665 Repositories
Python training-tricks Libraries
Repo for CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
CReST in Tensorflow 2 Code for the paper: "CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning" by Chen Wei, Ki
 75 Nov 1, 2022
75 Nov 1, 2022
Uni-Fold: Training your own deep protein-folding models.
Uni-Fold: Training your own deep protein-folding models. This package provides and implementation of a trainable, Transformer-based deep protein foldi
 88 Jan 3, 2023
88 Jan 3, 2023
Torchrecipes provides a set of reproduci-able, re-usable, ready-to-run RECIPES for training different types of models, across multiple domains, on PyTorch Lightning.
Recipes are a standard, well supported set of blueprints for machine learning engineers to rapidly train models using the latest research techniques without significant engineering overhead.Specifically, recipes aims to provide- Consistent access to pre-trained SOTA models ready for production- Reference implementations for SOTA research reproducibility, and infrastructure to guarantee correctness, efficiency, and interoperability.
 193 Dec 28, 2022
193 Dec 28, 2022

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
Training code for Korean multi-class sentiment analysis
KoSentimentAnalysis Bert implementation for the Korean multi-class sentiment analysis 왜 한국어 감정 다중분류 모델은 거의 없는 것일까?에서 시작된 프로젝트 Environment: Pytorch, Da
 3 Dec 2, 2022
3 Dec 2, 2022
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
 1 Dec 9, 2021
1 Dec 9, 2021

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
 862 Jan 1, 2023
862 Jan 1, 2023
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
28 Dec 9, 2022
Post-Training Quantization for Vision transformers.
PTQ4ViT Post-Training Quantization Framework for Vision Transformers. We use the twin uniform quantization method to reduce the quantization error on
 61 Dec 28, 2022
61 Dec 28, 2022
Uni-Fold: Training your own deep protein-folding models
Uni-Fold: Training your own deep protein-folding models. This package provides an implementation of a trainable, Transformer-based deep protein foldin
 187 Jan 4, 2023
187 Jan 4, 2023
The easiest tool for extracting radiomics features and training ML models on them.
Simple pipeline for experimenting with radiomics features Installation git clone https://github.com/piotrekwoznicki/ClassyRadiomics.git cd classrad pi
 17 Aug 4, 2022
17 Aug 4, 2022
Training Structured Neural Networks Through Manifold Identification and Variance Reduction
Training Structured Neural Networks Through Manifold Identification and Variance Reduction This repository is a pytorch implementation of the Regulari
 0 Dec 23, 2021
0 Dec 23, 2021

VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
 32 Oct 24, 2022
32 Oct 24, 2022

Official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th ICML Workshop on AutoML)
Automated Learning Rate Scheduler for Large-Batch Training The official repository for Automated Learning Rate Scheduler for Large-Batch Training (8th
 35 Jan 4, 2023
35 Jan 4, 2023
An OpenAI-Gym Package for Training and Testing Reinforcement Learning algorithms with OpenSim Models
Authors: Utkarsh A. Mishra and Dr. Dimitar Stanev Advisors: Dr. Dimitar Stanev and Prof. Auke Ijspeert, Biorobotics Laboratory (BioRob), EPFL Video Pl
 16 Dec 13, 2022
16 Dec 13, 2022
FedTorch is an open-source Python package for distributed and federated training of machine learning models using PyTorch distributed API
FedTorch is a generic repository for benchmarking different federated and distributed learning algorithms using PyTorch Distributed API.
 136 Dec 23, 2022
136 Dec 23, 2022
Yas CRNN model training - Yet Another Genshin Impact Scanner
Yas-Train Yet Another Genshin Impact Scanner 又一个原神圣遗物导出器 介绍 该仓库为 Yas 的模型训练程序 相关资料 MobileNetV3 CRNN 使用 假设你会设置基本的pytorch环境。 生成数据集 python main.py gen 训练
 18 Jan 8, 2023
18 Jan 8, 2023

FuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space OptimizationFuseDream: Training-Free Text-to-Image Generationwith Improved CLIP+GAN Space Optimization
FuseDream This repo contains code for our paper (paper link): FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimizat
 191 Dec 31, 2022
191 Dec 31, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 0 Mar 20, 2022
0 Mar 20, 2022
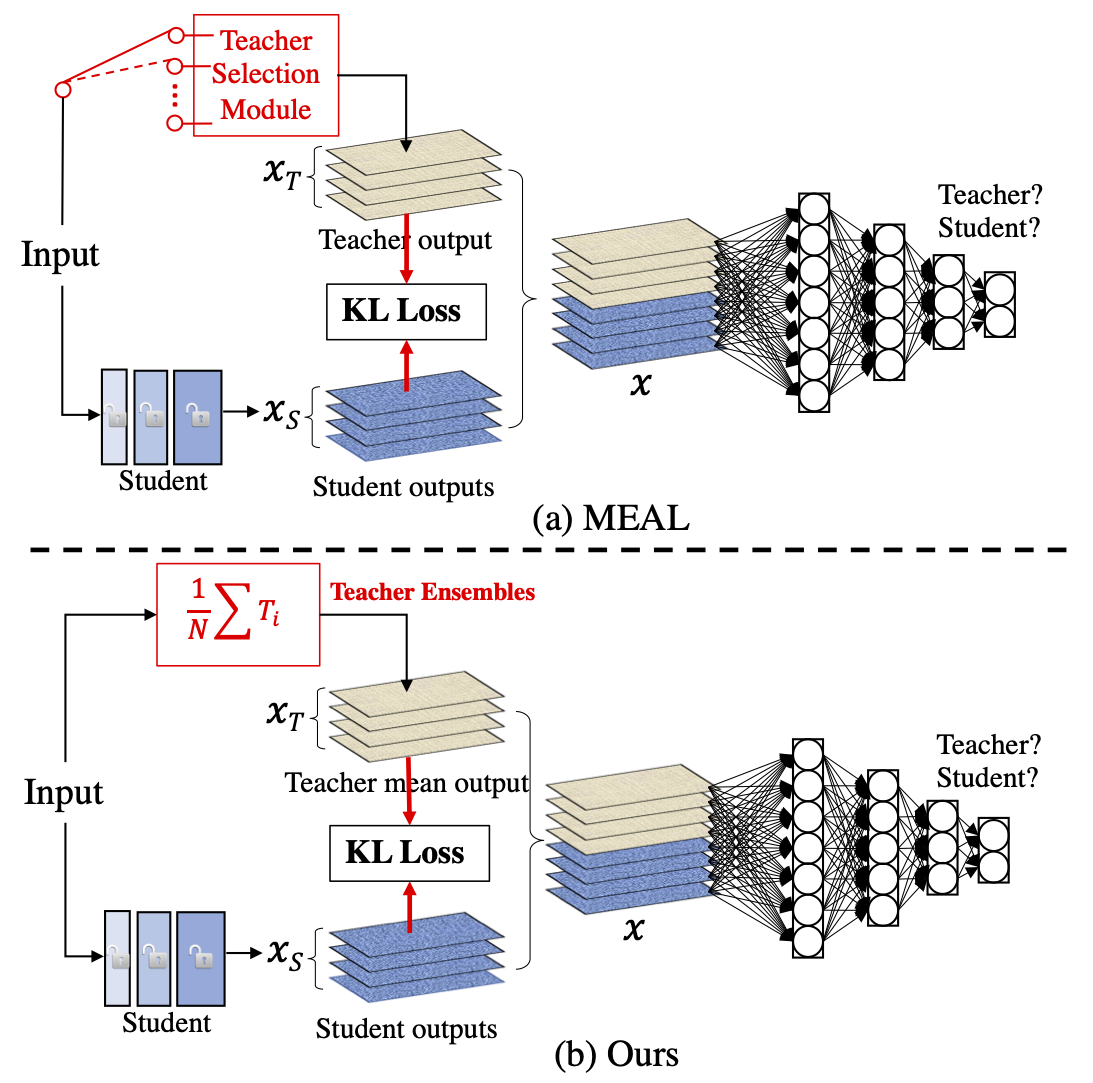
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022
Adaptive Denoising Training (ADT) for Recommendation.
DenoisingRec Adaptive Denoising Training for Recommendation. This is the pytorch implementation of our paper at WSDM 2021: Denoising Implicit Feedback
 51 Dec 30, 2022
51 Dec 30, 2022
Code repository for "Reducing Underflow in Mixed Precision Training by Gradient Scaling" presented at IJCAI '20
Reducing Underflow in Mixed Precision Training by Gradient Scaling This project implements the gradient scaling method to improve the performance of m
 5 Apr 14, 2022
5 Apr 14, 2022
Rainbow DQN implementation accompanying the paper "Fast and Data-Efficient Training of Rainbow" which reaches 205.7 median HNS after 10M frames. 🌈
Rainbow 🌈 An implementation of Rainbow DQN which reaches a median HNS of 205.7 after only 10M frames (the original Rainbow from Hessel et al. 2017 re
 15 Dec 3, 2021
15 Dec 3, 2021

Code for EMNLP 2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training"
SCAPT-ABSA Code for EMNLP2021 paper: "Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training" Overvie
 66 Dec 4, 2022
66 Dec 4, 2022
TextWorld is a sandbox learning environment for the training and evaluation of reinforcement learning (RL) agents on text-based games.
TextWorld A text-based game generator and extensible sandbox learning environment for training and testing reinforcement learning (RL) agents. Also ch
983 Dec 23, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
228 Nov 21, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
Vision-Language Pre-training for Image Captioning and Question Answering
VLP This repo hosts the source code for our AAAI2020 work Vision-Language Pre-training (VLP). We have released the pre-trained model on Conceptual Cap
 373 Jan 3, 2023
373 Jan 3, 2023
Research code for ECCV 2020 paper "UNITER: UNiversal Image-TExt Representation Learning"
UNITER: UNiversal Image-TExt Representation Learning This is the official repository of UNITER (ECCV 2020). This repository currently supports finetun
 680 Dec 24, 2022
680 Dec 24, 2022
Oscar and VinVL
Oscar: Object-Semantics Aligned Pre-training for Vision-and-Language Tasks VinVL: Revisiting Visual Representations in Vision-Language Models Updates
938 Dec 26, 2022

Research Code for NeurIPS 2020 Spotlight paper "Large-Scale Adversarial Training for Vision-and-Language Representation Learning": UNITER adversarial training part
VILLA: Vision-and-Language Adversarial Training This is the official repository of VILLA (NeurIPS 2020 Spotlight). This repository currently supports
 109 Dec 31, 2022
109 Dec 31, 2022

A Fast Knowledge Distillation Framework for Visual Recognition
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
129 Dec 24, 2022
Codebase for Inducing Causal Structure for Interpretable Neural Networks
Interchange Intervention Training (IIT) Codebase for Inducing Causal Structure for Interpretable Neural Networks Release Notes 12/01/2021: Code and Pa
 6 Oct 10, 2022
6 Oct 10, 2022
A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
 1.1k Dec 3, 2021
1.1k Dec 3, 2021
A fast, pure python implementation of the MuyGPs Gaussian process realization and training algorithm.
Fast implementation of the MuyGPs Gaussian process hyperparameter estimation algorithm MuyGPs is a GP estimation method that affords fast hyperparamet
 13 Dec 2, 2022
13 Dec 2, 2022
PyTorch implementation of paper A Fast Knowledge Distillation Framework for Visual Recognition.
FKD: A Fast Knowledge Distillation Framework for Visual Recognition Official PyTorch implementation of paper A Fast Knowledge Distillation Framework f
129 Dec 24, 2022
A simple framwork to streamline the Domain Adaptation training process.
FastDA Introduction This is a simple framework for domain adaptation training. You can use it to build your own training process. It heavily relies on
 7 Nov 22, 2022
7 Nov 22, 2022
A light weight data augmentation tool for training CNNs and Viola Jones detectors
hey-daug A light weight data augmentation tool for training CNNs and Viola Jones detectors (Haar Cascades). This tool inflates your data by up to six
 2 Nov 23, 2019
2 Nov 23, 2019
Tools for curating biomedical training data for large-scale language modeling
Tools for curating biomedical training data for large-scale language modeling
 242 Dec 25, 2022
242 Dec 25, 2022
EMNLP 2021 paper The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022

Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks.
The Lottery Ticket Hypothesis for Pre-trained BERT Networks Code for this paper The Lottery Ticket Hypothesis for Pre-trained BERT Networks. [NeurIPS
 122 Dec 14, 2022
122 Dec 14, 2022
Source code for "Efficient Training of BERT by Progressively Stacking"
Introduction This repository is the code to reproduce the result of Efficient Training of BERT by Progressively Stacking. The code is based on Fairseq
 101 Dec 2, 2022
101 Dec 2, 2022
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
2.1k Dec 28, 2022

Understanding the Difficulty of Training Transformers
Admin Understanding the Difficulty of Training Transformers Guided by our analyses, we propose Adaptive Model Initialization (Admin), which successful
 300 Dec 29, 2022
300 Dec 29, 2022
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
DeepSpeed+Megatron trained the world's most powerful language model: MT-530B DeepSpeed is hiring, come join us! DeepSpeed is a deep learning optimizat
8.4k Dec 28, 2022
[ACL-IJCNLP 2021] "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets"
EarlyBERT This is the official implementation for the paper in ACL-IJCNLP 2021 "EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets" by
13 May 11, 2022

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022

Revisiting Self-Training for Few-Shot Learning of Language Model.
SFLM This is the implementation of the paper Revisiting Self-Training for Few-Shot Learning of Language Model. SFLM is short for self-training for few
 15 Nov 19, 2022
15 Nov 19, 2022
![[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training](https://github.com/rrmenon10/ADAPET/raw/master/img/ADAPET_update.png)
[EMNLP 2021] Improving and Simplifying Pattern Exploiting Training
ADAPET This repository contains the official code for the paper: "Improving and Simplifying Pattern Exploiting Training". The model improves and simpl
 138 Dec 26, 2022
138 Dec 26, 2022
The code is the training example of AAAI2022 Security AI Challenger Program Phase 8: Data Centric Robot Learning on ML models.
Example code of [Tianchi AAAI2022 Security AI Challenger Program Phase 8]
 22 Oct 14, 2022
22 Oct 14, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
 45 Dec 3, 2021
45 Dec 3, 2021

Efficient training of deep recommenders on cloud.
HybridBackend Introduction HybridBackend is a training framework for deep recommenders which bridges the gap between evolving cloud infrastructure and
 111 Dec 23, 2022
111 Dec 23, 2022

Official Implementation of DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation [Arxiv] [Paper] As acquiring pixel-wise an
 305 Dec 29, 2022
305 Dec 29, 2022
Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis
HAABSAStar Code for "Adversarial Training for a Hybrid Approach to Aspect-Based Sentiment Analysis". This project builds on the code from https://gith
 1 Sep 14, 2020
1 Sep 14, 2020
![[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️](https://github.com/sungyoon-lee/LossLandscapeMatters/raw/master/media/fig.png)
[NeurIPS 2021] Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples | ⛰️⚠️
Towards Better Understanding of Training Certifiably Robust Models against Adversarial Examples This repository is the official implementation of "Tow
 4 Jul 12, 2022
4 Jul 12, 2022
Official implementation of the NeurIPS 2021 paper Online Learning Of Neural Computations From Sparse Temporal Feedback
Online Learning Of Neural Computations From Sparse Temporal Feedback This repository is the official implementation of the NeurIPS 2021 paper Online L
 3 Dec 15, 2021
3 Dec 15, 2021
Official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive
TTT++ This is an official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive? TL;DR: Online Feature Alignment + Str
 39 Dec 25, 2022
39 Dec 25, 2022
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models This repository is the official implementation of the fol
 41 Dec 6, 2022
41 Dec 6, 2022
A paper list of pre-trained language models (PLMs).
Large-scale pre-trained language models (PLMs) such as BERT and GPT have achieved great success and become a milestone in NLP.
 124 Jan 2, 2023
124 Jan 2, 2023
Minimalistic PyTorch training loop
Backbone for PyTorch training loop Will try to keep it minimalistic. pip install back from back import Bone Features Progress bar Checkpoints saving/l
 4 Jan 16, 2020
4 Jan 16, 2020
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
 5 Nov 30, 2021
5 Nov 30, 2021

The official implementation for "FQ-ViT: Fully Quantized Vision Transformer without Retraining".
FQ-ViT [arXiv] This repo contains the official implementation of "FQ-ViT: Fully Quantized Vision Transformer without Retraining". Table of Contents In
 132 Jan 8, 2023
132 Jan 8, 2023

Code implementing "Improving Deep Learning Interpretability by Saliency Guided Training"
Saliency Guided Training Code implementing "Improving Deep Learning Interpretability by Saliency Guided Training" by Aya Abdelsalam Ismail, Hector Cor
 8 Sep 22, 2022
8 Sep 22, 2022

Pre-Training 3D Point Cloud Transformers with Masked Point Modeling
Point-BERT: Pre-Training 3D Point Cloud Transformers with Masked Point Modeling Created by Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zho
 306 Jan 6, 2023
306 Jan 6, 2023
League of Legends Reinforcement Learning Environment (LoLRLE) multiple training scenarios using PPO.
League of Legends Reinforcement Learning Environment (LoLRLE) About This repo contains code to train an agent to play league of legends in a distribut
 2 Aug 19, 2022
2 Aug 19, 2022
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics.
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics. By Andres Milioto @ University of Bonn. (for the new P
 314 Dec 30, 2022
314 Dec 30, 2022
PyTorch common framework to accelerate network implementation, training and validation
pytorch-framework PyTorch common framework to accelerate network implementation, training and validation. This framework is inspired by works from MML
 3 Dec 19, 2022
3 Dec 19, 2022
Code of our paper "Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning"
CCOP Code of our paper Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning Requirement Install OpenSelfSup Install Detectron2
21 Dec 13, 2022
Single-step adversarial training (AT) has received wide attention as it proved to be both efficient and robust.
Subspace Adversarial Training Single-step adversarial training (AT) has received wide attention as it proved to be both efficient and robust. However,
 15 Sep 2, 2022
15 Sep 2, 2022
This repo contains simple to use, pretrained/training-less models for speaker diarization.
PyDiar This repo contains simple to use, pretrained/training-less models for speaker diarization. Supported Models Binary Key Speaker Modeling Based o
 12 Jan 20, 2022
12 Jan 20, 2022

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Training open neural machine translation models
Train Opus-MT models This package includes scripts for training NMT models using MarianNMT and OPUS data for OPUS-MT. More details are given in the Ma
 167 Jan 3, 2023
167 Jan 3, 2023

High performance distributed framework for training deep learning recommendation models based on PyTorch.
PERSIA (Parallel rEcommendation tRaining System with hybrId Acceleration) is developed by AI platform@Kuaishou Technology, collaborating with ETH. It
 113 Nov 28, 2021
113 Nov 28, 2021
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022
Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script.
clip-text-decoder Generate text captions for images from their CLIP embeddings. Includes PyTorch model code and example training script. Example Predi
 36 Dec 21, 2022
36 Dec 21, 2022

Make differentially private training of transformers easy for everyone
private-transformers This codebase facilitates fast experimentation of differentially private training of Hugging Face transformers. What is this? Why
 73 Dec 28, 2022
73 Dec 28, 2022
Pytorch library for end-to-end transformer models training and serving
Pytorch library for end-to-end transformer models training and serving
 768 Jan 1, 2023
768 Jan 1, 2023
Code accompanying paper: Meta-Learning to Improve Pre-Training
Meta-Learning to Improve Pre-Training This folder contains code to run experiments in the paper Meta-Learning to Improve Pre-Training, NeurIPS 2021. P
 28 Dec 31, 2022
28 Dec 31, 2022
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
105 Jan 8, 2022

YOLOv4-v3 Training Automation API for Linux
This repository allows you to get started with training a state-of-the-art Deep Learning model with little to no configuration needed! You provide your labeled dataset or label your dataset using our BMW-LabelTool-Lite and you can start the training right away and monitor it in many different ways like TensorBoard or a custom REST API and GUI. NoCode training with YOLOv4 and YOLOV3 has never been so easy.
 626 Dec 31, 2022
626 Dec 31, 2022
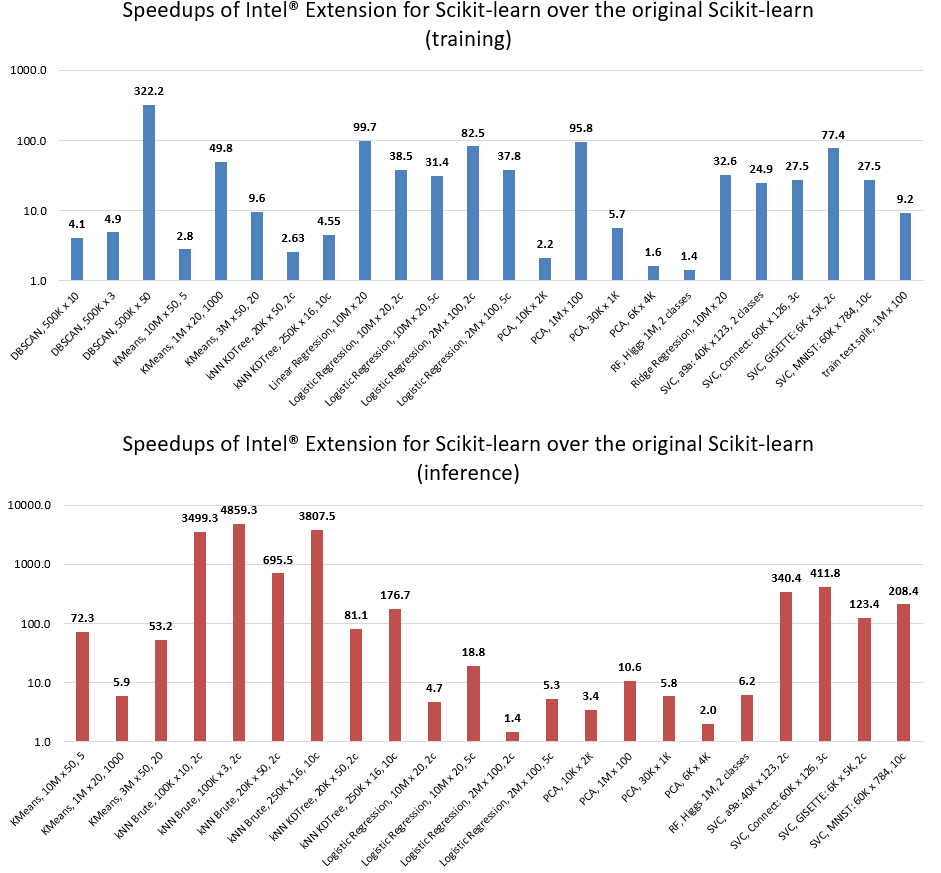
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Softlearning is a reinforcement learning framework for training maximum entropy policies in continuous domains. Includes the official implementation of the Soft Actor-Critic algorithm.
Softlearning Softlearning is a deep reinforcement learning toolbox for training maximum entropy policies in continuous domains. The implementation is
 997 Dec 30, 2022
997 Dec 30, 2022
This is a simple Tic-Tac-Toe game.
Tic-Tac-Toe Nosso famoso e tradicional Jogo da Velha, mas agora em Python. Development setup Para rodar o programa, basta instalar python em sua maqui
 1 Oct 10, 2022
1 Oct 10, 2022

Training code and evaluation benchmarks for the "Self-Supervised Policy Adaptation during Deployment" paper.
Self-Supervised Policy Adaptation during Deployment PyTorch implementation of PAD and evaluation benchmarks from Self-Supervised Policy Adaptation dur
 101 Nov 1, 2022
101 Nov 1, 2022
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification [pdf] The official repository for Self-Supervised Pre-Training for Transfo
116 Jan 4, 2023
A colab notebook for training Stylegan2-ada on colab, transfer learning onto your own dataset.
Stylegan2-Ada-Google-Colab-Starter-Notebook A no thrills colab notebook for training Stylegan2-ada on colab. transfer learning onto your own dataset h
 66 Dec 16, 2022
66 Dec 16, 2022
Code to reprudece NeurIPS paper: Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks
Accelerated Sparse Neural Training: A Provable and Efficient Method to FindN:M Transposable Masks Recently, researchers proposed pruning deep neural n
 4 Feb 23, 2022
4 Feb 23, 2022

Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
Delve is a Python package for analyzing the inference dynamics of your PyTorch model.
 73 Dec 12, 2022
73 Dec 12, 2022
fastai ulmfit - Pretraining the Language Model, Fine-Tuning and training a Classifier
fast.ai ULMFiT with SentencePiece from pretraining to deployment Motivation: Why even bother with a non-BERT / Transformer language model? Short answe
 26 May 27, 2022
26 May 27, 2022
An easy to use Natural Language Processing library and framework for predicting, training, fine-tuning, and serving up state-of-the-art NLP models.
Welcome to AdaptNLP A high level framework and library for running, training, and deploying state-of-the-art Natural Language Processing (NLP) models
 407 Jan 3, 2023
407 Jan 3, 2023
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
An Agnostic Object Detection Framework IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-q
 790 Jan 5, 2023
790 Jan 5, 2023

This is the official PyTorch implementation for "Mesa: A Memory-saving Training Framework for Transformers".
A Memory-saving Training Framework for Transformers This is the official PyTorch implementation for Mesa: A Memory-saving Training Framework for Trans
 105 Dec 6, 2022
105 Dec 6, 2022
Live training loss plot in Jupyter Notebook for Keras, PyTorch and others
livelossplot Don't train deep learning models blindfolded! Be impatient and look at each epoch of your training! (RECENT CHANGES, EXAMPLES IN COLAB, A
 1.2k Jan 8, 2023
1.2k Jan 8, 2023

 3 Nov 23, 2021
3 Nov 23, 2021