1774 Repositories
Python text-summarization-dataset Libraries

COCO Style Dataset Generator GUI
A simple GUI-based COCO-style JSON Polygon masks' annotation tool to facilitate quick and efficient crowd-sourced generation of annotation masks and bounding boxes. Optionally, one could choose to use a pretrained Mask RCNN model to come up with initial segmentations.
 142 Dec 9, 2022
142 Dec 9, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023

CRLT: A Unified Contrastive Learning Toolkit for Unsupervised Text Representation Learning
CRLT: A Unified Contrastive Learning Toolkit for Unsupervised Text Representation Learning This repository contains the code and relevant instructions
 5 Aug 19, 2022
5 Aug 19, 2022

CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
 6k Jan 25, 2022
6k Jan 25, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation
Improving Factual Completeness and Consistency of Image-to-text Radiology Report Generation The reference code of Improving Factual Completeness and C
 46 Dec 15, 2022
46 Dec 15, 2022
It is an open dataset for object detection in remote sensing images.
RSOD-Dataset It is an open dataset for object detection in remote sensing images. The dataset includes aircraft, oiltank, playground and overpass. The
 136 Dec 8, 2022
136 Dec 8, 2022
This jupyter notebook project was completed by me and my friend using the dataset from Kaggle
ARM This jupyter notebook project was completed by me and my friend using the dataset from Kaggle. The world Happiness 2017, which ranks 155 countries
 1 Jan 23, 2022
1 Jan 23, 2022

To prepare an image processing model to classify the type of disaster based on the image dataset
Disaster Classificiation using CNNs bunnysaini/Disaster-Classificiation Goal To prepare an image processing model to classify the type of disaster bas
 1 Jan 24, 2022
1 Jan 24, 2022

This project generates news headlines using a Long Short-Term Memory (LSTM) neural network.
News Headlines Generator bunnysaini/Generate-Headlines Goal This project aims to generate news headlines using a Long Short-Term Memory (LSTM) neural
1 Jan 24, 2022
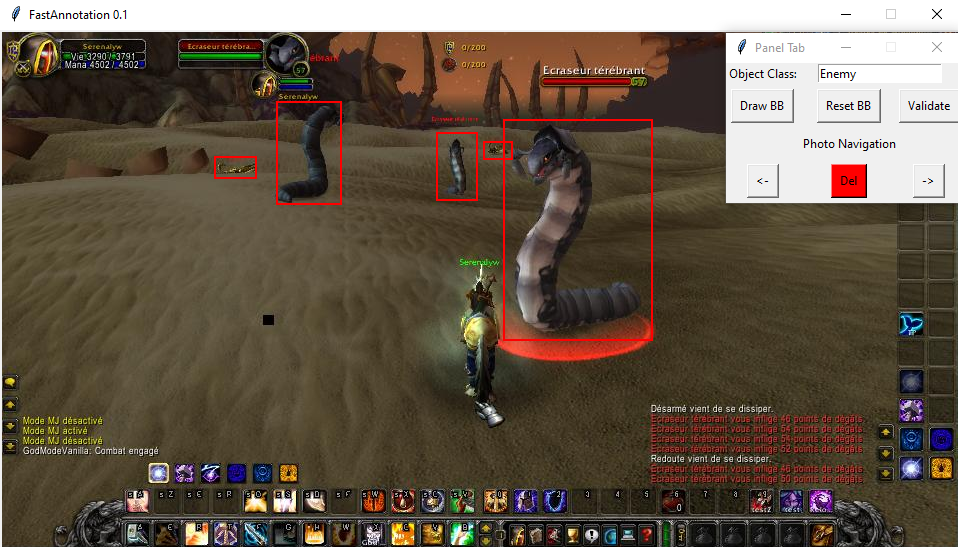
This is a simple framework to make object detection dataset very quickly
FastAnnotation Table of contents General info Requirements Setup General info This is a simple framework to make object detection dataset very quickly
 1 Jan 24, 2022
1 Jan 24, 2022
Simple Text-To-Speech Bot For Discord
Simple Text-To-Speech Bot For Discord This is a very simple TTS bot for discord made with python. For this bot you need FFMPEG, see installation to se
 1 Sep 26, 2022
1 Sep 26, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022
Klexikon: A German Dataset for Joint Summarization and Simplification
Klexikon: A German Dataset for Joint Summarization and Simplification Dennis Aumiller and Michael Gertz Heidelberg University Under submission at LREC
 8 Jan 3, 2023
8 Jan 3, 2023
A python module to parse text files with contains secret variables.
A python module to parse text files with contains secret variables.
 0 Dec 5, 2022
0 Dec 5, 2022
AIDynamicTextReader - A simple dynamic text reader based on Artificial intelligence
AI Dynamic Text Reader: This is a simple dynamic text reader based on Artificial
 1 Jan 18, 2022
1 Jan 18, 2022
Titanic Traveller Survivability Prediction
The aim of the mini project is predict whether or not a passenger survived based on attributes such as their age, sex, passenger class, where they embarked and more.
 0 Jan 20, 2022
0 Jan 20, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 8, 2023
579 Jan 8, 2023

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Grover is a model for Neural Fake News -- both generation and detectio
Grover is a model for Neural Fake News -- both generation and detection. However, it probably can also be used for other generation tasks.
 856 Dec 24, 2022
856 Dec 24, 2022

HairCLIP: Design Your Hair by Text and Reference Image
Overview This repository hosts the official PyTorch implementation of the paper: "HairCLIP: Design Your Hair by Text and Reference Image". Our single
 322 Dec 30, 2022
322 Dec 30, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

A library for creating text-based graphs in the terminal
tplot is a Python package for creating text-based graphs. Useful for visualizing data to the terminal or log files.
 164 Dec 14, 2022
164 Dec 14, 2022
ECLARE: Extreme Classification with Label Graph Correlations
ECLARE ECLARE: Extreme Classification with Label Graph Correlations @InProceedings{Mittal21b, author = "Mittal, A. and Sachdeva, N. and Agrawal
 35 Nov 6, 2022
35 Nov 6, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
 84 Dec 20, 2022
84 Dec 20, 2022
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
Finetune the base 64 px GLIDE-text2im model from OpenAI on your own image-text dataset
 82 Oct 13, 2022
82 Oct 13, 2022

A repo to show how to use custom dataset to train s2anet, and change backbone to resnext101
A repo to show how to use custom dataset to train s2anet, and change backbone to resnext101
 3 Dec 28, 2022
3 Dec 28, 2022
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
 87 Dec 24, 2022
87 Dec 24, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022
Custom function scheduler TUI (text-based user interface) in the console
Custom function scheduler TUI (text-based user interface) in the console
 1 Oct 26, 2022
1 Oct 26, 2022
Free & simple way to encipher text
VenSipher VenSipher is a free medium through which text can be enciphered. It can convert any text into an unrecognizable secret text that can only be
 3 Jan 28, 2022
3 Jan 28, 2022
Custom IMDB Dataset is extracted between 2020-2021 and custom distilBERT model is trained for movie success probability prediction
IMDB Success Predictor Project involves Web Scraping custom IMDB data between 2020 and 2021 of 10000 movies and shows sorted by number of votes ,fine
 1 Jan 18, 2022
1 Jan 18, 2022
The Scary Story - A Text Adventure
This is a text adventure which I made in python 3. This is one of my first big projects so any feedback would be greatly appreciated.
 2 Feb 20, 2022
2 Feb 20, 2022
📝An easy-to-use package to restore punctuation of the text.
✏️ rpunct - Restore Punctuation This repo contains code for Punctuation restoration. This package is intended for direct use as a punctuation restorat
 72 Dec 30, 2022
72 Dec 30, 2022
MAVE: : A Product Dataset for Multi-source Attribute Value Extraction
The dataset contains 3 million attribute-value annotations across 1257 unique categories on 2.2 million cleaned Amazon product profiles. It is a large, multi-sourced, diverse dataset for product attribute extraction study.
 17 Jan 18, 2022
17 Jan 18, 2022

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022

CLIP2Video: Mastering Video-Text Retrieval via Image CLIP
CLIP2Video: Mastering Video-Text Retrieval via Image CLIP The implementation of paper CLIP2Video: Mastering Video-Text Retrieval via Image CLIP. CLIP2
 168 Dec 29, 2022
168 Dec 29, 2022
"Exploring Vision Transformers for Fine-grained Classification" at CVPRW FGVC8
FGVC8 Exploring Vision Transformers for Fine-grained Classification paper presented at the CVPR 2021, The Eight Workshop on Fine-Grained Visual Catego
 19 Dec 6, 2022
19 Dec 6, 2022
Pretty-doc - Composable text objects with python
pretty-doc from __future__ import annotations from dataclasses import dataclass
 2 Jan 17, 2022
2 Jan 17, 2022
Deasciify-highlighted - A Python script for deasciifying text to Turkish and copying clipboard
deasciify-highlighted is a Python script for deasciifying text to Turkish and copying clipboard.
 3 Mar 18, 2022
3 Mar 18, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

Rotated Box Is Back : Accurate Box Proposal Network for Scene Text Detection
Rotated Box Is Back : Accurate Box Proposal Network for Scene Text Detection This material is supplementray code for paper accepted in ICDAR 2021 We h
 30 Dec 21, 2022
30 Dec 21, 2022

The mini-MusicNet dataset
mini-MusicNet A music-domain dataset for multi-label classification Music transcription is sequence-to-sequence prediction problem: given an audio per
 4 Nov 9, 2022
4 Nov 9, 2022
[AI6122] Text Data Management & Processing
[AI6122] Text Data Management & Processing is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Sun Aixin.
 1 Jan 17, 2022
1 Jan 17, 2022

Desktop utility to download images/videos/music/text from various websites, and more
Desktop utility to download images/videos/music/text from various websites, and more
 11.2k Jan 8, 2023
11.2k Jan 8, 2023
A Python library for generating new text from existing samples.
ReMarkov is a Python library for generating text from existing samples using Markov chains. You can use it to customize all sorts of writing from birt
 8 May 17, 2022
8 May 17, 2022
This repo is about implementing different approaches of pose estimation and also is a sub-task of the smart hospital bed project :smile:
Pose-Estimation This repo is a sub-task of the smart hospital bed project which is about implementing the task of pose estimation 😄 Many thanks to th
 11 Oct 17, 2022
11 Oct 17, 2022

Text editor on python tkinter to convert english text to other languages with the help of ployglot.
Transliterator Text Editor This is a simple transliteration program which is used to convert english word to phonetically matching word in another lan
 1 Jan 16, 2022
1 Jan 16, 2022
A python notification tool used for sending you text messages when certain conditions are met in the game, Neptune's Pride.
A python notification tool used for sending you text messages when certain conditions are met in the game, Neptune's Pride.
 1 Jan 16, 2022
1 Jan 16, 2022
The text based version of my App Blocker that I planning on converting to GUI soon.
App-Blocker The text based version of my App Blocker that I planning on converting to GUI soon. Currently I am just uploading the appblocker.py file,
 0 Sep 13, 2022
0 Sep 13, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 847 Dec 19, 2022
847 Dec 19, 2022
Bot that embeds a random hysterical meme from Reddit into your text channel as an embedded message, using an API call.
Discord_Meme_Bot 🤣 Bot that embeds a random hysterical meme from Reddit into your text channel as an embedded message, using an API call. Add the bot
 2 Jan 16, 2022
2 Jan 16, 2022
Code and data (Incidents Dataset) for ECCV 2020 Paper "Detecting natural disasters, damage, and incidents in the wild".
Incidents Dataset See the following pages for more details: Project page: IncidentsDataset.csail.mit.edu. ECCV 2020 Paper "Detecting natural disasters
 67 Dec 27, 2022
67 Dec 27, 2022
NLU Dataset Diagnostics
NLU Dataset Diagnostics This repository contains data and scripts to reproduce the results from our paper: Aarne Talman, Marianna Apidianaki, Stergios
 1 Jul 20, 2022
1 Jul 20, 2022
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples (WACV 2022) and Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning (TPAMI 2022 - in submission)
 42 Dec 6, 2022
42 Dec 6, 2022
Weakly Supervised Scene Text Detection using Deep Reinforcement Learning
Weakly Supervised Scene Text Detection using Deep Reinforcement Learning This repository contains the setup for all experiments performed in our Paper
 3 Dec 16, 2022
3 Dec 16, 2022
Long text token classification using LongFormer
Long text token classification using LongFormer
 161 Aug 7, 2022
161 Aug 7, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023
A Small and Easy approach to the BraTS2020 dataset (2D Segmentation)
BraTS2020 A Light & Scalable Solution to BraTS2020 | Medical Brain Tumor Segmentation (2D Segmentation) Developed the segmentation models for segregat
 0 Jan 19, 2022
0 Jan 19, 2022
Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord.
numpy2tfrecord Simple helper library to convert a collection of numpy data to tfrecord, and build a tensorflow dataset from the tfrecord. Installation
 2 Jan 16, 2022
2 Jan 16, 2022

LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation
LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation Table of Contents: Introduction Project Structure Installation Datas
 492 Dec 2, 2022
492 Dec 2, 2022
Files for a tutorial to train SegNet for road scenes using the CamVid dataset
SegNet and Bayesian SegNet Tutorial This repository contains all the files for you to complete the 'Getting Started with SegNet' and the 'Bayesian Seg
 800 Dec 31, 2022
800 Dec 31, 2022
classify fashion-mnist dataset with pytorch
Fashion-Mnist Classifier with PyTorch Inference 1- clone this repository: git clone https://github.com/Jhamed7/Fashion-Mnist-Classifier.git 2- Instal
 1 Jan 14, 2022
1 Jan 14, 2022
A collection of useful functions for writers to analyze text/stories.
AuthorTools AuthorTools provides a multitude of functions for easily analyzing (your?) writing. AuthorTools is made especially for creative writers wi
 1 Jan 14, 2022
1 Jan 14, 2022
Semantic Segmentation with SegFormer on Drone Dataset.
SegFormer_Segmentation Semantic Segmentation with SegFormer on Drone Dataset. You can check out the blog on Medium You can also try out the model with
 8 Oct 20, 2022
8 Oct 20, 2022

Frappe tinymce - Frappe app to replace default text editor with tinymce
Frappe tinyMCE tinyMCE Text Editor for frappe apps Replace frappe's Quill Text E
 23 Nov 16, 2022
23 Nov 16, 2022
Arabic-Phonetic-Output - You can input the phonetic version of any Arabic text here. This software will show you output in Arabic (with vowels)
Arabic-Phonetic-Output You can input the phonetic version of any Arabic text her
 1 Dec 30, 2021
1 Dec 30, 2021

Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
Using the provided dataset which includes various book features, in order to predict the price of books, using various proposed methods and models.
 1 Jan 13, 2022
1 Jan 13, 2022
2021 AI CUP Competition on Traditional Chinese Scene Text Recognition - Intermediate Contest
繁體中文場景文字辨識 程式碼說明 組別:這就是我 成員:蔣明憲 唐碩謙 黃玥菱 林冠霆 蕭靖騰 目錄 環境套件 安裝方式 資料夾布局 前處理-製作偵測訓練註解檔 前處理-製作分類訓練樣本 part.py : 從 json 裁切出分類訓練樣本 Class.py : 將切出來的樣本按照文字分類到各資料夾
 3 Jan 14, 2022
3 Jan 14, 2022
Text mining project; Using distilBERT to predict authors in the classification task authorship attribution.
DistilBERT-Text-mining-authorship-attribution Dataset used: https://www.kaggle.com/azimulh/tweets-data-for-authorship-attribution-modelling/version/2
 1 Jan 13, 2022
1 Jan 13, 2022
Image-generation-baseline - MUGE Text To Image Generation Baseline
MUGE Text To Image Generation Baseline Requirements and Installation More detail
 23 Oct 17, 2022
23 Oct 17, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool by
 20 Jan 13, 2022
20 Jan 13, 2022

Vector Quantized Diffusion Model for Text-to-Image Synthesis
Vector Quantized Diffusion Model for Text-to-Image Synthesis Due to company policy, I have to set microsoft/VQ-Diffusion to private for now, so I prov
 294 Jan 5, 2023
294 Jan 5, 2023

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
A menu for pygame. Simple, and easy to use
pygame-menu Source repo on GitHub, and run it on Repl.it Introduction Pygame-menu is a python-pygame library for creating menus and GUIs. It supports
 411 Dec 27, 2022
411 Dec 27, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
1 Jan 12, 2022
Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle.
2019-indian-election-eda Exploratory Data Analysis of the 2019 Indian General Elections using a dataset from Kaggle. This project is a part of the Cou
 5 Oct 10, 2022
5 Oct 10, 2022
I explore rock vs. mine prediction using a SONAR dataset
I explore rock vs. mine prediction using a SONAR dataset. Using a Logistic Regression Model for my prediction algorithm, I intend on predicting what an object is based on supervised learning.
 1 Jan 11, 2022
1 Jan 11, 2022
A Telegram bot written in python.
telegram_bot This bot is currently a beta project. Features A telegram bot which can: Send current COVID-19 cases/stats of Germany Send current worth
 1 Jan 11, 2022
1 Jan 11, 2022

Contains analysis of trends from Fitbit Dataset (source: Kaggle) to see how the trends can be applied to Bellabeat customers and Bellabeat products
Contains analysis of trends from Fitbit Dataset (source: Kaggle) to see how the trends can be applied to Bellabeat customers and Bellabeat products.
 2 Jan 12, 2022
2 Jan 12, 2022

FS2KToolbox FS2K Dataset Towards the translation between Face
FS2KToolbox FS2K Dataset Towards the translation between Face -- Sketch. Download (photo+sketch+annotation): Google-drive, Baidu-disk, pw: FS2K. For
 5 Jan 3, 2023
5 Jan 3, 2023
The dataset of tweets pulling from Twitters with keyword: Hydroxychloroquine, location: US, Time: 2020
HCQ_Tweet_Dataset: FREE to Download. Keywords: HCQ, hydroxychloroquine, tweet, twitter, COVID-19 This dataset is associated with the paper "Understand
 2 Mar 16, 2022
2 Mar 16, 2022

Using knowledge-informed machine learning on the PRONOSTIA (FEMTO) and IMS bearing data sets. Predict remaining-useful-life (RUL).
Knowledge Informed Machine Learning using a Weibull-based Loss Function Exploring the concept of knowledge-informed machine learning with the use of a
 43 Dec 14, 2022
43 Dec 14, 2022
Multi-Stage Episodic Control for Strategic Exploration in Text Games
XTX: eXploit - Then - eXplore Requirements First clone this repo using git clone https://github.com/princeton-nlp/XTX.git Please create two conda envi
 9 May 24, 2022
9 May 24, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool by
13 Jan 11, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022

UFPR-ADMR-v2 Dataset
UFPR-ADMR-v2 Dataset The UFPR-ADMRv2 dataset contains 5,000 dial meter images obtained on-site by employees of the Energy Company of Paraná (Copel), w
 8 Sep 29, 2022
8 Sep 29, 2022
Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Convolutional Recurrent Neural Network + CTCLoss | STAR-Net Code for paper "Towards Boosting the Accuracy of Non-Latin Scene Text Recognition" Depende
 7 Aug 7, 2022
7 Aug 7, 2022
AMUSE - financial summarization
AMUSE AMUSE - financial summarization Unzip data.zip Train new model: python FinAnalyze.py --task train --start 0 --count how many files,-1 for all
 1 Jan 11, 2022
1 Jan 11, 2022
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
Creating a python chatbot that Starbucks users can text to place an order + help cut wait time of a normal coffee.
 2 Jan 20, 2022
2 Jan 20, 2022
This is an AI that is supposed to say you if your text is formal or not
This is an AI that is supposed to say you if your text is formal or not. It's written in Python 3 and has some german examples (because I'm german yk) in the text.json file. This file contains the text which the AI. The TXT-file isn't important but necessary.
 1 Jan 12, 2022
1 Jan 12, 2022
ASCEND Chinese-English code-switching dataset
ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong.
 11 Dec 9, 2022
11 Dec 9, 2022
A music comments dataset, containing 39,051 comments for 27,384 songs.
Music Comments Dataset A music comments dataset, containing 39,051 comments for 27,384 songs. For academic research use only. Introduction This datase
 2 Jan 10, 2022
2 Jan 10, 2022
Send SMS text messages via email with as many accounts as you want :)
SMS-Spammer Send SMS text messages via email with as many accounts as you want :) Example Set Up Guide! To start log into the gmail account you would
 10 Oct 25, 2022
10 Oct 25, 2022

Text classification on IMDB dataset using Keras and Bi-LSTM network
Text classification on IMDB dataset using Keras and Bi-LSTM Text classification on IMDB dataset using Keras and Bi-LSTM network. Usage python3 main.py
 2 Sep 27, 2022
2 Sep 27, 2022