2335 Repositories
Python word-language-model Libraries
Causal Imitative Model for Autonomous Driving
Causal Imitative Model for Autonomous Driving Mohammad Reza Samsami, Mohammadhossein Bahari, Saber Salehkaleybar, Alexandre Alahi. arXiv 2021. [Projec
 8 Oct 4, 2022
8 Oct 4, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022

A simple word search made in python
Word Search Puzzle A simple word search made in python Usage $ python3 main.py -h usage: main.py [-h] [-c] [-f FILE] Generates a word s
 16 Mar 10, 2022
16 Mar 10, 2022
Convert openmmlab (not only mmdetection) series model to tensorrt
MMDet to TensorRT This project aims to convert the mmdetection model to TensorRT model end2end. Focus on object detection for now. Mask support is exp
 4 Dec 17, 2021
4 Dec 17, 2021
Validation and inference over LinkML instance data using souffle
Translates LinkML schemas into Datalog programs and executes them using Souffle, enabling advanced validation and inference over instance data
 7 Aug 7, 2022
7 Aug 7, 2022

A concise grammar of interactive graphics, built on Vega.
Vega-Lite Vega-Lite provides a higher-level grammar for visual analysis that generates complete Vega specifications. You can find more details, docume
 4k Jan 8, 2023
4k Jan 8, 2023
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022

RuleBERT: Teaching Soft Rules to Pre-Trained Language Models
RuleBERT: Teaching Soft Rules to Pre-Trained Language Models (Paper) (Slides) (Video) RuleBERT is a pre-trained language model that has been fine-tune
 16 Aug 24, 2022
16 Aug 24, 2022

Concept drift monitoring for HA model servers.
{Fast, Correct, Simple} - pick three Easily compare training and production ML data & model distributions Goals Boxkite is an instrumentation library
 98 Dec 15, 2022
98 Dec 15, 2022

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Machine Learning automation and tracking
The Open-Source MLOps Orchestration Framework MLRun is an open-source MLOps framework that offers an integrative approach to managing your machine-lea
 873 Jan 4, 2023
873 Jan 4, 2023

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022
This repository implements a brute-force spellchecker utilizing the Damerau-Levenshtein edit distance.
About spellchecker.py Implementing a highly-accurate, brute-force, and dynamically programmed spellchecking program that utilizes the Damerau-Levensht
 1 Dec 11, 2021
1 Dec 11, 2021
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
 8 Aug 10, 2022
8 Aug 10, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 922 Dec 10, 2021
922 Dec 10, 2021
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
This is a GUI program that will generate a word search puzzle image
Word Search Puzzle Generator Table of Contents About The Project Built With Getting Started Prerequisites Installation Usage Roadmap Contributing Cont
 11 Feb 22, 2022
11 Feb 22, 2022
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
 25 Dec 28, 2022
25 Dec 28, 2022
DOP-Tuning(Domain-Oriented Prefix-tuning model)
DOP-Tuning DOP-Tuning(Domain-Oriented Prefix-tuning model)代码基于Prefix-Tuning改进. Files ├── seq2seq # Code for encoder-decoder arch
 5 Nov 2, 2022
5 Nov 2, 2022
Interactive Visualization to empower domain experts to align ML model behaviors with their knowledge.
An interactive visualization system designed to helps domain experts responsibly edit Generalized Additive Models (GAMs). For more information, check
 83 Jan 4, 2023
83 Jan 4, 2023

CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks
CALVIN CALVIN - A benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks Oier Mees, Lukas Hermann, Erick Rosete,
 107 Dec 26, 2022
107 Dec 26, 2022

Hashformers is a framework for hashtag segmentation with transformers.
Hashtag segmentation is the task of automatically inserting the missing spaces between the words in a hashtag. Hashformers applies Transformer models
 41 Nov 9, 2022
41 Nov 9, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
 20 May 17, 2022
20 May 17, 2022

Meandering In Networks of Entities to Reach Verisimilar Answers
MINERVA Meandering In Networks of Entities to Reach Verisimilar Answers Code and models for the paper Go for a Walk and Arrive at the Answer - Reasoni
 271 Dec 13, 2022
271 Dec 13, 2022

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
 862 Jan 1, 2023
862 Jan 1, 2023
A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion
A Conditional Point Diffusion-Refinement Paradigm for 3D Point Cloud Completion This repo intends to release code for our work: Zhaoyang Lyu*, Zhifeng
 68 Jan 3, 2023
68 Jan 3, 2023
RaceBERT -- A transformer based model to predict race and ethnicty from names
RaceBERT -- A transformer based model to predict race and ethnicty from names Installation pip install racebert Using a virtual environment is highly
 3 Nov 2, 2022
3 Nov 2, 2022
BrainGNN - A deep learning model for data-driven discovery of functional connectivity
A deep learning model for data-driven discovery of functional connectivity https://doi.org/10.3390/a14030075 Usman Mahmood, Zengin Fu, Vince D. Calhou
 3 Aug 28, 2022
3 Aug 28, 2022
Pretrained Cost Model for Distributed Constraint Optimization Problems
Pretrained Cost Model for Distributed Constraint Optimization Problems Requirements PyTorch 1.9.0 PyTorch Geometric 1.7.1 Directory structure baseline
 2 Aug 28, 2022
2 Aug 28, 2022

Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand Introduction We propose a generalization of leaderboards, bidimensional leader
 4 Dec 3, 2022
4 Dec 3, 2022
Suite of 500 procedurally-generated NLP tasks to study language model adaptability
TaskBench500 The TaskBench500 dataset and code for generating tasks. Data The TaskBench dataset is available under wget http://web.mit.edu/bzl/www/Tas
20 May 17, 2022
![[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining](https://github.com/microsoft/COCO-LM/raw/main/coco-lm.png)
[NeurIPS 2021] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
COCO-LM This repository contains the scripts for fine-tuning COCO-LM pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: COCO-LM: Correcting an
106 Dec 12, 2022
An ongoing curated list of frameworks, libraries, learning tutorials, software and resources in Python Language.
Python Development Welcome to the world of Python. An ongoing curated list of frameworks, libraries, learning tutorials, software and resources in Pyt
 2 Dec 24, 2021
2 Dec 24, 2021
A python server markup language
PSML - Python server markup language How to install: python install.py
 6 May 18, 2022
6 May 18, 2022

Free Vocabulary Trainer - not only for German, but any language
Bilderraten DOWNLOAD THE EXE FILE HERE! What can you do with it? Vocabulary Trainer for any language Use your own vocabulary list No coding required!
 4 Jan 2, 2023
4 Jan 2, 2023
Correcting typos in a word based on the frequency dictionary
Auto-correct text Correcting typos in a word based on the frequency dictionary. This algorithm is based on the distance between words according to the
 2 Feb 5, 2022
2 Feb 5, 2022

Two factor authentication system using azure services and python language and its api's
FUTURE READY TALENT VIRTUAL INTERSHIP PROJECT PROJECT NAME - TWO FACTOR AUTHENTICATION SYSTEM Resources used: * Azure functions(python)
 1 Dec 10, 2021
1 Dec 10, 2021

Генератор отчетов на Python с использованием библиотеки docx для работы с word-файлами и запросов к сервису
Генератор отчетов на Python с использованием библиотеки docx для работы с word-файлами и запросов к сервису
 2 Jun 24, 2022
2 Jun 24, 2022
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
8 Aug 10, 2022
Functions to analyze Cell-ID single-cell cytometry data using python language.
PyCellID (building...) Functions to analyze Cell-ID single-cell cytometry data using python language. Dependecies for this project. attrs(=21.1.0) fo
 0 Dec 22, 2021
0 Dec 22, 2021
Data pipelines for both TensorFlow and PyTorch!
rapidnlp-datasets Data pipelines for both TensorFlow and PyTorch ! If you want to load public datasets, try: tensorflow/datasets huggingface/datasets
 1 Dec 8, 2021
1 Dec 8, 2021

My tensorflow implementation of "A neural conversational model", a Deep learning based chatbot
Deep Q&A Table of Contents Presentation Installation Running Chatbot Web interface Results Pretrained model Improvements Upgrade Presentation This wor
 2.9k Dec 28, 2022
2.9k Dec 28, 2022

Tensorflow implementation of Character-Aware Neural Language Models.
Character-Aware Neural Language Models Tensorflow implementation of Character-Aware Neural Language Models. The original code of author can be found h
 751 Dec 26, 2022
751 Dec 26, 2022

A Tensorfflow implementation of Attend, Infer, Repeat
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models This is an unofficial Tensorflow implementation of Attend, Infear, Repeat (AIR)
 82 May 27, 2022
82 May 27, 2022
Sarus implementation of classical ML models. The models are implemented using the Keras API of tensorflow 2. Vizualization are implemented and can be seen in tensorboard.
Sarus published models Sarus implementation of classical ML models. The models are implemented using the Keras API of tensorflow 2. Vizualization are
 39 Aug 19, 2022
39 Aug 19, 2022

Defending against Model Stealing via Verifying Embedded External Features
Defending against Model Stealing Attacks via Verifying Embedded External Features This is the official implementation of our paper Defending against M
 20 Dec 30, 2022
20 Dec 30, 2022
Unofficial Implementation of MLP-Mixer, Image Classification Model
MLP-Mixer Unoffical Implementation of MLP-Mixer, easy to use with terminal. Train and test easly. https://arxiv.org/abs/2105.01601 MLP-Mixer is an arc
 6 Dec 5, 2022
6 Dec 5, 2022
A design of MIDI language for music generation task, specifically for Natural Language Processing (NLP) models.
MIDI Language Introduction Reference Paper: Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions: code This
 3 May 25, 2022
3 May 25, 2022
Dragon Age: Origins toolset to extract/build .erf files, patch language-specific .dlg files, and view the contents of files in the ERF or GFF format
DAOTools This is a set of tools for Dragon Age: Origins modding. It can patch the text lines of .dlg files, extract and build an .erf file, and view t
 8 Dec 6, 2022
8 Dec 6, 2022
DG - A(n) (unusual) programming language
DG - A(n) (unusual) programming language General structure There are no infix-operators (i.e. 1 + 1) Each operator takes 2 parameters When there are m
 1 Mar 5, 2022
1 Mar 5, 2022
SLAMP: Stochastic Latent Appearance and Motion Prediction
SLAMP: Stochastic Latent Appearance and Motion Prediction Official implementation of the paper SLAMP: Stochastic Latent Appearance and Motion Predicti
 34 Dec 8, 2022
34 Dec 8, 2022

A PaddlePaddle implementation of STGCN with a few modifications in the model architecture in order to forecast traffic jam.
About This repository contains the code of a PaddlePaddle implementation of STGCN based on the paper Spatio-Temporal Graph Convolutional Networks: A D
 1 Jan 11, 2022
1 Jan 11, 2022
The Codebase for Causal Distillation for Language Models.
Causal Distillation for Language Models Zhengxuan Wu*,Atticus Geiger*, Josh Rozner, Elisa Kreiss, Hanson Lu, Thomas Icard, Christopher Potts, Noah D.
 20 Dec 31, 2022
20 Dec 31, 2022
NL-Augmenter 🦎 → 🐍 A Collaborative Repository of Natural Language Transformations
NL-Augmenter 🦎 → 🐍 The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformat
 684 Jan 9, 2023
684 Jan 9, 2023

A new play-and-plug method of controlling an existing generative model with conditioning attributes and their compositions.
Controllable and Compositional Generation with Latent-Space Energy-Based Models Official PyTorch implementation of the NeurIPS 2021 paper: Controllabl
 66 Jan 1, 2023
66 Jan 1, 2023
Simple bots or Simbots is a library designed to create simple bots using the power of python. This library utilises Intent, Entity, Relation and Context model to create bots .
Simple bots or Simbots is a library designed to create simple chat bots using the power of python. This library utilises Intent, Entity, Relation and
 14 Dec 15, 2021
14 Dec 15, 2021
Train and use generative text models in a few lines of code.
blather Train and use generative text models in a few lines of code. To see blather in action check out the colab notebook! Installation Use the packa
 16 Nov 7, 2022
16 Nov 7, 2022
Convert ONNX model graph to Keras model format.
Convert ONNX model graph to Keras model format.
 175 Dec 28, 2022
175 Dec 28, 2022
Yas CRNN model training - Yet Another Genshin Impact Scanner
Yas-Train Yet Another Genshin Impact Scanner 又一个原神圣遗物导出器 介绍 该仓库为 Yas 的模型训练程序 相关资料 MobileNetV3 CRNN 使用 假设你会设置基本的pytorch环境。 生成数据集 python main.py gen 训练
 18 Jan 8, 2023
18 Jan 8, 2023

A simple tool made in Python language
Simple tool Uma simples ferramenta feita 100% em linguagem Python 💻 Requisitos: Python3 instalado em seu dispositivo Clonagem e acesso 📳 git clone h
 4 Dec 7, 2021
4 Dec 7, 2021

ColorController is a Pythonic interface for managing colors by english-language name and various color values.
ColorController.py Table of Contents Encode color data in various formats. 1.1: Create a ColorController object using a familiar, english-language col
 2 Feb 12, 2022
2 Feb 12, 2022
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 0 Mar 20, 2022
0 Mar 20, 2022
Deep learning model for EEG artifact removal
DeepSeparator Introduction Electroencephalogram (EEG) recordings are often contaminated with artifacts. Various methods have been developed to elimina
 23 Dec 21, 2022
23 Dec 21, 2022
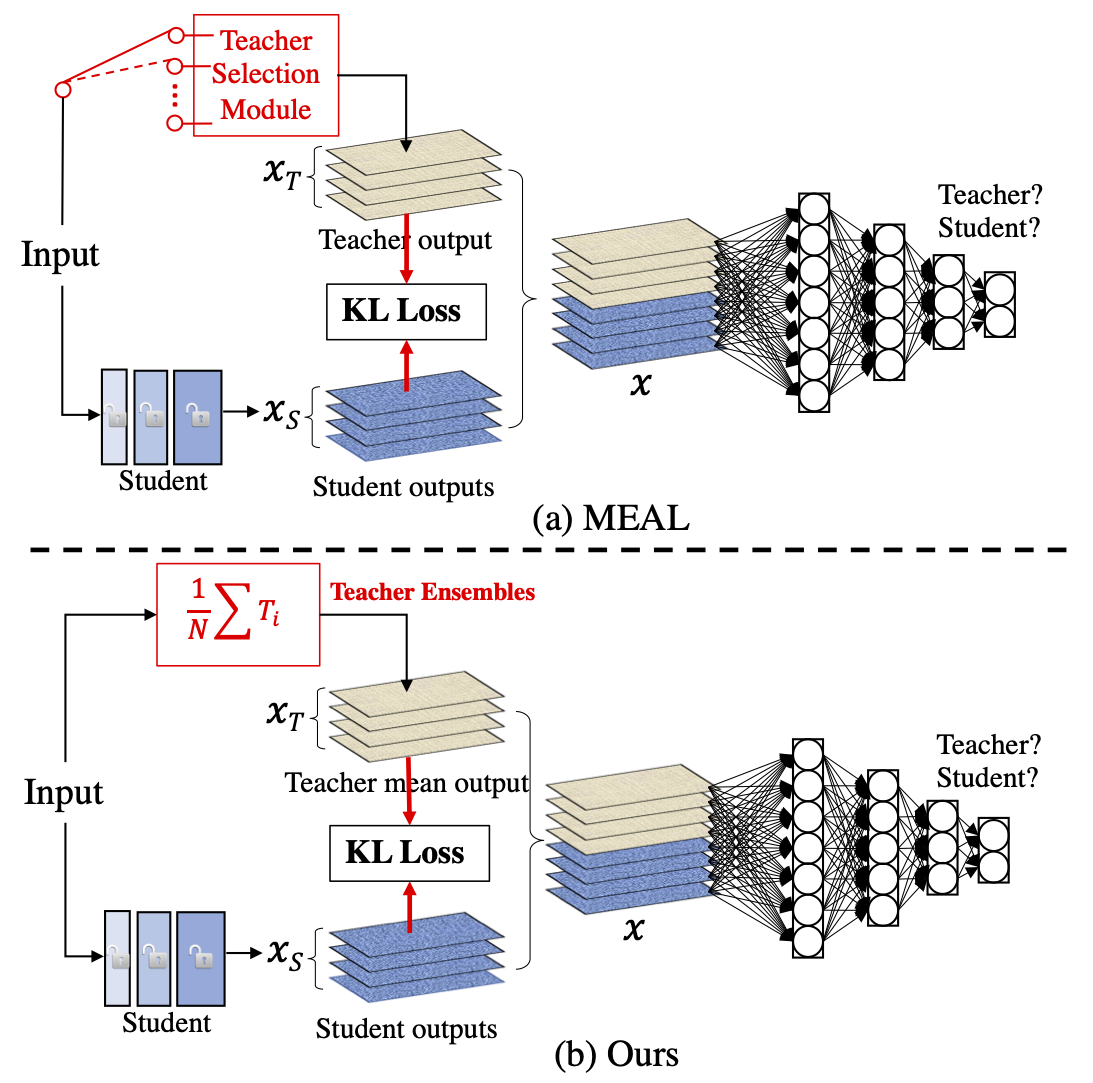
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
MEAL-V2 This is the official pytorch implementation of our paper: "MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tric
 653 Dec 19, 2022
653 Dec 19, 2022

A visual dataflow programming language for sklearn
Persimmon What is it? Persimmon is a visual dataflow language for creating sklearn pipelines. It represents functions as blocks, inputs and outputs ar
 194 Jan 4, 2023
194 Jan 4, 2023

Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking and Jupyter notebook analysis.
sklearn-evaluation Machine learning model evaluation made easy: plots, tables, HTML reports, experiment tracking, and Jupyter notebook analysis. Suppo
 354 Dec 31, 2022
354 Dec 31, 2022
A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
AI Fairness 360 (AIF360) The AI Fairness 360 toolkit is an extensible open-source library containg techniques developed by the research community to h
 1.9k Jan 6, 2023
1.9k Jan 6, 2023
A Chinese to English Neural Model Translation Project
ZH-EN NMT Chinese to English Neural Machine Translation This project is inspired by Stanford's CS224N NMT Project Dataset used in this project: News C
 29 Nov 26, 2022
29 Nov 26, 2022

Contra is a lightweight, production ready Tensorflow alternative for solving time series prediction challenges with AI
Contra AI Engine A lightweight, production ready Tensorflow alternative developed by Styvio styvio.com » How to Use · Report Bug · Request Feature Tab
 14 May 25, 2022
14 May 25, 2022

A programming language written with python
Kaoft A programming language written with python How to use A simple Hello World: c="Hello World" c Output: "Hello World" Operators: a=12
 1 Jan 24, 2022
1 Jan 24, 2022

Diffusion Probabilistic Models for 3D Point Cloud Generation (CVPR 2021)
Diffusion Probabilistic Models for 3D Point Cloud Generation [Paper] [Code] The official code repository for our CVPR 2021 paper "Diffusion Probabilis
 323 Jan 5, 2023
323 Jan 5, 2023
Website for D2C paper
D2C This is the repository that contains source code for the D2C Website. If you find D2C useful for your work please cite: @article{sinha2021d2c au
 1 Oct 21, 2021
1 Oct 21, 2021
A collection of resources and papers on Diffusion Models, a darkhorse in the field of Generative Models
This repository contains a collection of resources and papers on Diffusion Models and Score-based Models. If there are any missing valuable resources
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
A Loss Function for Generative Neural Networks Based on Watson’s Perceptual Model
This repository contains the similarity metrics designed and evaluated in the paper, and instructions and code to re-run the experiments. Implementation in the deep-learning framework PyTorch
 86 Dec 27, 2022
86 Dec 27, 2022
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

Model-based Reinforcement Learning Improves Autonomous Racing Performance
Racing Dreamer: Model-based versus Model-free Deep Reinforcement Learning for Autonomous Racing Cars In this work, we propose to learn a racing contro
 38 Dec 6, 2022
38 Dec 6, 2022
A Python script which randomly chooses and prints a file from a directory.
___ ____ ____ _ __ ___ / _ \ | _ \ | _ \ ___ _ __ | '__| / _ \ | |_| || | | || | | | / _ \| '__| | | | __/ | _ || |_| || |_| || __
 0 Aug 6, 2021
0 Aug 6, 2021
Quick program made to generate alpha and delta tables for Hidden Markov Models
HMM_Calc Functions for generating Alpha and Delta tables from a Hidden Markov Model. Parameters: a: Matrix of transition probabilities. a[i][j] = a_{i
 1 Dec 4, 2021
1 Dec 4, 2021
Sample Prior Guided Robust Model Learning to Suppress Noisy Labels
PGDF This repo is the official implementation of our paper "Sample Prior Guided Robust Model Learning to Suppress Noisy Labels ". Citation If you use
 22 Dec 23, 2022
22 Dec 23, 2022
100+ Chinese Word Vectors 上百种预训练中文词向量
Chinese Word Vectors 中文词向量 中文 This project provides 100+ Chinese Word Vectors (embeddings) trained with different representations (dense and sparse),
 10.4k Jan 9, 2023
10.4k Jan 9, 2023

Tensorflow implementation of Semi-supervised Sequence Learning (https://arxiv.org/abs/1511.01432)
Transfer Learning for Text Classification with Tensorflow Tensorflow implementation of Semi-supervised Sequence Learning(https://arxiv.org/abs/1511.01
 82 Oct 22, 2022
82 Oct 22, 2022
torchbearer: A model fitting library for PyTorch
Note: We're moving to PyTorch Lightning! Read about the move here. From the end of February, torchbearer will no longer be actively maintained. We'll
 632 Dec 13, 2022
632 Dec 13, 2022
A project to make Amazon Echo respond to sign language using your webcam
Making Alexa respond to Sign Language using Tensorflow.js Try the live demo Read the Blog Post on Tensorflow's Blog Coming Soon Watch the video This p
 444 Jan 3, 2023
444 Jan 3, 2023
Natural Language Processing Tasks and Examples.
Natural Language Processing Tasks and Examples With the advancement of A.I. technology in recent years, natural language processing technology has bee
 53 Dec 20, 2022
53 Dec 20, 2022
CLIP (Contrastive Language–Image Pre-training) trained on Indonesian data
CLIP-Indonesian CLIP (Radford et al., 2021) is a multimodal model that can connect images and text by training a vision encoder and a text encoder joi
 17 Mar 10, 2022
17 Mar 10, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022
you can add any codes in any language by creating its respective folder (if already not available).
HACKTOBERFEST-2021-WEB-DEV Beginner-Hacktoberfest Need Your first pr for hacktoberfest 2k21 ? come on in About This is repository of Responsive Portfo
 8 Oct 17, 2022
8 Oct 17, 2022
Small C-like language compiler for the Uxn assembly language
Pyuxncle is a single-pass compiler for a small subset of C (albeit without the std library). This compiler targets Uxntal, the assembly language of the Uxn virtual computer. The output Uxntal is not meant to be human readable, only to be directly passed to uxnasm.
 13 Jun 28, 2022
13 Jun 28, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
 303 Dec 17, 2022
303 Dec 17, 2022
GPT-3: Language Models are Few-Shot Learners
GPT-3: Language Models are Few-Shot Learners arXiv link Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-trainin
 12.5k Jan 5, 2023
12.5k Jan 5, 2023

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
MPNet: Masked and Permuted Pre-training for Language Understanding
MPNet MPNet: Masked and Permuted Pre-training for Language Understanding, by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu, is a novel pre-tr
228 Nov 21, 2022
Optimus: the first large-scale pre-trained VAE language model
Optimus: the first pre-trained Big VAE language model This repository contains source code necessary to reproduce the results presented in the EMNLP 2
 314 Dec 19, 2022
314 Dec 19, 2022
(ACL-IJCNLP 2021) Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models.
BERT Convolutions Code for the paper Convolutions and Self-Attention: Re-interpreting Relative Positions in Pre-trained Language Models. Contains expe
 21 Jul 18, 2022
21 Jul 18, 2022
Source code and dataset for ACL 2019 paper "ERNIE: Enhanced Language Representation with Informative Entities"
ERNIE Source code and dataset for "ERNIE: Enhanced Language Representation with Informative Entities" Reqirements: Pytorch=0.4.1 Python3 tqdm boto3 r
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023
LUKE -- Language Understanding with Knowledge-based Embeddings
LUKE (Language Understanding with Knowledge-based Embeddings) is a new pre-trained contextualized representation of words and entities based on transf
 587 Dec 30, 2022
587 Dec 30, 2022
Source code for TACL paper "KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation".
KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation Source code for TACL 2021 paper KEPLER: A Unified Model for Kn
 138 Dec 22, 2022
138 Dec 22, 2022