapes data from https://datenplattform.darmstadt.de and presents it in the Prometheus Exposition format. Pull requests w
 2 Apr 12, 2022
2 Apr 12, 2022
Deepchecks is a Python package for comprehensively validating your machine learning models and data with minimal effort
Deepchecks is a Python package for comprehensively validating your machine learning models and data with minimal effort
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023
PyTorch EO aims to make Deep Learning for Earth Observation data easy and accessible to real-world cases and research alike.
Pytorch EO Deep Learning for Earth Observation applications and research. 🚧 This project is in early development, so bugs and breaking changes are ex
 28 Aug 25, 2022
28 Aug 25, 2022

Full-Stack application that visualizes amusement park safety.
Amusement Park Ride Safety Analysis Project Proposal We have chosen to look into amusement park data to explore ride safety relationships visually, in
 0 Jul 11, 2021
0 Jul 11, 2021

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022