476 Repositories
Python human-readable-representations Libraries
![[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427](https://github.com/jiawei-ren/BalancedMSE/raw/main/figures/intro.png)
[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427
Balanced MSE Code for the paper: Balanced MSE for Imbalanced Visual Regression Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Ziwei Liu CVPR 2022 (Oral) News
 267 Jan 1, 2023
267 Jan 1, 2023
Relative Human dataset, CVPR 2022
Relative Human (RH) contains multi-person in-the-wild RGB images with rich human annotations, including: Depth layers (DLs): relative depth relationsh
 112 Dec 2, 2022
112 Dec 2, 2022
![[CVPR 2022] PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision (Oral)](https://github.com/Garfield-kh/PoseTriplet/raw/main/assets/dual-loop-detail-v3.jpg)
[CVPR 2022] PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision (Oral)
PoseTriplet: Co-evolving 3D Human Pose Estimation, Imitation, and Hallucination under Self-supervision Kehong Gong*, Bingbing Li*, Jianfeng Zhang*, Ta
 256 Dec 28, 2022
256 Dec 28, 2022

Pytorch implementation of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Make-A-Scene - PyTorch Pytorch implementation (inofficial) of Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors (https://arxiv.org/
 259 Dec 28, 2022
259 Dec 28, 2022

Unofficial implementation (replicates paper results!) of MINER: Multiscale Implicit Neural Representations in pytorch-lightning
MINER_pl Unofficial implementation of MINER: Multiscale Implicit Neural Representations in pytorch-lightning. 📖 Ref readings Laplacian pyramid explan
 51 Nov 28, 2022
51 Nov 28, 2022
This is the code for the paper "Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, Tao Mei: Gait Recognition in the Wild with Dense 3D Representations and A Benchmark. (CVPR 2022)"
Gait3D-Benchmark This is the code for the paper "Jinkai Zheng, Xinchen Liu, Wu Liu, Lingxiao He, Chenggang Yan, Tao Mei: Gait Recognition in the Wild
 82 Jan 4, 2023
82 Jan 4, 2023
![[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception](https://github.com/hongfz16/HCMoCo/raw/main/assets/teaser.png)
[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception
Versatile Multi-Modal Pre-Training for Human-Centric Perception Fangzhou Hong1 Liang Pan1 Zhongang Cai1,2,3 Ziwei Liu1* 1S-Lab, Nanyang Technologic
 96 Jan 3, 2023
96 Jan 3, 2023

Official PyTorch implementation of the paper "TEMOS: Generating diverse human motions from textual descriptions"
TEMOS: TExt to MOtionS Generating diverse human motions from textual descriptions Description Official PyTorch implementation of the paper "TEMOS: Gen
 187 Dec 27, 2022
187 Dec 27, 2022
Official PyTorch implementation of BlobGAN: Spatially Disentangled Scene Representations
BlobGAN: Spatially Disentangled Scene Representations Official PyTorch Implementation Paper | Project Page | Video | Interactive Demo BlobGAN.mp4 This
 148 Dec 29, 2022
148 Dec 29, 2022

Face and Pose detector that emits MQTT events when a face or human body is detected and not detected.
Face Detect MQTT Face or Pose detector that emits MQTT events when a face or human body is detected and not detected. I built this as an alternative t
 38 Oct 21, 2022
38 Oct 21, 2022

Python library for tracking human heads with FLAME (a 3D morphable head model)
Video Head Tracker 3D tracking library for human heads based on FLAME (a 3D morphable head model). The tracking algorithm is inspired by face2face. It
 61 Dec 25, 2022
61 Dec 25, 2022

Sapiens is a human antibody language model based on BERT.
Sapiens: Human antibody language model ____ _ / ___| __ _ _ __ (_) ___ _ __ ___ \___ \ / _` | '_ \| |/ _ \ '
 13 Nov 20, 2022
13 Nov 20, 2022

Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space"
MotionCLIP Official Pytorch implementation of the paper "MotionCLIP: Exposing Human Motion Generation to CLIP Space". Please visit our webpage for mor
 173 Dec 26, 2022
173 Dec 26, 2022
ICON: Implicit Clothed humans Obtained from Normals (CVPR 2022)
ICON: Implicit Clothed humans Obtained from Normals Yuliang Xiu · Jinlong Yang · Dimitrios Tzionas · Michael J. Black CVPR 2022 News 🚩 [2022/04/26] H
 1.1k Jan 4, 2023
1.1k Jan 4, 2023

StyleGAN-Human: A Data-Centric Odyssey of Human Generation
StyleGAN-Human: A Data-Centric Odyssey of Human Generation Abstract: Unconditional human image generation is an important task in vision and graphics,
 762 Jan 8, 2023
762 Jan 8, 2023

Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
Audio2Face - a project that transforms audio to blendshape weights,and drives the digital human,xiaomei,in UE project
 732 Jan 8, 2023
732 Jan 8, 2023

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR. CVPR 2022 [Project page | Video] Getting sta
 51 Nov 29, 2022
51 Nov 29, 2022

Official Pytorch implementation of "Learning to Estimate Robust 3D Human Mesh from In-the-Wild Crowded Scenes", CVPR 2022
Learning to Estimate Robust 3D Human Mesh from In-the-Wild Crowded Scenes / 3DCrowdNet News 💪 3DCrowdNet achieves the state-of-the-art accuracy on 3D
 113 Dec 21, 2022
113 Dec 21, 2022

Implementation of "Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis"
Generalizable Neural Performer: Learning Robust Radiance Fields for Human Novel View Synthesis Abstract: This work targets at using a general deep lea
 163 Dec 14, 2022
163 Dec 14, 2022

A Human-in-the-Loop workflow for creating HD images from text
A Human-in-the-Loop? workflow for creating HD images from text DALL·E Flow is an interactive workflow for generating high-definition images from text
 2.5k Jan 2, 2023
2.5k Jan 2, 2023
This is an official implementation for "DeciWatch: A Simple Baseline for 10x Efficient 2D and 3D Pose Estimation"
DeciWatch: A Simple Baseline for 10× Efficient 2D and 3D Pose Estimation This repo is the official implementation of "DeciWatch: A Simple Baseline for
 117 Dec 24, 2022
117 Dec 24, 2022
A command line interface tool converting starknet warp transpiled outputs into readable cairo contracts.
warp-to-cairo warp-to-cairo is a simple tool converting starknet warp outputs (NethermindEth/warp) outputs into readable cairo contracts. The warp out
 5 Jun 10, 2022
5 Jun 10, 2022
Wats2PDF - Convert whatsapp exported chat(without media) into a readable pdf format
Wats2PDF convert whatsApp exported chat into a readable pdf format. convert with
 5 Apr 26, 2022
5 Apr 26, 2022

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022

TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular potentials
TorchMD-net TorchMD-Net provides state-of-the-art graph neural networks and equivariant transformer neural networks potentials for learning molecular
 104 Jan 3, 2023
104 Jan 3, 2023
Transfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations
Transfer-Learning-in-Reinforcement-Learning Transfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations Final Report Tra
 4 Oct 17, 2022
4 Oct 17, 2022

Clean and readable code for Decision Transformer: Reinforcement Learning via Sequence Modeling
Minimal implementation of Decision Transformer: Reinforcement Learning via Sequence Modeling in PyTorch for mujoco control tasks in OpenAI gym
 104 Jan 6, 2023
104 Jan 6, 2023
A Broad Study on the Transferability of Visual Representations with Contrastive Learning
A Broad Study on the Transferability of Visual Representations with Contrastive Learning This repository contains code for the paper: A Broad Study on
 29 Nov 9, 2022
29 Nov 9, 2022

Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations
TopClus The source code used for Topic Discovery via Latent Space Clustering of Pretrained Language Model Representations, published in WWW 2022. Requ
 63 Dec 18, 2022
63 Dec 18, 2022

BASH - Biomechanical Animated Skinned Human
We developed a method animating a statistical 3D human model for biomechanical analysis to increase accessibility for non-experts, like patients, athletes, or designers.
 66 Nov 19, 2022
66 Nov 19, 2022
Building Ellee — A GPT-3 and Computer Vision Powered Talking Robotic Teddy Bear With Human Level Conversation Intelligence
Using an object detection and facial recognition system built on MobileNetSSDV2 and Dlib and running on an NVIDIA Jetson Nano, a GPT-3 model, Google Speech Recognition, Amazon Polly and servo motors, I built Ellee - a robotic teddy bear who can move her head and converse naturally.
 24 Oct 26, 2022
24 Oct 26, 2022

Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
Official code release for 3DV 2021 paper Human Performance Capture from Monocular Video in the Wild.
 58 Dec 24, 2022
58 Dec 24, 2022
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models Benchmark and Efficient Evaluation This reposi
 1 Aug 21, 2022
1 Aug 21, 2022

Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics
[AAAI2022] Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics Overall pipeline of OCN. Paper Link: [arXiv] [AAAI
 13 Nov 21, 2022
13 Nov 21, 2022

Unofficial Tensorflow 2 implementation of the paper Implicit Neural Representations with Periodic Activation Functions
Siren: Implicit Neural Representations with Periodic Activation Functions The unofficial Tensorflow 2 implementation of the paper Implicit Neural Repr
 2 Jun 27, 2022
2 Jun 27, 2022

Implementation of the method described in the Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations Implementation of the method described in the Speech Resynthesis from Di
 4 Mar 11, 2022
4 Mar 11, 2022
Human segmentation models, training/inference code, and trained weights, implemented in PyTorch
Human-Segmentation-PyTorch Human segmentation models, training/inference code, and trained weights, implemented in PyTorch. Supported networks UNet: b
 474 Dec 19, 2022
474 Dec 19, 2022
The Social-Engineer Toolkit (SET) is specifically designed to perform advanced attacks against the human element.
The Social-Engineer Toolkit (SET) The Social-Engineer Toolkit (SET) is specifically designed to perform advanced attacks against the human element. SE
 6 Nov 28, 2022
6 Nov 28, 2022
Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
NANSY: Unofficial Pytorch Implementation of Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations Notice Papers' D
 104 Dec 23, 2022
104 Dec 23, 2022

FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction
FaceExtraction FaceOcc: A Diverse, High-quality Face Occlusion Dataset for Human Face Extraction Occlusions often occur in face images in the wild, tr
 16 Dec 14, 2022
16 Dec 14, 2022

Answer a series of contextually-dependent questions like they may occur in natural human-to-human conversations.
SCAI-QReCC-21 [leaderboards] [registration] [forum] [contact] [SCAI] Answer a series of contextually-dependent questions like they may occur in natura
 19 Sep 28, 2022
19 Sep 28, 2022

AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
AirPose AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation Check the teaser video This repository contains the code of A
 41 Dec 5, 2022
41 Dec 5, 2022

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023

This is a Deep Leaning API for classifying emotions from human face and human audios.
Emotion AI This is a Deep Leaning API for classifying emotions from human face and human audios. Starting the server To start the server first you nee
 5 Oct 2, 2022
5 Oct 2, 2022
Bot by image recognition simulating (random) human clicks
bbbot22 bot por reconhecimento de imagem simulando cliques humanos (aleatórios) inb4: sim, esse é basicamente o mesmo bot de 2021 porque a Globo não t
 2 Apr 5, 2022
2 Apr 5, 2022

Human Detection - Pedestrian Detection using OpenCV Python
Pedestrian Detection using OpenCV Python Follow us on Instagram for Machine Lear
 1 Jan 23, 2022
1 Jan 23, 2022

Code for paper: Towards Tokenized Human Dynamics Representation
Video Tokneization Codebase for video tokenization, based on our paper Towards Tokenized Human Dynamics Representation. Prerequisites (tested under Py
 20 May 31, 2022
20 May 31, 2022

Official repository for the ICCV 2021 paper: UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model.
UltraPose: Synthesizing Dense Pose with 1 Billion Points by Human-body Decoupling 3D Model Official repository for the ICCV 2021 paper: UltraPose: Syn
 92 Dec 21, 2022
92 Dec 21, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022

Pose Transformers: Human Motion Prediction with Non-Autoregressive Transformers
Pose Transformers: Human Motion Prediction with Non-Autoregressive Transformers This is the repo used for human motion prediction with non-autoregress
 26 Dec 14, 2022
26 Dec 14, 2022

Unifying Global-Local Representations in Salient Object Detection with Transformer
GLSTR (Global-Local Saliency Transformer) This is the official implementation of paper "Unifying Global-Local Representations in Salient Object Detect
 11 Aug 24, 2022
11 Aug 24, 2022
Human pose estimation from video plays a critical role in various applications such as quantifying physical exercises, sign language recognition, and full-body gesture control.
Pose Detection Project Description: Human pose estimation from video plays a critical role in various applications such as quantifying physical exerci
 2 Jan 17, 2022
2 Jan 17, 2022
Accelerated SMPL operation, commonly used in generate 3D human mesh, STAR included.
SMPL2 An enchanced and accelerated SMPL operation which commonly used in 3D human mesh generation. It takes a poses, shapes, cam_trans as inputs, outp
 20 Oct 17, 2022
20 Oct 17, 2022

As a part of the HAKE project, includes the reproduced SOTA models and the corresponding HAKE-enhanced versions (CVPR2020).
HAKE-Action HAKE-Action (TensorFlow) is a project to open the SOTA action understanding studies based on our Human Activity Knowledge Engine. It inclu
 94 Nov 18, 2022
94 Nov 18, 2022
This repo is about implementing different approaches of pose estimation and also is a sub-task of the smart hospital bed project :smile:
Pose-Estimation This repo is a sub-task of the smart hospital bed project which is about implementing the task of pose estimation 😄 Many thanks to th
 11 Oct 17, 2022
11 Oct 17, 2022
Reproducing-BowNet: Learning Representations by Predicting Bags of Visual Words
Reproducing-BowNet Our reproducibility effort based on the 2020 ML Reproducibility Challenge. We are reproducing the results of this CVPR 2020 paper:
 6 Mar 16, 2022
6 Mar 16, 2022

Head2Toe: Utilizing Intermediate Representations for Better OOD Generalization
Head2Toe: Utilizing Intermediate Representations for Better OOD Generalization Code for reproducing our results in the Head2Toe paper. Paper: arxiv.or
 62 Dec 12, 2022
62 Dec 12, 2022

This is the code for the paper "Motion-Focused Contrastive Learning of Video Representations" (ICCV'21).
Motion-Focused Contrastive Learning of Video Representations Introduction This is the code for the paper "Motion-Focused Contrastive Learning of Video
 11 Sep 23, 2022
11 Sep 23, 2022
Dictionary Learning with Uniform Sparse Representations for Anomaly Detection
Dictionary Learning with Uniform Sparse Representations for Anomaly Detection Implementation of the Uniform DL Representation for AD algorithm describ
 1 Nov 23, 2022
1 Nov 23, 2022

UDP++ (ECCVW 2020 Oral), (Winner of COCO 2020 Keypoint Challenge).
UDP-Pose This is the pytorch implementation for UDP++, which won the Fisrt place in COCO Keypoint Challenge at ECCV 2020 Workshop. Top-Down Results on
 20 Jul 29, 2022
20 Jul 29, 2022
Deep Learning for Human Part Discovery in Images - Chainer implementation
Deep Learning for Human Part Discovery in Images - Chainer implementation NOTE: This is not official implementation. Original paper is Deep Learning f
 63 Sep 25, 2022
63 Sep 25, 2022
Repo 4 basic seminar §How to make human machine readable"
WORK IN PROGRESS... Notebooks from the Seminar: Human Machine Readable WS21/22 Introduction into programming Georg Trogemann, Christian Heck, Mattis
 3 May 29, 2022
3 May 29, 2022
The official TensorFlow implementation of the paper Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition
Action Transformer A Self-Attention Model for Short-Time Human Action Recognition This repository contains the official TensorFlow implementation of t
 20 Jan 3, 2023
20 Jan 3, 2023
Efficiently Disentangle Causal Representations
Efficiently Disentangle Causal Representations Install dependency pip install -r requirements.txt Main experiments Causality direction prediction cd
 4 Apr 1, 2022
4 Apr 1, 2022

A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets
HOW TO USE THIS PROJECT A Review of Deep Learning Techniques for Markerless Human Motion on Synthetic Datasets Based on DeepLabCut toolbox, we run wit
 1 Jan 10, 2022
1 Jan 10, 2022
Script that creates graphical representations of Julia an Mandelbrot sets.
Julia and Mandelbrot Picture Maker This simple functions create simple plots of the Julia and Mandelbrot sets. The Julia set require the important par
 1 Jan 10, 2022
1 Jan 10, 2022
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles (TASLP 2022)
 3 Apr 14, 2022
3 Apr 14, 2022
Official Implementation for Fast Training of Neural Lumigraph Representations using Meta Learning.
Fast Training of Neural Lumigraph Representations using Meta Learning Project Page | Paper | Data Alexander W. Bergman, Petr Kellnhofer, Gordon Wetzst
 39 Oct 8, 2022
39 Oct 8, 2022

Image based Human Fall Detection
Here I integrated the YOLOv5 object detection algorithm with my own created dataset which consists of human activity images to achieve low cost, high accuracy, and real-time computing requirements
 12 Dec 11, 2022
12 Dec 11, 2022

This repository is for our paper Exploiting Scene Graphs for Human-Object Interaction Detection accepted by ICCV 2021.
SG2HOI This repository is for our paper Exploiting Scene Graphs for Human-Object Interaction Detection accepted by ICCV 2021. Installation Pytorch 1.7
 10 Dec 20, 2022
10 Dec 20, 2022

Official code for the ICCV 2021 paper "DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders"
DECA Official code for the ICCV 2021 paper "DECA: Deep viewpoint-Equivariant human pose estimation using Capsule Autoencoders". All the code is writte
 23 Dec 1, 2022
23 Dec 1, 2022

Official implementation for the paper: Generating Smooth Pose Sequences for Diverse Human Motion Prediction
Generating Smooth Pose Sequences for Diverse Human Motion Prediction This is official implementation for the paper Generating Smooth Pose Sequences fo
 28 Dec 10, 2022
28 Dec 10, 2022
📦 A Human's Ultimate Guide to setup.py.
📦 setup.py (for humans) This repo exists to provide an example setup.py file, that can be used to bootstrap your next Python project. It includes som
 5k Jan 4, 2023
5k Jan 4, 2023
Self-supervised learning optimally robust representations for domain generalization.
OptDom: Learning Optimal Representations for Domain Generalization This repository contains the official implementation for Optimal Representations fo
 18 Aug 25, 2022
18 Aug 25, 2022

VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations
VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations 3D-aware Image Synthesis via Learning Structural and Textura
 116 Dec 26, 2022
116 Dec 26, 2022

Official tensorflow implementation for CVPR2020 paper “Learning to Cartoonize Using White-box Cartoon Representations”
Tensorflow implementation for CVPR2020 paper “Learning to Cartoonize Using White-box Cartoon Representations”.
 3.7k Dec 31, 2022
3.7k Dec 31, 2022

A unified framework to jointly model images, text, and human attention traces.
connect-caption-and-trace This repository contains the reference code for our paper Connecting What to Say With Where to Look by Modeling Human Attent
73 Oct 24, 2022
Automatic Number Plate Recognition (ANPR) is a highly accurate system capable of reading vehicle number plates without human intervention
ANPR ANPR is therefore the underlying technology used to find a vehicle license/number plate and it, in turn, supplies this information to a next stag
 1 Jan 9, 2022
1 Jan 9, 2022

A web-based analysis toolkit for the System Usability Scale providing calculation, plotting, interpretation and contextualization utility
System Usability Scale Analysis Toolkit The System Usability Scale (SUS) Analysis Toolkit is a web-based python application that provides a compilatio
 3 Oct 27, 2022
3 Oct 27, 2022
Skype export archive to text converter for python
Skype export archive to text converter This software utility extracts chat logs
 2 Jun 30, 2022
2 Jun 30, 2022

Keras Realtime Multi-Person Pose Estimation - Keras version of Realtime Multi-Person Pose Estimation project
This repository has become incompatible with the latest and recommended version of Tensorflow 2.0 Instead of refactoring this code painfully, I create
 769 Dec 8, 2022
769 Dec 8, 2022
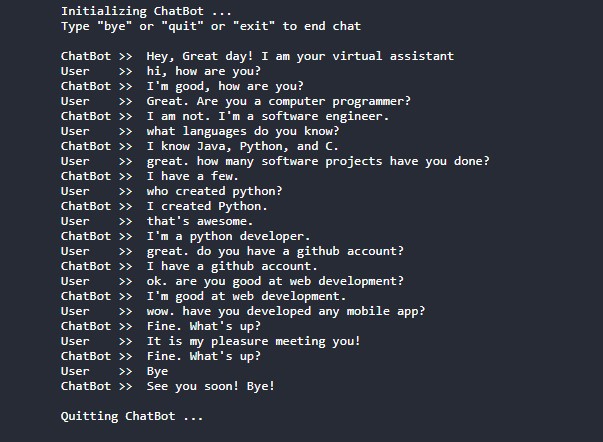
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022

HAR-stacked-residual-bidir-LSTMs - Deep stacked residual bidirectional LSTMs for HAR
HAR-stacked-residual-bidir-LSTM The project is based on this repository which is presented as a tutorial. It consists of Human Activity Recognition (H
 287 Dec 27, 2022
287 Dec 27, 2022

Face_mosaic - Mosaic blur processing is applied to multiple faces appearing in the video
動機 face_recognitionを使用して得られる顔座標は長方形であり、この座標をそのまま用いてぼかし処理を行った場合得られる画像は醜い。 それに対してモ
 6 Feb 3, 2022
6 Feb 3, 2022
Joint Unsupervised Learning (JULE) of Deep Representations and Image Clusters.
Joint Unsupervised Learning (JULE) of Deep Representations and Image Clusters. Overview This project is a Torch implementation for our CVPR 2016 paper
 278 Dec 25, 2022
278 Dec 25, 2022
Place holder for HOPE: a human-centric and task-oriented MT evaluation framework using professional post-editing
HOPE: A Task-Oriented and Human-Centric Evaluation Framework Using Professional Post-Editing Towards More Effective MT Evaluation Place holder for dat
 1 Apr 25, 2022
1 Apr 25, 2022

Source code of the "Graph-Bert: Only Attention is Needed for Learning Graph Representations" paper
Graph-Bert Source code of "Graph-Bert: Only Attention is Needed for Learning Graph Representations". Please check the script.py as the entry point. We
 14 Mar 25, 2022
14 Mar 25, 2022
Self-Guided Contrastive Learning for BERT Sentence Representations
Self-Guided Contrastive Learning for BERT Sentence Representations This repository is dedicated for releasing the implementation of the models utilize
 16 Dec 4, 2022
16 Dec 4, 2022

Unsupervised Learning of Video Representations using LSTMs
Unsupervised Learning of Video Representations using LSTMs Code for paper Unsupervised Learning of Video Representations using LSTMs by Nitish Srivast
 341 Dec 20, 2022
341 Dec 20, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
GUI for visualization and interactive editing of SMPL-family body models ie. SMPL, SMPL-X, MANO, FLAME.
Body Model Visualizer Introduction This is a simple Open3D-based GUI for SMPL-family body models. This GUI lets you play with the shape, expression, a
 25 Dec 28, 2021
25 Dec 28, 2021
This is a Python 3.10 port of mock, a library for manipulating human-readable message strings.
This is a Python 3.10 port of mock, a library for manipulating human-readable message strings.
 1 Dec 31, 2021
1 Dec 31, 2021
GUI for visualization and interactive editing of SMPL-family body models ie. SMPL, SMPL-X, MANO, FLAME.
Body Model Visualizer Introduction This is a simple Open3D-based GUI for SMPL-family body models. This GUI lets you play with the shape, expression, a
207 Jan 1, 2023
A human-readable PyTorch implementation of "Self-attention Does Not Need O(n^2) Memory"
memory_efficient_attention.pytorch A human-readable PyTorch implementation of "Self-attention Does Not Need O(n^2) Memory" (Rabe&Staats'21). def effic
 7 Dec 26, 2022
7 Dec 26, 2022
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022
Readable, simple and fast asynchronous non-blocking network apps
Fast and readable async non-blocking network apps Netius is a Python network library that can be used for the rapid creation of asynchronous non-block
 120 Nov 20, 2022
120 Nov 20, 2022
[PNAS2021] The neural architecture of language: Integrative modeling converges on predictive processing
The neural architecture of language: Integrative modeling converges on predictive processing Code accompanying the paper The neural architecture of la
 36 Dec 1, 2022
36 Dec 1, 2022

Learning Domain Invariant Representations in Goal-conditioned Block MDPs
Learning Domain Invariant Representations in Goal-conditioned Block MDPs Beining Han, Chongyi Zheng, Harris Chan, Keiran Paster, Michael R. Zhang, Jim
 3 Apr 12, 2022
3 Apr 12, 2022
VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations
VolumeGAN - 3D-aware Image Synthesis via Learning Structural and Textural Representations 3D-aware Image Synthesis via Learning Structural and Textura
116 Dec 26, 2022