1442 Repositories
Python human-language Libraries
![[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427](https://github.com/jiawei-ren/BalancedMSE/raw/main/figures/intro.png)
[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427
Balanced MSE Code for the paper: Balanced MSE for Imbalanced Visual Regression Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Ziwei Liu CVPR 2022 (Oral) News
 267 Jan 1, 2023
267 Jan 1, 2023
Relative Human dataset, CVPR 2022
Relative Human (RH) contains multi-person in-the-wild RGB images with rich human annotations, including: Depth layers (DLs): relative depth relationsh
 112 Dec 2, 2022
112 Dec 2, 2022
![[CVPR 2022] PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision (Oral)](https://github.com/Garfield-kh/PoseTriplet/raw/main/assets/dual-loop-detail-v3.jpg)
[CVPR 2022] PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision (Oral)
PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision Kehong Gong*, Bingbing Li*, Jianfeng Zhang*, Ta
 256 Dec 28, 2022
256 Dec 28, 2022

Pytorch implementation of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Make-A-Scene - PyTorch Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/
 259 Dec 28, 2022
259 Dec 28, 2022
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
115 Dec 16, 2022
![[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception](https://github.com/hongfz16/HCMoCo/raw/main/assets/teaser.png)
[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception
Versatile Multi-Modal Pre-Training for Human-Centric Perception Fangzhou Hong1 Liang Pan1 Zhongang Cai1,2,3 Ziwei Liu1* 1S-Lab, Nanyang Technologic
 96 Jan 3, 2023
96 Jan 3, 2023

Entity Disambiguation as text extraction (ACL 2022)
ExtEnD: Extractive Entity Disambiguation This repository contains the code of ExtEnD: Extractive Entity Disambiguation, a novel approach to Entity Dis
 121 Jan 3, 2023
121 Jan 3, 2023

A multi-lingual approach to AllenNLP CoReference Resolution along with a wrapper for spaCy.
Crosslingual Coreference Coreference is amazing but the data required for training a model is very scarce. In our case, the available training for non
 71 Jan 4, 2023
71 Jan 4, 2023
![[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links](https://github.com/michiyasunaga/LinkBERT/raw/main/figs/overview.png)
[ACL 2022] LinkBERT: A Knowledgeable Language Model 😎 Pretrained with Document Links
LinkBERT: A Knowledgeable Language Model Pretrained with Document Links This repo provides the model, code & data of our paper: LinkBERT: Pretraining
 264 Jan 1, 2023
264 Jan 1, 2023

Generate images from texts. In Russian
ruDALL-E Generate images from texts pip install rudalle==1.1.0rc0 🤗 HF Models: ruDALL-E Malevich (XL) ruDALL-E Emojich (XL) (readme here) ruDALL-E S
 1.6k Dec 31, 2022
1.6k Dec 31, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022

🙌Kart of 210+ projects based on machine learning, deep learning, computer vision, natural language processing and all. Show your support by ✨ this repository.
ML-ProjectKart 📌 Repository This kart showcases the finest collection of all projects based on machine learning, deep learning, computer vision, natu
 203 Dec 28, 2022
203 Dec 28, 2022
Curso práctico: NLP de cero a cien 🤗
Curso Práctico: NLP de cero a cien Comprende todos los conceptos y arquitecturas clave del estado del arte del NLP y aplícalos a casos prácticos utili
 147 Jan 6, 2023
147 Jan 6, 2023

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Official PyTorch implementation of the paper "TEMOS: Generating diverse human motions from textual descriptions"
TEMOS: TExt to MOtionS Generating diverse human motions from textual descriptions Description Official PyTorch implementation of the paper "TEMOS: Gen
 187 Dec 27, 2022
187 Dec 27, 2022

Face and Pose detector that emits MQTT events when a face or human body is detected and not detected.
Face Detect MQTT Face or Pose detector that emits MQTT events when a face or human body is detected and not detected. I built this as an alternative t
 38 Oct 21, 2022
38 Oct 21, 2022
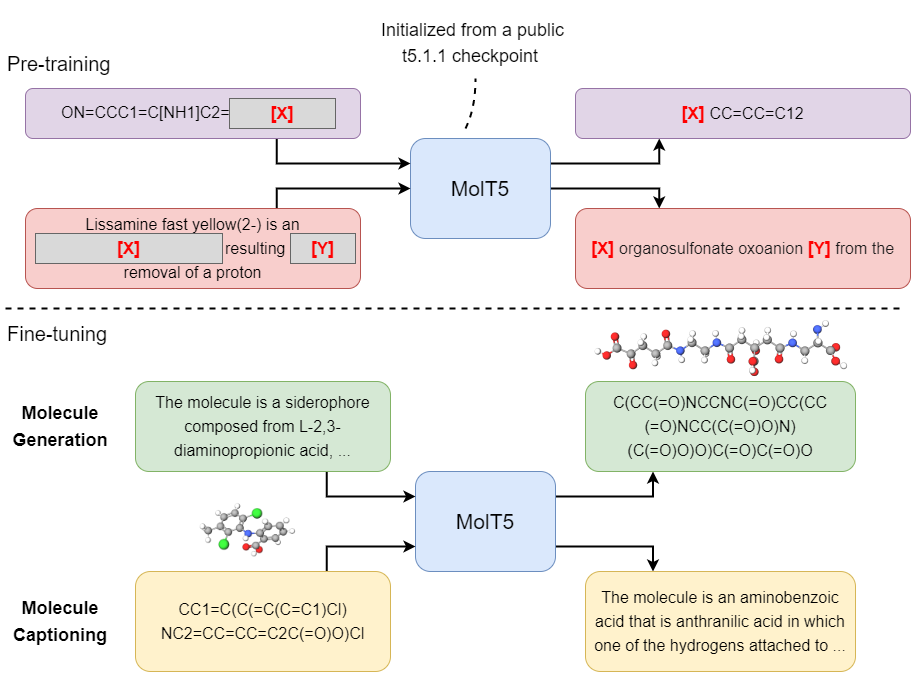
Associated Repository for "Translation between Molecules and Natural Language"
MolT5: Translation between Molecules and Natural Language Associated repository for "Translation between Molecules and Natural Language". Table of Con
 67 Dec 15, 2022
67 Dec 15, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022
An attempt to map the areas with active conflict in Ukraine using open source twitter data.
Live Action Map (LAM) An attempt to use open source data on Twitter to map areas with active conflict. Right now it is used for the Ukraine-Russia con
 171 Nov 21, 2022
171 Nov 21, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022
Natural Language Processing - Sommer Semester 2022
Natural Language Processing (DIS25a/NLP) This course can be taken for the Bachelor Programm Data and Information Science (DIS25a) or the Master Progra
 19 Sep 7, 2022
19 Sep 7, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

code for TCL: Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022
Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022 News (03/16/2022) upload retrieval checkpoints finetuned on COCO and Flickr T
 187 Jan 2, 2023
187 Jan 2, 2023

SentimentArcs: a large ensemble of dozens of sentiment analysis models to analyze emotion in text over time
SentimentArcs - Emotion in Text An end-to-end pipeline based on Jupyter notebooks to detect, extract, process and anlayze emotion over time in text. E
 14 Dec 19, 2022
14 Dec 19, 2022

Doing the asl sign language classification on static images using graph neural networks.
SignLangGNN When GNNs 💜 MediaPipe. This is a starter project where I tried to implement some traditional image classification problem i.e. the ASL si
 10 Nov 9, 2022
10 Nov 9, 2022
DLO8012: Natural Language Processing & CSL804: Computational Lab - II Semester VIII
NATURAL-LANGUAGE-PROCESSING-AND-COMPUTATIONAL-LAB-II DLO8012: NLP & CSL804: CL-II [SEMESTER VIII] Syllabus NLP - Reference Books THE WALL MEGA SATISH
 7 Apr 28, 2022
7 Apr 28, 2022

Sapiens is a human antibody language model based on BERT.
Sapiens: Human antibody language model ____ _ / ___| __ _ _ __ (_) ___ _ __ ___ \___ \ / _` | '_ \| |/ _ \ '
 13 Nov 20, 2022
13 Nov 20, 2022

Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space"
MotionCLIP Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space". Please visit our webpage for mor
 173 Dec 26, 2022
173 Dec 26, 2022

Process text, including tokenizing and representing sentences as vectors and Applying some concepts like RNN, LSTM and GRU to create a classifier can detect the language in which a sentence is written from among 17 languages.
Language Identifier What is this ? The goal of this project is to create a model that is able to predict a given sentence language through text proces
 9 Dec 15, 2022
9 Dec 15, 2022

The FLARE team's open-source library to disassemble Common Intermediate Language (CIL) instructions.
dncil is a Common Intermediate Language (CIL) disassembly library written in Python that supports parsing the header, instructions, and exception hand
 95 Jan 8, 2023
95 Jan 8, 2023

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023

Guide to using pre-trained large language models of source code
Large Models of Source Code I occasionally train and publicly release large neural language models on programs, including PolyCoder. Here, I describe
 947 Dec 28, 2022
947 Dec 28, 2022
AI Summer's complete catalog of articles
Learn Deep Learning with AI Summer A collection of all articles (almost 100) written for the AI Summer blog organized by topic. Deep Learning Theory M
 95 Dec 29, 2022
95 Dec 29, 2022
Get started with Machine Learning with Python - An introduction with Python programming examples
Machine Learning With Python Get started with Machine Learning with Python An engaging introduction to Machine Learning with Python TL;DR Download all
 130 Jan 2, 2023
130 Jan 2, 2023

Large-scale language modeling tutorials with PyTorch
Large-scale language modeling tutorials with PyTorch 안녕하세요. 저는 TUNiB에서 머신러닝 엔지니어로 근무 중인 고현웅입니다. 이 자료는 대규모 언어모델 개발에 필요한 여러가지 기술들을 소개드리기 위해 마련하였으며 기본적으로
 172 Dec 29, 2022
172 Dec 29, 2022

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022
ICON: Implicit Clothed humans Obtained from Normals (CVPR 2022)
ICON: Implicit Clothed humans Obtained from Normals Yuliang Xiu · Jinlong Yang · Dimitrios Tzionas · Michael J. Black CVPR 2022 News 🚩 [2022/04/26] H
 1.1k Jan 4, 2023
1.1k Jan 4, 2023

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

StyleGAN-Human: A Data-Centric Odyssey of Human Generation
StyleGAN-Human: A Data-Centric Odyssey of Human Generation Abstract: Unconditional human image generation is an important task in vision and graphics,
 762 Jan 8, 2023
762 Jan 8, 2023
Applied Natural Language Processing in the Enterprise - An O'Reilly Media Publication
Applied Natural Language Processing in the Enterprise This is the companion repo for Applied Natural Language Processing in the Enterprise, an O'Reill
 95 Jan 5, 2023
95 Jan 5, 2023
A benchmark for evaluation and comparison of various NLP tasks in Persian language.
Persian NLP Benchmark The repository aims to track existing natural language processing models and evaluate their performance on well-known datasets.
 68 Dec 19, 2022
68 Dec 19, 2022
An ever-growing playground of notebooks showcasing CLIP's impressive zero-shot capabilities.
Playground for CLIP-like models Demo Colab Link GradCAM Visualization Naive Zero-shot Detection Smarter Zero-shot Detection Captcha Solver Changelog 2
 101 Dec 30, 2022
101 Dec 30, 2022

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023
The implementation our EMNLP 2021 paper "Enhanced Language Representation with Label Knowledge for Span Extraction".
LEAR The implementation our EMNLP 2021 paper "Enhanced Language Representation with Label Knowledge for Span Extraction". See below for an overview of
 93 Jan 7, 2023
93 Jan 7, 2023

This is a repo of basic Machine Learning!
Basic Machine Learning This repository contains a topic-wise curated list of Machine Learning and Deep Learning tutorials, articles and other resource
 53 Dec 31, 2022
53 Dec 31, 2022

Make your first PR. A beginner friendly repository made specifically for open source beginners. Add any program under any language (it can be anything from a simple program to a complex data structure algorithm). Happy coding...
Hacktober Fest 2021 Upload Different Types of Programs in any Language Use this project to make your first contribution to an open source project on G
 40 Oct 11, 2022
40 Oct 11, 2022

MAGMA - a GPT-style multimodal model that can understand any combination of images and language
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning Authors repo (alphabetical) Constantin (CoEich), Mayukh (Mayukh
 331 Jan 3, 2023
331 Jan 3, 2023
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022
Data and code to support "Applied Natural Language Processing" (INFO 256, Fall 2021, UC Berkeley)
anlp21 Course materials for "Applied Natural Language Processing" (INFO 256, Fall 2021, UC Berkeley) Syllabus: http://people.ischool.berkeley.edu/~dba
 48 Dec 6, 2022
48 Dec 6, 2022
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022 [Project page | Video] Getting sta
 51 Nov 29, 2022
51 Nov 29, 2022

Code for CVPR'2022 paper ✨ "Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model"
PPE ✨ Repository for our CVPR'2022 paper: Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-
 34 Nov 28, 2022
34 Nov 28, 2022
![[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators](https://github.com/microsoft/AMOS/raw/main/AMOS.png)
[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
AMOS This repository contains the scripts for fine-tuning AMOS pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: Pretraining Text Encoders wi
 22 Sep 15, 2022
22 Sep 15, 2022

ACL22 paper: Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost
Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost LOVE is accpeted by ACL22 main conference as a long pape
 32 Jan 3, 2023
32 Jan 3, 2023

Code and data for ImageCoDe, a contextual vison-and-language benchmark
ImageCoDe This repository contains code and data for ImageCoDe: Image Retrieval from Contextual Descriptions. Data All collected descriptions for the
 27 Dec 2, 2022
27 Dec 2, 2022

Official Pytorch implementation of "Learning to Estimate Robust 3D Human Mesh from In-the-Wild Crowded Scenes", CVPR 2022
Learning to Estimate Robust 3D Human Mesh from In-the-Wild Crowded Scenes / 3DCrowdNet News 💪 3DCrowdNet achieves the state-of-the-art accuracy on 3D
 113 Dec 21, 2022
113 Dec 21, 2022

Implementation of a protein autoregressive language model, but with autoregressive infilling objective (editing subsequences capability)
Protein GLM (wip) Implementation of a protein autoregressive language model, but with autoregressive infilling objective (editing subsequences capabil
 17 May 6, 2022
17 May 6, 2022

SIGIR'22 paper: Axiomatically Regularized Pre-training for Ad hoc Search
Introduction This codebase contains source-code of the Python-based implementation (ARES) of our SIGIR 2022 paper. Chen, Jia, et al. "Axiomatically Re
 17 Nov 9, 2022
17 Nov 9, 2022

Implementation of "Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis"
Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis Abstract: This work targets at using a general deep lea
 163 Dec 14, 2022
163 Dec 14, 2022

A Human-in-the-Loop workflow for creating HD images from text
A Human-in-the-Loop? workflow for creating HD images from text DALL·E Flow is an interactive workflow for generating high-definition images from text
 2.5k Jan 2, 2023
2.5k Jan 2, 2023

CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
CLIP-GEN [简体中文][English] 本项目在萤火二号集群上用 PyTorch 实现了论文 《CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP》。 CLIP-GEN 是一个 Language-F
 75 Dec 29, 2022
75 Dec 29, 2022
Official codebase for ICLR oral paper Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling
CLIORA This is the official codebase for ICLR oral paper: Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling. We introduce
 32 Dec 23, 2022
32 Dec 23, 2022
The official code of LM-Debugger, an interactive tool for inspection and intervention in transformer-based language models.
LM-Debugger is an open-source interactive tool for inspection and intervention in transformer-based language models. This repository includes the code
 110 Dec 28, 2022
110 Dec 28, 2022
This is an official implementation for "DeciWatch: A Simple Baseline for 10x Efficient 2D and 3D Pose Estimation"
DeciWatch: A Simple Baseline for 10× Efficient 2D and 3D Pose Estimation This repo is the official implementation of "DeciWatch: A Simple Baseline for
 117 Dec 24, 2022
117 Dec 24, 2022
A general-purpose programming language, focused on simplicity, safety and stability.
The Rivet programming language A general-purpose programming language, focused on simplicity, safety and stability. Rivet's goal is to be a very power
 17 Dec 29, 2022
17 Dec 29, 2022

Source code of our TTH paper: Targeted Trojan-Horse Attacks on Language-based Image Retrieval.
Targeted Trojan-Horse Attacks on Language-based Image Retrieval Source code of our TTH paper: Targeted Trojan-Horse Attacks on Language-based Image Re
 7 Aug 23, 2022
7 Aug 23, 2022
PyTorch Implementation of "Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging" (Findings of ACL 2022)
Feature_CRF_AE Feature_CRF_AE provides a implementation of Bridging Pre-trained Language Models and Hand-crafted Features for Unsupervised POS Tagging
 6 Apr 29, 2022
6 Apr 29, 2022
Input english text, then translate it between languages n times using the Deep Translator Python Library.
mass-translator About Input english text, then translate it between languages n times using the Deep Translator Python Library. How to Use Install dep
 2 Mar 4, 2022
2 Mar 4, 2022
A brainfuck-based game oriented language written in python.
GF.py STILL WIP Gamefuck.py is a programming language based off brainfuck. It is oriented towards game development, and as such has many commands spec
 1 Feb 23, 2022
1 Feb 23, 2022

ZeroGen: Efficient Zero-shot Learning via Dataset Generation
ZEROGEN This repository contains the code for our paper “ZeroGen: Efficient Zero
 31 Dec 30, 2022
31 Dec 30, 2022
SimCTG - A Contrastive Framework for Neural Text Generation
A Contrastive Framework for Neural Text Generation Authors: Yixuan Su, Tian Lan,
345 Jan 3, 2023

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022

SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING - The Facebook paper about fine tuning RoBERTa with contrastive loss
"# SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING" i
 28 Dec 12, 2022
28 Dec 12, 2022
Textlesslib - Library for Textless Spoken Language Processing
textlesslib Textless NLP is an active area of research that aims to extend NLP t
379 Dec 27, 2022
Python-samples - This project is to help someone need some practices when learning python language
Python-samples - This project is to help someone need some practices when learning python language
 0 Feb 14, 2022
0 Feb 14, 2022
OpenDelta - An Open-Source Framework for Paramter Efficient Tuning.
OpenDelta is a toolkit for parameter efficient methods (we dub it as delta tuning), by which users could flexibly assign (or add) a small amount parameters to update while keeping the most paramters frozen. By using OpenDelta, users could easily implement prefix-tuning, adapters, Lora, or any other types of delta tuning with preferred PTMs.
 386 Dec 26, 2022
386 Dec 26, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022
SemEval2022 Patronizing and Condescending Language (PCL) Detection
SemEval2022 Patronizing and Condescending Language (PCL) Detection This task is from SemEval 2022. What is Patronizing and Condescending Language (PCL
 0 Aug 5, 2022
0 Aug 5, 2022

OMLT: Optimization and Machine Learning Toolkit
OMLT is a Python package for representing machine learning models (neural networks and gradient-boosted trees) within the Pyomo optimization environment.
 179 Jan 2, 2023
179 Jan 2, 2023

Real time sign language recognition
The proposed work aims at converting american sign language gestures into English that can be understood by everyone in real time.
 6 Jun 13, 2022
6 Jun 13, 2022

OceanScript is an Esoteric language used to encode and decode text into a formulation of characters
OceanScript is an Esoteric language used to encode and decode text into a formulation of characters - where the final result looks like waves in the ocean.
 2 Sep 9, 2022
2 Sep 9, 2022

Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations
TopClus The source code used for Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations, published in WWW 2022. Requ
 63 Dec 18, 2022
63 Dec 18, 2022

BASH - Biomechanical Animated Skinned Human
We developed a method animating a statistical 3D human model for biomechanical analysis to increase accessibility for non-experts, like patients, athletes, or designers.
 66 Nov 19, 2022
66 Nov 19, 2022
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents. Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts
 94 Dec 30, 2022
94 Dec 30, 2022
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
98 Dec 15, 2022

A simple machine learning python sign language detection project.
SST Coursework 2022 About the app A python application that utilises the tensorflow object detection algorithm to achieve automatic detection of ameri
 2 Jun 30, 2022
2 Jun 30, 2022
A general purpose low level programming language written in Python.
A general purpose low level programming language written in Python. Basal is an easy mid level programming language compiling to C. It has an easy syntax, similar to Python, Rust etc.
 6 Mar 30, 2022
6 Mar 30, 2022

Binary++ is an esoteric programming language based on* binary
Binary++ is an esoteric programming language based on* binary. * It's meant to be based on binary, but you can write Binary++ code using different mea
 3 Feb 18, 2022
3 Feb 18, 2022
Building Ellee — A GPT-3 and Computer Vision Powered Talking Robotic Teddy Bear With Human Level Conversation Intelligence
Using an object detection and facial recognition system built on MobileNetSSDV2 and Dlib and running on an NVIDIA Jetson Nano, a GPT-3 model, Google Speech Recognition, Amazon Polly and servo motors, I built Ellee - a robotic teddy bear who can move her head and converse naturally.
 24 Oct 26, 2022
24 Oct 26, 2022
Migrates translations to the REDCap native Multi-Language Management system
Automates much of the process of moving translations from the old Multilingual external module to the newer built-in Multi-Language Management (MLM) page.
 3 Sep 27, 2022
3 Sep 27, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022
Rank-One Model Editing for Locating and Editing Factual Knowledge in GPT
Rank-One Model Editing (ROME) This repository provides an implementation of Rank-One Model Editing (ROME) on auto-regressive transformers (GPU-only).
 130 Dec 21, 2022
130 Dec 21, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
38 Dec 12, 2022
Explore extreme compression for pre-trained language models
Code for paper "Exploring extreme parameter compression for pre-trained language models ICLR2022"
 16 Nov 14, 2022
16 Nov 14, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022