1774 Repositories
Python text-summarization-dataset Libraries
🎁 3,000,000+ Unsplash images made available for research and machine learning
The Unsplash Dataset The Unsplash Dataset is made up of over 250,000+ contributing global photographers and data sourced from hundreds of millions of
 2k Jan 3, 2023
2k Jan 3, 2023
A text file containing 479k English words for all your dictionary/word-based projects e.g: auto-completion / autosuggestion
List Of English Words A text file containing over 466k English words. While searching for a list of english words (for an auto-complete tutorial) I fo
 8.5k Jan 3, 2023
8.5k Jan 3, 2023
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022

macOS development environment setup: Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process.
dev-setup Motivation Setting up a new developer machine can be an ad-hoc, manual, and time-consuming process. dev-setup aims to simplify the process w
 5.9k Jan 2, 2023
5.9k Jan 2, 2023

DeepFashion2 is a comprehensive fashion dataset.
DeepFashion2 Dataset DeepFashion2 is a comprehensive fashion dataset. It contains 491K diverse images of 13 popular clothing categories from both comm
 1.8k Jan 7, 2023
1.8k Jan 7, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
FMA: A Dataset For Music Analysis
FMA: A Dataset For Music Analysis Michaël Defferrard, Kirell Benzi, Pierre Vandergheynst, Xavier Bresson. International Society for Music Information
 1.8k Dec 29, 2022
1.8k Dec 29, 2022
Official Implementation of "DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization."
DialogLM Code for AAAI 2022 paper: DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization. Pre-trained Models We release two ve
92 Dec 19, 2022

Moji sends text and fun facts from different APIs wit da use of a notification deamon
Moji sends text and fun facts from different APIs wit da use of a notification deamon. Can be runned via dmenu or rofi.
 2 Jan 12, 2022
2 Jan 12, 2022

Text editor on python to convert english text to malayalam(Romanization/Transiteration).
Manglish Text Editor This is a simple transiteration (romanization ) program which is used to convert manglish to malayalam (converts njaan to ഞാൻ ).
 1 May 11, 2022
1 May 11, 2022
Full LAKH MIDI dataset converted to MuseNet MIDI output format (9 instruments + drums)
LAKH MuseNet MIDI Dataset Full LAKH MIDI dataset converted to MuseNet MIDI output format (9 instruments + drums) Bonus: Choir on Channel 10 Please CC
 6 Nov 20, 2022
6 Nov 20, 2022

Image based Human Fall Detection
Here I integrated the YOLOv5 object detection algorithm with my own created dataset which consists of human activity images to achieve low cost, high accuracy, and real-time computing requirements
 12 Dec 11, 2022
12 Dec 11, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022

simple_pytorch_example project is a toy example of a python script that instantiates and trains a PyTorch neural network on the FashionMNIST dataset
simple_pytorch_example project is a toy example of a python script that instantiates and trains a PyTorch neural network on the FashionMNIST dataset
 1 Jan 7, 2022
1 Jan 7, 2022

A simple flask application to collect annotations for the Turing Change Point Dataset, a benchmark dataset for change point detection algorithms
AnnotateChange Welcome to the repository of the "AnnotateChange" application. This application was created to collect annotations of time series data
 16 Jul 21, 2022
16 Jul 21, 2022
Algorithms for outlier, adversarial and drift detection
Alibi Detect is an open source Python library focused on outlier, adversarial and drift detection. The package aims to cover both online and offline d
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

Speech to text streamlit app
Speech to text Streamlit-app! 👄 This speech to text recognition is powered by t
 9 Jan 1, 2023
9 Jan 1, 2023
Código para trabalho com o dataset Wine em Python
Um perceptron multicamadas (MLP) é uma rede neural artificial feedforward que gera um conjunto de saídas a partir de um conjunto de entradas. Um MLP é
 1 Jan 8, 2022
1 Jan 8, 2022
A generator of point clouds dataset for PyPipes.
CloudPipesGenerator Documentation | Colab Notebooks | Video Tutorials | Master Degree website A generator of point clouds dataset for PyPipes. TODO Us
 1 Jan 13, 2022
1 Jan 13, 2022
Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi.
Spchcat Speech recognition tool to convert audio to text transcripts, for Linux and Raspberry Pi. Description spchcat is a command-line tool that read
 279 Jan 3, 2023
279 Jan 3, 2023
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
Beancount: Double-Entry Accounting from Text Files.
beancount: Double-Entry Accounting from Text Files Contents Description Documentation Download & Installation Versions Filing Bugs Copyright and Licen
 2.3k Dec 28, 2022
2.3k Dec 28, 2022
Free and open source qualitative research tool
Taguette A spin on the phrase "tag it!", Taguette is a free and open source qualitative research tool that allows users to: Import PDFs, Word Docs (.d
 48 Jan 2, 2023
48 Jan 2, 2023

Official re-implementation of the Calibrated Adversarial Refinement model described in the paper Calibrated Adversarial Refinement for Stochastic Semantic Segmentation
Official re-implementation of the Calibrated Adversarial Refinement model described in the paper Calibrated Adversarial Refinement for Stochastic Semantic Segmentation
 31 Nov 22, 2022
31 Nov 22, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022
deep learning model with only python and numpy with test accuracy 99 % on mnist dataset and different optimization choices
deep_nn_model_with_only_python_100%_test_accuracy deep learning model with only python and numpy with test accuracy 99 % on mnist dataset and differen
 0 Aug 28, 2022
0 Aug 28, 2022

Graphical Password Authentication System.
Graphical Password Authentication System. This is used to increase the protection/security of a website. Our system is divided into further 4 layers of protection. Each layer is totally different and diverse than the others. This not only increases protection, but also makes sure that no non-human can log in to your account using different activities such as Brute Force Algorithm and so on.
 12 Dec 16, 2022
12 Dec 16, 2022
BERN2: an advanced neural biomedical namedentity recognition and normalization tool
BERN2 We present BERN2 (Advanced Biomedical Entity Recognition and Normalization
 99 Jan 6, 2023
99 Jan 6, 2023
Python module used to generate random facts
Randfacts is a python library that generates random facts. You can use randfacts.get_fact() to return a random fun fact. Disclaimer: Facts are not gua
 14 Dec 14, 2022
14 Dec 14, 2022
Text and code for the forthcoming second edition of Think Bayes, by Allen Downey.
Think Bayes 2 by Allen B. Downey The HTML version of this book is here. Think Bayes is an introduction to Bayesian statistics using computational meth
 1.5k Jan 8, 2023
1.5k Jan 8, 2023

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023
Diff Match Patch is a high-performance library in multiple languages that manipulates plain text.
The Diff Match and Patch libraries offer robust algorithms to perform the operations required for synchronizing plain text. Diff: Compare two blocks o
 5.9k Dec 30, 2022
5.9k Dec 30, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023

TensorFlow implementation of AlexNet and its training and testing on ImageNet ILSVRC 2012 dataset
AlexNet training on ImageNet LSVRC 2012 This repository contains an implementation of AlexNet convolutional neural network and its training and testin
 161 Nov 25, 2022
161 Nov 25, 2022

U-Net Implementation: Convolutional Networks for Biomedical Image Segmentation" using the Carvana Image Masking Dataset in PyTorch
U-Net Implementation By Christopher Ley This is my interpretation and implementation of the famous paper "U-Net: Convolutional Networks for Biomedical
 1 Jan 6, 2022
1 Jan 6, 2022
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022

Textual: a TUI (Text User Interface) framework for Python inspired by modern web development
Textual Textual is a TUI (Text User Interface) framework for Python inspired by
 17.1k Jan 4, 2023
17.1k Jan 4, 2023

End-to-End text sumarization, QAs generation using flask.
Help-Me-Read A web application created with Flask + BootStrap + HuggingFace 🤗 to generate summary and question-answer from given input text. It uses
 12 Nov 13, 2022
12 Nov 13, 2022
Automated Exploration Data Analysis on a financial dataset
Automated EDA on financial dataset Just a simple way to get automated Exploration Data Analysis from financial dataset (OHLCV) using Streamlit and ta.
 28 Nov 27, 2022
28 Nov 27, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

A simple component to display annotated text in Streamlit apps.
Annotated Text Component for Streamlit A simple component to display annotated text in Streamlit apps. For example: Installation First install Streaml
 312 Dec 30, 2022
312 Dec 30, 2022

Streamlit app demonstrating an image browser for the Udacity self-driving-car dataset with realtime object detection using YOLO.
Streamlit Demo: The Udacity Self-driving Car Image Browser This project demonstrates the Udacity self-driving-car dataset and YOLO object detection in
 992 Jan 4, 2023
992 Jan 4, 2023
G-Research-Crypto-Competition - Project for passing the ML exam. Dataset took from the competition on the kaggle
G-Research-Crypto-Competition Project for passing the ML exam. Dataset took from
 5 Jan 9, 2022
5 Jan 9, 2022

Understand Text Summarization and create your own summarizer in python
Automatic summarization is the process of shortening a text document with software, in order to create a summary with the major points of the original document. Technologies that can make a coherent summary take into account variables such as length, writing style and syntax.
 1 Oct 18, 2022
1 Oct 18, 2022
KIND: an Italian Multi-Domain Dataset for Named Entity Recognition
KIND (Kessler Italian Named-entities Dataset) KIND is an Italian dataset for Named-Entity Recognition. It contains more than one million tokens with t
 5 Jun 21, 2022
5 Jun 21, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022
The dataset of tweets pulling from Twitters with keyword: Hydroxychloroquine, location: US, Time: 2020
HCQ_Tweet_Dataset: FREE to Download. Keywords: HCQ, hydroxychloroquine, tweet, twitter, COVID-19 This dataset is associated with the paper "Understand
 2 Mar 16, 2022
2 Mar 16, 2022
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss
SAFL: A Self-Attention Scene Text Recognizer with Focal Loss This repository implements the SAFL in pytorch. Installation conda env create -f environm
 6 Aug 24, 2022
6 Aug 24, 2022

RodoSol-ALPR Dataset
RodoSol-ALPR Dataset This dataset, called RodoSol-ALPR dataset, contains 20,000 images captured by static cameras located at pay tolls owned by the Ro
 45 Dec 15, 2022
45 Dec 15, 2022
Generating synthetic mobility data for a realistic population with RNNs to improve utility and privacy
lbs-data Motivation Location data is collected from the public by private firms via mobile devices. Can this data also be used to serve the public goo
 11 Sep 22, 2022
11 Sep 22, 2022

Image Segmentation with U-Net Algorithm on Carvana Dataset using AWS Sagemaker
Image Segmentation with U-Net Algorithm on Carvana Dataset using AWS Sagemaker This is a full project of image segmentation using the model built with
 1 Jan 4, 2022
1 Jan 4, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Implementations of LSTM: A Search Space Odyssey variants and their training results on the PTB dataset.
An LSTM Odyssey Code for training variants of "LSTM: A Search Space Odyssey" on Fomoro. Check out the blog post. Training Install TensorFlow. Clone th
 95 Apr 13, 2022
95 Apr 13, 2022
STEFANN: Scene Text Editor using Font Adaptive Neural Network
STEFANN: Scene Text Editor using Font Adaptive Neural Network @ The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020.
 208 Dec 11, 2022
208 Dec 11, 2022

AsymmetricGAN - Dual Generator Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
AsymmetricGAN for Image-to-Image Translation AsymmetricGAN Framework for Multi-Domain Image-to-Image Translation AsymmetricGAN Framework for Hand Gest
 42 Jan 15, 2022
42 Jan 15, 2022

A unified framework to jointly model images, text, and human attention traces.
connect-caption-and-trace This repository contains the reference code for our paper Connecting What to Say With Where to Look by Modeling Human Attent
 73 Oct 24, 2022
73 Oct 24, 2022

Code and dataset for AAAI 2021 paper FixMyPose: Pose Correctional Describing and Retrieval Hyounghun Kim, Abhay Zala, Graham Burri, Mohit Bansal.
FixMyPose / फिक्समाइपोज़ Code and dataset for AAAI 2021 paper "FixMyPose: Pose Correctional Describing and Retrieval" Hyounghun Kim*, Abhay Zala*, Grah
 4 Sep 19, 2022
4 Sep 19, 2022
Character Grounding and Re-Identification in Story of Videos and Text Descriptions
Character in Story Identification Network (CiSIN) This project hosts the code for our paper. Youngjae Yu, Jongseok Kim, Heeseung Yun, Jiwan Chung and
 8 Dec 9, 2022
8 Dec 9, 2022
Moer Grounded Image Captioning by Distilling Image-Text Matching Model
Moer Grounded Image Captioning by Distilling Image-Text Matching Model Requirements Python 3.7 Pytorch 1.2 Prepare data Please use git clone --recurse
 60 Dec 16, 2022
60 Dec 16, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022
Python-Text-editor: a simple text editor on Python and Tkinter
Python-Text-editor This is a simple text editor on Python and Tkinter. The proje
 1 Jan 3, 2022
1 Jan 3, 2022
Image segmentation with private İstanbul Dataset
Image Segmentation This repo was created for academic research and test result. Repo will update after academic article online. This repo contains wei
 9 Dec 11, 2022
9 Dec 11, 2022
Text Summarization - WCN — Weighted Contextual N-gram method for evaluation of Text Summarization
Text Summarization WCN — Weighted Contextual N-gram method for evaluation of Text Summarization In this project, I fine tune T5 model on Extreme Summa
 1 Jan 3, 2022
1 Jan 3, 2022

Fashion Entity Classification
Fashion-Entity-Classification - Fashion-MNIST is a dataset of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Zalando intends Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
 1 Jan 4, 2022
1 Jan 4, 2022

Show-attend-and-tell - TensorFlow Implementation of "Show, Attend and Tell"
Show, Attend and Tell Update (December 2, 2016) TensorFlow implementation of Show, Attend and Tell: Neural Image Caption Generation with Visual Attent
 902 Nov 29, 2022
902 Nov 29, 2022
Pointer-generator - Code for the ACL 2017 paper Get To The Point: Summarization with Pointer-Generator Networks
Note: this code is no longer actively maintained. However, feel free to use the Issues section to discuss the code with other users. Some users have u
 2.1k Jan 4, 2023
2.1k Jan 4, 2023
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
March-madness - March Madness results 1985-2021
march-madness Results for all 2,268 NCAA Division I Men's Basketball Tournament games since the modern format was introduced in 1985. Includes years,
 2 Feb 26, 2022
2 Feb 26, 2022
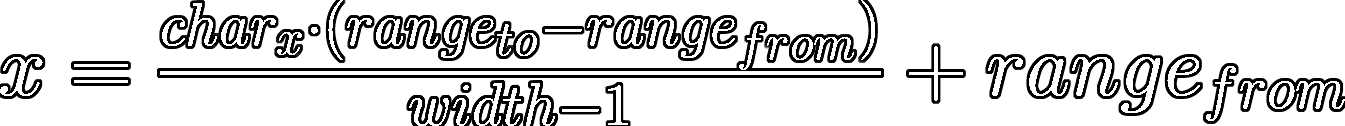
Glyph-graph - A simple, yet versatile, package for graphing equations on a 2-dimensional text canvas
Glyth Graph Revision for 0.01 A simple, yet versatile, package for graphing equations on a 2-dimensional text canvas List of contents: Brief Introduct
 2 Oct 21, 2022
2 Oct 21, 2022
Skype export archive to text converter for python
Skype export archive to text converter This software utility extracts chat logs
 2 Jun 30, 2022
2 Jun 30, 2022

Augmented CLIP - Training simple models to predict CLIP image embeddings from text embeddings, and vice versa.
Train aug_clip against laion400m-embeddings found here: https://laion.ai/laion-400-open-dataset/ - note that this used the base ViT-B/32 CLIP model. S
 55 Sep 13, 2022
55 Sep 13, 2022

Ascify-Art - An easy to use, GUI based and user-friendly colored ASCII art generator from images!
Ascify-Art This is a python based colored ASCII art generator for free! How to Install? You can download and use the python version if you want, modul
 14 Dec 31, 2022
14 Dec 31, 2022
Png-to-stl - Converts PNG and text to SVG, and then extrudes that based on parameters
have ansible installed locally run ansible-playbook setup_application.yml this sets up directories, installs system packages, and sets up python envir
 1 Jan 3, 2022
1 Jan 3, 2022

Research - dataset and code for 2016 paper Learning a Driving Simulator
the people's comma the paper Learning a Driving Simulator the comma.ai driving dataset 7 and a quarter hours of largely highway driving. Enough to tra
 4.1k Jan 2, 2023
4.1k Jan 2, 2023

AutoGluon: AutoML for Text, Image, and Tabular Data
AutoML for Text, Image, and Tabular Data AutoGluon automates machine learning tasks enabling you to easily achieve strong predictive performance in yo
 5.2k Dec 29, 2022
5.2k Dec 29, 2022
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
 794 Dec 23, 2022
794 Dec 23, 2022

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
Customer-Transaction-Analysis - This analysis is based on a synthesised transaction dataset containing 3 months worth of transactions for 100 hypothetical customers.
Customer-Transaction-Analysis - This analysis is based on a synthesised transaction dataset containing 3 months worth of transactions for 100 hypothetical customers. It contains purchases, recurring transactions, and salary transactions. The dataset is designed to simulate realistic transaction behaviours that are observed in ANZ’s real transaction data.
 1 Jan 1, 2022
1 Jan 1, 2022

Advanced_Data_Visualization_Tools - The present hands-on lab mainly uses Immigration to Canada dataset and employs advanced visualization tools such as word cloud, and waffle plot to display relations between features within the dataset.
Hands-on Practice Learning Lab for Data Science Overview This hands on practice lab is a part of Data Visualization with Python course offered by Cour
 1 Jan 5, 2022
1 Jan 5, 2022
Vector space based Information Retrieval System for Text Processing - Information retrieval
Information Retrieval: Text Processing Group 13 Sequence of operations Install Requirements Add given wikipedia files to the corpus directory. Downloa
 1 Jan 1, 2022
1 Jan 1, 2022

Generating .npy dataset and labels out of given image, containing numbers from 0 to 9, using opencv
basic-dataset-generator-from-image-of-numbers generating .npy dataset and labels out of given image, containing numbers from 0 to 9, using opencv inpu
 1 Jan 1, 2022
1 Jan 1, 2022
CIFAR-10_train-test - training and testing codes for dataset CIFAR-10
CIFAR-10_train-test - training and testing codes for dataset CIFAR-10
 3 Apr 26, 2022
3 Apr 26, 2022

Siamese-nn-semantic-text-similarity - A repository containing comprehensive Neural Networks based PyTorch implementations for the semantic text similarity task
Siamese Deep Neural Networks for Semantic Text Similarity PyTorch A repository c
 32 Dec 15, 2022
32 Dec 15, 2022

3D dataset of humans Manipulating Objects in-the-Wild (MOW)
MOW dataset [Website] This repository maintains our 3D dataset of humans Manipulating Objects in-the-Wild (MOW). The dataset contains 512 images in th
 28 Nov 6, 2022
28 Nov 6, 2022
This can be use to convert text in a file to handwritten text.
TextToHandwriting This can be used to convert text to handwriting. Clone this project or download the code. Run TextToImage.py give the filename of th
 2 Feb 6, 2022
2 Feb 6, 2022

TransPrompt - Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification
TransPrompt This code is implement for our EMNLP 2021's paper 《TransPrompt:Towards an Automatic Transferable Prompting Framework for Few-shot Text Cla
 23 Dec 21, 2022
23 Dec 21, 2022
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
MixText This repo contains codes for the following paper: Jiaao Chen, Zichao Yang, Diyi Yang: MixText: Linguistically-Informed Interpolation of Hidden
 309 Dec 12, 2022
309 Dec 12, 2022
Implementation of ICLR 2020 paper "Revisiting Self-Training for Neural Sequence Generation"
Self-Training for Neural Sequence Generation This repo includes instructions for running noisy self-training algorithms from the following paper: Revi
 45 Dec 31, 2022
45 Dec 31, 2022
Personal implementation of paper "Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval"
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval This repo provides personal implementation of paper Approximate Ne
 8 Oct 7, 2022
8 Oct 7, 2022

A minimal and ridiculously good looking command-line-interface toolkit
Proper CLI Proper CLI is a Python package for creating beautiful, composable, and ridiculously good looking command-line-user-interfaces without havin
 2 Dec 22, 2022
2 Dec 22, 2022
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf
 8k Jan 8, 2023
8k Jan 8, 2023
GCRC: A Gaokao Chinese Reading Comprehension dataset for interpretable Evaluation
GCRC GCRC: A New Challenging MRC Dataset from Gaokao Chinese for Explainable Eva
 5 Nov 4, 2022
5 Nov 4, 2022
This repo tries to recognize faces in the dataset you created
YÜZ TANIMA SİSTEMİ Bu repo oluşturacağınız yüz verisetlerini tanımaya çalışan ma
 2 Dec 30, 2021
2 Dec 30, 2021

Slice a single image into multiple pieces and create a dataset from them
OpenCV Image to Dataset Converter Slice a single image of Persian digits into mu
 14 Dec 29, 2022
14 Dec 29, 2022

Encode and decode text application
Text Encoder and Decoder Encode and decode text in many ways using this application! Encode in: ASCII85 Base85 Base64 Base32 Base16 Url MD5 Hash SHA-1
 1 Feb 12, 2022
1 Feb 12, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022

A Python parser that takes the content of a text file and then reads it into variables.
Text-File-Parser A Python parser that takes the content of a text file and then reads into variables. Input.text File 1. What is your ***? 1. 18 -
 0 Jul 26, 2021
0 Jul 26, 2021
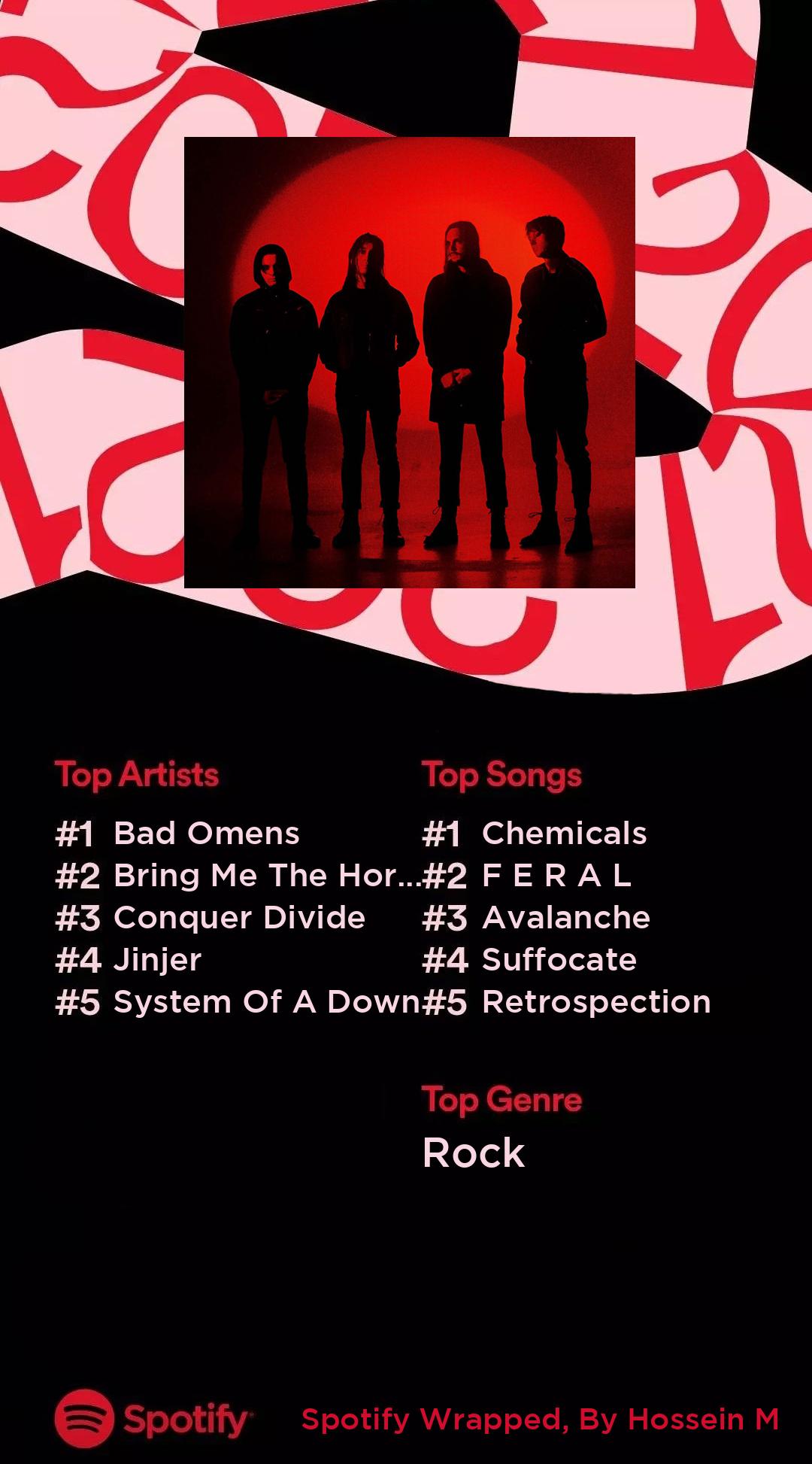
A project in order to analyze user's favorite musics, artists and genre
Spotify-Wrapped This is a project about Spotify Wrapped (which is an extra option for premium accounts, but you don't need to be premium here) This pr
 19 Jan 4, 2023
19 Jan 4, 2023