1774 Repositories
Python text-summarization-dataset Libraries
A python library for extracting text from PDFs without losing the formatting of the PDF content.
Multilingual PDF to Text Install Package from Pypi Install it using pip. pip install multilingual-pdf2text The library uses Tesseract which can be ins
 49 Nov 7, 2022
49 Nov 7, 2022

Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
Project page for the paper Semi-Supervised Raw-to-Raw Mapping 2021.
 22 Nov 8, 2022
22 Nov 8, 2022

Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
Just playing with getting VQGAN+CLIP running locally, rather than having to use colab.
 2.3k Jan 4, 2023
2.3k Jan 4, 2023

Command Line Text-To-Speech using Google TTS
cli-tts Thanks to gTTS by @pndurette! This is an interactive command line text-to-speech tool using Google TTS. Just type text and the voice will be p
 3 Nov 11, 2022
3 Nov 11, 2022

Check the basic quality of any dataset
Data Quality Checker in Python Check the basic quality of any dataset. Sneak Peek Read full tutorial at Medium. Explore the app Requirements python 3.
 8 Feb 23, 2022
8 Feb 23, 2022
Fixes 500+ mislabeled MURA images
In this repository, new csv files are provided that fixes 500+ mislabeled MURA x-rays for all categories. The mislabeled x-rays mainly had hardware in them. This project only fixes the false negatives for now.
 4 May 18, 2022
4 May 18, 2022

SDL: Synthetic Document Layout dataset
SDL is the project that synthesizes document images. It facilitates multiple-level labeling on document images and can generate in multiple languages.
 0 Oct 7, 2021
0 Oct 7, 2021
A toolbox of scene text detection and recognition
FudanOCR This toolbox contains the implementations of the following papers: Scene Text Telescope: Text-Focused Scene Image Super-Resolution [Chen et a
 170 Dec 26, 2022
170 Dec 26, 2022
Large dataset storage format for Pytorch
H5Record Large dataset ( 100G, = 1T) storage format for Pytorch (wip) Support python 3 pip install h5record Why? Writing large dataset is still a
 43 Oct 22, 2022
43 Oct 22, 2022
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022

BARTScore: Evaluating Generated Text as Text Generation
This is the Repo for the paper: BARTScore: Evaluating Generated Text as Text Generation Updates 2021.06.28 Release online evaluation Demo 2021.06.25 R
 196 Dec 17, 2022
196 Dec 17, 2022
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Fre-GAN Vocoder Fre-GAN: Adversarial Frequency-consistent Audio Synthesis Training: python train.py --config config.json Citation: @misc{kim2021frega
 93 Dec 17, 2022
93 Dec 17, 2022

PyTorch Implementation of NCSOFT's FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
FastPitchFormant - PyTorch Implementation PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis. Qu
 63 Jan 2, 2023
63 Jan 2, 2023
Source code for models described in the paper "AudioCLIP: Extending CLIP to Image, Text and Audio" (https://arxiv.org/abs/2106.13043)
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
 458 Jan 2, 2023
458 Jan 2, 2023

This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transformations at CVPR'21. According to some product reasons, we are not planning to release the training/testing codes and models. However, we will release the dataset and the scripts to prepare the dataset.
TransFill-Reference-Inpainting This is the official repo for TransFill: Reference-guided Image Inpainting by Merging Multiple Color and Spatial Transf
 80 Dec 8, 2022
80 Dec 8, 2022

Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback
CoSMo.pytorch Official Implementation of CoSMo: Content-Style Modulation for Image Retrieval with Text Feedback, Seungmin Lee*, Dongwan Kim*, Bohyung
 54 Dec 8, 2022
54 Dec 8, 2022
![[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach](https://github.com/SHI-Labs/Rethinking-Text-Segmentation/raw/main/.figure/image_only.jpg)
[CVPR 2021] Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach This is the repo to host the dataset TextSeg and code for TexRNe
 174 Dec 19, 2022
174 Dec 19, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022

A large dataset of 100k Google Satellite and matching Map images, resembling pix2pix's Google Maps dataset.
Larger Google Sat2Map dataset This dataset extends the aerial ⟷ Maps dataset used in pix2pix (Isola et al., CVPR17). The provide script download_sat2m
 34 Dec 28, 2022
34 Dec 28, 2022
BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset.
BloodCheck BloodCheck enables Red and Blue Teams to manage multiple Neo4j databases and run Cypher queries against a BloodHound dataset. Installation
 16 Nov 5, 2021
16 Nov 5, 2021

PyTorch implementation of ARM-Net: Adaptive Relation Modeling Network for Structured Data.
A ready-to-use framework of latest models for structured (tabular) data learning with PyTorch. Applications include recommendation, CRT prediction, healthcare analytics, and etc.
 48 Nov 30, 2022
48 Nov 30, 2022
This is a template for the Non-autoregressive Deep Learning-Based TTS model (in PyTorch).
Non-autoregressive Deep Learning-Based TTS Template This is a template for the Non-autoregressive TTS model. It contains Data Preprocessing Pipeline D
13 Dec 5, 2022

Attention mechanism with MNIST dataset
[TensorFlow] Attention mechanism with MNIST dataset Usage $ python run.py Result Training Loss graph. Test Each figure shows input digit, attention ma
 12 Jun 10, 2022
12 Jun 10, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022

Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
SEDE SEDE (Stack Exchange Data Explorer) is new dataset for Text-to-SQL tasks with more than 12,000 SQL queries and their natural language description
 83 Nov 11, 2022
83 Nov 11, 2022
Cross-Modal Contrastive Learning for Text-to-Image Generation
Cross-Modal Contrastive Learning for Text-to-Image Generation This repository hosts the open source JAX implementation of XMC-GAN. Setup instructions
 94 Nov 12, 2022
94 Nov 12, 2022

Blender Python - Node-based multi-line text and image flowchart
MindMapper v0.8 Node-based text and image flowchart for Blender Mindmap with shortcuts visible: Mindmap with shortcuts hidden: Notes This was requeste
 58 Oct 8, 2022
58 Oct 8, 2022
AudioCLIP Extending CLIP to Image, Text and Audio
AudioCLIP Extending CLIP to Image, Text and Audio This repository contains implementation of the models described in the paper arXiv:2106.13043. This
458 Jan 2, 2023

Code for SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations
The Second Situated Interactive MultiModal Conversations (SIMMC 2.0) Challenge 2021 Welcome to the Second Situated Interactive Multimodal Conversation
 81 Nov 22, 2022
81 Nov 22, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
Sublime Text 2/3 style auto completion for ST4
Hippie Autocompletion Sublime Text 2/3 style auto completion for ST4: cycle through words, do not show popup. Simply hit Tab to insert completion, hit
 20 May 19, 2022
20 May 19, 2022

Official Pytorch Implementation of: "Semantic Diversity Learning for Zero-Shot Multi-label Classification"(2021) paper
Semantic Diversity Learning for Zero-Shot Multi-label Classification Paper Official PyTorch Implementation Avi Ben-Cohen, Nadav Zamir, Emanuel Ben Bar
 28 Aug 29, 2022
28 Aug 29, 2022
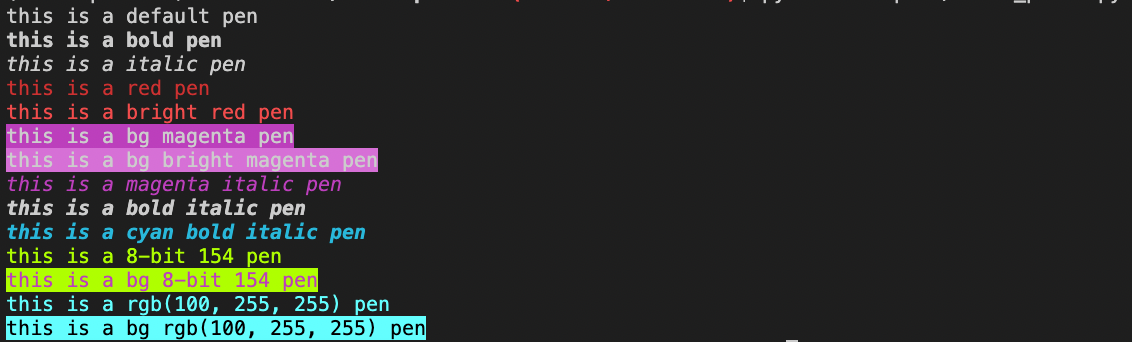
Print 'text color' and 'text format' on Term with Python
term-printer Print 'text color' and 'text format' on Term with Python ※ It may not work depending on the OS and shell used. PIP $ pip install term-pri
 10 Nov 12, 2022
10 Nov 12, 2022

Pytorch implementation for "Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter".
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter This is a pytorch-based implementation for paper Implicit Feature Alignme
 61 Nov 12, 2022
61 Nov 12, 2022

PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
WaveGrad2 - PyTorch Implementation PyTorch Implementation of Google Brain's WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis. Status (202
59 Dec 6, 2022

Open-sourcing the Slates Dataset for recommender systems research
FINN.no Recommender Systems Slate Dataset This repository accompany the paper "Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sa
 48 Nov 28, 2022
48 Nov 28, 2022
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption, CVPR 2021 (Oral)
TAP: Text-Aware Pre-training TAP: Text-Aware Pre-training for Text-VQA and Text-Caption by Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Flo
 61 Nov 14, 2022
61 Nov 14, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

Unconstrained Text Detection with Box Supervisionand Dynamic Self-Training
SelfText Beyond Polygon: Unconstrained Text Detection with Box Supervisionand Dynamic Self-Training Introduction This is a PyTorch implementation of "
 34 Nov 9, 2022
34 Nov 9, 2022
Code for "Primitive Representation Learning for Scene Text Recognition" (CVPR 2021)
Primitive Representation Learning Network (PREN) This repository contains the code for our paper accepted by CVPR 2021 Primitive Representation Learni
 76 Jan 2, 2023
76 Jan 2, 2023

Official Code for ICML 2021 paper "Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline"
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline Ankit Goyal, Hei Law, Bowei Liu, Alejandro Newell, Jia Deng Internati
 115 Jan 4, 2023
115 Jan 4, 2023

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022
A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation(DANN), support Office-31 and Office-Home dataset
DANN A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation Prerequisites Linux or OSX NVIDIA GPU + CUDA (may CuDNN) and corre
 8 Apr 16, 2022
8 Apr 16, 2022
This is the dataset and code release of the OpenRooms Dataset.
This is the dataset and code release of the OpenRooms Dataset.
 95 Jan 8, 2023
95 Jan 8, 2023
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
🐸 Identify anything. pyWhat easily lets you identify emails, IP addresses, and more. Feed it a .pcap file or some text and it'll tell you what it is! 🧙♀️
 5.6k Jan 3, 2023
5.6k Jan 3, 2023

In this repository, I have developed an end to end Automatic speech recognition project. I have developed the neural network model for automatic speech recognition with PyTorch and used MLflow to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry.
End to End Automatic Speech Recognition In this repository, I have developed an end to end Automatic speech recognition project. I have developed the
 22 Nov 13, 2022
22 Nov 13, 2022
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
 6 Jun 4, 2021
6 Jun 4, 2021

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021

Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition The official code of ABINet (CVPR 2021, Oral).
 334 Dec 31, 2022
334 Dec 31, 2022
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023
Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification"
PTR Code and datasets for our paper "PTR: Prompt Tuning with Rules for Text Classification" If you use the code, please cite the following paper: @art
 118 Dec 30, 2022
118 Dec 30, 2022
code for modular summarization work published in ACL2021 by Krishna et al
This repository contains the code for running modular summarization pipelines as described in the publication Krishna K, Khosla K, Bigham J, Lipton ZC
 21 Nov 24, 2022
21 Nov 24, 2022
easySpeech is an open-source Python wrapper for google speech to text API that doesn't require PyAudio(So you especially windows user don't have to deal with the errors while installing PyAudio) and also works with hugging face transformers
easySpeech easySpeech is an open source python wrapper for google speech to text api that doesn't require PyAaudio(So you specially windows user don't
 14 May 24, 2022
14 May 24, 2022
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
55 Dec 26, 2022
CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable.
CausalNLP CausalNLP is a practical toolkit for causal inference with text as treatment, outcome, or "controlled-for" variable. Install pip install -U
 95 Jan 3, 2023
95 Jan 3, 2023

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
Easy-to-use CPM for Chinese text generation
CPM 项目描述 CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂
 382 Jan 7, 2023
382 Jan 7, 2023
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations
DSTC10 Track 2 - Knowledge-grounded Task-oriented Dialogue Modeling on Spoken Conversations This repository contains the data, scripts and baseline co
 51 Dec 17, 2022
51 Dec 17, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
213 Dec 26, 2022

My Sublime Text theme
rsms sublime text theme Install: cd path/to/your/sublime/packages git clone https://github.com/rsms/sublime-theme.git rsms-theme You'll also need the
 166 Jan 4, 2023
166 Jan 4, 2023

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
A Dataset of Python Challenges for AI Research
Python Programming Puzzles (P3) This repo contains a dataset of python programming puzzles which can be used to teach and evaluate an AI's programming
850 Dec 24, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
31 Dec 8, 2022

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech Jaehyeon Kim, Jungil Kong, and Juhee Son In our rece
 1.7k Jan 8, 2023
1.7k Jan 8, 2023
Code and data of the ACL 2021 paper: Few-Shot Text Ranking with Meta Adapted Synthetic Weak Supervision
MetaAdaptRank This repository provides the implementation of meta-learning to reweight synthetic weak supervision data described in the paper Few-Shot
5 Jun 16, 2022
This is a GUI based text and image messenger. Other functionalities will be added soon.
Pigeon-Messenger (Requires Python and Kivy) Pigeon is a GUI based text and image messenger using Kivy and Python. Currently the layout is built. Funct
 4 Jan 21, 2022
4 Jan 21, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
75 Nov 2, 2022
Open Crawl Vietnamese Text
Open Crawl Vietnamese Text This repo contains crawled Vietnamese text from multiple sources. This list of a topic-centric public data sources in high
 4 Jan 5, 2022
4 Jan 5, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023
Codebase for the Summary Loop paper at ACL2020
Summary Loop This repository contains the code for ACL2020 paper: The Summary Loop: Learning to Write Abstractive Summaries Without Examples. Training
 44 Nov 4, 2022
44 Nov 4, 2022
EMNLP 2020 - Summarizing Text on Any Aspects
Summarizing Text on Any Aspects This repo contains preliminary code of the following paper: Summarizing Text on Any Aspects: A Knowledge-Informed Weak
 35 Nov 14, 2022
35 Nov 14, 2022

Pytorch implementation of MaskFlownet
MaskFlownet-Pytorch Unofficial PyTorch implementation of MaskFlownet (https://github.com/microsoft/MaskFlownet). Tested with: PyTorch 1.5.0 CUDA 10.1
 84 Nov 2, 2022
84 Nov 2, 2022
![[CVPR 2021] Monocular depth estimation using wavelets for efficiency](https://github.com/nianticlabs/wavelet-monodepth/raw/main/assets/combo_kitti.gif)
[CVPR 2021] Monocular depth estimation using wavelets for efficiency
Single Image Depth Prediction with Wavelet Decomposition Michaël Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit and Daniyar Turmukhambeto
 205 Jan 2, 2023
205 Jan 2, 2023
Code for our paper "SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization", ACL 2021
SimCLS Code for our paper: "SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization", ACL 2021 1. How to Install Requirements
 150 Dec 12, 2022
150 Dec 12, 2022

Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer.
Textual is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich termin
 17k Jan 2, 2023
17k Jan 2, 2023
Text to ASCII and ASCII to text
Text2ASCII Description This python script (converter.py) contains two functions: encode() is used to return a list of Integer, one item per character
 4 Jan 22, 2022
4 Jan 22, 2022

A Python app which can convert normal text to Handwritten text.
Text to HandWritten Text ✍️ Converter Watch Tutorial for this project Usage:- Clone my repository. Open CMD in working directory. Run following comman
 5 Dec 11, 2022
5 Dec 11, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 2, 2023

A framework for detecting, highlighting and correcting grammatical errors on natural language text.
Gramformer Human and machine generated text often suffer from grammatical and/or typographical errors. It can be spelling, punctuation, grammatical or
1.3k Jan 8, 2023

Fine-Tune EleutherAI GPT-Neo to Generate Netflix Movie Descriptions in Only 47 Lines of Code Using Hugginface And DeepSpeed
GPT-Neo-2.7B Fine-Tuning Example Using HuggingFace & DeepSpeed Installation cd venv/bin ./pip install -r ../../requirements.txt ./pip install deepspe
 180 Jan 5, 2023
180 Jan 5, 2023

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022

simpleT5 is built on top of PyTorch-lightning⚡️ and Transformers🤗 that lets you quickly train your T5 models.
Quickly train T5 models in just 3 lines of code + ONNX support simpleT5 is built on top of PyTorch-lightning ⚡️ and Transformers 🤗 that lets you quic
 220 Dec 30, 2022
220 Dec 30, 2022
Deep Text Search is an AI-powered multilingual text search and recommendation engine with state-of-the-art transformer-based multilingual text embedding (50+ languages).
Deep Text Search - AI Based Text Search & Recommendation System Deep Text Search is an AI-powered multilingual text search and recommendation engine w
 19 Sep 29, 2022
19 Sep 29, 2022

Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer.
rich.tui Rich.tui is a TUI (Text User Interface) framework for Python using Rich as a renderer. The end goal is to be able to rapidly create rich term
17.1k Jan 4, 2023
This is the repo for the paper `SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization'. (published in Bioinformatics'21)
SumGNN: Multi-typed Drug Interaction Prediction via Efficient Knowledge Graph Summarization This is the code for our paper ``SumGNN: Multi-typed Drug
 58 Dec 21, 2022
58 Dec 21, 2022