1774 Repositories
Python text-summarization-dataset Libraries
a python package that lets you add custom colors and text formatting to your scripts in a very easy way!
colormate Python script text formatting package What is colormate? colormate is a python library that lets you add text formatting to your scripts, it
 2 Dec 14, 2022
2 Dec 14, 2022
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
 39 Oct 5, 2021
39 Oct 5, 2021
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
Write maintainable, production-ready pipelines using Jupyter or your favorite text editor. Develop locally, deploy to the cloud. ☁️
 2.9k Jan 6, 2023
2.9k Jan 6, 2023

TensorFlow implementation of "Variational Inference with Normalizing Flows"
[TensorFlow 2] Variational Inference with Normalizing Flows TensorFlow implementation of "Variational Inference with Normalizing Flows" [1] Concept Co
 7 Jun 8, 2022
7 Jun 8, 2022
Script to generate VAD dataset used in Asteroid recipe
About the dataset LibriVAD is an open source dataset for voice activity detection in noisy environments. It is derived from LibriSpeech signals (clean
 11 Sep 15, 2022
11 Sep 15, 2022

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
68 Jul 18, 2022
Lightweight Markdown dialect for Python desktop apps
Litemark is a lightweight Markdown dialect originally created to be the markup language for the Codegame Platform project. When you run litemark from the command line interface without any arguments, the Litemark Viewer opens and displays the rendered demo.
 10 Apr 23, 2022
10 Apr 23, 2022

Code repo for EMNLP21 paper "Zero-Shot Information Extraction as a Unified Text-to-Triple Translation"
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation Source code repo for paper Zero-Shot Information Extraction as a Unified Text
 88 Dec 31, 2022
88 Dec 31, 2022
Simple script to ban bots at Twitch chats using a text file as a source.
AUTOBAN 🇺🇸 English version Simple script to ban bots at Twitch chats using a text file as a source. How to use Windows Go to releases for further in
 5 Feb 6, 2022
5 Feb 6, 2022

A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones.
Imbalanced Dataset Sampler Introduction In many machine learning applications, we often come across datasets where some types of data may be seen more
 2k Jan 8, 2023
2k Jan 8, 2023

A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
 309 Dec 16, 2022
309 Dec 16, 2022
A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc.
PyTorch Examples WARNING: if you fork this repo, github actions will run daily on it. To disable this, go to /examples/settings/actions and Disable Ac
 19.4k Jan 1, 2023
19.4k Jan 1, 2023

Quickly and easily create / train a custom DeepDream model
Dream-Creator This project aims to simplify the process of creating a custom DeepDream model by using pretrained GoogleNet models and custom image dat
 56 Jan 3, 2023
56 Jan 3, 2023
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
 237 Jan 2, 2023
237 Jan 2, 2023
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
Flexitext is a Python library that makes it easier to draw text with multiple styles in Matplotlib
Flexitext is a Python library that makes it easier to draw text with multiple styles in Matplotlib
 93 Dec 28, 2022
93 Dec 28, 2022

A pytorch implementation of the ACL2019 paper "Simple and Effective Text Matching with Richer Alignment Features".
RE2 This is a pytorch implementation of the ACL 2019 paper "Simple and Effective Text Matching with Richer Alignment Features". The original Tensorflo
 287 Dec 21, 2022
287 Dec 21, 2022
Simple Text-Generator with OpenAI gpt-2 Pytorch Implementation
GPT2-Pytorch with Text-Generator Better Language Models and Their Implications Our model, called GPT-2 (a successor to GPT), was trained simply to pre
 775 Jan 8, 2023
775 Jan 8, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
 249 Dec 22, 2022
249 Dec 22, 2022
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
 62 Dec 20, 2022
62 Dec 20, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Labelling platform for text using distant supervision
With DataQA, you can label unstructured text documents using rule-based distant supervision.
 245 Aug 5, 2022
245 Aug 5, 2022
text-to-speach bot - You really do NOT have time for read a newsletter? Now you can listen to it
NewsletterReader You really do NOT have time for read a newsletter? Now you can listen to it The Newsletter of Filipe Deschamps is a great place to re
 8 Sep 18, 2021
8 Sep 18, 2021
In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset.
Med-VQA In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset. Two of these are made on top of Facebook AI Reasearch's Multi-Mo
 8 Apr 14, 2022
8 Apr 14, 2022

Just playing with getting CLIP Guided Diffusion running locally, rather than having to use colab.
CLIP-Guided-Diffusion Just playing with getting CLIP Guided Diffusion running locally, rather than having to use colab. Original colab notebooks by Ka
 336 Dec 9, 2022
336 Dec 9, 2022
Simple embedding based text classifier inspired by fastText, implemented in tensorflow
FastText in Tensorflow This project is based on the ideas in Facebook's FastText but implemented in Tensorflow. However, it is not an exact replica of
 306 Dec 2, 2022
306 Dec 2, 2022
Library for fast text representation and classification.
fastText fastText is a library for efficient learning of word representations and sentence classification. Table of contents Resources Models Suppleme
 24.1k Jan 1, 2023
24.1k Jan 1, 2023

A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing.
AnimeGAN A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing. Randomly Generated Images The images are
 1.2k Jan 3, 2023
1.2k Jan 3, 2023

Pixel-wise segmentation on VOC2012 dataset using pytorch.
PiWiSe Pixel-wise segmentation on the VOC2012 dataset using pytorch. FCN SegNet PSPNet UNet RefineNet For a more complete implementation of segmentati
 378 Dec 30, 2022
378 Dec 30, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
 15.2k Jan 1, 2023
15.2k Jan 1, 2023
A production-ready pipeline for text mining and subject indexing
A production-ready pipeline for text mining and subject indexing
 12 Nov 6, 2022
12 Nov 6, 2022
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
 22 Oct 21, 2022
22 Oct 21, 2022

A free Python source code editor and Notepad replacement for Windows
Website Download Features Toolbar Wide array of view options Syntax highlighting support for Python Usable accelerator keys for each function (Ctrl+N,
 7 Feb 16, 2022
7 Feb 16, 2022
This repo in the implementation of EMNLP'21 paper "SPARQLing Database Queries from Intermediate Question Decompositions" by Irina Saparina, Anton Osokin
SPARQLing Database Queries from Intermediate Question Decompositions This repo is the implementation of the following paper: SPARQLing Database Querie
 20 Dec 19, 2022
20 Dec 19, 2022

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 50 Dec 21, 2022
50 Dec 21, 2022
Does Pretraining for Summarization Reuqire Knowledge Transfer?
Pretraining summarization models using a corpus of nonsense
 12 Dec 19, 2022
12 Dec 19, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
py-trans is a Free Python library for translate text into different languages.
Free Python library to translate text into different languages.
 13 Aug 27, 2022
13 Aug 27, 2022
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
AnnIE - Annotation Platform, tool for open information extraction annotations using text files.
 29 Dec 20, 2022
29 Dec 20, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
 19 Oct 28, 2022
19 Oct 28, 2022
`.](https://user-images.githubusercontent.com/4941909/132251464-0f6c48b2-f6ca-4ef7-9c76-39a78fbdd67c.png)
A Sublime Text plugin that displays inline images for single-line comments formatted like `// `.
Inline Images Sometimes ASCII art is not enough. Sometimes an image says more than a thousand words. This Sublime Text plugin can display images inlin
 8 Jul 1, 2022
8 Jul 1, 2022
A daily updated JSON dataset of all the Open House London venues, events, and metadata
Open House London listings data All of it. Automatically scraped hourly with updates committed to git, autogenerated per-day CSV's, and autogenerated
 4 Jan 1, 2022
4 Jan 1, 2022
A set of tools for converting a darknet dataset to COCO format working with YOLOX
darknet格式数据→COCO darknet训练数据目录结构(详情参见dataset/darknet): darknet ├── class.names ├── gen_config.data ├── gen_train.txt ├── gen_valid.txt └── images
 148 Jan 3, 2023
148 Jan 3, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them"
ood-text-emnlp Code for EMNLP'21 paper "Types of Out-of-Distribution Texts and How to Detect Them" Files fine_tune.py is used to finetune the GPT-2 mo
19 Oct 28, 2022
A multilingual version of MS MARCO passage ranking dataset
mMARCO A multilingual version of MS MARCO passage ranking dataset This repository presents a neural machine translation-based method for translating t
 75 Dec 27, 2022
75 Dec 27, 2022
Related resources for our EMNLP 2021 paper Plan-then-Generate: Controlled Data-to-Text Generation via Planning
Plan-then-Generate: Controlled Data-to-Text Generation via Planning Authors: Yixuan Su, David Vandyke, Sihui Wang, Yimai Fang, and Nigel Collier Code
 61 Jan 3, 2023
61 Jan 3, 2023

Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt
Feed forward VQGAN-CLIP model, where the goal is to eliminate the need for optimizing the latent space of VQGAN for each input prompt. This is done by
 135 Dec 30, 2022
135 Dec 30, 2022
Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet.
Sonnet finder Finds snippets in iambic pentameter in English-language text and tries to combine them to a rhyming sonnet. Usage This is a Python scrip
 11 Sep 25, 2022
11 Sep 25, 2022
Telegram bot to extract text from image
OCR Bot @Image_To_Text_OCR_Bot A star ⭐ from you means a lot to us! Telegram bot to extract text from image Usage Deploy to Heroku Tap on above button
 25 Nov 24, 2022
25 Nov 24, 2022

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
The FinQA dataset from paper: FinQA: A Dataset of Numerical Reasoning over Financial Data
Data and code for EMNLP 2021 paper "FinQA: A Dataset of Numerical Reasoning over Financial Data"
 114 Dec 29, 2022
114 Dec 29, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
 23 Nov 30, 2022
23 Nov 30, 2022
Tutorial to pretrain & fine-tune a 🤗 Flax T5 model on a TPUv3-8 with GCP
Pretrain and Fine-tune a T5 model with Flax on GCP This tutorial details how pretrain and fine-tune a FlaxT5 model from HuggingFace using a TPU VM ava
 41 Nov 18, 2022
41 Nov 18, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022
Python lib for Simple PDF text extraction
Python lib for Simple PDF text extraction
 651 Jan 1, 2023
651 Jan 1, 2023

This is the code for the EMNLP 2021 paper AEDA: An Easier Data Augmentation Technique for Text Classification
The baseline code is for EDA: Easy Data Augmentation techniques for boosting performance on text classification tasks
 81 Dec 9, 2022
81 Dec 9, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
✨Rubrix is a production-ready Python framework for exploring, annotating, and managing data in NLP projects.
✨A Python framework to explore, label, and monitor data for NLP projects
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that data.
CLabel is a terminal-based cluster labeling tool that allows you to explore text data interactively and label clusters based on reviewing that
 29 Aug 9, 2022
29 Aug 9, 2022

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022

Python 3 patcher for Sublime Text v4107-4114 Windows x64
sublime-text-4-patcher Python 3 patcher for Sublime Text v4107-4114 Windows x64 Credits for signatures and patching logic goes to https://github.com/l
 187 Dec 27, 2022
187 Dec 27, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
A bot can be used to broadcast your messages ( Text & Media ) to the Subscribers
Broadcast Bot A Telegram bot to send messages and medias to the subscribers directly through bot. Authorized users of the bot can send messages (Texts
 8 Oct 21, 2022
8 Oct 21, 2022
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
Mail classification with tensorflow and MS Exchange Server (ham or spam).
Mail classification with tensorflow and MS Exchange Server (ham or spam).
 1 Sep 11, 2021
1 Sep 11, 2021
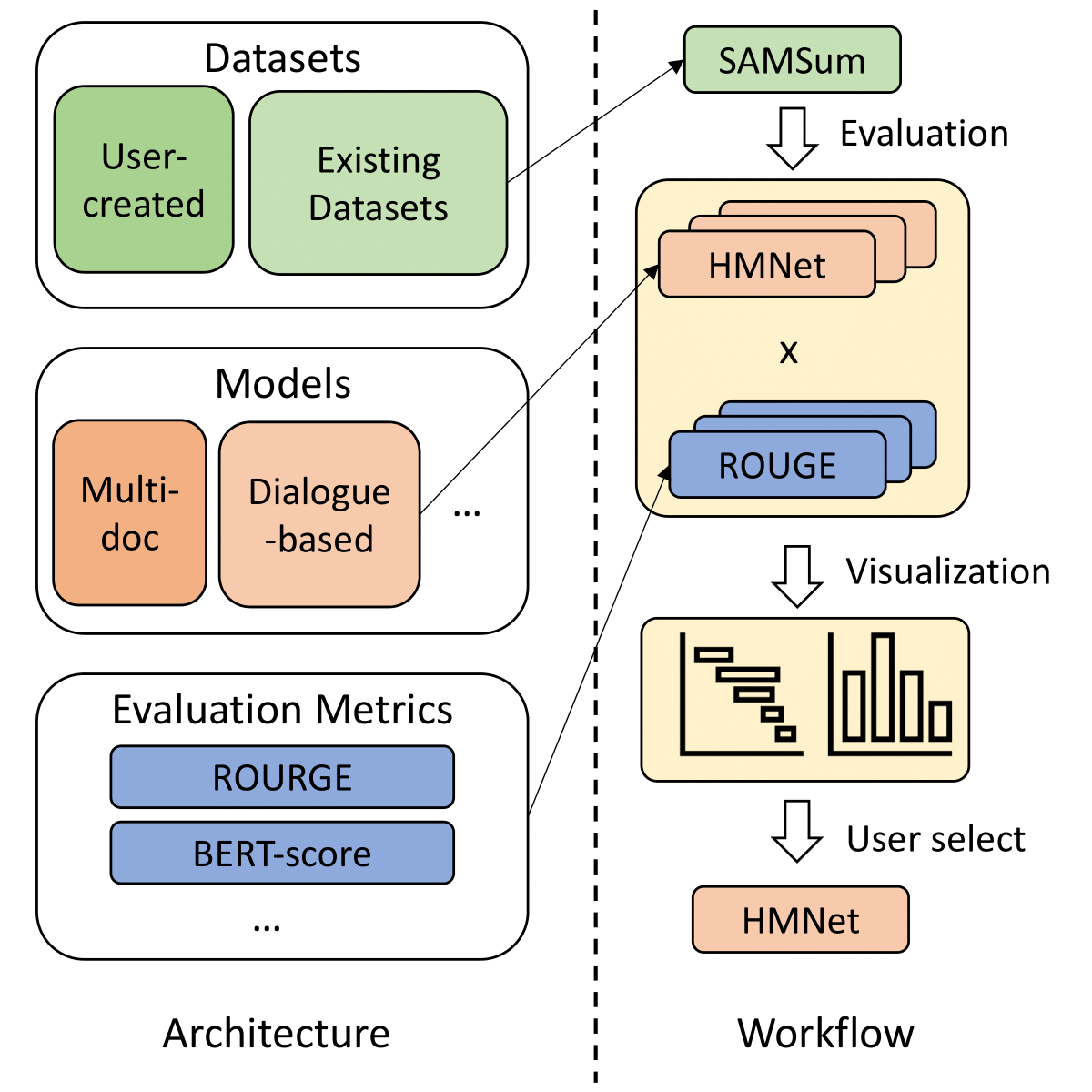
SummerTime - Text Summarization Toolkit for Non-experts
A library to help users choose appropriate summarization tools based on their specific tasks or needs. Includes models, evaluation metrics, and datasets.
 213 Jan 4, 2023
213 Jan 4, 2023

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection (ICCV 2021)
Preparation Please see dataset/README.md to get more details about our datasets-VIL100 Please see INSTALL.md to install environment and evaluation too
 82 Dec 15, 2022
82 Dec 15, 2022

Official implementation of particle-based models (GNS and DPI-Net) on the Physion dataset.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines [paper] Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiao-Y
 18 Dec 19, 2022
18 Dec 19, 2022
EMNLP 2021 Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections Ruiqi Zhong, Kristy Lee*, Zheng Zhang*, Dan Klein EMN
 42 Nov 3, 2022
42 Nov 3, 2022

An original implementation of "Noisy Channel Language Model Prompting for Few-Shot Text Classification"
Channel LM Prompting (and beyond) This includes an original implementation of Sewon Min, Mike Lewis, Hannaneh Hajishirzi, Luke Zettlemoyer. "Noisy Cha
 92 Jan 7, 2023
92 Jan 7, 2023
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021

LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision Project | Arxiv | Abstract It is very challenging for various visual tasks such as image
 377 Jan 7, 2023
377 Jan 7, 2023

NUANCED is a user-centric conversational recommendation dataset that contains 5.1k annotated dialogues and 26k high-quality user turns.
NUANCED: Natural Utterance Annotation for Nuanced Conversation with Estimated Distributions Overview NUANCED is a user-centric conversational recommen
18 Dec 28, 2021
⚖️ A Statutory Article Retrieval Dataset in French.
A Statutory Article Retrieval Dataset in French This repository contains the Belgian Statutory Article Retrieval Dataset (BSARD), as well as the code
 19 Nov 17, 2022
19 Nov 17, 2022

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022