1774 Repositories
Python text-summarization-dataset Libraries

Automatic game data translator for RPGMaker-MV
RPGMaker-MV Translator 🕹️ 🎮 Use AI to translate all the dialogs and texts of your RPGMaker automatically. 👊 You worked hard to make your game, now
 11 Dec 26, 2022
11 Dec 26, 2022
GVT is a generic translation tool for parts of text on the PC screen with Text to Speak functionality.
GVT is a generic translation tool for parts of text on the PC screen with Text to Speech functionality. I wanted to create it because the existing tools that I experimented with did not satisfy me in ease-to-use experience and configuration. Personally I used it with Lost Ark (example included generated by 2k monitor) to translate simple dialogues of quests in Italian.
 1 Aug 21, 2022
1 Aug 21, 2022
A working (ish) python script to convert text to a gradient.
verticle-horiontal-gradient-script A working (ish) python script to convert text to a gradient. This script is poorly made with the well known python
 1 Feb 20, 2022
1 Feb 20, 2022
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. This article aims to provide an introduction on how to make use of the SpeechRecognition and pyttsx3 library of Python.
 1 Feb 13, 2022
1 Feb 13, 2022
Redlines produces a Markdown text showing the differences between two strings/text
Redlines Redlines produces a Markdown text showing the differences between two strings/text. The changes are represented with strike-throughs and unde
 2 Apr 8, 2022
2 Apr 8, 2022
A python script that can send notifications to your phone via SMS text
Discord SMS Notification A python script that help you send text message to your phone one of your desire discord channel have a new message. The proj
 2 Apr 25, 2022
2 Apr 25, 2022
Citation Intent Classification in scientific papers using the Scicite dataset an Pytorch
Citation Intent Classification Table of Contents About the Project Built With Installation Usage Acknowledgments About The Project Citation Intent Cla
 4 Mar 4, 2022
4 Mar 4, 2022
Copy only text-like files from the folder
copy-only-text-like-files-from-folder-python copy only text-like files from the folder This project is for those who want to copy only source code or
 1 May 17, 2022
1 May 17, 2022

OceanScript is an Esoteric language used to encode and decode text into a formulation of characters
OceanScript is an Esoteric language used to encode and decode text into a formulation of characters - where the final result looks like waves in the ocean.
 2 Sep 9, 2022
2 Sep 9, 2022
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents. Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts
 94 Dec 30, 2022
94 Dec 30, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 98 Dec 15, 2022
98 Dec 15, 2022
hashily is a Python module that provides a variety of text decoding and encoding operations.
hashily is a python module that performs a variety of text decoding and encoding functions. It also various functions for encrypting and decrypting text using various ciphers.
 5 Jul 17, 2022
5 Jul 17, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022
Computational inteligence project on faces in the wild dataset
Table of Contents The general idea How these scripts work? Loading data Needed modules and global variables Parsing the arrays in dataset Extracting a
 4 Oct 21, 2022
4 Oct 21, 2022

Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2.
Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2. It is trained (finetuned) on a curated list of approximately 45K Python (~470MB) files gathered from the Github. Currently, it just works properly on Python but not bad at other languages (thanks to GPT-2's power).
 91 Sep 23, 2022
91 Sep 23, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
Repo for my Tensorflow/Keras CV experiments. Mostly revolving around the Danbooru20xx dataset
SW-CV-ModelZoo Repo for my Tensorflow/Keras CV experiments. Mostly revolving around the Danbooru20xx dataset Framework: TF/Keras 2.7 Training SQLite D
 20 Dec 27, 2022
20 Dec 27, 2022

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022

Code for ML, domain generation, graph generation of ABC dataset
This is the repository for codes for ML, domain generation, graph generation of Asymmetric Buckling Columns (ABC) dataset in the paper "Learning Mechanically Driven Emergent Behavior with Message Passing Neural Networks".
 0 Jan 28, 2022
0 Jan 28, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022
CodeContests is a competitive programming dataset for machine-learning
CodeContests CodeContests is a competitive programming dataset for machine-learning. This dataset was used when training AlphaCode. It consists of pro
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
To classify the News into Real/Fake using Features from the Text Content of the article
Hoax-Detector Authenticity of news has now become a major problem. The Idea is to classify the News into Real/Fake using Features from the Text Conten
 1 Feb 9, 2022
1 Feb 9, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022
JaQuAD: Japanese Question Answering Dataset
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension (2022, Skelter Labs)
 84 Dec 27, 2022
84 Dec 27, 2022

Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification and Phonemetic Analysis
TDY-CNN for Text-Independent Speaker Verification Official implementation of Temporal Dynamic Convolutional Neural Network for Text-Independent Speake
 16 Oct 17, 2022
16 Oct 17, 2022
This code is the implementation of Text Emotion Recognition (TER) with linguistic features
APSIPA-TER This code is the implementation of Text Emotion Recognition (TER) with linguistic features. The network model is BERT with a pretrained mod
 1 Feb 8, 2022
1 Feb 8, 2022
Text Analysis & Topic Extraction on Android App user reviews
AndroidApp_TextAnalysis Hi, there! This is code archive for Text Analysis and Topic Extraction from user_reviews of Android App. Dataset Source : http
 1 Feb 14, 2022
1 Feb 14, 2022

A transformer which can randomly augment VOC format dataset (both image and bbox) online.
VocAug It is difficult to find a script which can augment VOC-format dataset, especially the bbox. Or find a script needs complex requirements so it i
 1 Mar 5, 2022
1 Mar 5, 2022
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
To create a deep learning model which can explain the content of an image in the form of speech through caption generation with attention mechanism on Flickr8K dataset.
 0 Feb 8, 2022
0 Feb 8, 2022
Text Normalization(文本正则化)
Text Normalization(文本正则化) 任务描述:通过机器学习算法将英文文本的“手写”形式转换成“口语“形式,例如“6ft”转换成“six feet”等 实验结果 XGBoost + bag-of-words: 0.99159 XGBoost+Weights+rules:0.99002
 0 Feb 26, 2022
0 Feb 26, 2022
Estimation of the CEFR complexity score of a given word, sentence or text.
NLP-Swedish … allows to estimate CEFR (Common European Framework of References) complexity score of a given word, sentence or text. CEFR scores come f
 3 Apr 30, 2022
3 Apr 30, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022

Balabobapy - Using artificial intelligence algorithms to continue the text
Balabobapy - Using artificial intelligence algorithms to continue the text
 1 Feb 4, 2022
1 Feb 4, 2022
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
A python Tk GUI that creates, writes text and attaches images into a custom spreadsheet file
 13 Dec 9, 2022
13 Dec 9, 2022
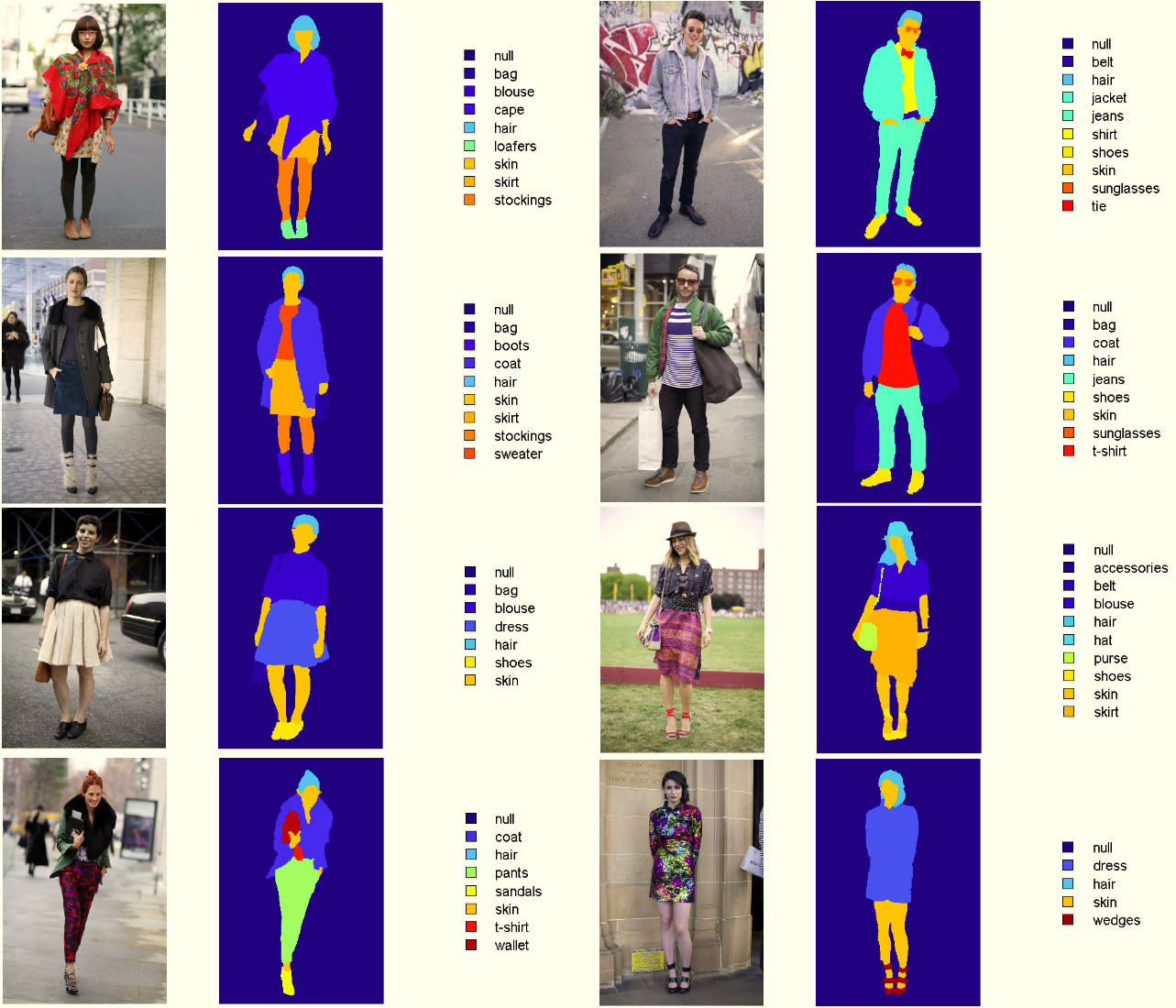
CCP dataset from Clothing Co-Parsing by Joint Image Segmentation and Labeling
Clothing Co-Parsing (CCP) Dataset Clothing Co-Parsing (CCP) dataset is a new clothing database including elaborately annotated clothing items. 2, 098
 434 Dec 24, 2022
434 Dec 24, 2022

Scraping and visualising India's real-time COVID-19 data from the MOHFW dataset.
COVID19-WEB-SCRAPER Open Source Tech Lab - Project [SEMESTER IV] OSTL Assignments OSTL Assignments - 1 OSTL Assignments - 2 Project COVID19 India Data
 8 Apr 28, 2022
8 Apr 28, 2022
A notebook to analyze Amazon Recommendation Review Dataset.
Amazon Recommendation Review Dataset Analyzer A notebook to analyze Amazon Recommendation Review Dataset. Features Calculates distinct user count, dis
 3 Aug 22, 2022
3 Aug 22, 2022
1900-2016 Olympic Data Analysis in Python by plotting different graphs
🔥 Olympics Data Analysis 🔥 In Data Science field, there is a big topic before creating a model for future prediction is Data Analysis. We can find o
 1 Feb 6, 2022
1 Feb 6, 2022
En- and decrypting text-messages by creating a key with of the fibonacci-sequence
En- and decrypting text-messages by creating a key with of the fibonacci-sequence. This key helps to create mathematical functions, whose zeros should generates the encrypted message.
 1 Feb 5, 2022
1 Feb 5, 2022
Application to help find best train itinerary, uses speech to text, has a spam filter to segregate invalid inputs, NLP and Pathfinding algos.
T-IAI-901-MSC2022 - GROUP 18 Gestion de projet Notre travail a été organisé et réparti dans un Trello. https://trello.com/b/X3s2fpPJ/ia-projet Install
 1 Feb 5, 2022
1 Feb 5, 2022
JD-backup is an advanced Python script, that will extract all links from a jDownloader 2 file list and export them to a text file.
JD-backup is an advanced Python script, that will extract all links from a jDownloader 2 file list and export them to a text file.
 3 Jun 7, 2022
3 Jun 7, 2022
A collection of Jupyter notebooks to play with NVIDIA's StyleGAN3 and OpenAI's CLIP for a text-based guided image generation.
StyleGAN3 CLIP-based guidance StyleGAN3 + CLIP StyleGAN3 + inversion + CLIP This repo is a collection of Jupyter notebooks made to easily play with St
 176 Dec 30, 2022
176 Dec 30, 2022

Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included.
pixel_character_generator Generating retro pixel game characters with Generative Adversarial Networks. Dataset "TinyHero" included. Dataset TinyHero D
 88 Nov 17, 2022
88 Nov 17, 2022

Semantic Segmentation Suite in TensorFlow
Semantic Segmentation Suite in TensorFlow. Implement, train, and test new Semantic Segmentation models easily!
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
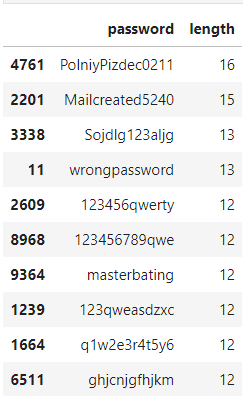
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
 7 Sep 4, 2022
7 Sep 4, 2022
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
Pytorch implementation of the paper "Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization"
 4 Sep 18, 2022
4 Sep 18, 2022

Breast Cancer Classification Model is applied on a different dataset
Breast Cancer Classification Model is applied on a different dataset
 1 Feb 4, 2022
1 Feb 4, 2022
Credit Card Fraud Detection, used the credit card fraud dataset from Kaggle
Credit Card Fraud Detection, used the credit card fraud dataset from Kaggle
 1 Feb 4, 2022
1 Feb 4, 2022

Sematic-Segmantation - Semantic Segmentation on MIT ADE20K dataset in PyTorch
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch impleme
 4 Mar 22, 2022
4 Mar 22, 2022
Training a deep learning model on the noisy CIFAR dataset
Training-a-deep-learning-model-on-the-noisy-CIFAR-dataset This repository contai
 1 Jun 14, 2022
1 Jun 14, 2022
Fake Shakespearean Text Generator
Fake Shakespearean Text Generator This project contains an impelementation of stateful Char-RNN model to generate fake shakespearean texts. Files and
 1 Feb 15, 2022
1 Feb 15, 2022

The code uses SegFormer for Semantic Segmentation on Drone Dataset.
SegFormer_Segmentation The code uses SegFormer for Semantic Segmentation on Drone Dataset. The details for the SegFormer can be obtained from the foll
 1 May 8, 2022
1 May 8, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022
This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project
Common Voice Utils This repository collects together basic linguistic processing data for using dataset dumps from the Common Voice project. It aims t
 40 Dec 20, 2022
40 Dec 20, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
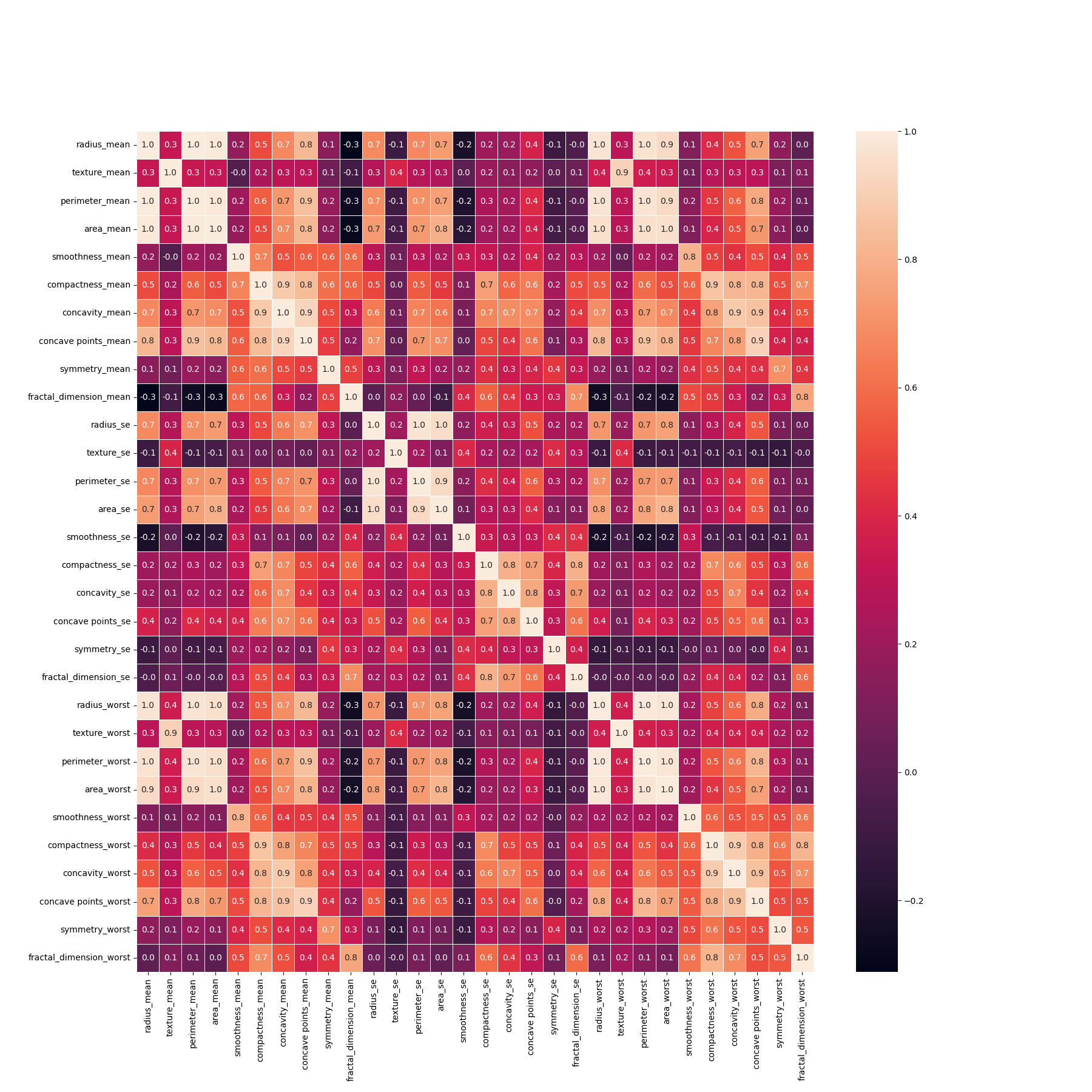
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
Breast-Cancer-Classification - Using SKLearn breast cancer dataset which contains 569 examples and 32 features classifying has been made with 6 different algorithms
 1 Jan 31, 2022
1 Jan 31, 2022

Py3editor - A text editor written in Python and Tkinter
Py3Editor My text editor written in Python and Tkinter! Contains a basic set of
 1 Mar 5, 2022
1 Mar 5, 2022
Using Logistic Regression and classifiers of the dataset to produce an accurate recall, f-1 and precision score
Using Logistic Regression and classifiers of the dataset to produce an accurate recall, f-1 and precision score
 1 Jan 31, 2022
1 Jan 31, 2022
Integrating C Buffer Data Into the instruction of `.text` segment instead of on `.data`, `.rodata` to avoid copy.
gcc-bufdata-integrating2text Integrating C Buffer Data Into the instruction of .text segment instead of on .data, .rodata to avoid copy. Usage In your
 1 Jan 31, 2022
1 Jan 31, 2022
Based on the given clinical dataset, Predict whether the patient having Heart Disease or Not having Heart Disease
Heart_Disease_Classification Based on the given clinical dataset, Predict whether the patient having Heart Disease or Not having Heart Disease Dataset
 1 Jan 30, 2022
1 Jan 30, 2022
Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech
epub2audiobook Creating an Audiobook (mp3 file) using a Ebook (epub) using BeautifulSoup and Google Text to Speech Input examples qual a pasta do seu
 7 Aug 25, 2022
7 Aug 25, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
Python tool that takes the OCR.space JSON output as input and draws a text overlay on top of the image.
OCR.space OCR Result Checker = Draw OCR overlay on top of image Python tool that takes the OCR.space JSON output as input, and draws an overlay on to
 4 Oct 18, 2022
4 Oct 18, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Notebooks, slides and dataset of the CorrelAid Machine Learning Winter School
CorrelAid Machine Learning Winter School Welcome to the CorrelAid ML Winter School! Task The problem we want to solve is to classify trees in Roosevel
 12 Nov 23, 2022
12 Nov 23, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Tensorflow Implementation of A Generative Flow for Text-to-Speech via Monotonic Alignment Search
 10 Oct 13, 2022
10 Oct 13, 2022

TalkingHead-1KH is a talking-head dataset consisting of YouTube videos
TalkingHead-1KH Dataset TalkingHead-1KH is a talking-head dataset consisting of YouTube videos, originally created as a benchmark for face-vid2vid: On
 173 Dec 29, 2022
173 Dec 29, 2022
A face dataset generator with out-of-focus blur detection and dynamic interval adjustment.
A face dataset generator with out-of-focus blur detection and dynamic interval adjustment.
 2 Jan 29, 2022
2 Jan 29, 2022
This repository contains (not all) code from my project on Named Entity Recognition in philosophical text
NERphilosophy 👋 Welcome to the github repository of my BsC thesis. This repository contains (not all) code from my project on Named Entity Recognitio
 1 Jan 27, 2022
1 Jan 27, 2022
2 telegram-bots: for image recognition and for text generation
💻 📱 Telegram_Bots 🔎 & 📖 2 telegram-bots: for image recognition and for text generation. About Image recognition bot: User sends a photo and bot de
 1 Jan 27, 2022
1 Jan 27, 2022
Recognizing the text contents from a scanned visiting card
Recognizing the text contents from a scanned visiting card. The application which is used to recognize the text from scanned images,printeddocuments,r
 1 Jan 28, 2022
1 Jan 28, 2022
This repository serves as a place to document a toy attempt on how to create a generative text model in Catalan, based on GPT-2
GPT-2 Catalan playground and scripts to train a GPT-2 model either from scrath or from another pretrained model.
 1 Jan 28, 2022
1 Jan 28, 2022

Python script for writing text on github contribution chart.
Github Contribution Drawer Python script for writing text on github contribution chart. Requirements Python 3.X Getting Started Create repository Put
 0 May 27, 2022
0 May 27, 2022

An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters
CNN-Filter-DB An Empirical Investigation of Model-to-Model Distribution Shifts in Trained Convolutional Filters Paul Gavrikov, Janis Keuper Paper: htt
 18 Dec 30, 2022
18 Dec 30, 2022

FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction
FaceExtraction FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction Occlusions often occur in face images in the wild, tr
 16 Dec 14, 2022
16 Dec 14, 2022
Tracking Progress in Question Answering over Knowledge Graphs
Tracking Progress in Question Answering over Knowledge Graphs Table of contents Question Answering Systems with Descriptions The QA Systems Table cont
 47 Jan 2, 2023
47 Jan 2, 2023

A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation".
Dual-Contrastive-Learning A PyTorch implementation for our paper "Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation". Y
 85 Dec 26, 2022
85 Dec 26, 2022
For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training.
LongScientificFormer For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training. Some code
 6 Nov 2, 2022
6 Nov 2, 2022
PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks
AttentionHTR PyTorch implementation of an end-to-end Handwritten Text Recognition (HTR) system based on attention encoder-decoder networks. Scene Text
 31 Dec 22, 2022
31 Dec 22, 2022
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation Prerequisites This repo is built upon a local copy of transfo
 10 Sep 28, 2022
10 Sep 28, 2022
This pyhton script converts a pdf to Image then using tesseract as OCR engine converts Image to Text
Script_Convertir_PDF_IMG_TXT Este script de pyhton convierte un pdf en Imagen luego utilizando tesseract como motor OCR convierte la Imagen a Texto. p
 1 Jan 27, 2022
1 Jan 27, 2022

Create animated and pretty Pandas Dataframe or Pandas Series
Rich DataFrame Create animated and pretty Pandas Dataframe or Pandas Series, as shown below: Installation pip install rich-dataframe Usage Minimal exa
 92 Dec 26, 2022
92 Dec 26, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
Detic ros - A simple ROS wrapper for Detic instance segmentation using pre-trained dataset
 12 Nov 19, 2022
12 Nov 19, 2022

This is a NLP based project to extract effective date of the contract from their text files.
Date-Extraction-from-Contracts This is a NLP based project to extract effective date of the contract from their text files. Problem statement This is
 1 Jan 26, 2022
1 Jan 26, 2022
Towards Fine-Grained Reasoning for Fake News Detection
FinerFact This is the PyTorch implementation for the FinerFact model in the AAAI 2022 paper Towards Fine-Grained Reasoning for Fake News Detection (Ar
 15 Dec 15, 2022
15 Dec 15, 2022
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
TweebankNLP This repo contains the new Tweebank-NER dataset and off-the-shelf Twitter-Stanza pipeline for state-of-the-art Tweet NLP, as described in
 42 Jan 26, 2022
42 Jan 26, 2022

This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation
This repository contains the database and code used in the paper Embedding Arithmetic for Text-driven Image Transformation (Guillaume Couairon, Holger
 31 Oct 17, 2022
31 Oct 17, 2022

PyTorch META-DATASET (Few-shot classification benchmark)
PyTorch META-DATASET (Few-shot classification benchmark) This repo contains a PyTorch implementation of meta-dataset and a unified implementation of s
 39 Oct 31, 2022
39 Oct 31, 2022

COPA-SSE contains crowdsourced explanations for the Balanced COPA dataset
COPA-SSE Repository for COPA-SSE: Semi-Structured Explanations for Commonsense Reasoning. COPA-SSE contains crowdsourced explanations for the Balanced
 5 Jul 31, 2022
5 Jul 31, 2022
"Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion"(WWW 2021)
STAR_KGC This repo contains the source code of the paper accepted by WWW'2021. "Structure-Augmented Text Representation Learning for Efficient Knowled
 60 Dec 26, 2022
60 Dec 26, 2022
PyTorch IPFS Dataset
PyTorch IPFS Dataset IPFSDataset(Dataset) See the jupyter notepad to see how it works and how it interacts with a standard pytorch DataLoader You need
 2 Apr 13, 2022
2 Apr 13, 2022
SpyQL - SQL with Python in the middle
SpyQL SQL with Python in the middle Concept SpyQL is a query language that combines: the simplicity and structure of SQL with the power and readabilit
 853 Dec 30, 2022
853 Dec 30, 2022
Postgres full text search options (tsearch, trigram) examples
postgres-full-text-search Postgres full text search options (tsearch, trigram) examples. Create DB CREATE DATABASE ftdb; To feed db with an example
 97 Dec 30, 2022
97 Dec 30, 2022
Application of K-means algorithm on a music dataset after a dimensionality reduction with PCA
PCA for dimensionality reduction combined with Kmeans Goal The Goal of this notebook is to apply a dimensionality reduction on a big dataset in order
 0 Sep 17, 2022
0 Sep 17, 2022
Discord Bot that can translate your text, count and reply to your messages with a personalised text
Discord Bot that can translate your text, count and reply to your messages with a personalised text
 2 Jan 26, 2022
2 Jan 26, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022