1401 Repositories
Python video-swin-transformer Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation, CVPR2022
TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation Paper Links: TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentati
253 Dec 21, 2022

Official code for CVPR2022 paper: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
📖 Depth-Aware Generative Adversarial Network for Talking Head Video Generation (CVPR 2022) 🔥 If DaGAN is helpful in your photos/projects, please hel
 503 Jan 4, 2023
503 Jan 4, 2023

"MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction" (CVPRW 2022) & (Winner of NTIRE 2022 Challenge on Spectral Reconstruction from RGB)
MST++: Multi-stage Spectral-wise Transformer for Efficient Spectral Reconstruction (CVPRW 2022) Yuanhao Cai, Jing Lin, Zudi Lin, Haoqian Wang, Yulun Z
 274 Jan 5, 2023
274 Jan 5, 2023

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023

Official code for "Towards An End-to-End Framework for Flow-Guided Video Inpainting" (CVPR2022)
E2FGVI (CVPR 2022) English | 简体中文 This repository contains the official implementation of the following paper: Towards An End-to-End Framework for Flo
 537 Jan 7, 2023
537 Jan 7, 2023

CVPR2022 (Oral) - Rethinking Semantic Segmentation: A Prototype View
Rethinking Semantic Segmentation: A Prototype View Rethinking Semantic Segmentation: A Prototype View, Tianfei Zhou, Wenguan Wang, Ender Konukoglu and
 239 Dec 26, 2022
239 Dec 26, 2022
Official repository of "BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment"
BasicVSR_PlusPlus (CVPR 2022) [Paper] [Project Page] [Code] This is the official repository for BasicVSR++. Please feel free to raise issue related to
 227 Jan 1, 2023
227 Jan 1, 2023

Stratified Transformer for 3D Point Cloud Segmentation (CVPR 2022)
Stratified Transformer for 3D Point Cloud Segmentation Xin Lai*, Jianhui Liu*, Li Jiang, Liwei Wang, Hengshuang Zhao, Shu Liu, Xiaojuan Qi, Jiaya Jia
 195 Jan 1, 2023
195 Jan 1, 2023

Official implementation for "Style Transformer for Image Inversion and Editing" (CVPR 2022)
Style Transformer for Image Inversion and Editing (CVPR2022) https://arxiv.org/abs/2203.07932 Existing GAN inversion methods fail to provide latent co
 153 Dec 2, 2022
153 Dec 2, 2022

Implementation of Deformable Attention in Pytorch from the paper "Vision Transformer with Deformable Attention"
Deformable Attention Implementation of Deformable Attention from this paper in Pytorch, which appears to be an improvement to what was proposed in DET
 128 Dec 24, 2022
128 Dec 24, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

Cross-view Transformers for real-time Map-view Semantic Segmentation (CVPR 2022 Oral)
Cross View Transformers This repository contains the source code and data for our paper: Cross-view Transformers for real-time Map-view Semantic Segme
 363 Dec 25, 2022
363 Dec 25, 2022

Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds (CVPR 2022)
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds (CVPR2022)[paper] Authors: Chenhang He, Ruihuang Li, Shuai Li, L
 141 Dec 30, 2022
141 Dec 30, 2022

Implementation of the Transformer variant proposed in "Transformer Quality in Linear Time"
FLASH - Pytorch Implementation of the Transformer variant proposed in the paper Transformer Quality in Linear Time Install $ pip install FLASH-pytorch
209 Dec 28, 2022

MAT: Mask-Aware Transformer for Large Hole Image Inpainting
MAT: Mask-Aware Transformer for Large Hole Image Inpainting (CVPR2022, Oral) Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, Jiaya Jia [Paper] News This
 254 Dec 29, 2022
254 Dec 29, 2022

Official source code of Fast Point Transformer, CVPR 2022
Fast Point Transformer Project Page | Paper This repository contains the official source code and data for our paper: Fast Point Transformer Chunghyun
 182 Dec 23, 2022
182 Dec 23, 2022
![[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links](https://github.com/michiyasunaga/LinkBERT/raw/main/figs/overview.png)
[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links
LinkBERT: A Knowledgeable Language Model Pretrained with Document Links This repo provides the model, code & data of our paper: LinkBERT: Pretraining
 264 Jan 1, 2023
264 Jan 1, 2023

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

The official implementation of Autoregressive Image Generation using Residual Quantization (CVPR '22)
Autoregressive Image Generation using Residual Quantization (CVPR 2022) The official implementation of "Autoregressive Image Generation using Residual
 529 Dec 30, 2022
529 Dec 30, 2022

RuDOLPH: One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP
[Paper] [Хабр] [Model Card] [Colab] [Kaggle] RuDOLPH 🦌 🎄 ☃️ One Hyper-Modal Transformer can be creative as DALL-E and smart as CLIP Russian Diffusio
232 Jan 4, 2023
Official codebase used to develop Vision Transformer, MLP-Mixer, LiT and more.
Big Vision This codebase is designed for training large-scale vision models on Cloud TPU VMs. It is based on Jax/Flax libraries, and uses tf.data and
 701 Jan 3, 2023
701 Jan 3, 2023
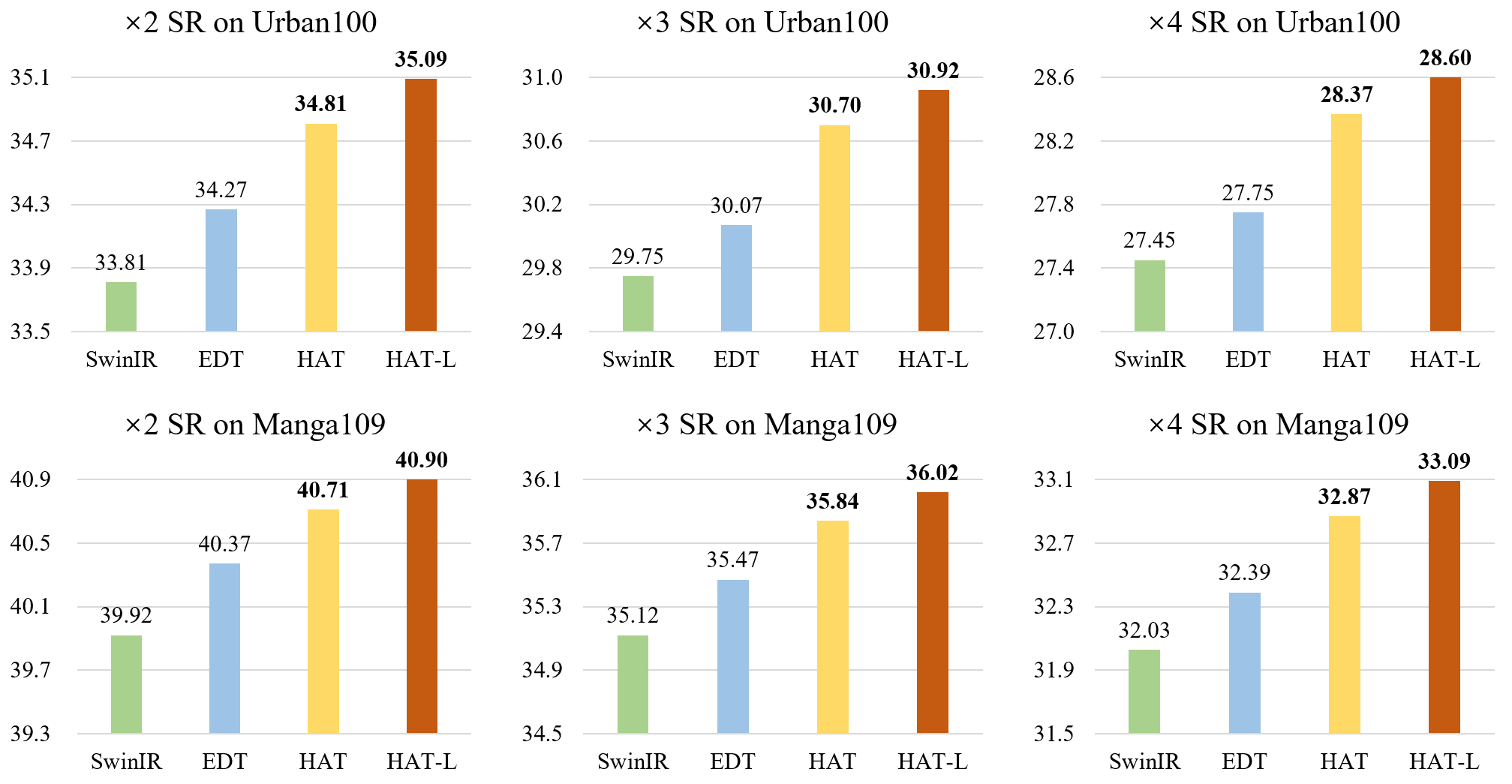
Activating More Pixels in Image Super-Resolution Transformer
HAT [Paper Link] Activating More Pixels in Image Super-Resolution Transformer Xiangyu Chen, Xintao Wang, Jiantao Zhou and Chao Dong BibTeX @article{ch
 270 Dec 27, 2022
270 Dec 27, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022
Video Frame Interpolation with Transformer (CVPR2022)
VFIformer Official PyTorch implementation of our CVPR2022 paper Video Frame Interpolation with Transformer Dependencies python = 3.8 pytorch = 1.8.0
63 Dec 16, 2022

Adaptive FNO transformer - official Pytorch implementation
Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers This repository contains PyTorch implementation of the Adaptive Fourier Neu
 77 Dec 29, 2022
77 Dec 29, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022

Practical Blind Denoising via Swin-Conv-UNet and Data Synthesis
Practical Blind Denoising via Swin-Conv-UNet and Data Synthesis [Paper] [Online Demo] The following results are obtained by our SCUNet with purely syn
 312 Jan 7, 2023
312 Jan 7, 2023
[CVPR 2022] Official PyTorch Implementation for "Reference-based Video Super-Resolution Using Multi-Camera Video Triplets"
Reference-based Video Super-Resolution (RefVSR) Official PyTorch Implementation of the CVPR 2022 Paper Project | arXiv | RealMCVSR Dataset This repo c
 151 Dec 30, 2022
151 Dec 30, 2022

Implementation of ETSformer, state of the art time-series Transformer, in Pytorch
ETSformer - Pytorch Implementation of ETSformer, state of the art time-series Transformer, in Pytorch Install $ pip install etsformer-pytorch Usage im
121 Dec 30, 2022

Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding (CVPR2022)
Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding by Qiaole Dong*, Chenjie Cao*, Yanwei Fu Paper and Supple
 190 Dec 27, 2022
190 Dec 27, 2022

The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for LiDAR-Based Place Recognition.
OverlapTransformer The code for our paper submitted to RAL/IROS 2022: OverlapTransformer: An Efficient and Rotation-Invariant Transformer Network for
 136 Jan 3, 2023
136 Jan 3, 2023
![[CVPR 2022] TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing](https://github.com/BillyXYB/TransEditor/raw/main/resources/teaser_change_order.png)
[CVPR 2022] TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing (CVPR 2022) This repository provides the official PyTorch impleme
 128 Jan 3, 2023
128 Jan 3, 2023

As-ViT: Auto-scaling Vision Transformers without Training
As-ViT: Auto-scaling Vision Transformers without Training [PDF] Wuyang Chen, Wei Huang, Xianzhi Du, Xiaodan Song, Zhangyang Wang, Denny Zhou In ICLR 2
 68 Sep 5, 2022
68 Sep 5, 2022
Telegram Group Calls Streaming bot with some useful features, written in Python with Pyrogram and Py-Tgcalls. Supporting platforms like Youtube, Spotify, Resso, AppleMusic, Soundcloud and M3u8 Links.
Yukki Music Bot Yukki Music Bot is a Powerful Telegram Music+Video Bot written in Python using Pyrogram and Py-Tgcalls by which you can stream songs,
 996 Dec 28, 2022
996 Dec 28, 2022

(CVPR 2022) Pytorch implementation of "Self-supervised transformers for unsupervised object discovery using normalized cut"
(CVPR 2022) TokenCut Pytorch implementation of Tokencut: Self-supervised Transformers for Unsupervised Object Discovery using Normalized Cut Yangtao W
 200 Jan 2, 2023
200 Jan 2, 2023
KoCLIP: Korean port of OpenAI CLIP, in Flax
KoCLIP This repository contains code for KoCLIP, a Korean port of OpenAI's CLIP. This project was conducted as part of Hugging Face's Flax/JAX communi
 100 Jan 2, 2023
100 Jan 2, 2023

This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf
Behavior-Sequence-Transformer-Pytorch This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf This model
 83 Jan 5, 2023
83 Jan 5, 2023

Implements VQGAN+CLIP for image and video generation, and style transfers, based on text and image prompts. Emphasis on ease-of-use, documentation, and smooth video creation.
VQGAN-CLIP-GENERATOR Overview This is a package (with available notebook) for running VQGAN+CLIP locally, with a focus on ease of use, good documentat
 98 Dec 30, 2022
98 Dec 30, 2022

Official Implementation of "Third Time's the Charm? Image and Video Editing with StyleGAN3" https://arxiv.org/abs/2201.13433
Third Time's the Charm? Image and Video Editing with StyleGAN3 Yuval Alaluf*, Or Patashnik*, Zongze Wu, Asif Zamir, Eli Shechtman, Dani Lischinski, Da
 531 Dec 20, 2022
531 Dec 20, 2022
PyTorch implementation of Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
Anomaly Transformer in PyTorch This is an implementation of Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy. This pape
 160 Dec 19, 2022
160 Dec 19, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology (LMRL Workshop, NeurIPS 2021)
Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology Self-Supervised Vision Transformers Learn Visual Concepts in Histopatholog
 95 Dec 24, 2022
95 Dec 24, 2022
.png)
Contextual Attention Network: Transformer Meets U-Net
Contextual Attention Network: Transformer Meets U-Net Contexual attention network for medical image segmentation with state of the art results on skin
 67 Nov 28, 2022
67 Nov 28, 2022
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022

Rethinking Portrait Matting with Privacy Preserving
Rethinking Portrait Matting with Privacy Preserving This is the official repository of the paper Rethinking Portrait Matting with Privacy Preserving.
 184 Jan 3, 2023
184 Jan 3, 2023
[CVPR 2022] Official Pytorch code for OW-DETR: Open-world Detection Transformer
OW-DETR: Open-world Detection Transformer (CVPR 2022) [Paper] Akshita Gupta*, Sanath Narayan*, K J Joseph, Salman Khan, Fahad Shahbaz Khan, Mubarak Sh
 127 Dec 27, 2022
127 Dec 27, 2022
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

Official Implementation of DE-DETR and DELA-DETR in "Towards Data-Efficient Detection Transformers"
DE-DETRs By Wen Wang, Jing Zhang, Yang Cao, Yongliang Shen, and Dacheng Tao This repository is an official implementation of DE-DETR and DELA-DETR in
 61 Dec 12, 2022
61 Dec 12, 2022

PyTorch implementations of the paper: "DR.VIC: Decomposition and Reasoning for Video Individual Counting, CVPR, 2022"
DRNet for Video Indvidual Counting (CVPR 2022) Introduction This is the official PyTorch implementation of paper: DR.VIC: Decomposition and Reasoning
 35 Nov 22, 2022
35 Nov 22, 2022
![[CVPR22] Official codebase of Semantic Segmentation by Early Region Proxy.](https://github.com/YiF-Zhang/RegionProxy/raw/master/.github/perf-gflops-param.jpg)
[CVPR22] Official codebase of Semantic Segmentation by Early Region Proxy.
RegionProxy Figure 2. Performance vs. GFLOPs on ADE20K val split. Semantic Segmentation by Early Region Proxy Yifan Zhang, Bo Pang, Cewu Lu CVPR 2022
 54 Nov 29, 2022
54 Nov 29, 2022

Official code for "Bridging Video-text Retrieval with Multiple Choice Questions", CVPR 2022 (Oral).
Bridging Video-text Retrieval with Multiple Choice Questions, CVPR 2022 (Oral) Paper | Project Page | Pre-trained Model | CLIP-Initialized Pre-trained
 99 Jan 6, 2023
99 Jan 6, 2023
UMT is a unified and flexible framework which can handle different input modality combinations, and output video moment retrieval and/or highlight detection results.
Unified Multi-modal Transformers This repository maintains the official implementation of the paper UMT: Unified Multi-modal Transformers for Joint Vi
84 Jan 4, 2023

Official Implementation of DE-CondDETR and DELA-CondDETR in "Towards Data-Efficient Detection Transformers"
DE-DETRs By Wen Wang, Jing Zhang, Yang Cao, Yongliang Shen, and Dacheng Tao This repository is an official implementation of DE-CondDETR and DELA-Cond
41 Dec 12, 2022
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy" (ICLR 2022 Spotlight)
About Code release for Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy (ICLR 2022 Spotlight)
 221 Dec 31, 2022
221 Dec 31, 2022
![[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds](https://github.com/zlccccc/3DVG-Transformer/raw/main/demo/Model.png)
[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds
3DVG-Transformer This repository is for the ICCV 2021 paper "3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds" Our method "3DV
 22 Dec 11, 2022
22 Dec 11, 2022

Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion"
MKGFormer Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion" Model Architecture Illu
 68 Dec 28, 2022
68 Dec 28, 2022

SIGIR'22 paper: Axiomatically Regularized Pre-training for Ad hoc Search
Introduction This codebase contains source-code of the Python-based implementation (ARES) of our SIGIR 2022 paper. Chen, Jia, et al. "Axiomatically Re
 17 Nov 9, 2022
17 Nov 9, 2022
Direct application of DALLE-2 to video synthesis, using factored space-time Unet and Transformers
DALLE2 Video (wip) ** only to be built after DALLE2 image is done and replicated, and the importance of the prior network is validated ** Direct appli
105 May 15, 2022

Implementation of the GVP-Transformer, which was used in the paper "Learning inverse folding from millions of predicted structures" for de novo protein design alongside Alphafold2
GVP Transformer (wip) Implementation of the GVP-Transformer, which was used in the paper Learning inverse folding from millions of predicted structure
19 May 6, 2022

Official Implementation of HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation by Lukas Hoyer, Dengxin Dai, and Luc Van Gool [Arxiv] [Paper] Overview Unsup
 149 Dec 28, 2022
149 Dec 28, 2022
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
An open souce video/music streamer based on MPV and piped.
🎶 Harmony Music An easy way to stream videos or music from Youtube from the command line while regaining your privacy. 📖 Table Of Contents ❔ What's
 16 Nov 15, 2022
16 Nov 15, 2022

PSTR: End-to-End One-Step Person Search With Transformers (CVPR2022)
PSTR (CVPR2022) This code is an official implementation of "PSTR: End-to-End One-Step Person Search With Transformers (CVPR2022)". End-to-end one-step
 28 Dec 13, 2022
28 Dec 13, 2022
Fast TikTok NO Watermark Video Downloader (username or url)
💎 TD [ TikDown v4 ] Star ⭐ if you want more Discord Server * discord.gg/onlp | Waxor#9999 Why not open source anymore ? * BECAUSE PEOPLE SKID, STEA
 26 Dec 1, 2022
26 Dec 1, 2022
The official code of LM-Debugger, an interactive tool for inspection and intervention in transformer-based language models.
LM-Debugger is an open-source interactive tool for inspection and intervention in transformer-based language models. This repository includes the code
 110 Dec 28, 2022
110 Dec 28, 2022

Unofficial Implement PU-Transformer
PU-Transformer-pytorch Pytorch unofficial implementation of PU-Transformer (PU-Transformer: Point Cloud Upsampling Transformer) https://arxiv.org/abs/
 7 Sep 21, 2022
7 Sep 21, 2022

The repo for the paper "I3CL: Intra- and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection".
I3CL: Intra- and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection Updates | Introduction | Results | Usage | Citation |
33 Jan 5, 2023
![[arXiv22] Disentangled Representation Learning for Text-Video Retrieval](https://github.com/foolwood/DRL/raw/main/demo/pipeline.png)
[arXiv22] Disentangled Representation Learning for Text-Video Retrieval
Disentangled Representation Learning for Text-Video Retrieval This is a PyTorch implementation of the paper Disentangled Representation Learning for T
 49 Dec 18, 2022
49 Dec 18, 2022
"Video Moment Retrieval from Text Queries via Single Frame Annotation" in SIGIR 2022.
ViGA: Video moment retrieval via Glance Annotation This is the official repository of the paper "Video Moment Retrieval from Text Queries via Single F
 38 Dec 31, 2022
38 Dec 31, 2022

YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Created using Python, PyTube and PySimpleGUI.
YouTube Downloader YouTube Downloader is extremely simple program for downloading songs or playlists (in audio or video) from YouTube. Disclaimer It's
 3 Dec 14, 2022
3 Dec 14, 2022

This repository contains the data and code for the paper "Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors" (SPNLP@ACL2022)
GP-VAE This repository provides datasets and code for preprocessing, training and testing models for the paper: Diverse Text Generation via Variationa
 18 Dec 29, 2022
18 Dec 29, 2022
![[CVPR 2022]](https://github.com/VITA-Group/Diverse-ViT/raw/main/Figs/Diversity_overview.png)
[CVPR 2022] "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy" by Tianlong Chen, Zhenyu Zhang, Yu Cheng, Ahmed Awadallah, Zhangyang Wang
The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy Codes for this paper: [CVPR 2022] The Pr
16 Nov 26, 2022
scrape tiktok/douyin video list from specific user or keyword
get-tiktok-user-video-list scrape tiktok/douyin video list from specific user or keyword 以**https://www.douyin.com/user/MS4wLjABAAAAUpIowEL3ygUAahQB47
 4 Jul 6, 2022
4 Jul 6, 2022
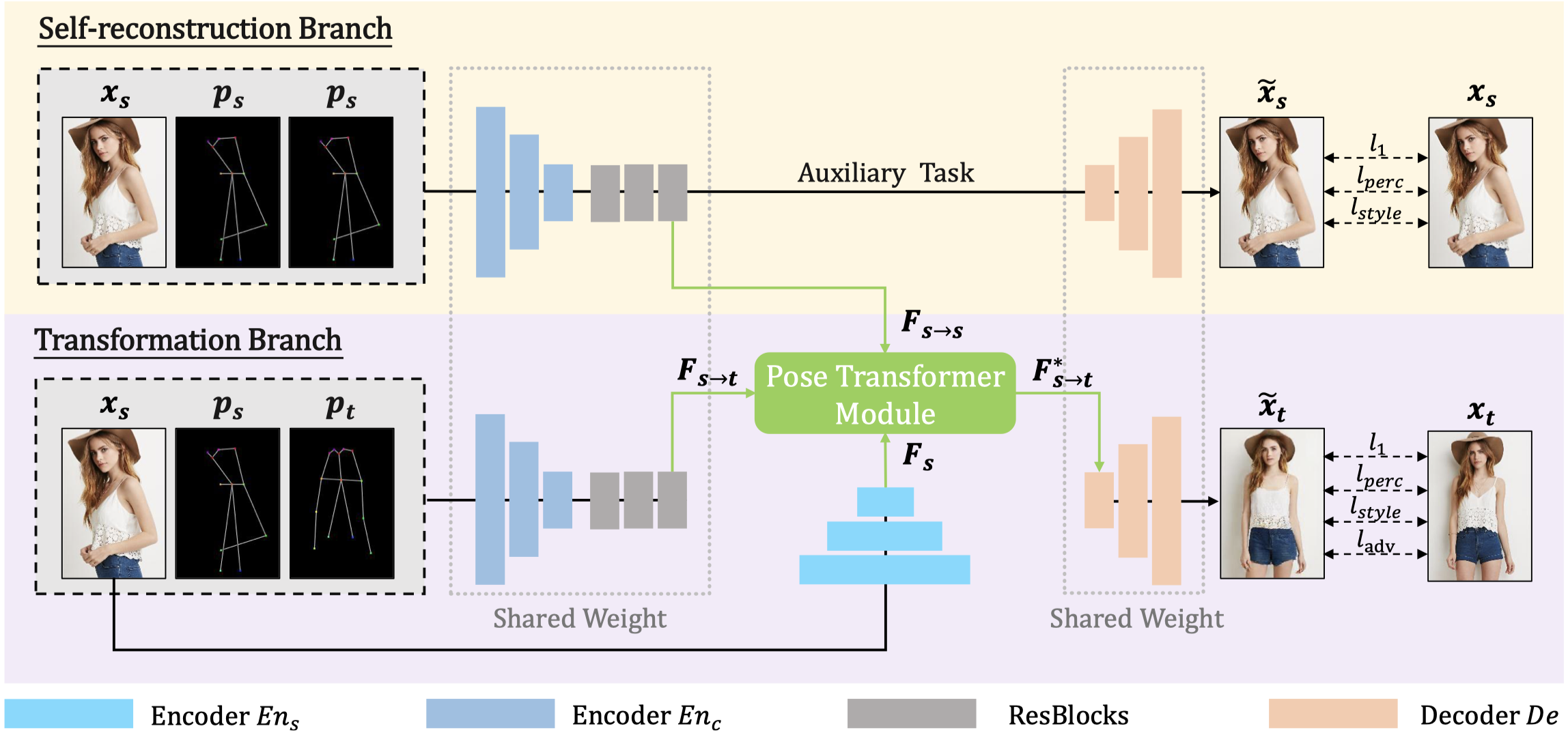
Exploring the Dual-task Correlation for Pose Guided Person Image Generation
Dual-task Pose Transformer Network The source code for our paper "Exploring Dual-task Correlation for Pose Guided Person Image Generation“ (CVPR2022)
 63 Dec 15, 2022
63 Dec 15, 2022
MAU: A Motion-Aware Unit for Video Prediction and Beyond, NeurIPS2021
MAU (NeurIPS2021) Zheng Chang, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Yan Ye, Xinguang Xiang, Wen GAo. Official PyTorch Code for "MAU: A Motion-Aware
 20 Nov 25, 2022
20 Nov 25, 2022
2022-bridge - Example code belonging to the Bridge pattern video
Let's Take The Bridge Pattern To The Next Level This video covers how the bridge
 11 Jun 14, 2022
11 Jun 14, 2022
Transformer Huffman coding - Complete Huffman coding through transformer
Transformer_Huffman_coding Complete Huffman coding through transformer 2022/2/19
 3 May 19, 2022
3 May 19, 2022
SmallInitEmb - LayerNorm(SmallInit(Embedding)) in a Transformer to improve convergence
SmallInitEmb LayerNorm(SmallInit(Embedding)) in a Transformer I find that when t
 11 Dec 25, 2022
11 Dec 25, 2022
Programmers-quest - Programmer's Quest! An open source MMO built on top of the Panda3D game engine and Astron server
Programmer's Quest! Programmer's Quest! The open source Python 3 2D MMORPG showc
 5 Oct 7, 2022
5 Oct 7, 2022

Digan - Official PyTorch implementation of Generating Videos with Dynamics-aware Implicit Generative Adversarial Networks
DIGAN (ICLR 2022) Official PyTorch implementation of "Generating Videos with Dyn
 147 Dec 31, 2022
147 Dec 31, 2022

GeoTransformer - Geometric Transformer for Fast and Robust Point Cloud Registration
Geometric Transformer for Fast and Robust Point Cloud Registration PyTorch imple
 220 Jan 5, 2023
220 Jan 5, 2023
Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy"
Shapeland Simulator Source code to accompany Defunctland's video "FASTPASS: A Complicated Legacy" Download the video at https://www.youtube.com/watch?
 70 Dec 14, 2022
70 Dec 14, 2022

RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation YouTube | BiliBili 16X interpolation results from two input images: Introd
 28 Dec 9, 2022
28 Dec 9, 2022

Accuracy Aligned. Concise Implementation of Swin Transformer
Accuracy Aligned. Concise Implementation of Swin Transformer This repository contains the implementation of Swin Transformer, and the training codes o
 77 Dec 16, 2022
77 Dec 16, 2022

HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
HCQ: Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval [toc] 1. Introduction This repository provides the code for our paper at
 13 Dec 8, 2022
13 Dec 8, 2022
Vitrix is an open-source FPS video game coded in python
Vitrix is an open-source FPS video game coded in python Table of contents Usage Game Server Installing Requirements Hardware Requirements Software Req
 1 Feb 13, 2022
1 Feb 13, 2022

This repository contains code from the paper "TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network"
TTS-GAN: A Transformer-based Time-Series Generative Adversarial Network This repository contains code from the paper "TTS-GAN: A Transformer-based Tim
 108 Dec 29, 2022
108 Dec 29, 2022

A python package to fine-tune transformer-based models for named entity recognition (NER).
nerblackbox A python package to fine-tune transformer-based language models for named entity recognition (NER). Resources Source Code: https://github.
 13 Jul 30, 2022
13 Jul 30, 2022

TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular potentials
TorchMD-net TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular
 104 Jan 3, 2023
104 Jan 3, 2023

Clean and readable code for Decision Transformer: Reinforcement Learning via Sequence Modeling
Minimal implementation of Decision Transformer: Reinforcement Learning via Sequence Modeling in PyTorch for mujoco control tasks in OpenAI gym
 104 Jan 6, 2023
104 Jan 6, 2023

Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
Deeply Supervised, Layer-wise Prediction-aware (DSLP) Transformer for Non-autoregressive Neural Machine Translation
 37 Jan 4, 2023
37 Jan 4, 2023

Tensorflow 2 implementation of our high quality frame interpolation neural network
FILM: Frame Interpolation for Large Scene Motion Project | Paper | YouTube | Benchmark Scores Tensorflow 2 implementation of our high quality frame in
1.6k Dec 28, 2022

A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
A python scripts that uses 3 different feature extraction methods such as SIFT, SURF and ORB to find a book in a video clip and project trailer of a movie based on that book, on to it.
 3 Feb 10, 2022
3 Feb 10, 2022
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
Official repository for GCR rerank, a GCN-based reranking method for both image and video re-ID
 53 Nov 22, 2022
53 Nov 22, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022

This project uses ViT to perform image classification tasks on DATA set CIFAR10.
Vision-Transformer-Multiprocess-DistributedDataParallel-Apex Introduction This project uses ViT to perform image classification tasks on DATA set CIFA
 3 Jun 3, 2022
3 Jun 3, 2022
This bot plays the most recent video from the Daily Silksong News Youtube Channel whenever a specific user enters voice chat once a day.
Do you have that one friend that really likes Hollow Knight. Are they waiting for Silksong to come out? Heckle them with this Discord bot.
 2 Feb 9, 2022
2 Feb 9, 2022