291 Repositories
Python ee-land-cover-datasets Libraries
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023
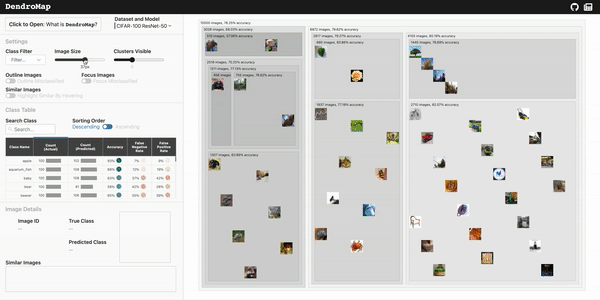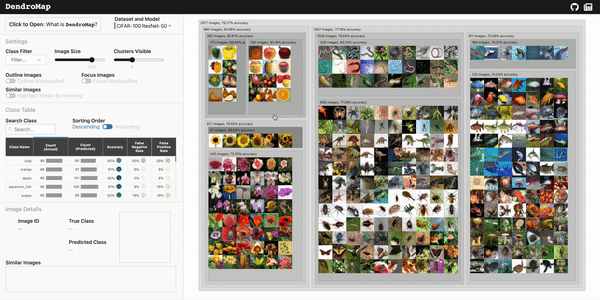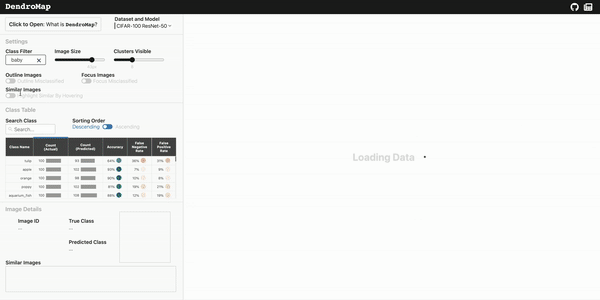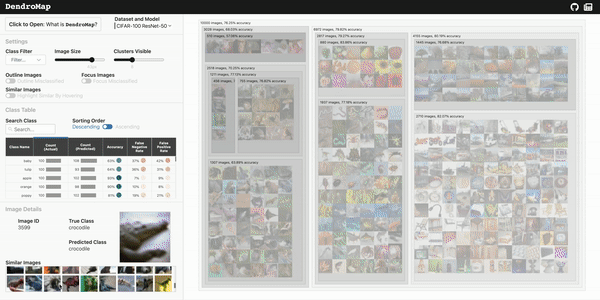
This repository contains the DendroMap implementation for scalable and interactive exploration of image datasets in machine learning.
DendroMap DendroMap is an interactive tool to explore large-scale image datasets used for machine learning. A deep understanding of your data can be v
 33 Dec 30, 2022
33 Dec 30, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022
Framework for evaluating ANNS algorithms on billion scale datasets.
Billion-Scale ANN http://big-ann-benchmarks.com/ Install The only prerequisite is Python (tested with 3.6) and Docker. Works with newer versions of Py
 132 Dec 24, 2022
132 Dec 24, 2022
![[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets](https://github.com/autonomousvision/stylegan_xl/raw/main/media/banner.png)
[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
[Project] [PDF] This repository contains code for our SIGGRAPH'22 paper "StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets" by Axel Sauer, Katja
 742 Jan 4, 2023
742 Jan 4, 2023

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
 66 Dec 14, 2022
66 Dec 14, 2022
Implementation of Basic Machine Learning Algorithms on small datasets using Scikit Learn.
Basic Machine Learning Algorithms All the basic Machine Learning Algorithms are implemented in Python using libraries Acknowledgements Machine Learnin
 47 Oct 16, 2022
47 Oct 16, 2022

This is a Python bot, which automates logging in, purchasing and planting the seeds. Open source bot and completely free.
🌻 Sunflower Land Bot 🌻 ⚠️ Warning I am not responsible for any penalties incurred by those who use the bot, use it at your own risk. This BOT is com
 18 Aug 31, 2022
18 Aug 31, 2022
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets.
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets. It makes dataset creation more effective and helps find essential insights from training results and improves AI performance.
 27 Oct 22, 2022
27 Oct 22, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
An extension package of 🤗 Datasets that provides support for executing arbitrary SQL queries on HF datasets
datasets_sql A 🤗 Datasets extension package that provides support for executing arbitrary SQL queries on HF datasets. It uses DuckDB as a SQL engine
 19 Dec 15, 2022
19 Dec 15, 2022
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data"
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data" You can download the pretrained
 3 May 7, 2022
3 May 7, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022

Datasets and pretrained Models for StyleGAN3 ...
Datasets and pretrained Models for StyleGAN3 ... Dear arfiticial friend, this is a collection of artistic datasets and models that we have put togethe
 34 Oct 6, 2022
34 Oct 6, 2022
Notebook and code to synthesize complex and highly dimensional datasets using Gretel APIs.
Gretel Trainer This code is designed to help users successfully train synthetic models on complex datasets with high row and column counts. The code w
 24 Nov 3, 2022
24 Nov 3, 2022
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022
A notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository
We provide a notebook that shows how to import the IITB English-Hindi Parallel Corpus from the HuggingFace datasets repository. The notebook also shows how to segment the corpus using BPE tokenization which can be used to train an English-Hindi MT System.
 9 Oct 13, 2022
9 Oct 13, 2022

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023
Graviti-python-sdk - Graviti Data Platform Python SDK
Graviti Python SDK Graviti Python SDK is a python library to access Graviti Data
 13 Dec 15, 2022
13 Dec 15, 2022

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023
Land Cover Classification Random Forest
You can perform Land Cover Classification on Satellite Images using Random Forest and visualize the result using Earthpy package. Make sure to install the required packages and such as
 1 Jan 21, 2022
1 Jan 21, 2022
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
An interactive App to play with Spotify data, both from the Spotify Web API and from CSV datasets.
 3 Jan 24, 2022
3 Jan 24, 2022
Awesome AI Learning with +100 AI Cheat-Sheets, Free online Books, Top Courses, Best Videos and Lectures, Papers, Tutorials, +99 Researchers, Premium Websites, +121 Datasets, Conferences, Frameworks, Tools
All about AI with Cheat-Sheets(+100 Cheat-sheets), Free Online Books, Courses, Videos and Lectures, Papers, Tutorials, Researchers, Websites, Datasets
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets
T‘rex Park is a Youzan sponsored project. Offering Chinese NLP and image models pretrained from E-commerce datasets (product titles, images, comments, etc.).
 55 Nov 22, 2022
55 Nov 22, 2022

Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization
Th2En & Th2Zh: The large-scale datasets for Thai text cross-lingual summarization 📥 Download Datasets 📥 Download Trained Models INTRODUCTION TH2ZH (
 5 Jan 3, 2022
5 Jan 3, 2022

A Unified Framework and Analysis for Structured Knowledge Grounding
UnifiedSKG 📚 : Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models Code for paper UnifiedSKG: Unifying and Mu
 370 Dec 21, 2022
370 Dec 21, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022
Few-Shot-Intent-Detection includes popular challenging intent detection datasets with/without OOS queries and state-of-the-art baselines and results.
Few-Shot-Intent-Detection Few-Shot-Intent-Detection is a repository designed for few-shot intent detection with/without Out-of-Scope (OOS) intents. It
 73 Dec 26, 2022
73 Dec 26, 2022

Python Auto-ML Package for Tabular Datasets
Tabular-AutoML AutoML Package for tabular datasets Tabular dataset tuning is now hassle free! Run one liner command and get best tuning and processed
 18 Nov 20, 2022
18 Nov 20, 2022
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes
Compartmental epidemic model to assess undocumented infections: applications to SARS-CoV-2 epidemics in Brazil - Datasets and Codes The codes for simu
 1 Jan 12, 2022
1 Jan 12, 2022
[ WSDM '22 ] On Sampling Collaborative Filtering Datasets
On Sampling Collaborative Filtering Datasets This repository contains the implementation of many popular sampling strategies, along with various expli
 17 Dec 8, 2022
17 Dec 8, 2022
A curated list of awesome game datasets, and tools to artificial intelligence in games
🎮 Awesome Game Datasets In computer science, Artificial Intelligence (AI) is intelligence demonstrated by machines. Its definition, AI research as th
 454 Jan 3, 2023
454 Jan 3, 2023

If you are worried about being found perhaps try taking cover under a blanket. Pure Python PowerShell Obfuscator
If you are worried about being found perhaps try taking cover under a blanket. Pure Python PowerShell Obfuscator
 3 Jun 7, 2022
3 Jun 7, 2022
Cl datasets - PyTorch image dataloaders and utility functions to load datasets for supervised continual learning
Continual learning datasets Introduction This repository contains PyTorch image
 5 Aug 28, 2022
5 Aug 28, 2022
Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis
Introduction This is an implementation of our paper Supervised 3D Pre-training on Large-scale 2D Natural Image Datasets for 3D Medical Image Analysis.
 24 Dec 6, 2022
24 Dec 6, 2022
This is the source code for generating the ASL-Skeleton3D and ASL-Phono datasets. Check out the README.md for more details.
ASL-Skeleton3D and ASL-Phono Datasets Generator The ASL-Skeleton3D contains a representation based on mapping into the three-dimensional space the coo
 5 Nov 20, 2022
5 Nov 20, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
![[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021](https://github.com/hasanirtiza/Pedestron/raw/master/gifs/1.gif)
[Pedestron] Generalizable Pedestrian Detection: The Elephant In The Room. @ CVPR2021
Pedestron Pedestron is a MMdetection based repository, that focuses on the advancement of research on pedestrian detection. We provide a list of detec
 594 Jan 5, 2023
594 Jan 5, 2023

A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
A minimal yet resourceful implementation of diffusion models (along with pretrained models + synthetic images for nine datasets)
 65 Dec 19, 2022
65 Dec 19, 2022
Jupyter notebook and datasets from the pandas Q&A video series
Python pandas Q&A video series Read about the series, and view all of the videos on one page: Easier data analysis in Python with pandas. Jupyter Note
 2k Jan 5, 2023
2k Jan 5, 2023
A general and strong 3D object detection codebase that supports more methods, datasets and tools (debugging, recording and analysis).
ALLINONE-Det ALLINONE-Det is a general and strong 3D object detection codebase built on OpenPCDet, which supports more methods, datasets and tools (de
 5 Nov 3, 2022
5 Nov 3, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Customer Service Requests Analysis is one of the practical life problems that an analyst may face. This Project is one such take. The project is a beginner to intermediate level project. This repository has a Source Code, README file, Dataset, Image and License file.
Customer Service Requests Analysis Project 1 DESCRIPTION Background of Problem Statement : NYC 311's mission is to provide the public with quick and e
 7 Sep 19, 2022
7 Sep 19, 2022

Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
Real-time face detection and emotion/gender classification using fer2013/imdb datasets with a keras CNN model and openCV.
 5.3k Dec 30, 2022
5.3k Dec 30, 2022

Streamlit tool to explore coco datasets
What is this This tool given a COCO annotations file and COCO predictions file will let you explore your dataset, visualize results and calculate impo
 75 Dec 16, 2022
75 Dec 16, 2022

This repository contains datasets and baselines for benchmarking Chinese text recognition.
Benchmarking-Chinese-Text-Recognition This repository contains datasets and baselines for benchmarking Chinese text recognition. Please see the corres
 254 Dec 30, 2022
254 Dec 30, 2022

Interactive dimensionality reduction for large datasets
BlosSOM 🌼 BlosSOM is a graphical environment for running semi-supervised dimensionality reduction with EmbedSOM. You can use it to explore multidimen
 19 Dec 14, 2022
19 Dec 14, 2022
This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detection', CVPR 2019.
Code-and-Dataset-for-CapSal This project provides the code and datasets for 'CapSal: Leveraging Captioning to Boost Semantics for Salient Object Detec
 48 Aug 19, 2022
48 Aug 19, 2022
Imports VZD (Latvian State Land Service) open data into postgis enabled database
Python script main.py downloads and imports Latvian addresses into PostgreSQL database. Data contains parishes, counties, cities, towns, and streets.
 7 Oct 26, 2022
7 Oct 26, 2022

TarkovScrappy - A nifty little bot that lets you know if a queried item might be required for a quest at some point in the land of Tarkov!
TarkovScrappy A nifty little bot that lets you know if a queried item might be required for a quest at some point in the land of Tarkov! Hideout items
 2 Apr 11, 2022
2 Apr 11, 2022
This Crash Course will cover all you need to know to start using Plotly in your projects.
Plotly Crash Course This course was designed to help you get started using Plotly. If you ever felt like your data visualization skills could use an u
 2 Aug 21, 2022
2 Aug 21, 2022

SPT_LSA_ViT - Implementation for Visual Transformer for Small-size Datasets
Vision Transformer for Small-Size Datasets Seung Hoon Lee and Seunghyun Lee and Byung Cheol Song | Paper Inha University Abstract Recently, the Vision
 87 Jan 1, 2023
87 Jan 1, 2023
StyleGAN2-ADA-training-jupyter - Training custom datasets in styleGAN2-ADA by NVIDIA using Jupyter
styleGAN2-ADA-training-jupyter Training custom datasets in styleGAN2-ADA on Jupyter Official StyleGAN2-ADA by NIVIDIA Paper Training Generative Advers
 2 Feb 24, 2022
2 Feb 24, 2022
Datasets for new state-of-the-art challenge in disentanglement learning
High resolution disentanglement datasets This repository contains the Falcor3D and Isaac3D datasets, which present a state-of-the-art challenge for co
 37 May 26, 2022
37 May 26, 2022
Quickly download, clean up, and install public datasets into a database management system
Finding data is one thing. Getting it ready for analysis is another. Acquiring, cleaning, standardizing and importing publicly available data is time
 274 Jan 4, 2023
274 Jan 4, 2023
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible
Python script that analyses the given datasets and comes up with the best polynomial regression representation with the smallest polynomial degree possible, to be the most reliable with the least complexity possible
 2 Aug 1, 2022
2 Aug 1, 2022
A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets
Notebooks A NASA MEaSUREs project to provide automated, low latency, global glacier flow and elevation change datasets This repository provides tools
 27 Oct 25, 2022
27 Oct 25, 2022

Code to generate datasets used in "How Useful is Self-Supervised Pretraining for Visual Tasks?"
Synthetic dataset rendering Framework for producing the synthetic datasets used in: How Useful is Self-Supervised Pretraining for Visual Tasks? Alejan
 21 Apr 29, 2022
21 Apr 29, 2022

Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
Official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
 689 Dec 25, 2022
689 Dec 25, 2022
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size.
Hub is a dataset format with a simple API for creating, storing, and collaborating on AI datasets of any size. The hub data layout enables rapid transformations and streaming of data while training models at scale. Hub is used by Google, Waymo, Red Cross, Oxford University, and Omdena.
 5.1k Jan 8, 2023
5.1k Jan 8, 2023
Tool to get Canvas cover videos from Spotify tracks.
Spotify Canvas Downloader Tool to get Canvas cover videos from Spotify tracks. ✨ Try it out Building Clone the repository git clone https://github.com
 35 Dec 28, 2022
35 Dec 28, 2022
Datasets with Softcatalà website content
softcatala-web-dataset This repository contains Sofcatalà web site content (articles and programs descriptions). Dataset are available in the dataset
 2 Dec 26, 2021
2 Dec 26, 2021
LynxKite: a complete graph data science platform for very large graphs and other datasets.
LynxKite is a complete graph data science platform for very large graphs and other datasets. It seamlessly combines the benefits of a friendly graphical interface and a powerful Python API.
 124 Dec 14, 2022
124 Dec 14, 2022
A Python library that simplifies the extraction of datasets from XML content.
xmldataset: simple xml parsing 🗃️ XML Dataset: simple xml parsing Documentation: https://xmldataset.readthedocs.io A Python library that simplifies t
 75 Dec 30, 2022
75 Dec 30, 2022
The Agriculture Domain of ERPNext comes with features to record crops and land
Agriculture The Agriculture Domain of ERPNext comes with features to record crops and land, track plant, soil, water, weather analytics, and even trac
 21 Jan 2, 2023
21 Jan 2, 2023
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 8 Nov 21, 2022
8 Nov 21, 2022
Index different CKAN entities in Solr, not just datasets
ckanext-sitesearch Index different CKAN entities in Solr, not just datasets Requirements This extension requires CKAN 2.9 or higher and Python 3 Featu
 3 Dec 2, 2022
3 Dec 2, 2022
Final project code: Implementing MAE with downscaled encoders and datasets, for ESE546 FA21 at University of Pennsylvania
546 Final Project: Masked Autoencoder Haoran Tang, Qirui Wu 1. Training To train the network, please run mae_pretraining.py. Please modify folder path
 0 Apr 22, 2022
0 Apr 22, 2022
Open source annotation tool for machine learning practitioners.
doccano doccano is an open source text annotation tool for humans. It provides annotation features for text classification, sequence labeling and sequ
 7.1k Jan 1, 2023
7.1k Jan 1, 2023
AKShare is an elegant and simple financial data interface library for Python, built for human beings
AKShare is an elegant and simple financial data interface library for Python, built for human beings
 5.8k Dec 30, 2022
5.8k Dec 30, 2022
An elaborate and exhaustive paper list for Named Entity Recognition (NER)
Named-Entity-Recognition-NER-Papers by Pengfei Liu, Jinlan Fu and other contributors. An elaborate and exhaustive paper list for Named Entity Recognit
 388 Dec 18, 2022
388 Dec 18, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022
🏆 • 5050 most frequent words in 109 languages
🏆 Most Common Words Multilingual 5000 most frequent words in 109 languages. Uses wordfrequency.info as a source. 🔗 License source code license data
 14 Nov 24, 2022
14 Nov 24, 2022
demir.ai Dataset Operations
demir.ai Dataset Operations With this application, you can have the empty values (nan/null) deleted or filled before giving your dataset to machine le
 8 Nov 1, 2022
8 Nov 1, 2022
This repository contains the code, models and datasets discussed in our paper "Few-Shot Question Answering by Pretraining Span Selection"
Splinter This repository contains the code, models and datasets discussed in our paper "Few-Shot Question Answering by Pretraining Span Selection", to
 88 Dec 31, 2022
88 Dec 31, 2022
Library of deep learning models and datasets designed to make deep learning more accessible and accelerate ML research.
Tensor2Tensor Tensor2Tensor, or T2T for short, is a library of deep learning models and datasets designed to make deep learning more accessible and ac
 12.9k Jan 7, 2023
12.9k Jan 7, 2023

A public data repository for datasets created from TransLink GTFS data.
TransLink Spatial Data What: TransLink is the statutory public transit authority for the Metro Vancouver region. This GitHub repository is a collectio
 3 Jan 14, 2022
3 Jan 14, 2022

The datasets and code of ACL 2021 paper "Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions".
Aspect-Category-Opinion-Sentiment (ACOS) Quadruple Extraction This repo contains the data sets and source code of our paper: Aspect-Category-Opinion-S
 144 Jan 2, 2023
144 Jan 2, 2023
A collection of existing KGQA datasets in the form of the huggingface datasets library, aiming to provide an easy-to-use access to them.
KGQA Datasets Brief Introduction This repository is a collection of existing KGQA datasets in the form of the huggingface datasets library, aiming to
 21 Jan 6, 2023
21 Jan 6, 2023

CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological images.
cleanX CleanX is an open source python library for exploring, cleaning and augmenting large datasets of X-rays, or certain other types of radiological
 20 Jan 5, 2023
20 Jan 5, 2023

Binary classification for arrythmia detection with ECG datasets.
HEART DISEASE AI DATATHON 2021 [Eng] / [Kor] #English This is an AI diagnosis modeling contest that uses the heart disease echocardiography and electr
 3 Jul 14, 2022
3 Jul 14, 2022
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets
Easy Language Model Pretraining leveraging Huggingface's Transformers and Datasets What is LASSL • How to Use What is LASSL LASSL은 LAnguage Semi-Super
 116 Dec 27, 2022
116 Dec 27, 2022
Synthetic Data Generation for tabular, relational and time series data.
An Open Source Project from the Data to AI Lab, at MIT Website: https://sdv.dev Documentation: https://sdv.dev/SDV User Guides Developer Guides Github
 1.2k Jan 7, 2023
1.2k Jan 7, 2023
Models, datasets and tools for Facial keypoints detection
Template for Data Science Project This repo aims to give a robust starting point to any Data Science related project. It contains readymade tools setu
 1 Feb 11, 2022
1 Feb 11, 2022