1398 Repositories
Python video-transformer Libraries
Pytorch implementation of MaskGIT: Masked Generative Image Transformer
Pytorch implementation of MaskGIT: Masked Generative Image Transformer
 247 Dec 16, 2022
247 Dec 16, 2022

Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
Youtube Downloader is a simple but highly efficient Youtube Video Downloader, made completly using Python
 2 Nov 26, 2022
2 Nov 26, 2022

Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
 13 Feb 8, 2022
13 Feb 8, 2022
A motion tracking system for any arbitaray points in a video frame.
PointTracking This code is written by Majid Masoumi @ [email protected] I have used lucas kanade optical flow technique to track the points b
 1 Feb 9, 2022
1 Feb 9, 2022

Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression
Regression Transformer Codebase to experiment with a hybrid Transformer that combines conditional sequence generation with regression . Development se
 27 Jan 5, 2023
27 Jan 5, 2023

Official implementation for paper Render In-between: Motion Guided Video Synthesis for Action Interpolation
Render In-between: Motion Guided Video Synthesis for Action Interpolation [Paper] [Supp] [arXiv] [4min Video] This is the official Pytorch implementat
 8 Oct 27, 2022
8 Oct 27, 2022
NeuralForecast is a Python library for time series forecasting with deep learning models
NeuralForecast is a Python library for time series forecasting with deep learning models. It includes benchmark datasets, data-loading utilities, evaluation functions, statistical tests, univariate model benchmarks and SOTA models implemented in PyTorch and PyTorchLightning.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

A transformer which can randomly augment VOC format dataset (both image and bbox) online.
VocAug It is difficult to find a script which can augment VOC-format dataset, especially the bbox. Or find a script needs complex requirements so it i
 1 Mar 5, 2022
1 Mar 5, 2022

Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
Steganography is the art of hiding the fact that communication is taking place, by hiding information in other information.
 7 Nov 9, 2022
7 Nov 9, 2022
Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
This repository is the official PyTorch implementation of Cascaded Deep Video Deblurring Using Temporal Sharpness Prior and Non-local Spatial-Temporal Similarity
 4 Dec 11, 2022
4 Dec 11, 2022

Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5
NLP-Summarizer Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5 This project aimed to provide in
 1 Feb 7, 2022
1 Feb 7, 2022
 15 Apr 12, 2022
15 Apr 12, 2022
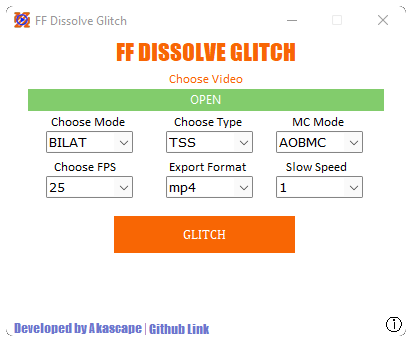
A GUI based glitch tool that uses FFMPEG to create motion interpolated glitches in your videos.
FF Dissolve Glitch This is a GUI based glitch tool that uses FFmpeg to create awesome and wierd motion interpolated glitches in videos. I call it FF d
 19 Nov 10, 2022
19 Nov 10, 2022
VideoMergeDcBot1 - Video Merge Dc Bot for telegram
VIDEO MERGE BOT An Telegram Bot Demo 👉 @VideoMergeDcBot To Merge multiple Video
 2 Feb 4, 2022
2 Feb 4, 2022

Splat a video into a mosaic by sampling a frame at regular intervals
Splat a video into a mosaic by sampling a frame at regular intervals. Useful for seeing the changes over time of an entire video or movie.
 4 Oct 16, 2022
4 Oct 16, 2022

Simple Python script that lets you upload image/video to imgur
Pymgur 🐍 Simple Python script that lets you upload image/video to imgur! Usage 🔨 Git Clone this repository install the requirements (pip install -r
 3 Feb 20, 2022
3 Feb 20, 2022
Video-face-extractor - Video face extractor with Python
Python face extractor Setup Create the srcvideos and faces directories Put your
 2 Feb 3, 2022
2 Feb 3, 2022
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
Terminal-Video-Player - A program that can display video in the terminal using ascii characters
 15 Nov 10, 2022
15 Nov 10, 2022
Mae segmentation - Reproduction of semantic segmentation using masked autoencoder (mae)
ADE20k Semantic segmentation with MAE Getting started Install the mmsegmentation
 97 Dec 17, 2022
97 Dec 17, 2022
The official code repo of "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound Classification and Detection"
Hierarchical Token Semantic Audio Transformer Introduction The Code Repository for "HTS-AT: A Hierarchical Token-Semantic Audio Transformer for Sound
134 Jan 1, 2023
traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation toolbox based on PyTorch.
traiNNer traiNNer is an open source image and video restoration (super-resolution, denoising, deblurring and others) and image to image translation to
 202 Jan 4, 2023
202 Jan 4, 2023

camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
camKapture is an open source application that allows users to access their webcam device and take pictures or create videos.
 1 Jun 21, 2022
1 Jun 21, 2022
This repo contains the code required to train the multivariate time-series Transformer.
Multi-Variate Time-Series Transformer This repo contains the code required to train the multivariate time-series Transformer. Download the data The No
 4 Nov 24, 2022
4 Nov 24, 2022
Video-stream - A telegram video stream bot repo
This is a Telegram Video stream Bot. Binary Tech 💫 Features stream videos downl
 1 Feb 2, 2022
1 Feb 2, 2022
MoRecon - A tool for reconstructing missing frames in motion capture data.
MoRecon - A tool for reconstructing missing frames in motion capture data.
 38 Dec 3, 2022
38 Dec 3, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation
SSWS-loss_function_based_on_MS-TCN Supervised Sliding Window Smoothing Loss Function Based on MS-TCN for Video Segmentation Supervised Sliding Window
 3 Aug 3, 2022
3 Aug 3, 2022

An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax
Simple Transformer An implementation of the "Attention is all you need" paper without extra bells and whistles, or difficult syntax. Note: The only ex
 29 Jun 16, 2022
29 Jun 16, 2022

DocEnTr: An end-to-end document image enhancement transformer
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 19 Jan 29, 2022
19 Jan 29, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Computer Vision Paper Reviews with Key Summary of paper, End to End Code Practice and Jupyter Notebook converted papers
Computer-Vision-Paper-Reviews Computer Vision Paper Reviews with Key Summary along Papers & Codes. Jonathan Choi 2021 The repository provides 100+ Pap
 2 Mar 17, 2022
2 Mar 17, 2022

PyTorch implementation of "VRT: A Video Restoration Transformer"
VRT: A Video Restoration Transformer Jingyun Liang, Jiezhang Cao, Yuchen Fan, Kai Zhang, Rakesh Ranjan, Yawei Li, Radu Timofte, Luc Van Gool Computer
 837 Jan 9, 2023
837 Jan 9, 2023
This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transformer"
FlatTN This repository contains code accompanying the paper "An End-to-End Chinese Text Normalization Model based on Rule-Guided Flat-Lattice Transfor
 74 Nov 28, 2022
74 Nov 28, 2022

Decision Transformer: A brand new Offline RL Pattern
DecisionTransformer_StepbyStep Intro Decision Transformer: A brand new Offline RL Pattern. 这是关于NeurIPS 2021 热门论文Decision Transformer的复现。 👍 原文地址: Deci
 14 Nov 22, 2022
14 Nov 22, 2022
Self-Supervised Deep Blind Video Super-Resolution
Self-Blind-VSR Paper | Discussion Self-Supervised Deep Blind Video Super-Resolution By Haoran Bai and Jinshan Pan Abstract Existing deep learning-base
 35 Dec 9, 2022
35 Dec 9, 2022

Geometric Interpretation of Matrix Square Root and Inverse Square Root
Fast Differentiable Matrix Sqrt Root Geometric Interpretation of Matrix Square Root and Inverse Square Root This repository constains the official Pyt
 5 Jan 24, 2022
5 Jan 24, 2022

This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans
This repository contains the code for TABS, a 3D CNN-Transformer hybrid automated brain tissue segmentation algorithm using T1w structural MRI scans. TABS relies on a Res-Unet backbone, with a Vision Transformer embedded between the encoder and decoder layers.
 6 Nov 7, 2022
6 Nov 7, 2022

SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation
SegTransVAE: Hybrid CNN - Transformer with Regularization for medical image segmentation This repo is the official implementation for SegTransVAE. Seg
 4 Aug 4, 2022
4 Aug 4, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022
Transformer based SAR image despeckling
Transformer based SAR image despeckling Using the code: The code is stable while using Python 3.6.13, CUDA =10.1 Clone this repository: git clone htt
 27 Nov 13, 2022
27 Nov 13, 2022
Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
74 Jan 7, 2023

Blind Video Temporal Consistency via Deep Video Prior
deep-video-prior (DVP) Code for NeurIPS 2020 paper: Blind Video Temporal Consistency via Deep Video Prior PyTorch implementation | paper | project web
 272 Dec 21, 2022
272 Dec 21, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization,
FSRA This repository contains the dataset link and the code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV
 32 Dec 18, 2022
32 Dec 18, 2022

EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation
EdiBERT, a generative model for image editing EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation. The
 16 Dec 7, 2022
16 Dec 7, 2022

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023

On the Adversarial Robustness of Visual Transformer
On the Adversarial Robustness of Visual Transformer Code for our paper "On the Adversarial Robustness of Visual Transformers"
 35 Dec 14, 2022
35 Dec 14, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022
Spotify playlist video generator
This program creates a video version of your Spotify playlist by using the Spotify API and YouTube-dl.
 0 Mar 3, 2022
0 Mar 3, 2022
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022
Meme-videos - Scrapes memes and turn them into a video compilations
Meme Videos Scrapes memes from reddit using praw and request and then converts t
 12 Oct 28, 2022
12 Oct 28, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

 431 Jan 3, 2023
431 Jan 3, 2023

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022

RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting
RATCHET: RAdiological Text Captioning for Human Examined Thoraxes RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting. Based on t
 26 Nov 14, 2022
26 Nov 14, 2022
Generating Radiology Reports via Memory-driven Transformer
R2Gen This is the implementation of Generating Radiology Reports via Memory-driven Transformer at EMNLP-2020. Citations If you use or extend our work,
 101 Dec 13, 2022
101 Dec 13, 2022

This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
ICCV Workshop 2021 VTGAN This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
 25 Dec 8, 2022
25 Dec 8, 2022
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021)
T2Net Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021) [Paper][Code] Dependencies numpy==1.18.5 scikit_image==
 64 Nov 23, 2022
64 Nov 23, 2022
COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models
COVID-ViT COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models This code is to response to te MIA-COV19 compe
 17 Dec 30, 2022
17 Dec 30, 2022
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification [NeurIPS 2021] Abstract Multiple instance learn
 132 Dec 30, 2022
132 Dec 30, 2022
Mixed Transformer UNet for Medical Image Segmentation
MT-UNet Update 2022/01/05 By another round of training based on previous weights, our model also achieved a better performance on ACDC (91.61% DSC). W
 92 Dec 25, 2022
92 Dec 25, 2022
Official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation
SegPC-2021 This is the official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation by
 13 Dec 14, 2022
13 Dec 14, 2022

This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
 89 Jan 24, 2022
89 Jan 24, 2022
nnFormer: Interleaved Transformer for Volumetric Segmentation
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022
Clockwork Convnets for Video Semantic Segmentation
Clockwork Convnets for Video Semantic Segmentation This is the reference implementation of arxiv:1608.03609: Clockwork Convnets for Video Semantic Seg
 141 Nov 21, 2022
141 Nov 21, 2022

Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
Video-Captioning - A machine Learning project to generate captions for video frames indicating the relationship between the objects in the video
 1 Jan 23, 2022
1 Jan 23, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 6 Sep 21, 2022
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022
Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
42 Dec 30, 2022
This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector of the financial market.
GPlearn_finiance_stock_futures_extension This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector
 189 Dec 25, 2022
189 Dec 25, 2022
Xbot-Music - Bot Play Music and Video in Voice Chat Group Telegram
XBOT-MUSIC A Telegram Music+video Bot written in Python using Pyrogram and Py-Tg
 2 Jan 20, 2022
2 Jan 20, 2022
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Transformer in Computer Vision
Transformer-in-Vision A paper list of some recent Transformer-based CV works. If you find some ignored papers, please open issues or pull requests. **
 506 Dec 26, 2022
506 Dec 26, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022
Detail-Preserving Transformer for Light Field Image Super-Resolution
DPT Official Pytorch implementation of the paper "Detail-Preserving Transformer for Light Field Image Super-Resolution" accepted by AAAI 2022 . Update
 50 Jan 1, 2023
50 Jan 1, 2023

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction. arxiv This repository contains python scripts for tr
 12 Dec 12, 2022
12 Dec 12, 2022
TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning
TransZero++ This repository contains the testing code for the paper "TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning" submitted
 3 Jan 5, 2022
3 Jan 5, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022

All exercises done during the Python 3 course in the Video Course (World 1, 2 and 3)
Python3-cursoemvideo-exercises - All exercises done during the Python 3 course in the Video Course (World 1, 2 and 3)
 3 Jan 17, 2022
3 Jan 17, 2022
TikTok - TikTok Bot to download video or audio from TikTok
TikTok - TikTok Bot to download video or audio from TikTok
 51 Mar 4, 2022
51 Mar 4, 2022

DeepFaceLive - Live Deep Fake in python, Real-time face swap for PC streaming or video calls
DeepFaceLive - Live Deep Fake in python, Real-time face swap for PC streaming or video calls
 8.3k Dec 31, 2022
8.3k Dec 31, 2022
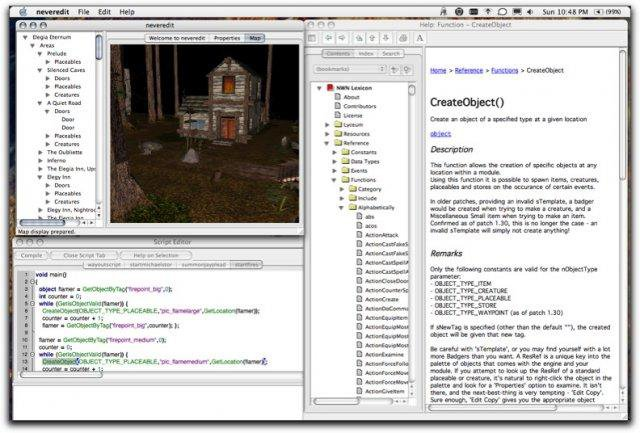
Editor for Bioware's Original Neverwinter Nights Game
neveredit This is an import of an old sourceforge project. Neveredit is an editor for Bioware's Neverwinter Nights game. It also includes all the low
 2 Apr 12, 2022
2 Apr 12, 2022

Code for paper: Towards Tokenized Human Dynamics Representation
Video Tokneization Codebase for video tokenization, based on our paper Towards Tokenized Human Dynamics Representation. Prerequisites (tested under Py
 20 May 31, 2022
20 May 31, 2022

A PyTorch implementation of VIOLET
VIOLET: End-to-End Video-Language Transformers with Masked Visual-token Modeling A PyTorch implementation of VIOLET Overview VIOLET is an implementati
 119 Dec 30, 2022
119 Dec 30, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss
CAMoE + Dual SoftMax Loss (DSL): Improving Video-Text Retrieval by Multi-Stream Corpus Alignment and Dual Softmax Loss This is official implement of "
 87 Dec 24, 2022
87 Dec 24, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023