1027 Repositories
Python audio-recognition Libraries
Repo for EchoVPR: Echo State Networks for Visual Place Recognition
EchoVPR Repo for EchoVPR: Echo State Networks for Visual Place Recognition Currently under development Dirs: data: pre-collected hidden representation
 4 Oct 4, 2022
4 Oct 4, 2022
👐OpenHands : Making Sign Language Recognition Accessible (WiP 🚧👷♂️🏗)
👐 OpenHands: Sign Language Recognition Library Making Sign Language Recognition Accessible Check the documentation on how to use the library: ReadThe
 69 Dec 12, 2022
69 Dec 12, 2022
Repository sharing code and the model for the paper "Rescoring Sequence-to-Sequence Models for Text Line Recognition with CTC-Prefixes"
Rescoring Sequence-to-Sequence Models for Text Line Recognition with CTC-Prefixes Setup virtualenv -p python3 venv source venv/bin/activate pip instal
 9 May 20, 2022
9 May 20, 2022

University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN
Music-Sentiment-Transfer University of Rochester 2021 Summer REU focusing on music sentiment transfer using CycleGAN Poster: Music Sentiment Transfer
 2 Jan 24, 2022
2 Jan 24, 2022
![[ICCV 2021 Oral] Deep Evidential Action Recognition](https://github.com/Cogito2012/DEAR/raw/master/assets/gif/known/Basketball_v_Basketball_g05_c03.gif)
[ICCV 2021 Oral] Deep Evidential Action Recognition
DEAR (Deep Evidential Action Recognition) Project | Paper & Supp Wentao Bao, Qi Yu, Yu Kong International Conference on Computer Vision (ICCV Oral), 2
 80 Jan 3, 2023
80 Jan 3, 2023
A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering.
DeepFilterNet A Low Complexity Speech Enhancement Framework for Full-Band Audio (48kHz) based on Deep Filtering. libDF contains Rust code used for dat
 292 Dec 25, 2022
292 Dec 25, 2022

Open-Set Recognition: A Good Closed-Set Classifier is All You Need
Open-Set Recognition: A Good Closed-Set Classifier is All You Need Code for our paper: "Open-Set Recognition: A Good Closed-Set Classifier is All You
 194 Jan 3, 2023
194 Jan 3, 2023
基于openpose和图像分类的手语识别项目
手语识别 0、使用到的模型 (1). openpose,作者:CMU-Perceptual-Computing-Lab https://github.com/CMU-Perceptual-Computing-Lab/openpose (2). 图像分类classification,作者:Bubbl
 20 Dec 15, 2022
20 Dec 15, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022
Official PyTorch implementation of "AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks"
AASIST This repository provides the overall framework for training and evaluating audio anti-spoofing systems proposed in 'AASIST: Audio Anti-Spoofing
 56 Jan 2, 2023
56 Jan 2, 2023
FAST-RIR: FAST NEURAL DIFFUSE ROOM IMPULSE RESPONSE GENERATOR
This is the official implementation of our neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment.
 89 Dec 22, 2022
89 Dec 22, 2022
 2k Jan 6, 2023
2k Jan 6, 2023
An audio-solving python funcaptcha solving module
funcapsolver funcapsolver is a funcaptcha audio-solving module, which allows captchas to be interacted with and solved with the use of google's speech
 8 Nov 21, 2022
8 Nov 21, 2022
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
 20 Nov 15, 2022
20 Nov 15, 2022

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
Time-stretch audio clips quickly with PyTorch (CUDA supported)! Additional utilities for searching efficient transformations are included.
 22 Jul 7, 2022
22 Jul 7, 2022

Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable Sensors
-IEEE-TIM-2021-1-Shallow-CNN-for-HAR [IEEE TIM 2021-1] Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable Sensors All
 1 May 17, 2022
1 May 17, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition [ArXiv] [Project Page] This repository is the official implementation of AdaMML:
 43 Dec 26, 2022
43 Dec 26, 2022

Neural network for recognizing the gender of people in photos
Neural Network For Gender Recognition How to test it? Install requirements.txt file using pip install -r requirements.txt command Run nn.py using pyth
 1 Sep 18, 2022
1 Sep 18, 2022

A PyTorch implementation of SlowFast based on ICCV 2019 paper "SlowFast Networks for Video Recognition"
SlowFast A PyTorch implementation of SlowFast based on ICCV 2019 paper SlowFast Networks for Video Recognition. Requirements Anaconda PyTorch conda in
 8 Dec 23, 2022
8 Dec 23, 2022
A web app to scan crypto markets based on candlestick pattern recognition from
Crypto_Scanner A web app to scan crypto markets based on candlestick pattern recognition from "Japanese Candlestick Charting Techniques: A Contemporar
 27 Jan 1, 2023
27 Jan 1, 2023
Deep Face Recognition in PyTorch
Face Recognition in PyTorch By Alexey Gruzdev and Vladislav Sovrasov Introduction A repository for different experimental Face Recognition models such
 141 Sep 11, 2022
141 Sep 11, 2022

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 2, 2023
3.1k Jan 2, 2023

Pytorch implementation for "Large-Scale Long-Tailed Recognition in an Open World" (CVPR 2019 ORAL)
Large-Scale Long-Tailed Recognition in an Open World [Project] [Paper] [Blog] Overview Open Long-Tailed Recognition (OLTR) is the author's re-implemen
 761 Dec 26, 2022
761 Dec 26, 2022
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022
A GUI for Face Recognition, based upon Docker, Tkinter, GPU and a camera device.
Face Recognition GUI This repository is a GUI version of Face Recognition by Adam Geitgey, where e.g. Docker and Tkinter are utilized. All the materia
 6 Dec 5, 2022
6 Dec 5, 2022

This is the official implement of paper "ActionCLIP: A New Paradigm for Action Recognition"
This is an official pytorch implementation of ActionCLIP: A New Paradigm for Video Action Recognition [arXiv] Overview Content Prerequisites Data Prep
 32 Sep 25, 2021
32 Sep 25, 2021

GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
 29 Dec 26, 2022
29 Dec 26, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
This is the official implement of paper "ActionCLIP: A New Paradigm for Action Recognition"
This is an official pytorch implementation of ActionCLIP: A New Paradigm for Video Action Recognition [arXiv] Overview Content Prerequisites Data Prep
268 Jan 9, 2023

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
SVHNClassifier-PyTorch A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks If
 182 Jan 3, 2023
182 Jan 3, 2023
Speech Recognition using DeepSpeech2.
deepspeech.pytorch Implementation of DeepSpeech2 for PyTorch using PyTorch Lightning. The repo supports training/testing and inference using the DeepS
 2k Jan 4, 2023
2k Jan 4, 2023

A PyTorch Implementation of Single Shot MultiBox Detector
SSD: Single Shot MultiBox Object Detector, in PyTorch A PyTorch implementation of Single Shot MultiBox Detector from the 2016 paper by Wei Liu, Dragom
 4.8k Jan 7, 2023
4.8k Jan 7, 2023
A facial recognition doorbell system using a Raspberry Pi
Facial Recognition Doorbell This project expands on the person-detecting doorbell system to allow it to identify faces, and announce names accordingly
 22 Apr 15, 2022
22 Apr 15, 2022
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021

Django-Audiofield is a simple app that allows Audio files upload, management and conversion to different audio format (mp3, wav & ogg), which also makes it easy to play audio files into your Django application.
Django-Audiofield Description: Django Audio Management Tools Maintainer: Areski Contributors: list of contributors Django-Audiofield is a simple app t
 167 Nov 10, 2022
167 Nov 10, 2022

A collection of SOTA Image Classification Models in PyTorch
A collection of SOTA Image Classification Models in PyTorch
 85 Dec 30, 2022
85 Dec 30, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Music source separation is a task to separate audio recordings into individual sources
Music Source Separation Music source separation is a task to separate audio recordings into individual sources. This repository is an PyTorch implmeme
 958 Jan 3, 2023
958 Jan 3, 2023
![[ICCV2021] Official code for](https://github.com/Uason-Chen/CTR-GCN/raw/main/src/framework.jpg)
[ICCV2021] Official code for "Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition"
CTR-GCN This repo is the official implementation for Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. The pap
 148 Dec 16, 2022
148 Dec 16, 2022

Tool to add main subject to items on Wikidata using a WMFs CirrusSearch for named entity recognition or a manually supplied list of QIDs
ItemSubjector Tool made to add main subject statements to items based on the title using a home-brewed CirrusSearch-based Named Entity Recognition alg
 9 Nov 17, 2022
9 Nov 17, 2022
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
 1k Jan 3, 2023
1k Jan 3, 2023

“Data Augmentation for Cross-Domain Named Entity Recognition” (EMNLP 2021)
Data Augmentation for Cross-Domain Named Entity Recognition Authors: Shuguang Chen, Gustavo Aguilar, Leonardo Neves and Thamar Solorio This repository
 18 Sep 10, 2022
18 Sep 10, 2022
Gateware for the Terasic/Arrow DECA board, to become a USB2 high speed audio interface
DECA USB Audio Interface DECA based USB 2.0 High Speed audio interface Status / current limitations enumerates as class compliant audio device on Linu
 16 Mar 21, 2022
16 Mar 21, 2022

Desktop music recognition application for windows
MusicRecognizer Music recognition application for windows You can choose from which of the devices the recording will be made. If you choose speakers,
 28 Dec 13, 2022
28 Dec 13, 2022
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022

Official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
This repository is the official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
 101 Dec 30, 2022
101 Dec 30, 2022

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022

Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network.
face-mask-detection Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network. It contains 3 scr
 13 Jan 18, 2022
13 Jan 18, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022
A tool to fuck a video/audio quality using FFmpeg
Media quality fucker A tool to fuck a video/audio quality using FFmpeg How to use Download the source Download Python Extract FFmpeg Put what you want
 8 Jan 25, 2022
8 Jan 25, 2022
Reading list for research topics in sound event detection
Sound event detection aims at processing the continuous acoustic signal and converting it into symbolic descriptions of the corresponding sound events present at the auditory scene.
 64 Jan 5, 2023
64 Jan 5, 2023

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
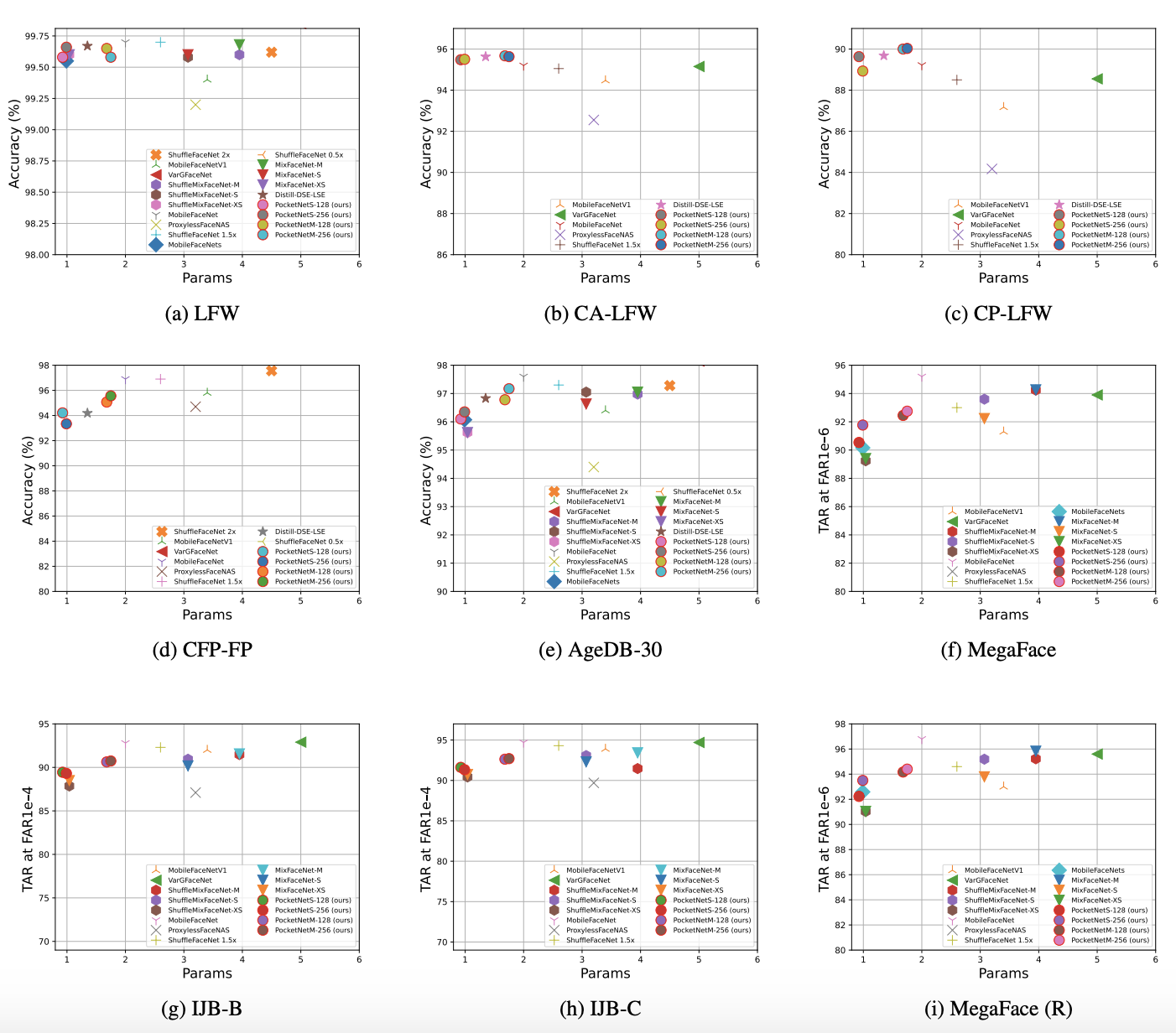
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
PocketNet This is the official repository of the paper: PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and M
 40 Dec 22, 2022
40 Dec 22, 2022

pedalboard is a Python library for adding effects to audio.
pedalboard is a Python library for adding effects to audio. It supports a number of common audio effects out of the box, and also allows the use of VST3® and Audio Unit plugin formats for third-party effects.
 3.9k Jan 2, 2023
3.9k Jan 2, 2023

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022

Official code of ICCV2021 paper "Residual Attention: A Simple but Effective Method for Multi-Label Recognition"
CSRA This is the official code of ICCV 2021 paper: Residual Attention: A Simple But Effective Method for Multi-Label Recoginition Demo, Train and Vali
 163 Dec 22, 2022
163 Dec 22, 2022
praudio provides audio preprocessing framework for Deep Learning audio applications
praudio provides objects and a script for performing complex preprocessing operations on entire audio datasets with one command.
 105 Dec 26, 2022
105 Dec 26, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

AdaFocus (ICCV 2021) Adaptive Focus for Efficient Video Recognition
AdaFocus (ICCV 2021) This repo contains the official code and pre-trained models for AdaFocus. Adaptive Focus for Efficient Video Recognition Referenc
 115 Dec 21, 2022
115 Dec 21, 2022
The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution.
WSRGlow The official implementation of the Interspeech 2021 paper WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution. Audio sa
 96 Jan 3, 2023
96 Jan 3, 2023
Source Code For Template-Based Named Entity Recognition Using BART
Template-Based NER Source Code For Template-Based Named Entity Recognition Using BART Training Training train.py Inference inference.py Corpus ATIS (h
 174 Dec 19, 2022
174 Dec 19, 2022
PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
samplernn-pytorch A PyTorch implementation of SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. It's based on the reference implem
 261 Dec 14, 2022
261 Dec 14, 2022
Temporal Segment Networks (TSN) in PyTorch
TSN-Pytorch We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation for TSN as well as oth
 1k Jan 3, 2023
1k Jan 3, 2023

This is the offical website for paper ''Category-consistent deep network learning for accurate vehicle logo recognition''
The Pytorch Implementation of Category-consistent deep network learning for accurate vehicle logo recognition This is the offical website for paper ''
 28 Oct 29, 2022
28 Oct 29, 2022

Simple torch.nn.module implementation of Alias-Free-GAN style filter and resample
Alias-Free-Torch Simple torch module implementation of Alias-Free GAN. This repository including Alias-Free GAN style lowpass sinc filter @filter.py A
 64 Dec 22, 2022
64 Dec 22, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023

Jittor Medical Segmentation Lib -- The assignment of Pattern Recognition course (2021 Spring) in Tsinghua University
THU模式识别2021春 -- Jittor 医学图像分割 模型列表 本仓库收录了课程作业中同学们采用jittor框架实现的如下模型: UNet SegNet DeepLab V2 DANet EANet HarDNet及其改动HarDNet_alter PSPNet OCNet OCRNet DL
 48 Dec 26, 2022
48 Dec 26, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
We present a framework for training multi-modal deep learning models on unlabelled video data by forcing the network to learn invariances to transformations applied to both the audio and video streams.
Multi-Modal Self-Supervision using GDT and StiCa This is an official pytorch implementation of papers: Multi-modal Self-Supervision from Generalized D
 42 Dec 9, 2022
42 Dec 9, 2022
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
structshot Code and data for paper "Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning", Yi Yang and Arz
47 Dec 27, 2022
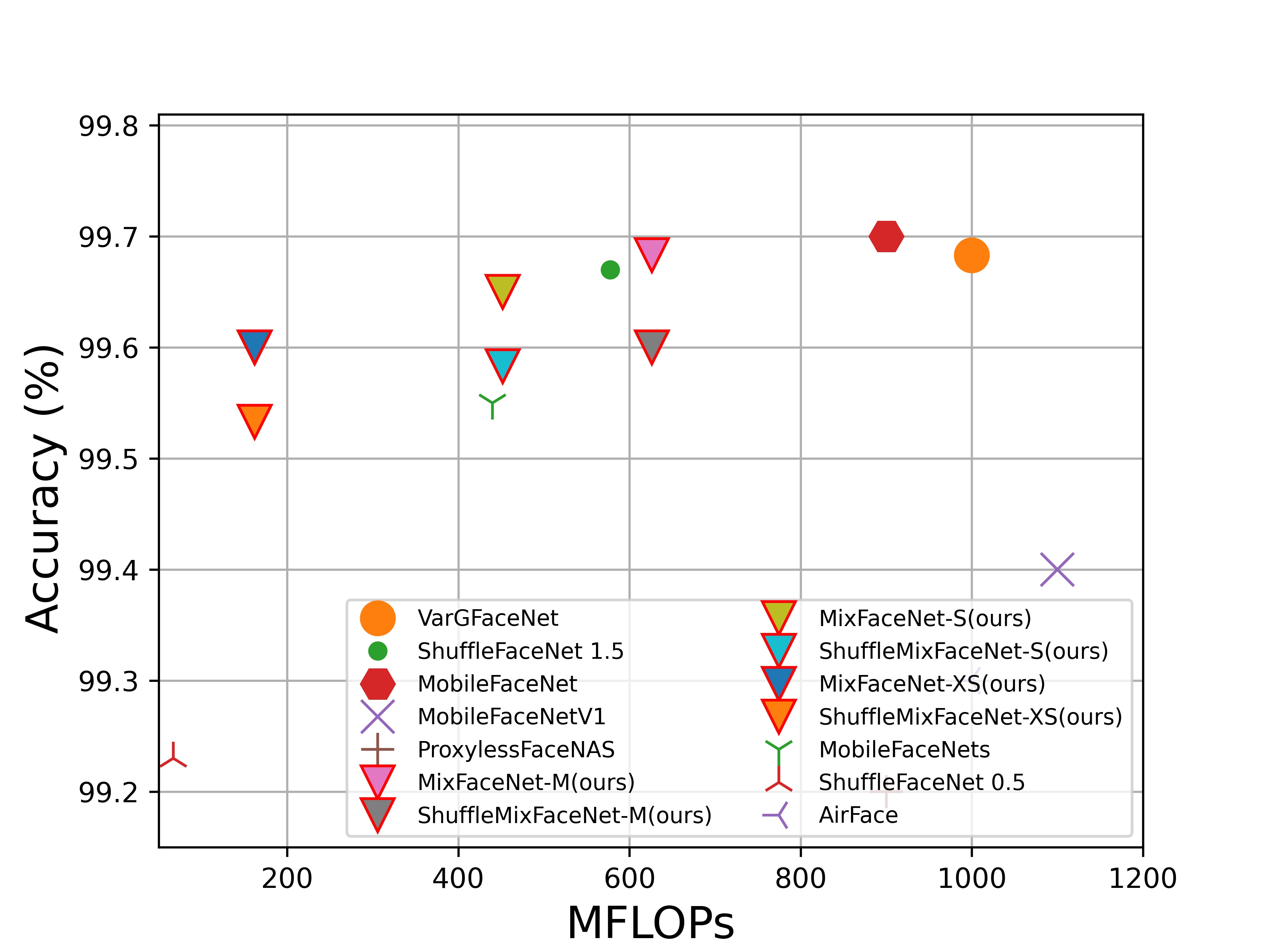
Official repository for MixFaceNets: Extremely Efficient Face Recognition Networks
MixFaceNets This is the official repository of the paper: MixFaceNets: Extremely Efficient Face Recognition Networks. (Accepted in IJCB2021) https://i
51 Dec 13, 2022
3D ResNets for Action Recognition (CVPR 2018)
3D ResNets for Action Recognition Update (2020/4/13) We published a paper on arXiv. Hirokatsu Kataoka, Tenga Wakamiya, Kensho Hara, and Yutaka Satoh,
 3.5k Jan 6, 2023
3.5k Jan 6, 2023

Easy to use Audio Tagging in PyTorch
Audio Classification, Tagging & Sound Event Detection in PyTorch Progress: Fine-tune on audio classification Fine-tune on audio tagging Fine-tune on s
15 Dec 22, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Parametric Contrastive Learning (ICCV2021)
Parametric-Contrastive-Learning This repository contains the implementation code for ICCV2021 paper: Parametric Contrastive Learning (https://arxiv.or
 156 Dec 21, 2022
156 Dec 21, 2022
ExKaldi-RT: An Online Speech Recognition Extension Toolkit of Kaldi
ExKaldi-RT is an online ASR toolkit for Python language. It reads realtime streaming audio and do online feature extraction, probability computation, and online decoding.
 31 Aug 16, 2021
31 Aug 16, 2021
FPGA based USB 2.0 high speed audio interface featuring multiple optical ADAT inputs and outputs
ADAT USB Audio Interface FPGA based USB 2.0 High Speed audio interface featuring multiple optical ADAT inputs and outputs Status / current limitations
78 Dec 31, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition (PyTorch) Paper: https://arxiv.org/abs/2105.01883 Citation: @
 260 Jan 3, 2023
260 Jan 3, 2023
Official implementation for ICDAR 2021 paper "Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer"
Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer Description Convert offline handwritten mathematical expressi
 87 Dec 27, 2022
87 Dec 27, 2022
PyTorch implementation for Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuous Sign Language Recognition.
Stochastic CSLR This is the PyTorch implementation for the ECCV 2020 paper: Stochastic Fine-grained Labeling of Multi-state Sign Glosses for Continuou
 28 Dec 19, 2022
28 Dec 19, 2022
AutoVideo: An Automated Video Action Recognition System
AutoVideo is a system for automated video analysis. It is developed based on D3M infrastructure, which describes machine learning with generic pipeline languages. Currently, it focuses on video action recognition, supporting various state-of-the-art video action recognition algorithms. It also supports automated model selection and hyperparameter tuning. AutoVideo is developed by DATA Lab at Texas A&M University.
 267 Dec 17, 2022
267 Dec 17, 2022

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022