1250 Repositories
Python video-generation Libraries

This is an official implementation for "Video Swin Transformers".
Video Swin Transformer By Ze Liu*, Jia Ning*, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin and Han Hu. This repo is the official implementation of "V
 981 Jan 3, 2023
981 Jan 3, 2023

Code for "LASR: Learning Articulated Shape Reconstruction from a Monocular Video". CVPR 2021.
LASR Installation Build with conda conda env create -f lasr.yml conda activate lasr # install softras cd third_party/softras; python setup.py install;
 157 Dec 26, 2022
157 Dec 26, 2022
The implementation of CVPR2021 paper Temporal Query Networks for Fine-grained Video Understanding, by Chuhan Zhang, Ankush Gupta and Andrew Zisserman.
Temporal Query Networks for Fine-grained Video Understanding 📋 This repository contains the implementation of CVPR2021 paper Temporal_Query_Networks
 55 Dec 21, 2022
55 Dec 21, 2022

Towards Long-Form Video Understanding
Towards Long-Form Video Understanding Chao-Yuan Wu, Philipp Krähenbühl, CVPR 2021 [Paper] [Project Page] [Dataset] Citation @inproceedings{lvu2021,
 69 Dec 26, 2022
69 Dec 26, 2022

Cartoon-StyleGan2 🙃 : Fine-tuning StyleGAN2 for Cartoon Face Generation
Fine-tuning StyleGAN2 for Cartoon Face Generation
 520 Jan 4, 2023
520 Jan 4, 2023

Senginta is All in one Search Engine Scrapper for used by API or Python Module. It's Free!
Senginta is All in one Search Engine Scrapper. With traditional scrapping, Senginta can be powerful to get result from any Search Engine, and convert to Json. Now support only for Google Product Search Engine (GShop, GVideo and many too) and Baidu Search Engine.
 33 Nov 21, 2022
33 Nov 21, 2022
VIMPAC: Video Pre-Training via Masked Token Prediction and Contrastive Learning
This is a release of our VIMPAC paper to illustrate the implementations. The pretrained checkpoints and scripts will be soon open-sourced in HuggingFace transformers.
 74 Dec 3, 2022
74 Dec 3, 2022
This is the dataset and code release of the OpenRooms Dataset.
This is the dataset and code release of the OpenRooms Dataset.
 95 Jan 8, 2023
95 Jan 8, 2023
pygamevideo module helps developer to embed videos into their Pygame display
pygamevideo module helps developer to embed videos into their Pygame display. Audio playback doesn't use pygame.mixer.
 10 Dec 28, 2022
10 Dec 28, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

Code for our ACL 2021 paper "One2Set: Generating Diverse Keyphrases as a Set"
One2Set This repository contains the code for our ACL 2021 paper “One2Set: Generating Diverse Keyphrases as a Set”. Our implementation is built on the
 63 Jan 5, 2023
63 Jan 5, 2023

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022

CT-Net: Channel Tensorization Network for Video Classification
[ICLR2021] CT-Net: Channel Tensorization Network for Video Classification @inproceedings{ li2021ctnet, title={{\{}CT{\}}-Net: Channel Tensorization Ne
 33 Nov 15, 2022
33 Nov 15, 2022
Code for papers "Generation-Augmented Retrieval for Open-Domain Question Answering" and "Reader-Guided Passage Reranking for Open-Domain Question Answering", ACL 2021
This repo provides the code of the following papers: (GAR) "Generation-Augmented Retrieval for Open-domain Question Answering", ACL 2021 (RIDER) "Read
 49 Dec 26, 2022
49 Dec 26, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
 4.6k Jan 9, 2023
4.6k Jan 9, 2023
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. Training python train.py --c
 55 Dec 26, 2022
55 Dec 26, 2022

Creates a landscape with more accurate river generation in Minecraft version 1.12 using python.
MinecraftLandRiverGen View the following youtube video to set up a world that can interact with the python programs
 23 Dec 25, 2022
23 Dec 25, 2022

This is the official repository of XVFI (eXtreme Video Frame Interpolation)
XVFI This is the official repository of XVFI (eXtreme Video Frame Interpolation), https://arxiv.org/abs/2103.16206 Last Update: 20210607 We provide th
 195 Dec 29, 2022
195 Dec 29, 2022
Easy-to-use CPM for Chinese text generation
CPM 项目描述 CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B,用户需申请与通过审核,方可下载。 由于原项目需要考虑大模型的训练和使用,需要安装较为复杂
 382 Jan 7, 2023
382 Jan 7, 2023
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
544 Dec 19, 2022
Code for our paper "Transfer Learning for Sequence Generation: from Single-source to Multi-source" in ACL 2021.
TRICE: a task-agnostic transferring framework for multi-source sequence generation This is the source code of our work Transfer Learning for Sequence
 9 Jun 27, 2022
9 Jun 27, 2022

A denoising diffusion probabilistic model (DDPM) tailored for conditional generation of protein distograms
Denoising Diffusion Probabilistic Model for Proteins Implementation of Denoising Diffusion Probabilistic Model in Pytorch. It is a new approach to gen
 108 Nov 23, 2022
108 Nov 23, 2022
A Telegram Video Merge Bot by @AbirHasan2005
VideoMerge-Bot This is very simple Telegram Videos Merge Bot by @AbirHasan2005. Using FFmpeg for Merging Videos. Features: Merge Multiple Videos. User
 57 Nov 12, 2022
57 Nov 12, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
 140 Dec 21, 2022
140 Dec 21, 2022

A lightweight deep network for fast and accurate optical flow estimation.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation The official PyTorch implementation of FastFlowNet (ICRA 2021). Authors: Lingtong
 161 Jan 3, 2023
161 Jan 3, 2023
Towards End-to-end Video-based Eye Tracking
Towards End-to-end Video-based Eye Tracking The code accompanying our ECCV 2020 publication and dataset, EVE. Authors: Seonwook Park, Emre Aksan, Xuco
 76 Dec 12, 2022
76 Dec 12, 2022

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
 308 Dec 7, 2022
308 Dec 7, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file
Vehicle Identification Speed Detection (VISD) extracts vehicle information like License Plate number, Manufacturer and colour from a video and provides this data in the form of a CSV file. VISD can also perform vehicle speed detection on a video. All these features of VSID are provided to the user using a Web Application which is created using Flask
 6 Feb 22, 2022
6 Feb 22, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023
To automate the generation and validation tests of COSE/CBOR Codes and it's base45/2D Code representations
To automate the generation and validation tests of COSE/CBOR Codes and it's base45/2D Code representations, a lot of data has to be collected to ensure the variance of the tests. This respository was established to collect a lot of different test data and related test cases of different member states in a standardized manner. Each member state can generate a folder in this section.
 160 Jul 25, 2022
160 Jul 25, 2022
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022

Codes for ACL-IJCNLP 2021 Paper "Zero-shot Fact Verification by Claim Generation"
Zero-shot-Fact-Verification-by-Claim-Generation This repository contains code and models for the paper: Zero-shot Fact Verification by Claim Generatio
 47 Jan 1, 2023
47 Jan 1, 2023

Fine-Tune EleutherAI GPT-Neo to Generate Netflix Movie Descriptions in Only 47 Lines of Code Using Hugginface And DeepSpeed
GPT-Neo-2.7B Fine-Tuning Example Using HuggingFace & DeepSpeed Installation cd venv/bin ./pip install -r ../../requirements.txt ./pip install deepspe
 180 Jan 5, 2023
180 Jan 5, 2023
HatSploit native powerful payload generation and shellcode injection tool that provides support for common platforms and architectures.
HatVenom HatSploit native powerful payload generation and shellcode injection tool that provides support for common platforms and architectures. Featu
 100 Dec 23, 2022
100 Dec 23, 2022
Pynguin, The PYthoN General UnIt Test geNerator is a test-generation tool for Python
Pynguin, the PYthoN General UnIt test geNerator, is a tool that allows developers to generate unit tests automatically.
 997 Jan 6, 2023
997 Jan 6, 2023

Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
Avatarify Python - Avatars for Zoom, Skype and other video-conferencing apps.
 15.3k Jan 5, 2023
15.3k Jan 5, 2023

Self-Learned Video Rain Streak Removal: When Cyclic Consistency Meets Temporal Correspondence
In this paper, we address the problem of rain streaks removal in video by developing a self-learned rain streak removal method, which does not require any clean groundtruth images in the training process.
 44 Dec 6, 2022
44 Dec 6, 2022
NExT-QA: Next Phase of Question-Answering to Explaining Temporal Actions (CVPR2021)
NExT-QA We reproduce some SOTA VideoQA methods to provide benchmark results for our NExT-QA dataset accepted to CVPR2021 (with 1 'Strong Accept' and 2
 50 Nov 24, 2022
50 Nov 24, 2022

BoobSnail allows generating Excel 4.0 XLM macro. Its purpose is to support the RedTeam and BlueTeam in XLM macro generation.
Follow us on Twitter! BoobSnail BoobSnail allows generating XLM (Excel 4.0) macro. Its purpose is to support the RedTeam and BlueTeam in XLM macro gen
 232 Nov 21, 2022
232 Nov 21, 2022
Github project for Attention-guided Temporal Coherent Video Object Matting.
Attention-guided Temporal Coherent Video Object Matting This is the Github project for our paper Attention-guided Temporal Coherent Video Object Matti
 71 Dec 19, 2022
71 Dec 19, 2022

Official implementation of the network presented in the paper "M4Depth: A motion-based approach for monocular depth estimation on video sequences"
M4Depth This is the reference TensorFlow implementation for training and testing depth estimation models using the method described in M4Depth: A moti
 76 Jan 3, 2023
76 Jan 3, 2023

Efficient 6-DoF Grasp Generation in Cluttered Scenes
Contact-GraspNet Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes Martin Sundermeyer, Arsalan Mousavian, Rudolph Triebel, Dieter
 148 Dec 28, 2022
148 Dec 28, 2022

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022

SiamMOT is a region-based Siamese Multi-Object Tracking network that detects and associates object instances simultaneously.
SiamMOT: Siamese Multi-Object Tracking
 432 Dec 17, 2022
432 Dec 17, 2022
Music and video downloader, Made with love by Bryan Herrera
Python-Mp3Mp4-Downloader Music and video downloader, Made with love by Bryan Herrera Requirements CHOCOLATELY windows command If your system does not
 104 Dec 27, 2022
104 Dec 27, 2022
TikTok X-Gorgon & X-Khronos Generation Algorithm
TikTok X-Gorgon & X-Khronos Generation Algorithm X-Gorgon and X-Khronos headers are required to call tiktok api. I will provide you API as rental or s
 31 Dec 1, 2022
31 Dec 1, 2022
Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification"
hypergraph_reid Implementation of "Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification" If you find this help your research,
 62 Dec 21, 2022
62 Dec 21, 2022
The implemention of Video Depth Estimation by Fusing Flow-to-Depth Proposals
Flow-to-depth (FDNet) video-depth-estimation This is the implementation of paper Video Depth Estimation by Fusing Flow-to-Depth Proposals Jiaxin Xie,
 32 Jun 14, 2022
32 Jun 14, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
 225 Dec 25, 2022
225 Dec 25, 2022

Code for ECCV 2020 paper "Contacts and Human Dynamics from Monocular Video".
Contact and Human Dynamics from Monocular Video This is the official implementation for the ECCV 2020 spotlight paper by Davis Rempe, Leonidas J. Guib
 207 Jan 5, 2023
207 Jan 5, 2023
Inference code for "StylePeople: A Generative Model of Fullbody Human Avatars" paper. This code is for the part of the paper describing video-based avatars.
NeuralTextures This is repository with inference code for paper "StylePeople: A Generative Model of Fullbody Human Avatars" (CVPR21). This code is for
 18 Oct 6, 2022
18 Oct 6, 2022

Text to Image Generation with Semantic-Spatial Aware GAN
text2image This repository includes the implementation for Text to Image Generation with Semantic-Spatial Aware GAN This repo is not completely. Netwo
 124 Dec 30, 2022
124 Dec 30, 2022
A Telegram bot to convert videos into x265/x264 format via ffmpeg.
Video Encoder Bot A Telegram bot to convert videos into x265/x264 format via ffmpeg. Configuration Add values in environment variables or add them in
 82 Jan 3, 2023
82 Jan 3, 2023
Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21'
Argument Extraction by Generation Code for paper "Document-Level Argument Extraction by Conditional Generation". NAACL 21' Dependencies pytorch=1.6 tr
 87 Dec 26, 2022
87 Dec 26, 2022
Deep learning (neural network) based remote photoplethysmography: how to extract pulse signal from video using deep learning tools
Deep-rPPG: Camera-based pulse estimation using deep learning tools Deep learning (neural network) based remote photoplethysmography: how to extract pu
 138 Dec 17, 2022
138 Dec 17, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
 135 Dec 28, 2022
135 Dec 28, 2022
Multi-Track Music Generation with the Transfomer and the Johann Sebastian Bach Chorales dataset
MMM: Exploring Conditional Multi-Track Music Generation with the Transformer and the Johann Sebastian Bach Chorales Dataset. Implementation of the pap
 102 Dec 8, 2022
102 Dec 8, 2022

Code for paper 'Audio-Driven Emotional Video Portraits'.
Audio-Driven Emotional Video Portraits [CVPR2021] Xinya Ji, Zhou Hang, Kaisiyuan Wang, Wayne Wu, Chen Change Loy, Xun Cao, Feng Xu [Project] [Paper] G
 197 Dec 31, 2022
197 Dec 31, 2022

QueryInst: Parallelly Supervised Mask Query for Instance Segmentation
QueryInst is a simple and effective query based instance segmentation method driven by parallel supervision on dynamic mask heads, which outperforms previous arts in terms of both accuracy and speed.
 386 Jan 8, 2023
386 Jan 8, 2023

Code for "ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on", accepted at WACV 2021 Generation of Human Behavior Workshop.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on [ Paper ] [ Project Page ] This repository contains the code fo
 97 Dec 13, 2022
97 Dec 13, 2022
![[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior](https://github.com/yzxing87/pytorch-deep-video-prior/raw/main/example/example_in.gif)
[NeurIPS 2020] Blind Video Temporal Consistency via Deep Video Prior
pytorch-deep-video-prior (DVP) Official PyTorch implementation for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior TensorFlo
 90 Oct 19, 2022
90 Oct 19, 2022

DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control
DeepFaceEditing: Deep Face Generation and Editing with Disentangled Geometry and Appearance Control One version of our system is implemented using the
 260 Nov 28, 2022
260 Nov 28, 2022

The pytorch implementation of DG-Font: Deformable Generative Networks for Unsupervised Font Generation
DG-Font: Deformable Generative Networks for Unsupervised Font Generation The source code for 'DG-Font: Deformable Generative Networks for Unsupervised
 130 Dec 5, 2022
130 Dec 5, 2022
Word2Wave: a framework for generating short audio samples from a text prompt using WaveGAN and COALA.
Word2Wave is a simple method for text-controlled GAN audio generation. You can either follow the setup instructions below and use the source code and CLI provided in this repo or you can have a play around in the Colab notebook provided. Note that, in both cases, you will need to train a WaveGAN model first
 91 Dec 23, 2022
91 Dec 23, 2022
Awesome Video Datasets
Awesome Video Datasets
 462 Jan 2, 2023
462 Jan 2, 2023

Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models
Parrot is a paraphrase based utterance augmentation framework purpose built to accelerate training NLU models. A paraphrase framework is more than just a paraphrasing model.
 681 Jan 1, 2023
681 Jan 1, 2023
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022
An implementation of WaveNet with fast generation
pytorch-wavenet This is an implementation of the WaveNet architecture, as described in the original paper. Features Automatic creation of a dataset (t
 858 Dec 27, 2022
858 Dec 27, 2022

A simple command line tool for text to image generation, using OpenAI's CLIP and a BigGAN.
Ryan Murdock has done it again, combining OpenAI's CLIP and the generator from a BigGAN! This repository wraps up his work so it is easily accessible to anyone who owns a GPU.
2.3k Jan 9, 2023
An easier way to build neural search on the cloud
Jina is geared towards building search systems for any kind of data, including text, images, audio, video and many more. With the modular design & multi-layer abstraction, you can leverage the efficient patterns to build the system by parts, or chaining them into a Flow for an end-to-end experience.
17k Jan 1, 2023

DeepMetaHandles: Learning Deformation Meta-Handles of 3D Meshes with Biharmonic Coordinates
DeepMetaHandles (CVPR2021 Oral) [paper] [animations] DeepMetaHandles is a shape deformation technique. It learns a set of meta-handles for each given
 73 Dec 15, 2022
73 Dec 15, 2022
A Distributional Approach To Controlled Text Generation
A Distributional Approach To Controlled Text Generation This is the repository code for the ICLR 2021 paper "A Distributional Approach to Controlled T
 102 Jan 7, 2023
102 Jan 7, 2023
Text Generation by Learning from Demonstrations
Text Generation by Learning from Demonstrations The README was last updated on March 7, 2021. The repo is based on fairseq (v0.9.?). Paper arXiv Prere
 38 Oct 21, 2022
38 Oct 21, 2022
[EMNLP 2020] Keep CALM and Explore: Language Models for Action Generation in Text-based Games
Contextual Action Language Model (CALM) and the ClubFloyd Dataset Code and data for paper Keep CALM and Explore: Language Models for Action Generation
 43 Dec 16, 2022
43 Dec 16, 2022
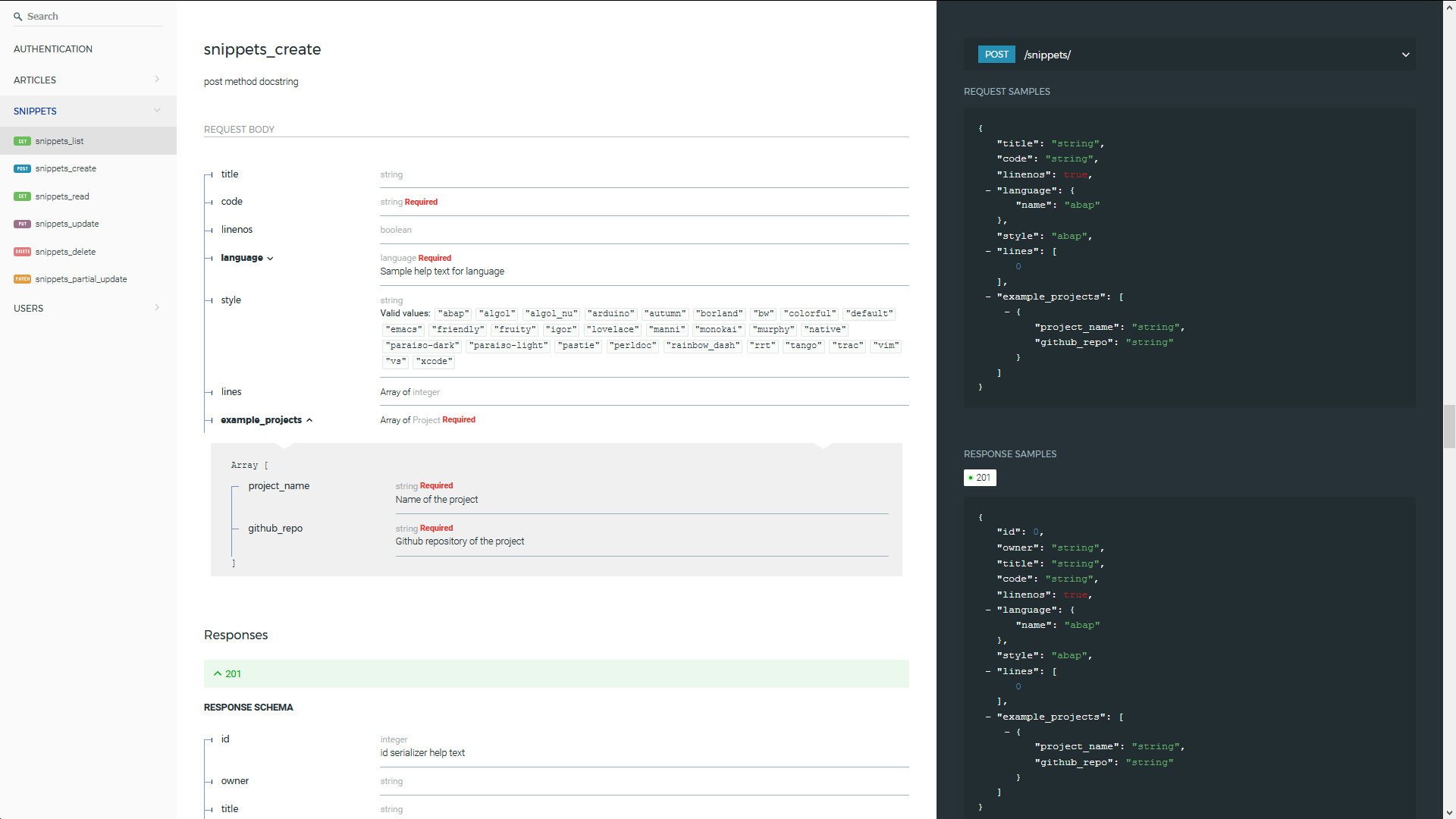
Automated generation of real Swagger/OpenAPI 2.0 schemas from Django REST Framework code.
drf-yasg - Yet another Swagger generator Generate real Swagger/OpenAPI 2.0 specifications from a Django Rest Framework API. Compatible with Django Res
 3k Jan 6, 2023
3k Jan 6, 2023

A simple image/video to Desmos graph converter run locally
Desmos Bezier Renderer A simple image/video to Desmos graph converter run locally Sample Result Setup Install dependencies apt update apt install git
 339 Dec 23, 2022
339 Dec 23, 2022

All in one Search Engine Scrapper for used by API or Python Module. It's Free!
All in one Search Engine Scrapper for used by API or Python Module. How to use: Video Documentation Senginta is All in one Search Engine Scrapper. Wit
33 Nov 21, 2022
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
 2.5k Jan 3, 2023
2.5k Jan 3, 2023
Pytorch implementation of CoCon: A Self-Supervised Approach for Controlled Text Generation
COCON_ICLR2021 This is our Pytorch implementation of COCON. CoCon: A Self-Supervised Approach for Controlled Text Generation (ICLR 2021) Alvin Chan, Y
 79 Dec 18, 2022
79 Dec 18, 2022
Implementation of "Efficient Regional Memory Network for Video Object Segmentation" (Xie et al., CVPR 2021).
RMNet This repository contains the source code for the paper Efficient Regional Memory Network for Video Object Segmentation. Cite this work @inprocee
 76 Dec 14, 2022
76 Dec 14, 2022
[CVPR 2021] MiVOS - Mask Propagation module. Reproduced STM (and better) with training code :star2:. Semi-supervised video object segmentation evaluation.
MiVOS (CVPR 2021) - Mask Propagation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [arXiv] [Paper PDF] [Project Page] [Papers with Code] This repo impleme
106 Jan 3, 2023

Official Pytorch implementation of "Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video", CVPR 2021
TCMR: Beyond Static Features for Temporally Consistent 3D Human Pose and Shape from a Video Qualtitative result Paper teaser video Introduction This r
 215 Jan 6, 2023
215 Jan 6, 2023
Code for "Graph-Evolving Meta-Learning for Low-Resource Medical Dialogue Generation". [AAAI 2021]
Graph Evolving Meta-Learning for Low-resource Medical Dialogue Generation Code to be further cleaned... This repo contains the code of the following p
 29 Nov 1, 2022
29 Nov 1, 2022
Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021, Pytorch)
S2VD Semi-supervised Video Deraining with Dynamical Rain Generator (CVPR, 2021) Requirements and Dependencies Ubuntu 16.04, cuda 10.0 Python 3.6.10, P
 53 Nov 23, 2022
53 Nov 23, 2022
This is a simple collection of instructions and scripts to accompany the computerphile video about mininet and openflow.
How to get going. This project should work on Linux or MacOS. I used Ubuntu 20.04 and provide some notes here. Note, this is certainly not intended as
 70 Jan 2, 2023
70 Jan 2, 2023

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023
[TIP2020] Adaptive Graph Representation Learning for Video Person Re-identification
Introduction This is the PyTorch implementation for Adaptive Graph Representation Learning for Video Person Re-identification. Get started git clone h
 41 Dec 12, 2022
41 Dec 12, 2022
The official pytorch implemention of the CVPR paper "Temporal Modulation Network for Controllable Space-Time Video Super-Resolution".
This is the official PyTorch implementation of TMNet in the CVPR 2021 paper "Temporal Modulation Network for Controllable Space-Time VideoSuper-Resolu
 95 Oct 24, 2022
95 Oct 24, 2022

Code for Dual Contrastive Learning for Unsupervised Image-to-Image Translation, NTIRE, CVPRW 2021.
arXiv Dual Contrastive Learning Adversarial Generative Networks (DCLGAN) We provide our PyTorch implementation of DCLGAN, which is a simple yet powerf
 119 Dec 4, 2022
119 Dec 4, 2022

FID calculation with proper image resizing and quantization steps
clean-fid: Fixing Inconsistencies in FID Project | Paper The FID calculation involves many steps that can produce inconsistencies in the final metric.
 606 Jan 6, 2023
606 Jan 6, 2023

Training code of Spatial Time Memory Network. Semi-supervised video object segmentation.
Training-code-of-STM This repository fully reproduces Space-Time Memory Networks Performance on Davis17 val set&Weights backbone training stage traini
 128 Dec 11, 2022
128 Dec 11, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
Syntax-Aware Action Targeting for Video Captioning
Syntax-Aware Action Targeting for Video Captioning Code for SAAT from "Syntax-Aware Action Targeting for Video Captioning" (Accepted to CVPR 2020). Th
 59 Oct 13, 2022
59 Oct 13, 2022

TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks
TSP: Temporally-Sensitive Pretraining of Video Encoders for Localization Tasks [Paper] [Project Website] This repository holds the source code, pretra
 83 Dec 21, 2022
83 Dec 21, 2022