1987 Repositories
Python Offline-Pre-trained-Multi-Agent-Decision-Transformer Libraries
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation "
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022

Code for the paper "Reinforcement Learning as One Big Sequence Modeling Problem"
Trajectory Transformer Code release for Reinforcement Learning as One Big Sequence Modeling Problem. Installation All python dependencies are in envir
 269 Jan 5, 2023
269 Jan 5, 2023
Voxel Transformer for 3D object detection
Voxel Transformer This is a reproduced repo of Voxel Transformer for 3D object detection. The code is mainly based on OpenPCDet. Introduction We provi
 173 Dec 25, 2022
173 Dec 25, 2022
![[ICCV 2021] Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation](https://github.com/ziniuwan/maed/raw/master/doc/figs/net_arch.png)
[ICCV 2021] Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation
MAED: Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation Getting Started Our codes are implemented and tested with pyth
 176 Dec 15, 2022
176 Dec 15, 2022

CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection
CVE-2021-26084 - Confluence Pre-Auth RCE OGNL injection Usage usage: cve-2021-26084_confluence_rce.py [-h] --url URL [--cmd CMD] [--shell] CVE-2021-2
 92 Jul 20, 2022
92 Jul 20, 2022

Adaptive Pyramid Context Network for Semantic Segmentation (APCNet CVPR'2019)
Adaptive Pyramid Context Network for Semantic Segmentation (APCNet CVPR'2019) Introduction Official implementation of Adaptive Pyramid Context Network
 21 Nov 9, 2022
21 Nov 9, 2022
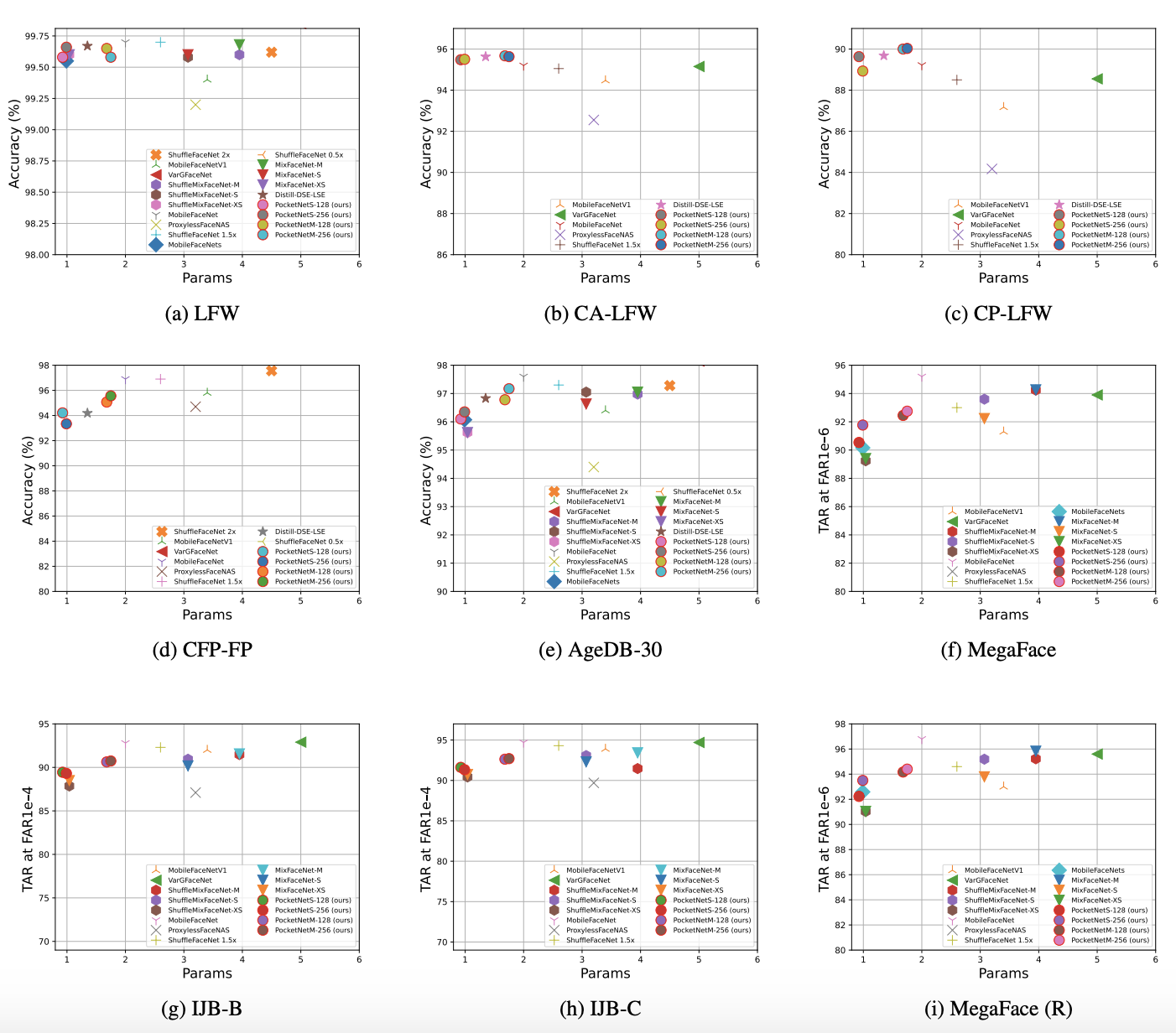
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
PocketNet This is the official repository of the paper: PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and M
 40 Dec 22, 2022
40 Dec 22, 2022

ZSL-KG is a general-purpose zero-shot learning framework with a novel transformer graph convolutional network (TrGCN) to learn class representation from common sense knowledge graphs.
ZSL-KG is a general-purpose zero-shot learning framework with a novel transformer graph convolutional network (TrGCN) to learn class representa
 94 Nov 21, 2022
94 Nov 21, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

Multi-view 3D reconstruction using neural rendering. Unofficial implementation of UNISURF, VolSDF, NeuS and more.
Multi-view 3D reconstruction using neural rendering. Unofficial implementation of UNISURF, VolSDF, NeuS and more.
 683 Jan 4, 2023
683 Jan 4, 2023
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
multi-label,classifier,text classification,多标签文本分类,文本分类,BERT,ALBERT,multi-label-classification,seq2seq,attention,beam search
 30 Dec 12, 2022
30 Dec 12, 2022

Train GPT-3 model on V100(16GB Mem) Using improved Transformer.
GPT-X using transformer pytorch
 24 Sep 11, 2022
24 Sep 11, 2022

Code for "Searching for Efficient Multi-Stage Vision Transformers"
Searching for Efficient Multi-Stage Vision Transformers This repository contains the official Pytorch implementation of "Searching for Efficient Multi
 62 Oct 25, 2022
62 Oct 25, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
超轻量级bert的pytorch版本,大量中文注释,容易修改结构,持续更新
bert4pytorch 2021年8月27更新: 感谢大家的star,最近有小伙伴反映了一些小的bug,我也注意到了,奈何这个月工作上实在太忙,更新不及时,大约会在9月中旬集中更新一个只需要pip一下就完全可用的版本,然后会新添加一些关键注释。 再增加对抗训练的内容,更新一个完整的finetune
 317 Dec 18, 2022
317 Dec 18, 2022
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
WarpDrive is a flexible, lightweight, and easy-to-use open-source reinforcement learning (RL) framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit).
 334 Jan 6, 2023
334 Jan 6, 2023
![[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo](https://github.com/weiyithu/NerfingMVS/raw/main/imgs/demo.gif)
[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo
NerfingMVS Project Page | Paper | Video | Data NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo Yi Wei, Shaohui
 369 Dec 24, 2022
369 Dec 24, 2022
TAPEX: Table Pre-training via Learning a Neural SQL Executor
TAPEX: Table Pre-training via Learning a Neural SQL Executor The official repository which contains the code and pre-trained models for our paper TAPE
 157 Dec 28, 2022
157 Dec 28, 2022

Official code of ICCV2021 paper "Residual Attention: A Simple but Effective Method for Multi-Label Recognition"
CSRA This is the official code of ICCV 2021 paper: Residual Attention: A Simple But Effective Method for Multi-Label Recoginition Demo, Train and Vali
 163 Dec 22, 2022
163 Dec 22, 2022
EMNLP 2021 - Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling This is the official implementation for "Frustratingly Simple Pretraining Al
 31 Nov 18, 2022
31 Nov 18, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022
Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs
Perceiver IO Unofficial implementation of Perceiver IO: A General Architecture for Structured Inputs & Outputs Usage import torch from src.perceiver.
 111 Nov 15, 2022
111 Nov 15, 2022
The official repository for our paper "The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers". We significantly improve the systematic generalization of transformer models on a variety of datasets using simple tricks and careful considerations.
Codebase for training transformers on systematic generalization datasets. The official repository for our EMNLP 2021 paper The Devil is in the Detail:
 57 Nov 21, 2022
57 Nov 21, 2022
Codes to pre-train Japanese T5 models
t5-japanese Codes to pre-train a T5 (Text-to-Text Transfer Transformer) model pre-trained on Japanese web texts. The model is available at https://hug
 37 Dec 25, 2022
37 Dec 25, 2022

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
 54 Aug 30, 2021
54 Aug 30, 2021
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
 65 Oct 4, 2022
65 Oct 4, 2022

Code for our ALiBi method for transformer language models.
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation This repository contains the code and models for our paper Tra
 211 Dec 31, 2022
211 Dec 31, 2022
[ICCV 2021] Official Pytorch implementation for Discriminative Region-based Multi-Label Zero-Shot Learning SOTA results on NUS-WIDE and OpenImages
Discriminative Region-based Multi-Label Zero-Shot Learning (ICCV 2021) [arXiv][Project page coming soon] Sanath Narayan*, Akshita Gupta*, Salman Kh
 54 Nov 21, 2022
54 Nov 21, 2022

Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
![[ICCV'21] Official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations](https://github.com/vita-epfl/social-nce-crowdnav/raw/main/docs/illustration.png)
[ICCV'21] Official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations
CrowdNav with Social-NCE This is an official implementation for the paper Social NCE: Contrastive Learning of Socially-aware Motion Representations by
 125 Dec 23, 2022
125 Dec 23, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
[ICCV 2021] Official Pytorch implementation for Discriminative Region-based Multi-Label Zero-Shot Learning SOTA results on NUS-WIDE and OpenImages
Discriminative Region-based Multi-Label Zero-Shot Learning (ICCV 2021) [arXiv][Project page coming soon] Sanath Narayan*, Akshita Gupta*, Salman Kh
54 Nov 21, 2022
A PyTorch implementation of the Transformer model in "Attention is All You Need".
Attention is all you need: A Pytorch Implementation This is a PyTorch implementation of the Transformer model in "Attention is All You Need" (Ashish V
 7.1k Jan 5, 2023
7.1k Jan 5, 2023
Implementation of Fast Transformer in Pytorch
Fast Transformer - Pytorch Implementation of Fast Transformer in Pytorch. This only work as an encoder. Yannic video AI Epiphany Install $ pip install
167 Dec 27, 2022
Implementation of a Transformer that Ponders, using the scheme from the PonderNet paper
Ponder(ing) Transformer Implementation of a Transformer that learns to adapt the number of computational steps it takes depending on the difficulty of
65 Oct 4, 2022

Official code for paper "Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight"
Demysitifing Local Vision Transformer, arxiv This is the official PyTorch implementation of our paper. We simply replace local self attention by (dyna
 138 Dec 28, 2022
138 Dec 28, 2022

Official code for "Focal Self-attention for Local-Global Interactions in Vision Transformers"
Focal Transformer This is the official implementation of our Focal Transformer -- "Focal Self-attention for Local-Global Interactions in Vision Transf
486 Dec 20, 2022

A PyTorch implementation of "Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning", IJCAI-21
MERIT A PyTorch implementation of our IJCAI-21 paper Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning. Depen
 32 Jan 2, 2023
32 Jan 2, 2023
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022

Online Multi-Granularity Distillation for GAN Compression (ICCV2021)
Online Multi-Granularity Distillation for GAN Compression (ICCV2021) This repository contains the pytorch codes and trained models described in the IC
 299 Dec 16, 2022
299 Dec 16, 2022

Transformer model implemented with Pytorch
transformer-pytorch Transformer model implemented with Pytorch Attention is all you need-[Paper] Architecture Self-Attention self_attention.py class
 12 Sep 3, 2022
12 Sep 3, 2022
Extract knowledge from raw text
Extract knowledge from raw text This repository is a nearly copy-paste of "From Text to Knowledge: The Information Extraction Pipeline" with some cosm
 10 Dec 3, 2022
10 Dec 3, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

Official implementation of the ICCV 2021 paper "Conditional DETR for Fast Training Convergence".
The DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings and that the spatial embeddings make minor contributions, increasing the need for high-quality content embeddings and thus increasing the training difficulty.
281 Dec 30, 2022
The official code for paper "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Modeling".
R2D2 This is the official code for paper titled "R2D2: Recursive Transformer based on Differentiable Tree for Interpretable Hierarchical Language Mode
 49 Dec 17, 2022
49 Dec 17, 2022

Compute descriptors for 3D point cloud registration using a multi scale sparse voxel architecture
MS-SVConv : 3D Point Cloud Registration with Multi-Scale Architecture and Self-supervised Fine-tuning Compute features for 3D point cloud registration
 42 Jul 25, 2022
42 Jul 25, 2022

Reference code for the paper CAMS: Color-Aware Multi-Style Transfer.
CAMS: Color-Aware Multi-Style Transfer Mahmoud Afifi1, Abdullah Abuolaim*1, Mostafa Hussien*2, Marcus A. Brubaker1, Michael S. Brown1 1York University
 36 Dec 4, 2022
36 Dec 4, 2022

This is an official implementation of the High-Resolution Transformer for Dense Prediction.
High-Resolution Transformer for Dense Prediction Introduction This is the official implementation of High-Resolution Transformer (HRT). We present a H
 403 Dec 13, 2022
403 Dec 13, 2022

Official PaddlePaddle implementation of Paint Transformer
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction [Paper] [Paddle Implementation] Update We have optimized the serial inference p
 284 Dec 31, 2022
284 Dec 31, 2022
This Telegram bot allows you to create direct links with pre-filled text to WhatsApp Chats
WhatsApp API Bot Telegram bot to create direct links with pre-filled text for WhatsApp Chats You can check our bot here. The bot is based on the API p
 17 Aug 20, 2022
17 Aug 20, 2022
EzilaX Music ❤ is the best and only Telegram VC player with playlists, Multi Playback, Channel play and more POWERD By SDBOTs
EzilaX-Music 🎵 A bot that can play music on Telegram Group and Channel Voice Chats Available on telegram as @EzilaXMBot Features 🔥 Thumbnail Support
 9 Oct 24, 2021
9 Oct 24, 2021

Customizable RecSys Simulator for OpenAI Gym
gym-recsys: Customizable RecSys Simulator for OpenAI Gym Installation | How to use | Examples | Citation This package describes an OpenAI Gym interfac
 14 Dec 8, 2022
14 Dec 8, 2022
MINERVA: An out-of-the-box GUI tool for offline deep reinforcement learning
MINERVA is an out-of-the-box GUI tool for offline deep reinforcement learning, designed for everyone including non-programmers to do reinforcement learning as a tool.
 80 Nov 6, 2022
80 Nov 6, 2022

3D position tracking for soccer players with multi-camera videos
This repo contains a full pipeline to support 3D position tracking of soccer players, with multi-view calibrated moving/fixed video sequences as inputs.
 72 Dec 27, 2022
72 Dec 27, 2022
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022
LONG-TERM SERIES FORECASTING WITH QUERYSELECTOR – EFFICIENT MODEL OF SPARSEATTENTION
Query Selector Here you can find code and data loaders for the paper https://arxiv.org/pdf/2107.08687v1.pdf . Query Selector is a novel approach to sp
 62 Dec 17, 2022
62 Dec 17, 2022
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
 41 Jan 3, 2023
41 Jan 3, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023

Stacked Hourglass Network with a Multi-level Attention Mechanism: Where to Look for Intervertebral Disc Labeling
⚠️ A more recent and actively-maintained version of this code is available in ivadomed Stacked Hourglass Network with a Multi-level Attention Mech
 14 Oct 24, 2022
14 Oct 24, 2022
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
"Segmenter: Transformer for Semantic Segmentation" reproduced via mmsegmentation
Segmenter-based-on-OpenMMLab "Segmenter: Transformer for Semantic Segmentation, arxiv 2105.05633." reproduced via mmsegmentation. We reproduce Segment
 22 Feb 24, 2022
22 Feb 24, 2022

Learning and Building Convolutional Neural Networks using PyTorch
Image Classification Using Deep Learning Learning and Building Convolutional Neural Networks using PyTorch. Models, selected are based on number of ci
 126 Dec 22, 2022
126 Dec 22, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022

Code for "Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo"
Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo This repository includes the source code for our CVPR 2021 paper on multi-view mult
 66 Jan 4, 2023
66 Jan 4, 2023
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
Code for EmBERT, a transformer model for embodied, language-guided visual task completion.
41 Jan 3, 2023

Official code for "Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer. ICCV2021".
Simpler is Better: Few-shot Semantic Segmentation with Classifier Weight Transformer. ICCV2021. Introduction We proposed a novel model training paradi
 103 Dec 14, 2022
103 Dec 14, 2022

Vision Transformer and MLP-Mixer Architectures
Vision Transformer and MLP-Mixer Architectures Update (2.7.2021): Added the "When Vision Transformers Outperform ResNets..." paper, and SAM (Sharpness
 6.4k Jan 4, 2023
6.4k Jan 4, 2023
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022

This is the official implementation for "Do Transformers Really Perform Bad for Graph Representation?".
Graphormer By Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng*, Guolin Ke, Di He*, Yanming Shen and Tie-Yan Liu. This repo is the official impl
1.3k Dec 26, 2022

Homepage of paper: Paint Transformer: Feed Forward Neural Painting with Stroke Prediction, ICCV 2021.
Paint Transformer: Feed Forward Neural Painting with Stroke Prediction [Paper] [PaddlePaddle Implementation] Homepage of paper: Paint Transformer: Fee
 442 Dec 16, 2022
442 Dec 16, 2022

This repository contains PyTorch models for SpecTr (Spectral Transformer).
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation This repository contains PyTorch models for SpecTr (Spectral Transformer).
 45 Dec 13, 2022
45 Dec 13, 2022
Code for "Multi-Compound Transformer for Accurate Biomedical Image Segmentation"
News The code of MCTrans has been released. if you are interested in contributing to the standardization of the medical image analysis community, plea
 97 Jan 5, 2023
97 Jan 5, 2023
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
Sign Language Translation with Transformers (COLING'2020, ECCV'20 SLRTP Workshop)
transformer-slt This repository gathers data and code supporting the experiments in the paper Better Sign Language Translation with STMC-Transformer.
 107 Dec 27, 2022
107 Dec 27, 2022

Pre-Trained Image Processing Transformer (IPT)
Pre-Trained Image Processing Transformer (IPT) By Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Cha
 332 Dec 18, 2022
332 Dec 18, 2022

Official PyTorch implementation of Segmenter: Transformer for Semantic Segmentation
Segmenter: Transformer for Semantic Segmentation Segmenter: Transformer for Semantic Segmentation by Robin Strudel*, Ricardo Garcia*, Ivan Laptev and
 594 Jan 6, 2023
594 Jan 6, 2023

This repository is an official implementation of the paper MOTR: End-to-End Multiple-Object Tracking with TRansformer.
MOTR: End-to-End Multiple-Object Tracking with TRansformer This repository is an official implementation of the paper MOTR: End-to-End Multiple-Object
 348 Jan 7, 2023
348 Jan 7, 2023

This is an official implementation for "Self-Supervised Learning with Swin Transformers".
Self-Supervised Learning with Vision Transformers By Zhenda Xie*, Yutong Lin*, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao and Han Hu This repo is the
 529 Jan 2, 2023
529 Jan 2, 2023
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
712 Dec 19, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training.
Updates (2020/06/21) Code of PVTv2 is released! PVTv2 largely improves PVTv1 and works better than Swin Transformer with ImageNet-1K pre-training. Pyr
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
2.5k Jan 6, 2023
Full-text multi-table search application for Django. Easy to install and use, with good performance.
django-watson django-watson is a fast multi-model full-text search plugin for Django. It is easy to install and use, and provides high quality search
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Collective Multi-type Entity Alignment Between Knowledge Graphs (WWW'20)
CG-MuAlign A reference implementation for "Collective Multi-type Entity Alignment Between Knowledge Graphs", published in WWW 2020. If you find our pa
 28 Dec 11, 2022
28 Dec 11, 2022

Emotional conditioned music generation using transformer-based model.
This is the official repository of EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-based Music Generation. The paper has b
 96 Nov 9, 2022
96 Nov 9, 2022

Official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
Vision Transformer with Progressive Sampling This is the official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
 123 Jan 1, 2023
123 Jan 1, 2023

This is official implementaion of paper "Token Shift Transformer for Video Classification".
This is official implementaion of paper "Token Shift Transformer for Video Classification". We achieve SOTA performance 80.40% on Kinetics-400 val. Paper link
 60 Dec 30, 2022
60 Dec 30, 2022
Orthrus is a macOS agent that uses Apple's MDM to backdoor a device using a malicious profile.
Orthrus is a macOS agent that uses Apple's MDM to backdoor a device using a malicious profile. It effectively runs its own MDM server and allows the operator to interface with it using Mythic.
 37 Dec 6, 2022
37 Dec 6, 2022

Official implementation of paper "Query2Label: A Simple Transformer Way to Multi-Label Classification".
Introdunction This is the official implementation of the paper "Query2Label: A Simple Transformer Way to Multi-Label Classification". Abstract This pa
 274 Dec 28, 2022
274 Dec 28, 2022
Scenic: A Jax Library for Computer Vision and Beyond
Scenic Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop c
1.6k Dec 27, 2022

Pytorch implementation of CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generation"
MUST-GAN Code | paper The Pytorch implementation of our CVPR2021 paper "MUST-GAN: Multi-level Statistics Transfer for Self-driven Person Image Generat
 46 Dec 26, 2022
46 Dec 26, 2022

A Multi-modal Model Chinese Spell Checker Released on ACL2021.
ReaLiSe ReaLiSe is a multi-modal Chinese spell checking model. This the office code for the paper Read, Listen, and See: Leveraging Multimodal Informa
 106 Dec 29, 2022
106 Dec 29, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022
DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021)
DPT This repo is the official implementation of DPT: Deformable Patch-based Transformer for Visual Recognition (ACM MM2021). We provide code and model
 111 Dec 21, 2022
111 Dec 21, 2022