379 Repositories
Python trilium-chinese-translation Libraries
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
Chinese NER(Named Entity Recognition) using BERT(Softmax, CRF, Span)
 1.6k Jan 3, 2023
1.6k Jan 3, 2023
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
Machine Translation Implement By Bi-GRU And Transformer
Seq2Seq Translation Implement By Bidirectional GRU And Transformer In Pytorch Before You Run The Code You should download the data through the link be
 2 Oct 27, 2021
2 Oct 27, 2021
Chinese Grammatical Error Diagnosis
nlp-CGED Chinese Grammatical Error Diagnosis 中文语法纠错研究 基于序列标注的方法 所需环境 Python==3.6 tensorflow==1.14.0 keras==2.3.1 bert4keras==0.10.6 笔者使用了开源的bert4keras
 12 Nov 25, 2022
12 Nov 25, 2022
NLP-based analysis of poor Chinese movie reviews on Douban
douban_embedding 豆瓣中文影评差评分析 1. NLP NLP(Natural Language Processing)是指自然语言处理,他的目的是让计算机可以听懂人话。 下面是我将2万条豆瓣影评训练之后,随意输入一段新影评交给神经网络,最终AI推断出的结果。 "很好,演技不错
 3 Apr 15, 2022
3 Apr 15, 2022
Code for the paper "M2m: Imbalanced Classification via Major-to-minor Translation" (CVPR 2020)
M2m: Imbalanced Classification via Major-to-minor Translation This repository contains code for the paper "M2m: Imbalanced Classification via Major-to
 79 Oct 13, 2022
79 Oct 13, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
 197 Nov 26, 2022
197 Nov 26, 2022

Mengzi Pretrained Models
中文 | English Mengzi 尽管预训练语言模型在 NLP 的各个领域里得到了广泛的应用,但是其高昂的时间和算力成本依然是一个亟需解决的问题。这要求我们在一定的算力约束下,研发出各项指标更优的模型。 我们的目标不是追求更大的模型规模,而是轻量级但更强大,同时对部署和工业落地更友好的模型。
 424 Jan 4, 2023
424 Jan 4, 2023
A Collection of Papers and Codes for ICCV2021 Low Level Vision and Image Generation
A Collection of Papers and Codes for ICCV2021 Low Level Vision and Image Generation
 196 Jan 5, 2023
196 Jan 5, 2023
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 1.9.0 ubuntu20/python3.9/pip ubuntu20/python3.8/p
 5.9k Jan 4, 2023
5.9k Jan 4, 2023

LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
LOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation Tasks | Datasets | LongLM | Baselines | Paper Introduction LOT is a ben
 46 Dec 28, 2022
46 Dec 28, 2022
Code for SALT: Stackelberg Adversarial Regularization, EMNLP 2021.
SALT: Stackelberg Adversarial Regularization Code for Adversarial Regularization as Stackelberg Game: An Unrolled Optimization Approach, EMNLP 2021. R
 10 Jan 10, 2022
10 Jan 10, 2022
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
 12.9k Jan 9, 2023
12.9k Jan 9, 2023

Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision Training Efficiency We show the training efficiency of our DSLP model b
 36 Oct 31, 2022
36 Oct 31, 2022
Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision Training Efficiency We show the training efficiency of our DSLP model b
37 Jan 4, 2023

CyTran: Cycle-Consistent Transformers for Non-Contrast to Contrast CT Translation
CyTran: Cycle-Consistent Transformers for Non-Contrast to Contrast CT Translation We propose a novel approach to translate unpaired contrast computed
 13 Jan 2, 2023
13 Jan 2, 2023
Breaking the Dilemma of Medical Image-to-image Translation
Breaking the Dilemma of Medical Image-to-image Translation Supervised Pix2Pix and unsupervised Cycle-consistency are two modes that dominate the field
 7 Oct 15, 2021
7 Oct 15, 2021
Breaking the Dilemma of Medical Image-to-image Translation
Breaking the Dilemma of Medical Image-to-image Translation Supervised Pix2Pix and unsupervised Cycle-consistency are two modes that dominate the field
86 Dec 21, 2022
A PyTorch implementation of paper "Learning Shared Semantic Space for Speech-to-Text Translation", ACL (Findings) 2021
Chimera: Learning Shared Semantic Space for Speech-to-Text Translation This is a Pytorch implementation for the "Chimera" paper Learning Shared Semant
 43 Dec 28, 2022
43 Dec 28, 2022

An addon uses SMPL's poses and global translation to drive cartoon character in Blender.
Blender addon for driving character The addon drives the cartoon character by passing SMPL's poses and global translation into model's armature in Ble
 153 Dec 14, 2022
153 Dec 14, 2022
This repository is for EMNLP 2021 paper: It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpretation Data
InterpretationData This repository is for our EMNLP 2021 paper: It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpr
 4 Apr 21, 2022
4 Apr 21, 2022
Code repository for the paper "Doubly-Trained Adversarial Data Augmentation for Neural Machine Translation" with instructions to reproduce the results.
Doubly Trained Neural Machine Translation System for Adversarial Attack and Data Augmentation Languages Experimented: Data Overview: Source Target Tra
 1 Aug 18, 2022
1 Aug 18, 2022

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023

Some useful blender add-ons for SMPL skeleton's poses and global translation.
Blender add-ons for SMPL skeleton's poses and trans There are two blender add-ons for SMPL skeleton's poses and trans.The first is for making an offli
154 Jan 4, 2023

Build a translation program similar to Google Translate with Python programming language and QT library
google-translate Build a translation program similar to Google Translate with Python programming language and QT library Different parts of the progra
 3 Oct 9, 2021
3 Oct 9, 2021
Bald-to-Hairy Translation Using CycleGAN
GANiry: Bald-to-Hairy Translation Using CycleGAN Official PyTorch implementation of GANiry. GANiry: Bald-to-Hairy Translation Using CycleGAN, Fidan Sa
 10 Oct 27, 2022
10 Oct 27, 2022

Google and Stanford University released a new pre-trained model called ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants. For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA. ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
 1.2k Dec 30, 2022
1.2k Dec 30, 2022

Transfer-Learn is an open-source and well-documented library for Transfer Learning.
Transfer-Learn is an open-source and well-documented library for Transfer Learning. It is based on pure PyTorch with high performance and friendly API. Our code is pythonic, and the design is consistent with torchvision. You can easily develop new algorithms, or readily apply existing algorithms.
 2.2k Jan 3, 2023
2.2k Jan 3, 2023
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Code repo for EMNLP21 paper "Zero-Shot Information Extraction as a Unified Text-to-Triple Translation"
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation Source code repo for paper Zero-Shot Information Extraction as a Unified Text
 88 Dec 31, 2022
88 Dec 31, 2022
vits chinese, tts chinese, tts mandarin
vits chinese, tts chinese, tts mandarin 史上训练最简单,音质最好的语音合成系统
 12 Dec 14, 2022
12 Dec 14, 2022
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022
Code and data to accompany the camera-ready version of "Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation" in EMNLP 2021
Code and data to accompany the camera-ready version of "Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation" in EMNLP 2021
 16 Jul 16, 2022
16 Jul 16, 2022
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
2.7k Jan 5, 2023
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
 490 Dec 15, 2022
490 Dec 15, 2022
Code for Emergent Translation in Multi-Agent Communication
Emergent Translation in Multi-Agent Communication PyTorch implementation of the models described in the paper Emergent Translation in Multi-Agent Comm
 75 Jul 15, 2022
75 Jul 15, 2022
PyTorch Implementation of "Non-Autoregressive Neural Machine Translation"
Non-Autoregressive Transformer Code release for Non-Autoregressive Neural Machine Translation by Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K.
 261 Nov 12, 2022
261 Nov 12, 2022
pytorch implementation of Attention is all you need
A Pytorch Implementation of the Transformer: Attention Is All You Need Our implementation is largely based on Tensorflow implementation Requirements N
 230 Dec 7, 2022
230 Dec 7, 2022

StarGAN - Official PyTorch Implementation (CVPR 2018)
StarGAN - Official PyTorch Implementation ***** New: StarGAN v2 is available at https://github.com/clovaai/stargan-v2 ***** This repository provides t
 5.1k Jan 4, 2023
5.1k Jan 4, 2023
Neural machine translation between the writings of Shakespeare and modern English using TensorFlow
Shakespeare translations using TensorFlow This is an example of using the new Google's TensorFlow library on monolingual translation going from modern
 245 Dec 28, 2022
245 Dec 28, 2022
Sequence-to-Sequence learning using PyTorch
Seq2Seq in PyTorch This is a complete suite for training sequence-to-sequence models in PyTorch. It consists of several models and code to both train
 514 Nov 17, 2022
514 Nov 17, 2022

Image-to-Image Translation in PyTorch
CycleGAN and pix2pix in PyTorch New: Please check out contrastive-unpaired-translation (CUT), our new unpaired image-to-image translation model that e
 19k Jan 7, 2023
19k Jan 7, 2023

PyTorch implementation of "Image-to-Image Translation Using Conditional Adversarial Networks".
pix2pix-pytorch PyTorch implementation of Image-to-Image Translation Using Conditional Adversarial Networks. Based on pix2pix by Phillip Isola et al.
 383 Dec 17, 2022
383 Dec 17, 2022
Official pytorch implementation of "Scaling-up Disentanglement for Image Translation", ICCV 2021.
Official pytorch implementation of "Scaling-up Disentanglement for Image Translation", ICCV 2021.
 41 Nov 29, 2022
41 Nov 29, 2022
The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models
Graformer The repository for the paper: Multilingual Translation via Grafting Pre-trained Language Models Graformer (also named BridgeTransformer in t
 22 Dec 14, 2022
22 Dec 14, 2022

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation
CPT This repository contains code and checkpoints for CPT. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Gener
 341 Dec 29, 2022
341 Dec 29, 2022

An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix
An experimental Fang Song style Chinese font generated with skeleton-tracing and pix2pix, with glyphs based on cwTeXFangSong. The font is optimised fo
 98 Jan 7, 2023
98 Jan 7, 2023

DataCLUE: 国内首个以数据为中心的AI测评(含模型分析报告)
DataCLUE 以数据为中心的AI测评(DataCLUE) DataCLUE: A Chinese Data-centric Language Evaluation Benchmark 内容导引 章节 描述 简介 介绍以数据为中心的AI测评(DataCLUE)的背景 任务描述 任务描述 实验结果
 135 Dec 22, 2022
135 Dec 22, 2022
Repository for Graph2Pix: A Graph-Based Image to Image Translation Framework
Graph2Pix: A Graph-Based Image to Image Translation Framework Installation Install the dependencies in env.yml $ conda env create -f env.yml $ conda a
 18 Nov 17, 2022
18 Nov 17, 2022
This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch filtering, and new datasets for Bengali-English machine translation". It is intended to be used for normalizing / cleaning Bengali and English text.
normalizer This python module is an easy-to-use port of the text normalization used in the paper "Not low-resource anymore: Aligner ensembling, batch
 23 Nov 30, 2022
23 Nov 30, 2022
Official code of our work, AVATAR: A Parallel Corpus for Java-Python Program Translation.
AVATAR Official code of our work, AVATAR: A Parallel Corpus for Java-Python Program Translation. AVATAR stands for jAVA-pyThon progrAm tRanslation. AV
 26 Dec 3, 2022
26 Dec 3, 2022

codes for "Scheduled Sampling Based on Decoding Steps for Neural Machine Translation" (long paper of EMNLP-2022)
Scheduled Sampling Based on Decoding Steps for Neural Machine Translation (EMNLP-2021 main conference) Contents Overview Background Quick to Use Furth
 13 Jul 25, 2022
13 Jul 25, 2022

Application for shadowing Chinese.
chinese-shadowing Simple APP for shadowing chinese. With this application, it is very easy to record yourself, play the sound recorded and listen to s
 5 Sep 6, 2022
5 Sep 6, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task
DomainWordsDict, Chinese words dict that contains more than 68 domains, which can be used as text classification、knowledge enhance task。涵盖68个领域、共计916万词的专业词典知识库,可用于文本分类、知识增强、领域词汇库扩充等自然语言处理应用。
 357 Dec 24, 2022
357 Dec 24, 2022
Sequence-to-Sequence learning using PyTorch
Seq2Seq in PyTorch This is a complete suite for training sequence-to-sequence models in PyTorch. It consists of several models and code to both train
514 Nov 17, 2022

Unsupervised Image-to-Image Translation
UNIT: UNsupervised Image-to-image Translation Networks Imaginaire Repository We have a reimplementation of the UNIT method that is more performant. It
 1.9k Dec 26, 2022
1.9k Dec 26, 2022
Python library for the DeepL language translation API.
The DeepL API is a language translation API that allows other computer programs to send texts and documents to DeepL's servers and receive high-quality translations. This opens a whole universe of opportunities for developers: any translation product you can imagine can now be built on top of DeepL's best-in-class translation technology.
 535 Jan 4, 2023
535 Jan 4, 2023
"Reinforcement Learning for Bandit Neural Machine Translation with Simulated Human Feedback"
This is code repo for our EMNLP 2017 paper "Reinforcement Learning for Bandit Neural Machine Translation with Simulated Human Feedback", which implements the A2C algorithm on top of a neural encoder-decoder model and benchmarks the combination under simulated noisy rewards.
 131 Oct 21, 2022
131 Oct 21, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022

A demo for end-to-end English and Chinese text spotting using ABCNet.
ABCNet_Chinese A demo for end-to-end English and Chinese text spotting using ABCNet. This is an old model that was trained a long ago, which serves as
 45 Oct 4, 2022
45 Oct 4, 2022

Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021
Contrastive Learning for Many-to-many Multilingual Neural Machine Translation(mCOLT/mRASP2), ACL2021 The code for training mCOLT/mRASP2, a multilingua
 104 Jan 1, 2023
104 Jan 1, 2023
pydantic-i18n is an extension to support an i18n for the pydantic error messages.
pydantic-i18n is an extension to support an i18n for the pydantic error messages
 48 Dec 21, 2022
48 Dec 21, 2022

A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
 106 Dec 29, 2022
106 Dec 29, 2022
Universal End2End Training Platform, including pre-training, classification tasks, machine translation, and etc.
背景 安装教程 快速上手 (一)预训练模型 (二)机器翻译 (三)文本分类 TenTrans 进阶 1. 多语言机器翻译 2. 跨语言预训练 背景 TrenTrans是一个统一的端到端的多语言多任务预训练平台,支持多种预训练方式,以及序列生成和自然语言理解任务。 安装教程 git clone git
 42 Dec 20, 2022
42 Dec 20, 2022

Chinese real time voice cloning (VC) and Chinese text to speech (TTS).
Chinese real time voice cloning (VC) and Chinese text to speech (TTS). 好用的中文语音克隆兼中文语音合成系统,包含语音编码器、语音合成器、声码器和可视化模块。
 6 Nov 8, 2022
6 Nov 8, 2022

Image Deblurring using Generative Adversarial Networks
DeblurGAN arXiv Paper Version Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. Our netwo
 2.2k Jan 1, 2023
2.2k Jan 1, 2023
StarGAN - Official PyTorch Implementation
StarGAN - Official PyTorch Implementation ***** New: StarGAN v2 is available at https://github.com/clovaai/stargan-v2 ***** This repository provides t
5.1k Dec 30, 2022

Synthesizing and manipulating 2048x1024 images with conditional GANs
pix2pixHD Project | Youtube | Paper Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic image-to-image translatio
 6k Dec 27, 2022
6k Dec 27, 2022
pytorch implementation of Attention is all you need
A Pytorch Implementation of the Transformer: Attention Is All You Need Our implementation is largely based on Tensorflow implementation Requirements N
230 Dec 7, 2022
PyTorch Implementation of "Non-Autoregressive Neural Machine Translation"
Non-Autoregressive Transformer Code release for Non-Autoregressive Neural Machine Translation by Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K.
261 Nov 12, 2022
Code for Emergent Translation in Multi-Agent Communication
Emergent Translation in Multi-Agent Communication PyTorch implementation of the models described in the paper Emergent Translation in Multi-Agent Comm
75 Jul 15, 2022

Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic video-to-video translation.
vid2vid Project | YouTube(short) | YouTube(full) | arXiv | Paper(full) Pytorch implementation for high-resolution (e.g., 2048x1024) photorealistic vid
8.1k Jan 1, 2023
Pervasive Attention: 2D Convolutional Networks for Sequence-to-Sequence Prediction
This is a fork of Fairseq(-py) with implementations of the following models: Pervasive Attention - 2D Convolutional Neural Networks for Sequence-to-Se
490 Dec 15, 2022
Implementation of "Glancing Transformer for Non-Autoregressive Neural Machine Translation"
GLAT Implementation for the ACL2021 paper "Glancing Transformer for Non-Autoregressive Neural Machine Translation" Requirements Python = 3.7 Pytorch
 117 Jan 9, 2023
117 Jan 9, 2023
Write Python in Urdu - اردو میں کوڈ لکھیں
UrduPython Write simple Python in Urdu. How to Use Write Urdu code in سامپل۔پے The mappings are as following: "۔": ".", "،":
 26 Nov 27, 2022
26 Nov 27, 2022

ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information This repository contains code, model, dataset for ChineseBERT at ACL2021. Ch
 413 Dec 1, 2022
413 Dec 1, 2022
Code for paper "Vocabulary Learning via Optimal Transport for Neural Machine Translation"
**Codebase and data are uploaded in progress. ** VOLT(-py) is a vocabulary learning codebase that allows researchers and developers to automaticaly ge
 416 Jan 9, 2023
416 Jan 9, 2023

Translation for Trilium Notes. Trilium Notes 中文版.
Trilium Translation 中文说明 This repo provides a translation for the awesome Trilium Notes. Currently, I have translated Trilium Notes into Chinese. Test
 743 Jan 8, 2023
743 Jan 8, 2023

Official PyTorch implementation of the preprint paper "Stylized Neural Painting", accepted to CVPR 2021.
Official PyTorch implementation of the preprint paper "Stylized Neural Painting", accepted to CVPR 2021.
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
Code for the paper "Balancing Training for Multilingual Neural Machine Translation, ACL 2020"
Balancing Training for Multilingual Neural Machine Translation Implementation of the paper Balancing Training for Multilingual Neural Machine Translat
 21 May 18, 2022
21 May 18, 2022
Kaggle | 9th place (part of) solution for the Bristol-Myers Squibb – Molecular Translation challenge
Part of the 9th place solution for the Bristol-Myers Squibb – Molecular Translation challenge translating images containing chemical structures into I
 22 Nov 30, 2022
22 Nov 30, 2022
Source code for the paper "PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction" in ACL2021
PLOME:Pre-training with Misspelled Knowledge for Chinese Spelling Correction (ACL2021) This repository provides the code and data of the work in ACL20
197 Nov 26, 2022
SIMULEVAL A General Evaluation Toolkit for Simultaneous Translation
SimulEval SimulEval is a general evaluation framework for simultaneous translation on text and speech. Requirement python = 3.7.0 Installation git cl
48 Dec 28, 2022
A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
106 Dec 29, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
99 Dec 23, 2022
![[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data](https://github.com/michiyasunaga/BIFI/raw/main/figs/task.png)
[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data
Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data This repo provides the source code & data of our paper: Break-It-Fix-It: Unsupervised
 86 Nov 30, 2022
86 Nov 30, 2022
Spatially-Adaptive Pixelwise Networks for Fast Image Translation, CVPR 2021
Image Translation with ASAPNets Spatially-Adaptive Pixelwise Networks for Fast Image Translation, CVPR 2021 Webpage | Paper | Video Installation insta
 100 Dec 28, 2022
100 Dec 28, 2022
Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021)
UNITE and UNITE+ Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021) Unbalanced Intrinsic Feature Transport for Exemplar-bas
 183 Nov 9, 2022
183 Nov 9, 2022

A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
GuwenModels: 古文自然语言处理模型合集, 收录互联网上的古文相关模型及资源. A collection of Classical Chinese natural language processing models, including Classical Chinese related models and resources on the Internet.
 66 Dec 26, 2022
66 Dec 26, 2022
Your missing PO formatter and linter
pofmt Your missing PO formatter and linter Features Wrap msgid and msgstr with a constant max width. Can act as a pre-commit hook. Display lint errors
 5 Mar 22, 2022
5 Mar 22, 2022
A Django chatbot that is capable of doing math and searching Chinese poet online. Developed with django, channels, celery and redis.
Django Channels Websocket Chatbot A Django chatbot that is capable of doing math and searching Chinese poet online. Developed with django, channels, c
 8 Oct 28, 2022
8 Oct 28, 2022
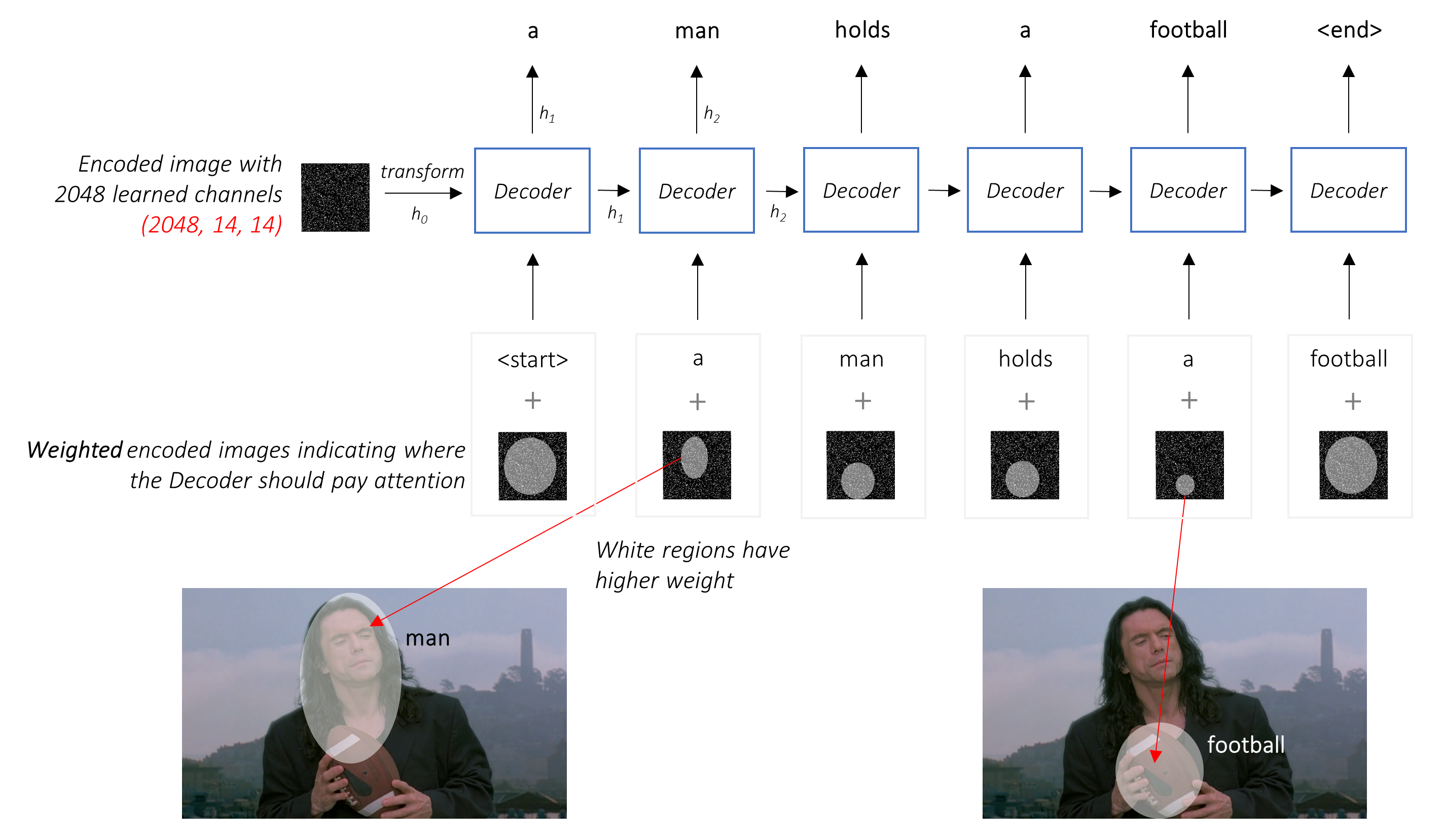
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

This is the PyTorch implementation of GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation
Official PyTorch repo for GAN's N' Roses. Diverse im2im and vid2vid selfie to anime translation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023
Easy-to-use CPM for Chinese text generation
CPM 项目描述 CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂
 382 Jan 7, 2023
382 Jan 7, 2023
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022
多语言降噪预训练模型MBart的中文生成任务
mbart-chinese 基于mbart-large-cc25 的中文生成任务 Input source input: text + /s + lang_code target input: lang_code + text + /s Usage token_ids_mapping.jso
 11 Sep 19, 2022
11 Sep 19, 2022