940 Repositories
Python video-to-audio Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

Official code for CVPR2022 paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
📖 Depth-Aware Generative Adversarial Network for Talking Head Video Generation (CVPR 2022) 🔥 If DaGAN is helpful in your photos/projects, please hel
 503 Jan 4, 2023
503 Jan 4, 2023

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023

Official code for "Towards An End-to-End Framework for Flow-Guided Video Inpainting" (CVPR2022)
E2FGVI (CVPR 2022) English | 简体中文 This repository contains the official implementation of the following paper: Towards An End-to-End Framework for Flo
 537 Jan 7, 2023
537 Jan 7, 2023
Official repository of "BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment"
BasicVSR_PlusPlus (CVPR 2022) [Paper] [Project Page] [Code] This is the official repository for BasicVSR++. Please feel free to raise issue related to
 227 Jan 1, 2023
227 Jan 1, 2023

Dataset and baseline code for the VocalSound dataset (ICASSP2022).
VocalSound: A Dataset for Improving Human Vocal Sounds Recognition Introduction Citing Download VocalSound Dataset Details Baseline Experiment Contact
 58 Jan 3, 2023
58 Jan 3, 2023

A lightweight yet powerful audio-to-MIDI converter with pitch bend detection
Basic Pitch is a Python library for Automatic Music Transcription (AMT), using lightweight neural network developed by Spotify's Audio Intelligence La
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
Video Frame Interpolation with Transformer (CVPR2022)
VFIformer Official PyTorch implementation of our CVPR2022 paper Video Frame Interpolation with Transformer Dependencies python = 3.8 pytorch = 1.8.0
 63 Dec 16, 2022
63 Dec 16, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022
HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools
HuggingSound HuggingSound: A toolkit for speech-related tasks based on HuggingFace's tools. I have no intention of building a very complex tool here.
 247 Dec 26, 2022
247 Dec 26, 2022
[CVPR 2022] Official PyTorch Implementation for "Reference-based Video Super-Resolution Using Multi-Camera Video Triplets"
Reference-based Video Super-Resolution (RefVSR) Official PyTorch Implementation of the CVPR 2022 Paper Project | arXiv | RealMCVSR Dataset This repo c
 151 Dec 30, 2022
151 Dec 30, 2022
Telegram Group Calls Streaming bot with some useful features, written in Python with Pyrogram and Py-Tgcalls. Supporting platforms like Youtube, Spotify, Resso, AppleMusic, Soundcloud and M3u8 Links.
Yukki Music Bot Yukki Music Bot is a Powerful Telegram Music+Video Bot written in Python using Pyrogram and Py-Tgcalls by which you can stream songs,
 996 Dec 28, 2022
996 Dec 28, 2022
HF's ML for Audio study group
Hugging Face Machine Learning for Audio Study Group Welcome to the ML for Audio Study Group. Through a series of presentations, paper reading and disc
 110 Jan 1, 2023
110 Jan 1, 2023
A Traffic Sign Recognition Project which can help the driver recognise the signs via text as well as audio. Can be used at Night also.
Traffic-Sign-Recognition In this report, we propose a Convolutional Neural Network(CNN) for traffic sign classification that achieves outstanding perf
 64 Nov 19, 2022
64 Nov 19, 2022

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023

Official Implementation of "Third Time's the Charm? Image and Video Editing with StyleGAN3" https://arxiv.org/abs/2201.13433
Third Time's the Charm? Image and Video Editing with StyleGAN3 Yuval Alaluf*, Or Patashnik*, Zongze Wu, Asif Zamir, Eli Shechtman, Dani Lischinski, Da
 531 Dec 20, 2022
531 Dec 20, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
RAVE: Realtime Audio Variational autoEncoder Official implementation of RAVE: A variational autoencoder for fast and high-quality neural audio synthes
 587 Jan 1, 2023
587 Jan 1, 2023
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
87 Dec 21, 2022

PyTorch implementations of the paper: "DR.VIC: Decomposition and Reasoning for Video Individual Counting, CVPR, 2022"
DRNet for Video Indvidual Counting (CVPR 2022) Introduction This is the official PyTorch implementation of paper: DR.VIC: Decomposition and Reasoning
 35 Nov 22, 2022
35 Nov 22, 2022

Official code for "Bridging Video-text Retrieval with Multiple Choice Questions", CVPR 2022 (Oral).
Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral) Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained
 99 Jan 6, 2023
99 Jan 6, 2023
UMT is a unified and flexible framework which can handle different input modality combinations, and output video moment retrieval and/or highlight detection results.
Unified Multi-modal Transformers This repository maintains the official implementation of the paper UMT: Unified Multi-modal Transformers for Joint Vi
84 Jan 4, 2023
Direct application of DALLE-2 to video synthesis, using factored space-time Unet and Transformers
DALLE2 Video (wip) ** only to be built after DALLE2 image is done and replicated, and the importance of the prior network is validated ** Direct appli
 105 May 15, 2022
105 May 15, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Classification models 1D Zoo - Keras and TF.Keras
Classification models 1D Zoo - Keras and TF.Keras This repository contains 1D variants of popular CNN models for classification like ResNets, DenseNet
 12 Jan 6, 2023
12 Jan 6, 2023
An open souce video/music streamer based on MPV and piped.
🎶 Harmony Music An easy way to stream videos or music from Youtube from the command line while regaining your privacy. 📖 Table Of Contents ❔ What's
 16 Nov 15, 2022
16 Nov 15, 2022
Fast TikTok NO Watermark Video Downloader (username or url)
💎 TD [ TikDown v4 ] Star ⭐ if you want more Discord Server * discord.gg/onlp | Waxor#9999 Why not open source anymore ? * BECAUSE PEOPLE SKID, STEA
 26 Dec 1, 2022
26 Dec 1, 2022
![[arXiv22] Disentangled Representation Learning for Text-Video Retrieval](https://github.com/foolwood/DRL/raw/main/demo/pipeline.png)
[arXiv22] Disentangled Representation Learning for Text-Video Retrieval
Disentangled Representation Learning for Text-Video Retrieval This is a PyTorch implementation of the paper Disentangled Representation Learning for T
 49 Dec 18, 2022
49 Dec 18, 2022
"Video Moment Retrieval from Text Queries via Single Frame Annotation" in SIGIR 2022.
ViGA: Video moment retrieval via Glance Annotation This is the official repository of the paper "Video Moment Retrieval from Text Queries via Single F
 38 Dec 31, 2022
38 Dec 31, 2022

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

Audio-analytics for music-producers! Automate tedious tasks such as musical scale detection, BPM rate classification and audio file conversion.
Click here to be re-directed to the Beat Inspect Streamlit Web-App You are a music producer? Let's get in touch via LinkedIn Fundamental Analytics for
 11 Dec 27, 2022
11 Dec 27, 2022
scrape tiktok/douyin video list from specific user or keyword
get-tiktok-user-video-list scrape tiktok/douyin video list from specific user or keyword 以**https://www.douyin.com/user/MS4wLjABAAAAUpIowEL3ygUAahQB47
 4 Jul 6, 2022
4 Jul 6, 2022
Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution.
convolver Python script that takes an Impulse response .wav and a input .wav to demonstrate audio convolution. Created by Sean Higley [email protected]
 1 Feb 23, 2022
1 Feb 23, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023
MAU: A Motion-Aware Unit for Video Prediction and Beyond, NeurIPS2021
MAU (NeurIPS2021) Zheng Chang, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Yan Ye, Xinguang Xiang, Wen GAo. Official PyTorch Code for "MAU: A Motion-Aware
 20 Nov 25, 2022
20 Nov 25, 2022
2022-bridge - Example code belonging to the Bridge pattern video
Let's Take The Bridge Pattern To The Next Level This video covers how the bridge
 11 Jun 14, 2022
11 Jun 14, 2022
Programmers-quest - Programmer's Quest! An open source MMO built on top of the Panda3D game engine and Astron server
Programmer's Quest! Programmer's Quest! The open source Python 3 2D MMORPG showc
 5 Oct 7, 2022
5 Oct 7, 2022

Digan - Official PyTorch implementation of Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
DIGAN (ICLR 2022) Official PyTorch implementation of "Generating Videos with Dyn
 147 Dec 31, 2022
147 Dec 31, 2022
Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy"
Shapeland Simulator Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy" Download the video at https://www.youtube.com/watch?
 70 Dec 14, 2022
70 Dec 14, 2022

RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation YouTube | BiliBili 16X interpolation results from two input images: Introd
 28 Dec 9, 2022
28 Dec 9, 2022

SHAS: Approaching optimal Segmentation for End-to-End Speech Translation
SHAS: Approaching optimal Segmentation for End-to-End Speech Translation In this repo you can find the code of the Supervised Hybrid Audio Segmentatio
 21 Dec 20, 2022
21 Dec 20, 2022

HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval [toc] 1. Introduction This repository provides the code for our paper at
 13 Dec 8, 2022
13 Dec 8, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022
Vitrix is an open-source FPS video game coded in python
Vitrix is an open-source FPS video game coded in python Table of contents Usage Game Server Installing Requirements Hardware Requirements Software Req
 1 Feb 13, 2022
1 Feb 13, 2022

Tensorflow 2 implementation of our high quality frame interpolation neural network
FILM: Frame Interpolation for Large Scene Motion Project | Paper | YouTube | Benchmark Scores Tensorflow 2 implementation of our high quality frame in
 1.6k Dec 28, 2022
1.6k Dec 28, 2022

A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
 3 Feb 10, 2022
3 Feb 10, 2022
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
 53 Nov 22, 2022
53 Nov 22, 2022
An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright.
Playwright nonoCAPTCHA An async Python library to automate solving ReCAPTCHA v2 by audio using Playwright. Disclaimer This project is for educational
 69 Dec 28, 2022
69 Dec 28, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022
This bot plays the most recent video from the Daily Silksong News Youtube Channel whenever a specific user enters voice chat once a day.
Do you have that one friend that really likes Hollow Knight. Are they waiting for Silksong to come out? Heckle them with this Discord bot.
 2 Feb 9, 2022
2 Feb 9, 2022

Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
 2 Nov 26, 2022
2 Nov 26, 2022

TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
TONet Introduction The official implementation of "TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music", in ICASSP 2022 We
 29 Dec 1, 2022
29 Dec 1, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
13 Feb 8, 2022
A motion tracking system for any arbitaray points in a video frame.
PointTracking This code is written by Majid Masoumi @ [email protected] I have used lucas kanade optical flow technique to track the points b
 1 Feb 9, 2022
1 Feb 9, 2022
Transformers provides thousands of pretrained models to perform tasks on different modalities such as text, vision, and audio.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 50 Nov 12, 2022
50 Nov 12, 2022

Official implementation for paper Render In-between: Motion Guided Video Synthesis for Action Interpolation
Render In-between: Motion Guided Video Synthesis for Action Interpolation [Paper] [Supp] [arXiv] [4min Video] This is the official Pytorch implementat
 8 Oct 27, 2022
8 Oct 27, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
This repository is the official PyTorch implementation of Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
 4 Dec 11, 2022
4 Dec 11, 2022
 15 Apr 12, 2022
15 Apr 12, 2022
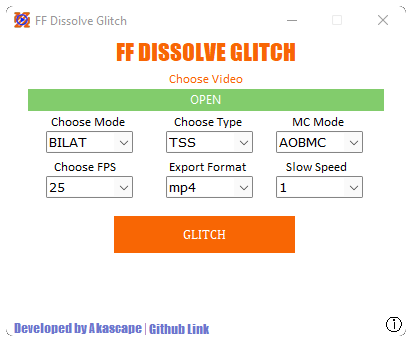
A GUI based glitch tool that uses FFMPEG to create motion interpolated glitches in your videos.
FF Dissolve Glitch This is a GUI based glitch tool that uses FFmpeg to create awesome and wierd motion interpolated glitches in videos. I call it FF d
 19 Nov 10, 2022
19 Nov 10, 2022
VideoMergeDcBot1 - Video Merge Dc Bot for telegram
VIDEO MERGE BOT An Telegram Bot Demo 👉 @VideoMergeDcBot To Merge multiple Video
 2 Feb 4, 2022
2 Feb 4, 2022

Splat a video into a mosaic by sampling a frame at regular intervals
Splat a video into a mosaic by sampling a frame at regular intervals. Useful for seeing the changes over time of an entire video or movie.
 4 Oct 16, 2022
4 Oct 16, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022
YoutubeDownloader - Repo for downloading YT audio and videos
YoutubeDownloader Downloads video/playlist/audio from youtube url. install all t
 2 Feb 17, 2022
2 Feb 17, 2022

Simple Python script that lets you upload image/video to imgur
Pymgur 🐍 Simple Python script that lets you upload image/video to imgur! Usage 🔨 Git Clone this repository install the requirements (pip install -r
 3 Feb 20, 2022
3 Feb 20, 2022
Video-face-extractor - Video face extractor with Python
Python face extractor Setup Create the srcvideos and faces directories Put your
 2 Feb 3, 2022
2 Feb 3, 2022
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
 15 Nov 10, 2022
15 Nov 10, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation toolbox based on PyTorch.
traiNNer traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation to
 202 Jan 4, 2023
202 Jan 4, 2023

camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
 1 Jun 21, 2022
1 Jun 21, 2022
Video-stream - A telegram video stream bot repo
This is a Telegram Video stream Bot. Binary Tech 💫 Features stream videos downl
 1 Feb 2, 2022
1 Feb 2, 2022
Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation
SSWS-loss_function_based_on_MS-TCN Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation Supervised Sliding Window
 3 Aug 3, 2022
3 Aug 3, 2022

PyTorch implementation of "VRT: A Video Restoration Transformer"
VRT: A Video Restoration Transformer Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, Luc Van Gool Computer
 837 Jan 9, 2023
837 Jan 9, 2023
Audio Retrieval with Natural Language Queries: A Benchmark Study
Audio Retrieval with Natural Language Queries: A Benchmark Study Paper | Project page | Text-to-audio search demo This repository is the implementatio
 21 Oct 31, 2022
21 Oct 31, 2022
Self-Supervised Deep Blind Video Super-Resolution
Self-Blind-VSR Paper | Discussion Self-Supervised Deep Blind Video Super-Resolution By Haoran Bai and Jinshan Pan Abstract Existing deep learning-base
 35 Dec 9, 2022
35 Dec 9, 2022
This is the source code for the experiments related to the paper Unsupervised Audio Source Separation Using Differentiable Parametric Source Models
Unsupervised Audio Source Separation Using Differentiable Parametric Source Models This is the source code for the experiments related to the paper Un
 30 Oct 19, 2022
30 Oct 19, 2022

Blind Video Temporal Consistency via Deep Video Prior
deep-video-prior (DVP) Code for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior PyTorch implementation | paper | project web
 272 Dec 21, 2022
272 Dec 21, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023

Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources
Audio Source Separation is the process of separating a mixture into isolated sounds from individual sources (e.g. just the lead vocals).
 14 Nov 7, 2022
14 Nov 7, 2022
An NVDA add-on to split screen reader and audio from other programs to different sound channels
An NVDA add-on to split screen reader and audio from other programs to different sound channels (add-on idea credit: Tony Malykh)
 7 Dec 25, 2022
7 Dec 25, 2022

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023
Spotify playlist video generator
This program creates a video version of your Spotify playlist by using the Spotify API and YouTube-dl.
 0 Mar 3, 2022
0 Mar 3, 2022
Meme-videos - Scrapes memes and turn them into a video compilations
Meme Videos Scrapes memes from reddit using praw and request and then converts t
 12 Oct 28, 2022
12 Oct 28, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023

 431 Jan 3, 2023
431 Jan 3, 2023
Clockwork Convnets for Video Semantic Segmentation
Clockwork Convnets for Video Semantic Segmentation This is the reference implementation of arxiv:1608.03609: Clockwork Convnets for Video Semantic Seg
 141 Nov 21, 2022
141 Nov 21, 2022
A tool for retrieving audio in the past
Rewinder A tool for retrieving audio in the past. Ever felt like, I need to remember that discussion which happened 10 min back. Now you can! Rewind a
 1 Jan 24, 2022
1 Jan 24, 2022

Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
 1 Jan 23, 2022
1 Jan 23, 2022

Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution
Deep Learning: Architectures & Methods Project: Deep Learning for Audio Super-Resolution Figure: Example visualization of the method and baseline as a
 16 Dec 23, 2022
16 Dec 23, 2022

Audio2Face - Audio To Face With Python
Audio2Face Discription We create a project that transforms audio to blendshape w
724 Dec 26, 2022
Xbot-Music - Bot Play Music and Video in Voice Chat Group Telegram
XBOT-MUSIC A Telegram Music+video Bot written in Python using Pyrogram and Py-Tg
 2 Jan 20, 2022
2 Jan 20, 2022
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning
Predicting Keystrokes using an Audio Side-Channel Attack and Machine Learning My
 3 Apr 10, 2022
3 Apr 10, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022