1617 Repositories
Python Train-Test-Validation-Dataset-Generation Libraries

CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
CSAW-M This repository contains code for CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer. Source code for tr
 7 Oct 11, 2022
7 Oct 11, 2022

PartImageNet is a large, high-quality dataset with part segmentation annotations
PartImageNet: A Large, High-Quality Dataset of Parts We will release our dataset and scripts soon after cleaning and approval. Introduction PartImageN
 77 Nov 30, 2022
77 Nov 30, 2022

Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
 2 Dec 2, 2021
2 Dec 2, 2021
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation Woncheol Shin1, Gyubok Lee1, Jiyoung Lee1, Joonseok Lee2,3, Edward Ch
 7 Sep 26, 2022
7 Sep 26, 2022
The Malware Open-source Threat Intelligence Family dataset contains 3,095 disarmed PE malware samples from 454 families
MOTIF Dataset The Malware Open-source Threat Intelligence Family (MOTIF) dataset contains 3,095 disarmed PE malware samples from 454 families, labeled
 112 Dec 13, 2022
112 Dec 13, 2022

Artstation-Artistic-face-HQ Dataset (AAHQ)
Artstation-Artistic-face-HQ Dataset (AAHQ) Artstation-Artistic-face-HQ (AAHQ) is a high-quality image dataset of artistic-face images. It is proposed
 105 Dec 16, 2022
105 Dec 16, 2022
Core ML tools contain supporting tools for Core ML model conversion, editing, and validation.
Core ML Tools Use coremltools to convert machine learning models from third-party libraries to the Core ML format. The Python package contains the sup
 3k Jan 8, 2023
3k Jan 8, 2023
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
Research code for "What to Pre-Train on? Efficient Intermediate Task Selection", EMNLP 2021
efficient-task-transfer This repository contains code for the experiments in our paper "What to Pre-Train on? Efficient Intermediate Task Selection".
 26 Dec 24, 2022
26 Dec 24, 2022

Training and evaluation codes for the BertGen paper (ACL-IJCNLP 2021)
BERTGEN This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codeb
 9 Oct 26, 2022
9 Oct 26, 2022
EMNLP 2021 paper "Pre-train or Annotate? Domain Adaptation with a Constrained Budget".
Pre-train or Annotate? Domain Adaptation with a Constrained Budget This repo contains code and data associated with EMNLP 2021 paper "Pre-train or Ann
 8 Dec 17, 2021
8 Dec 17, 2021

DANeS is an open-source E-newspaper dataset by collaboration between DATASET JSC (dataset.vn) and AIV Group (aivgroup.vn)
DANeS - Open-source E-newspaper dataset Source: Technology vector created by macrovector - www.freepik.com. DANeS is an open-source E-newspaper datase
 64 Aug 17, 2022
64 Aug 17, 2022
Media Replay Engine (MRE) is a framework to build automated video clipping and replay (highlight) generation pipelines for live and video-on-demand content.
Media Replay Engine (MRE) is a framework for building automated video clipping and replay (highlight) generation pipelines using AWS services for live
 30 Nov 29, 2022
30 Nov 29, 2022

Cooperative Driving Dataset: a dataset for multi-agent driving scenarios
Cooperative Driving Dataset (CODD) The Cooperative Driving dataset is a synthetic dataset generated using CARLA that contains lidar data from multiple
 124 Dec 28, 2022
124 Dec 28, 2022

Label Studio is a multi-type data labeling and annotation tool with standardized output format
Website • Docs • Twitter • Join Slack Community What is Label Studio? Label Studio is an open source data labeling tool. It lets you label data types
 11.7k Jan 9, 2023
11.7k Jan 9, 2023
Label-Free Model Evaluation with Semi-Structured Dataset Representations
Label-Free Model Evaluation with Semi-Structured Dataset Representations Prerequisites This code uses the following libraries Python 3.7 NumPy PyTorch
8 Oct 6, 2022
Semi-automated vocabulary generation from semantic vector models
vec2word Semi-automated vocabulary generation from semantic vector models This script generates a list of potential conlang word forms along with asso
 9 Nov 25, 2022
9 Nov 25, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
The official homepage of the COCO-Stuff dataset.
The COCO-Stuff dataset Holger Caesar, Jasper Uijlings, Vittorio Ferrari Welcome to official homepage of the COCO-Stuff [1] dataset. COCO-Stuff augment
 715 Dec 31, 2022
715 Dec 31, 2022

Train the HRNet model on ImageNet
High-resolution networks (HRNets) for Image classification News [2021/01/20] Add some stronger ImageNet pretrained models, e.g., the HRNet_W48_C_ssld_
 866 Jan 4, 2023
866 Jan 4, 2023
Python script to download the celebA-HQ dataset from google drive
download-celebA-HQ Python script to download and create the celebA-HQ dataset. WARNING from the author. I believe this script is broken since a few mo
 133 Dec 21, 2022
133 Dec 21, 2022
[3DV 2021] A Dataset-Dispersion Perspective on Reconstruction Versus Recognition in Single-View 3D Reconstruction Networks
dispersion-score Official implementation of 3DV 2021 Paper A Dataset-dispersion Perspective on Reconstruction versus Recognition in Single-view 3D Rec
 7 May 28, 2022
7 May 28, 2022

Dataset for the Research2Clinics @ NeurIPS 2021 Paper: What Do You See in this Patient? Behavioral Testing of Clinical NLP Models
Behavioral Testing of Clinical NLP Models This repository contains code for testing the behavior of clinical prediction models based on patient letter
 2 Sep 20, 2022
2 Sep 20, 2022
Dataset and codebase for NeurIPS 2021 paper: Exploring Forensic Dental Identification with Deep Learning
Repository under construction. Example dataset, checkpoints, and training/testing scripts will be avaible soon! 💡 Collated best practices from most p
 4 Jun 26, 2022
4 Jun 26, 2022
Official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive
TTT++ This is an official implementation for TTT++: When Does Self-supervised Test-time Training Fail or Thrive? TL;DR: Online Feature Alignment + Str
 39 Dec 25, 2022
39 Dec 25, 2022
Locally Most Powerful Bayesian Test for Out-of-Distribution Detection using Deep Generative Models
LMPBT Supplementary code for the Paper entitled ``Locally Most Powerful Bayesian Test for Out-of-Distribution Detection using Deep Generative Models"
 1 Sep 29, 2022
1 Sep 29, 2022
Official implementation of the NeurIPS'21 paper 'Conditional Generation Using Polynomial Expansions'.
Conditional Generation Using Polynomial Expansions Official implementation of the conditional image generation experiments as described on the NeurIPS
 4 Aug 7, 2022
4 Aug 7, 2022
This repository is an implementation of our NeurIPS 2021 paper (Stylized Dialogue Generation with Multi-Pass Dual Learning) in PyTorch.
MPDL---TODO This repository is an implementation of our NeurIPS 2021 paper (Stylized Dialogue Generation with Multi-Pass Dual Learning) in PyTorch. Ci
 3 Nov 27, 2022
3 Nov 27, 2022
Info and sample codes for "NTU RGB+D Action Recognition Dataset"
"NTU RGB+D" Action Recognition Dataset "NTU RGB+D 120" Action Recognition Dataset "NTU RGB+D" is a large-scale dataset for human action recognition. I
 578 Dec 30, 2022
578 Dec 30, 2022

DALLE-tools provided useful dataset utilities to improve you workflow with WebDatasets.
DALLE tools DALLE-tools is a github repository with useful tools to categorize, annotate or check the sanity of your datasets. Installation Just clone
 11 Dec 25, 2022
11 Dec 25, 2022
CCPD: a diverse and well-annotated dataset for license plate detection and recognition
CCPD (Chinese City Parking Dataset, ECCV) UPdate on 10/03/2019. CCPD Dataset is now updated. We are confident that images in subsets of CCPD is much m
 1.8k Dec 30, 2022
1.8k Dec 30, 2022
Cluttered MNIST Dataset
Cluttered MNIST Dataset A setup script will download MNIST and produce mnist/*.t7 files: luajit download_mnist.lua Example usage: local mnist_clutter
 50 Jul 12, 2022
50 Jul 12, 2022
A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset
xwrf A lightweight interface for reading in output from the Weather Research and Forecasting (WRF) model into xarray Dataset. The primary objective of
 43 Nov 29, 2022
43 Nov 29, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Long Expressive Memory (LEM)
Long Expressive Memory for Sequence Modeling This repository contains the implementation to reproduce the numerical experiments of the paper Long Expr
 47 Dec 17, 2022
47 Dec 17, 2022

Project to deploy a machine learning model based on Titanic dataset from Kaggle
kaggle_titanic_deploy Project to deploy a machine learning model based on Titanic dataset from Kaggle In this project we used the Titanic dataset from
 8 May 23, 2022
8 May 23, 2022
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset
MassiveSumm: a very large-scale, very multilingual, news summarisation dataset This repository contains links to data and code to fetch and reproduce
 19 Dec 16, 2022
19 Dec 16, 2022

Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
 6 Dec 1, 2021
6 Dec 1, 2021
This is the face keypoint train code of project face-detection-project
face-key-point-pytorch 1. Data structure The structure of landmarks_jpg is like below: |--landmarks_jpg |----AFW |------AFW_134212_1_0.jpg |------AFW_
 3 Nov 27, 2022
3 Nov 27, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Modern Denial-of-service ToolKit for python
💣 Impulse Modern Denial-of-service ToolKit 💻 Main window 📡 Methods: Method Target Description SMS PHONE Sends a massive amount of SMS messages and
 1 Nov 29, 2021
1 Nov 29, 2021
COIN the currently largest dataset for comprehensive instruction video analysis.
COIN Dataset COIN is the currently largest dataset for comprehensive instruction video analysis. It contains 11,827 videos of 180 different tasks (i.e
 86 Dec 28, 2022
86 Dec 28, 2022
Dataset and Source code of paper 'Enhancing Keyphrase Extraction from Academic Articles with their Reference Information'.
Enhancing Keyphrase Extraction from Academic Articles with their Reference Information Overview Dataset and code for paper "Enhancing Keyphrase Extrac
 15 Nov 24, 2022
15 Nov 24, 2022

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
Pytorch Implementation of Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic [Paper] [Colab is coming soon] Approach Example Usage To r
170 Jan 3, 2023
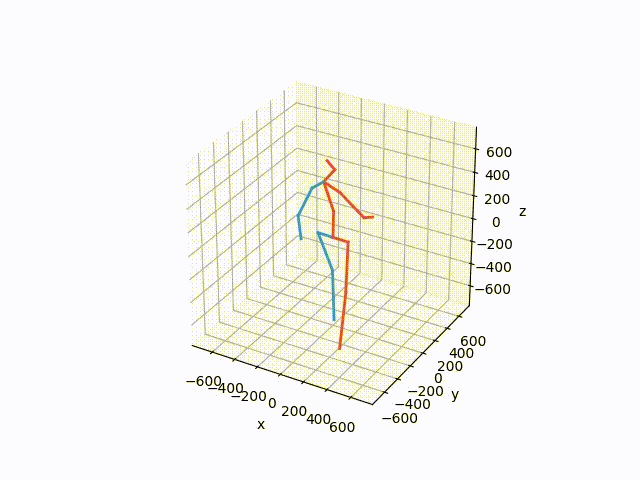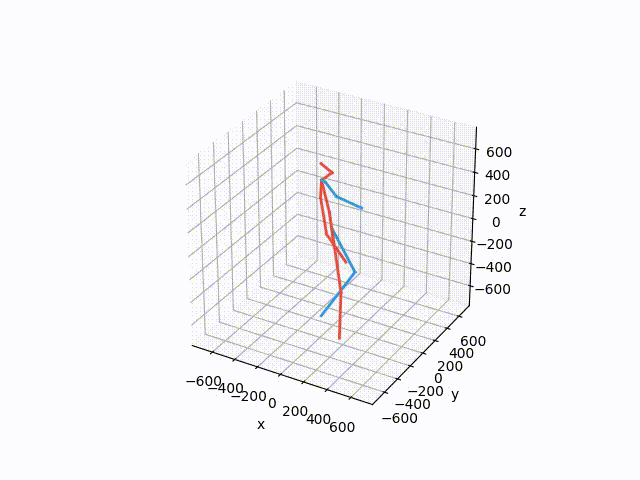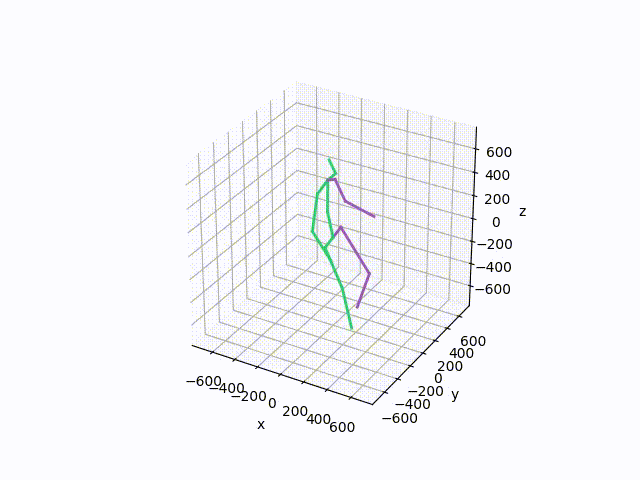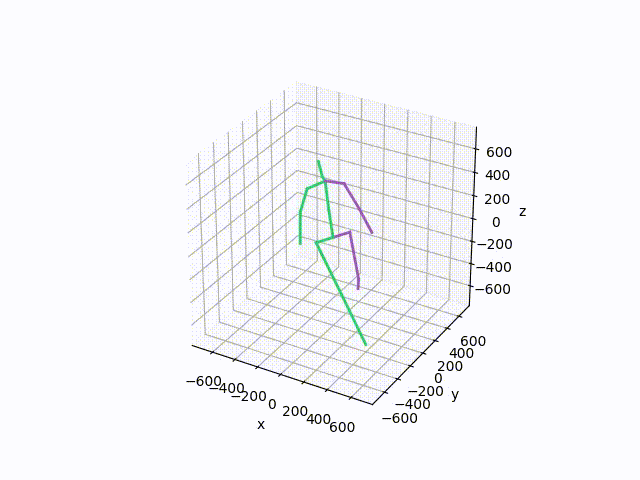
Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset.
Visualization-of-Human3.6M-Dataset Plot and save the ground truth and predicted results of human 3.6 M and CMU mocap dataset. human-motion-prediction
 5 Nov 18, 2022
5 Nov 18, 2022
A benchmark dataset for mesh multi-label-classification based on cube engravings introduced in MeshCNN
Double Cube Engravings This script creates a dataset for multi-label mesh clasification, with an intentionally difficult setup for point cloud classif
 1 Nov 30, 2021
1 Nov 30, 2021
A fast, dataset-agnostic, deep visual search engine for digital art history
imgs.ai imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings. It utilizes modern
 5 Dec 14, 2022
5 Dec 14, 2022
Predicting diabetes over a five year period using logistic regression and the Pima First-Nation dataset
Diabetes This script uses the Pima First Nations dataset to create a model to predict whether or not an individual will develop Diabetes Mellitus Type
 1 Mar 28, 2022
1 Mar 28, 2022
ESP32 recording button presses, and serving webpage that graphs the numbers over time.
ESP32-IoT-button-graph-test ESP32 recording button presses, and serving webpage via webSockets in order to graph the responses. The objective was to t
 1 Nov 30, 2021
1 Nov 30, 2021
Train an imgs.ai model on your own dataset
imgs.ai is a fast, dataset-agnostic, deep visual search engine for digital art history based on neural network embeddings.
5 Dec 21, 2021

Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Models
Molecular Sets (MOSES): A benchmarking platform for molecular generation models Deep generative models are rapidly becoming popular for the discovery
 656 Dec 29, 2022
656 Dec 29, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Model This repository is the official PyTorch implementation of GraphRNN, a graph gene
 568 Dec 29, 2022
568 Dec 29, 2022

This repository contains the source code of our work on designing efficient CNNs for computer vision
Efficient networks for Computer Vision This repo contains source code of our work on designing efficient networks for different computer vision tasks:
 386 Nov 26, 2022
386 Nov 26, 2022
PyTorch common framework to accelerate network implementation, training and validation
pytorch-framework PyTorch common framework to accelerate network implementation, training and validation. This framework is inspired by works from MML
 3 Dec 19, 2022
3 Dec 19, 2022
WSDM‘2022: Knowledge Enhanced Sports Game Summarization
Knowledge Enhanced Sports Game Summarization Cooming Soon! :) Data will be released after approval process. Code will be published once the author of
 14 Jul 13, 2022
14 Jul 13, 2022
Accompanying code for the paper "A Kernel Test for Causal Association via Noise Contrastive Backdoor Adjustment".
#backdoor-HSIC (bd_HSIC) Accompanying code for the paper "A Kernel Test for Causal Association via Noise Contrastive Backdoor Adjustment". To generate
 0 Nov 25, 2021
0 Nov 25, 2021

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
Simple command line tool to train and deploy your machine learning models with AWS SageMaker
metamaker Simple command line tool to train and deploy your machine learning models with AWS SageMaker Features metamaker enables you to: Build a dock
 5 Jan 9, 2022
5 Jan 9, 2022
This repository provides an unified frameworks to train and test the state-of-the-art few-shot font generation (FFG) models.
FFG-benchmarks This repository provides an unified frameworks to train and test the state-of-the-art few-shot font generation (FFG) models. What is Fe
 101 Dec 27, 2022
101 Dec 27, 2022
A working roblox account generator it doesnt bypass the capcha stuff cuz these didnt showed up in my test runs
A working roblox account generator (state 11.5.2021) it doesnt bypass the capcha stuff cuz these didnt showed up in my test runs
 22 Jan 3, 2023
22 Jan 3, 2023
Generate random test credit card numbers for testing, validation and/or verification purposes.
Generate random test credit card numbers for testing, validation and/or verification purposes.
 5 Nov 14, 2022
5 Nov 14, 2022

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Online Pseudo Label Generation by Hierarchical Cluster Dynamics for Adaptive Person Re-identification
Online Pseudo Label Generation by Hierarchical Cluster Dynamics for Adaptive Person Re-identification
 6 Nov 25, 2022
6 Nov 25, 2022
LSUN Dataset Documentation and Demo Code
LSUN Please check LSUN webpage for more information about the dataset. Data Release All the images in one category are stored in one lmdb database fil
 426 Jan 2, 2023
426 Jan 2, 2023
A new test set for ImageNet
ImageNetV2 The ImageNetV2 dataset contains new test data for the ImageNet benchmark. This repository provides associated code for assembling and worki
 186 Dec 18, 2022
186 Dec 18, 2022

spade is the next-generation networking command line tool.
spade is the next-generation networking command line tool. Say goodbye to the likes of dig, ping and traceroute with more accessible, more informative and prettier output.
 5 Jan 28, 2022
5 Jan 28, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
 10.1k Dec 30, 2022
10.1k Dec 30, 2022

PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019.
PointRCNN PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud Code release for the paper PointRCNN:3D Object Proposal Generation a
 1.5k Dec 27, 2022
1.5k Dec 27, 2022

Official pytorch implementation of the paper: "SinGAN: Learning a Generative Model from a Single Natural Image"
SinGAN Project | Arxiv | CVF | Supplementary materials | Talk (ICCV`19) Official pytorch implementation of the paper: "SinGAN: Learning a Generative M
 3.2k Dec 25, 2022
3.2k Dec 25, 2022

We are building an open database of COVID-19 cases with chest X-ray or CT images.
🛑 Note: please do not claim diagnostic performance of a model without a clinical study! This is not a kaggle competition dataset. Please read this pa
 2.9k Dec 30, 2022
2.9k Dec 30, 2022
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022
Package to compute Mauve, a similarity score between neural text and human text. Install with `pip install mauve-text`.
MAUVE MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE
 182 Jan 2, 2023
182 Jan 2, 2023
HuggingTweets - Train a model to generate tweets
HuggingTweets - Train a model to generate tweets Create in 5 minutes a tweet generator based on your favorite Tweeter Make my own model with the demo
 318 Jan 4, 2023
318 Jan 4, 2023

Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
Faster R-CNN pretrained on VisualGenome This repository modifies maskrcnn-benchmark for object detection and attribute prediction on VisualGenome data
 7 Apr 20, 2021
7 Apr 20, 2021

 36 Dec 28, 2022
36 Dec 28, 2022

The code for the NeurIPS 2021 paper "A Unified View of cGANs with and without Classifiers".
Energy-based Conditional Generative Adversarial Network (ECGAN) This is the code for the NeurIPS 2021 paper "A Unified View of cGANs with and without
 11 Nov 25, 2021
11 Nov 25, 2021
Official pytorch code for SSC-GAN: Semi-Supervised Single-Stage Controllable GANs for Conditional Fine-Grained Image Generation(ICCV 2021)
SSC-GAN_repo Pytorch implementation for 'Semi-Supervised Single-Stage Controllable GANs for Conditional Fine-Grained Image Generation'.PDF SSC-GAN:Sem
 4 Aug 28, 2022
4 Aug 28, 2022
Python code for loading the Aschaffenburg Pose Dataset.
Aschaffenburg Pose Dataset (APD) This repository contains Python code for loading and filtering the Aschaffenburg Pose Dataset. The dataset itself and
 1 Nov 26, 2021
1 Nov 26, 2021

Unofficial PyTorch implementation of "RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving" (ECCV 2020)
RTM3D-PyTorch The PyTorch Implementation of the paper: RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving (ECCV 2020
 271 Nov 29, 2022
271 Nov 29, 2022

Benchmarks for the Optimal Power Flow Problem
Power Grid Lib - Optimal Power Flow This benchmark library is curated and maintained by the IEEE PES Task Force on Benchmarks for Validation of Emergi
 207 Dec 8, 2022
207 Dec 8, 2022
The devkit of the nuScenes dataset.
nuScenes devkit Welcome to the devkit of the nuScenes and nuImages datasets. Overview Changelog Devkit setup nuImages nuImages setup Getting started w
 1.6k Jan 5, 2023
1.6k Jan 5, 2023

Train SN-GAN with AdaBelief
SNGAN-AdaBelief Train a state-of-the-art spectral normalization GAN with AdaBelief https://github.com/juntang-zhuang/Adabelief-Optimizer Acknowledgeme
 10 Jun 11, 2022
10 Jun 11, 2022

A large-scale face dataset for face parsing, recognition, generation and editing.
CelebAMask-HQ [Paper] [Demo] CelebAMask-HQ is a large-scale face image dataset that has 30,000 high-resolution face images selected from the CelebA da
 1.7k Dec 26, 2022
1.7k Dec 26, 2022
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
 880 Jan 7, 2023
880 Jan 7, 2023
Test for using pyIIIFpres for rara magnetica project
raramagnetica_pyIIIFpres Test for using pyIIIFpres for rara magnetica project. This test show how to use pyIIIFpres for creating mannifest compliant t
 1 Dec 3, 2021
1 Dec 3, 2021
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022
This repository contains several image-to-image translation models, whcih were tested for RGB to NIR image generation. The models are Pix2Pix, Pix2PixHD, CycleGAN and PointWise.
RGB2NIR_Experimental This repository contains several image-to-image translation models, whcih were tested for RGB to NIR image generation. The models
 5 Jan 4, 2023
5 Jan 4, 2023

TeST: Temporal-Stable Thresholding for Semi-supervised Learning
TeST: Temporal-Stable Thresholding for Semi-supervised Learning TeST Illustration Semi-supervised learning (SSL) offers an effective method for large-
 1 Jul 14, 2022
1 Jul 14, 2022
Pydantic based mock data generation
This library offers powerful mock data generation capabilities for pydantic based models. It can also be used with other libraries that use pydantic as a foundation, for example SQLModel, Beanie and ormar.
 396 Dec 28, 2022
396 Dec 28, 2022
Nodule Generation Algorithm Baseline and template code for node21 generation track
Nodule Generation Algorithm This codebase implements a simple baseline model, by following the main steps in the paper published by Litjens et al. for
 10 Apr 21, 2022
10 Apr 21, 2022
An open source algorithm and dataset for finding poop in pictures.
The shitspotter module is where I will be work on the "shitspotter" poop-detection algorithm and dataset. The primary goal of this work is to allow for the creation of a phone app that finds where your dog pooped, because you ran to grab the doggy-bags you forgot, and now you can't find the damn thing.
 29 Nov 29, 2022
29 Nov 29, 2022

Automated question generation and question answering from Turkish texts using text-to-text transformers
Turkish Question Generation Offical source code for "Automated question generation & question answering from Turkish texts using text-to-text transfor
 29 Dec 14, 2022
29 Dec 14, 2022

Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes
Unleashing Transformers: Parallel Token Prediction with Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized C
 139 Jan 4, 2023
139 Jan 4, 2023

Code Generation using a large neural network called GPT-J
CodeGenX is a Code Generation system powered by Artificial Intelligence! It is delivered to you in the form of a Visual Studio Code Extension and is Free and Open-source!
 389 Dec 31, 2022
389 Dec 31, 2022
A colab notebook for training Stylegan2-ada on colab, transfer learning onto your own dataset.
Stylegan2-Ada-Google-Colab-Starter-Notebook A no thrills colab notebook for training Stylegan2-ada on colab. transfer learning onto your own dataset h
 66 Dec 16, 2022
66 Dec 16, 2022
Auto locust load test config and worker distribution with Docker and GitHub Action
Auto locust load test config and worker distribution with Docker and GitHub Action Install Fork the repo and change the visibility option to private S
 1 Nov 24, 2021
1 Nov 24, 2021
A library that integrates huggingface transformers with the world of fastai, giving fastai devs everything they need to train, evaluate, and deploy transformer specific models.
blurr A library that integrates huggingface transformers with version 2 of the fastai framework Install You can now pip install blurr via pip install
 253 Dec 31, 2022
253 Dec 31, 2022