93 Repositories
Python multimodal-rl Libraries

Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch
CoCa - Pytorch Implementation of CoCa, Contrastive Captioners are Image-Text Foundation Models, in Pytorch. They were able to elegantly fit in contras
 565 Dec 30, 2022
565 Dec 30, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

MAGMA - a GPT-style multimodal model that can understand any combination of images and language
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning Authors repo (alphabetical) Constantin (CoEich), Mayukh (Mayukh
 331 Jan 3, 2023
331 Jan 3, 2023
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
TorchMultimodal (Alpha Release) Introduction TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
 663 Jan 6, 2023
663 Jan 6, 2023
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022
NAACL 2022: MCSE: Multimodal Contrastive Learning of Sentence Embeddings
MCSE: Multimodal Contrastive Learning of Sentence Embeddings This repository contains code and pre-trained models for our NAACL-2022 paper MCSE: Multi
 39 Nov 15, 2022
39 Nov 15, 2022

Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion"
MKGFormer Code for the SIGIR 2022 paper "Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion" Model Architecture Illu
 68 Dec 28, 2022
68 Dec 28, 2022
![[LREC] MMChat: Multi-Modal Chat Dataset on Social Media](https://github.com/silverriver/MMChat/raw/main/bin/sample.jpg)
[LREC] MMChat: Multi-Modal Chat Dataset on Social Media
MMChat This repo contains the code and data for the LREC2022 paper MMChat: Multi-Modal Chat Dataset on Social Media. Dataset MMChat is a large-scale d
 47 Jan 3, 2023
47 Jan 3, 2023
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset.
A repository for the updated version of CoinRun used to collect MUGEN, a multimodal video-audio-text dataset. This repo contains scripts to train RL agents to navigate the closed world and collect video data.
 11 Oct 22, 2022
11 Oct 22, 2022
Code for Findings of ACL 2022 Paper "Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors"
SWRM Code for Findings of ACL 2022 Paper "Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors" Clone Clone th
 14 Jan 3, 2023
14 Jan 3, 2023

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022

MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition Paper: MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition accepted fo
 64 Dec 18, 2022
64 Dec 18, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022
Code for Multimodal Neural SLAM for Interactive Instruction Following
Code for Multimodal Neural SLAM for Interactive Instruction Following Code structure The code is adapted from E.T. and most training as well as data p
 7 Dec 7, 2022
7 Dec 7, 2022

Official code of Team Yao at Multi-Modal-Fact-Verification-2022
Official code of Team Yao at Multi-Modal-Fact-Verification-2022 A Multi-Modal Fact Verification dataset released as part of the De-Factify workshop in
 11 Nov 15, 2022
11 Nov 15, 2022
Evidential Softmax for Sparse Multimodal Distributions in Deep Generative Models
Evidential Softmax for Sparse Multimodal Distributions in Deep Generative Models Abstract Many applications of generative models rely on the marginali
 9 Jun 6, 2022
9 Jun 6, 2022

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022
Implementation of "With a Little Help from my Temporal Context: Multimodal Egocentric Action Recognition, BMVC, 2021" in PyTorch
Multimodal Temporal Context Network (MTCN) This repository implements the model proposed in the paper: Evangelos Kazakos, Jaesung Huh, Arsha Nagrani,
 13 Nov 24, 2022
13 Nov 24, 2022
![[CVPR 2021]](https://github.com/decisionforce/mmTransformer/raw/main/figs/model.png)
[CVPR 2021] "Multimodal Motion Prediction with Stacked Transformers": official code implementation and project page.
mmTransformer Introduction This repo is official implementation for mmTransformer in pytorch. Currently, the core code of mmTransformer is implemented
 232 Dec 31, 2022
232 Dec 31, 2022

MINOS: Multimodal Indoor Simulator
MINOS Simulator MINOS is a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environ
 194 Dec 27, 2022
194 Dec 27, 2022
Image-retrieval-baseline - MUGE Multimodal Retrieval Baseline
MUGE Multimodal Retrieval Baseline This repo is implemented based on the open_cl
 47 Dec 16, 2022
47 Dec 16, 2022
NeuralTalk is a Python+numpy project for learning Multimodal Recurrent Neural Networks that describe images with sentences.
#NeuralTalk Warning: Deprecated. Hi there, this code is now quite old and inefficient, and now deprecated. I am leaving it on Github for educational p
 5.3k Jan 7, 2023
5.3k Jan 7, 2023

LAVT: Language-Aware Vision Transformer for Referring Image Segmentation
LAVT: Language-Aware Vision Transformer for Referring Image Segmentation Where we are ? 12.27 目前和原论文仍有1%左右得差距,但已经力压很多SOTA了 ckpt__448_epoch_25.pth mIoU
 60 Dec 11, 2022
60 Dec 11, 2022

PyTorch code for training MM-DistillNet for multimodal knowledge distillation
There is More than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking with Sound by Distilling Multimodal Knowledge MM-DistillNet is a
 51 Dec 20, 2022
51 Dec 20, 2022

Code for "Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals," CoRL 2021.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals This repository contains code for "Multimodal trajectory prediction conditioned
 113 Dec 28, 2022
113 Dec 28, 2022
Tensorflow Implementation of ECCV'18 paper: Multimodal Human Motion Synthesis
MT-VAE for Multimodal Human Motion Synthesis This is the code for ECCV 2018 paper MT-VAE: Learning Motion Transformations to Generate Multimodal Human
 36 Oct 2, 2022
36 Oct 2, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Cleaned up code for DSTC 10: SIMMC 2.0 track: subtask 2: multimodal coreference resolution
UNITER-Based Situated Coreference Resolution with Rich Multimodal Input: arXiv MMCoref_cleaned Code for the MMCoref task of the SIMMC 2.0 dataset. Pre
 2 Dec 5, 2022
2 Dec 5, 2022
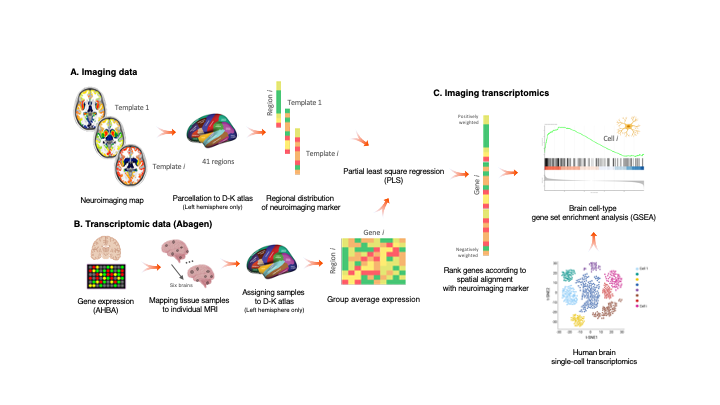
A package, and script, to perform imaging transcriptomics on a neuroimaging scan.
Imaging Transcriptomics Imaging transcriptomics is a methodology that allows to identify patterns of correlation between gene expression and some prop
 10 Dec 27, 2022
10 Dec 27, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
 5.4k Jan 3, 2023
5.4k Jan 3, 2023
This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text"
Iconary This is the code for our paper "Iconary: A Pictionary-Based Game for Testing Multimodal Communication with Drawings and Text". It includes the
 6 May 24, 2022
6 May 24, 2022
End-to-End Referring Video Object Segmentation with Multimodal Transformers
End-to-End Referring Video Object Segmentation with Multimodal Transformers This repo contains the official implementation of the paper: End-to-End Re
 608 Dec 30, 2022
608 Dec 30, 2022
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
 206 Dec 28, 2022
206 Dec 28, 2022
MMDA - multimodal document analysis
MMDA - multimodal document analysis
75 Jan 4, 2023

Multimodal commodity image retrieval 多模态商品图像检索
Multimodal commodity image retrieval 多模态商品图像检索 Not finished yet... introduce explain:The specific description of the project and the product image dat
 8 Nov 25, 2022
8 Nov 25, 2022
This repository contains the official implementation code of the paper Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis
This repository contains the official implementation code of the paper Transformer-based Feature Reconstruction Network for Robust Multimodal Sentiment Analysis, accepted at ACMMM 2021.
 10 Sep 30, 2022
10 Sep 30, 2022

Creating multimodal multitask models
Fusion Brain Challenge The English version of the document can be found here. Обновления 01.11 Мы выкладываем пример данных, аналогичных private test
 43 Nov 28, 2022
43 Nov 28, 2022
Clinica is a software platform for clinical research studies involving patients with neurological and psychiatric diseases and the acquisition of multimodal data
Clinica Software platform for clinical neuroimaging studies Homepage | Documentation | Paper | Forum | See also: AD-ML, AD-DL ClinicaDL About The Proj
 165 Dec 29, 2022
165 Dec 29, 2022

Toward Multimodal Image-to-Image Translation
BicycleGAN Project Page | Paper | Video Pytorch implementation for multimodal image-to-image translation. For example, given the same night image, our
 1.4k Dec 22, 2022
1.4k Dec 22, 2022

the official code for ICRA 2021 Paper: "Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation"
G2S This is the official code for ICRA 2021 Paper: Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation by Hemang
 4 Jul 27, 2022
4 Jul 27, 2022

History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
 46 Nov 23, 2022
46 Nov 23, 2022

Turning pixels into virtual points for multimodal 3D object detection.
Multimodal Virtual Point 3D Detection Turning pixels into virtual points for multimodal 3D object detection. Multimodal Virtual Point 3D Detection, Ti
 204 Jan 8, 2023
204 Jan 8, 2023

MediaPipe is a an open-source framework from Google for building multimodal
MediaPipe is a an open-source framework from Google for building multimodal (eg. video, audio, any time series data), cross platform (i.e Android, iOS, web, edge devices) applied ML pipelines. It is performance optimized with end-to-end on device inference in mind.
 3 Sep 30, 2022
3 Sep 30, 2022
History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
46 Nov 23, 2022
[ICCV 2021 Oral] Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Just Ask: Learning to Answer Questions from Millions of Narrated Videos Webpage • Demo • Paper This repository provides the code for our paper, includ
87 Jan 5, 2023
METER: Multimodal End-to-end TransformER
METER Code and pre-trained models will be publicized soon. Citation @article{dou2021meter, title={An Empirical Study of Training End-to-End Vision-a
 257 Jan 6, 2023
257 Jan 6, 2023
Repository for Multimodal AutoML Benchmark
Benchmarking Multimodal AutoML for Tabular Data with Text Fields Repository for the NeurIPS 2021 Dataset Track Submission "Benchmarking Multimodal Aut
 44 Nov 24, 2022
44 Nov 24, 2022

A CROSS-MODAL FUSION NETWORK BASED ON SELF-ATTENTION AND RESIDUAL STRUCTURE FOR MULTIMODAL EMOTION RECOGNITION
CFN-SR A CROSS-MODAL FUSION NETWORK BASED ON SELF-ATTENTION AND RESIDUAL STRUCTURE FOR MULTIMODAL EMOTION RECOGNITION The audio-video based multimodal
 15 Sep 26, 2022
15 Sep 26, 2022

Code for ICMI2020 and ICMI2021 papers: "Studying Person-Specific Pointing and Gaze Behavior for Multimodal Referencing of Outside Objects from a Moving Vehicle" and "ML-PersRef: A Machine Learning-based Personalized Multimodal Fusion Approach for Referencing Outside Objects From a Moving Vehicle"
ML-PersRef This repository has python code (in jupyter notebooks) for both of the following papers: ML-PersRef: A Machine Learning-based Personalized
 3 Sep 4, 2022
3 Sep 4, 2022
scikit-multimodallearn is a Python package implementing algorithms multimodal data.
scikit-multimodallearn is a Python package implementing algorithms multimodal data. It is compatible with scikit-learn, a popul
 12 Jun 29, 2022
12 Jun 29, 2022
Multimodal Temporal Context Network (MTCN)
Multimodal Temporal Context Network (MTCN) This repository implements the model proposed in the paper: Evangelos Kazakos, Jaesung Huh, Arsha Nagrani,
13 Nov 24, 2022
How to Leverage Multimodal EHR Data for Better Medical Predictions?
How to Leverage Multimodal EHR Data for Better Medical Predictions? This repository contains the code of the paper: How to Leverage Multimodal EHR Dat
 13 Dec 13, 2022
13 Dec 13, 2022
This repository contains code and data for "On the Multimodal Person Verification Using Audio-Visual-Thermal Data"
trimodal_person_verification This repository contains the code, and preprocessed dataset featured in "A Study of Multimodal Person Verification Using
 7 Aug 31, 2022
7 Aug 31, 2022

A Context-aware Visual Attention-based training pipeline for Object Detection from a Webpage screenshot!
CoVA: Context-aware Visual Attention for Webpage Information Extraction Abstract Webpage information extraction (WIE) is an important step to create k
 41 Jan 1, 2023
41 Jan 1, 2023
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
5.1k Jan 4, 2023

Implements the training, testing and editing tools for "Pluralistic Image Completion"
Pluralistic Image Completion ArXiv | Project Page | Online Demo | Video(demo) This repository implements the training, testing and editing tools for "
 615 Dec 8, 2022
615 Dec 8, 2022
Multimodal Descriptions of Social Concepts: Automatic Modeling and Detection of (Highly Abstract) Social Concepts evoked by Art Images
MUSCO - Multimodal Descriptions of Social Concepts Automatic Modeling of (Highly Abstract) Social Concepts evoked by Art Images This project aims to i
 0 Aug 22, 2021
0 Aug 22, 2021

Original Pytorch Implementation of FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation
FLAME Original Pytorch Implementation of FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation, accepted at the 17th IEEE Internation Co
 19 Dec 17, 2022
19 Dec 17, 2022
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition [ArXiv] [Project Page] This repository is the official implementation of AdaMML:
 43 Dec 26, 2022
43 Dec 26, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
740 Dec 24, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

This repository contains the official implementation code of the paper Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis, accepted at EMNLP 2021.
MultiModal-InfoMax This repository contains the official implementation code of the paper Improving Multimodal Fusion with Hierarchical Mutual Informa
 89 Dec 26, 2022
89 Dec 26, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023
This repository contains various models targetting multimodal representation learning, multimodal fusion for downstream tasks such as multimodal sentiment analysis.
Multimodal Deep Learning 🎆 🎆 🎆 Announcing the multimodal deep learning repository that contains implementation of various deep learning-based model
398 Dec 30, 2022

Generate vibrant and detailed images using only text.
CLIP Guided Diffusion From RiversHaveWings. Generate vibrant and detailed images using only text. See captions and more generations in the Gallery See
 401 Dec 28, 2022
401 Dec 28, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022

FairyTailor: Multimodal Generative Framework for Storytelling
FairyTailor: Multimodal Generative Framework for Storytelling
 172 Dec 30, 2022
172 Dec 30, 2022

multimodal transformer
This repo holds the code to perform experiments with the multimodal autoregressive probabilistic model Transflower. Overview of the repo It is structu
 68 Dec 13, 2022
68 Dec 13, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023

Code for SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations
The Second Situated Interactive MultiModal Conversations (SIMMC 2.0) Challenge 2021 Welcome to the Second Situated Interactive Multimodal Conversation
81 Nov 22, 2022
Preprocessed Datasets for our Multimodal NER paper
Unified Multimodal Transformer (UMT) for Multimodal Named Entity Recognition (MNER) Two MNER Datasets and Codes for our ACL'2020 paper: Improving Mult
 76 Dec 21, 2022
76 Dec 21, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022
MERLOT: Multimodal Neural Script Knowledge Models
merlot MERLOT: Multimodal Neural Script Knowledge Models MERLOT is a model for learning what we are calling "neural script knowledge" -- representatio
 190 Dec 22, 2022
190 Dec 22, 2022

Framework for joint representation learning, evaluation through multimodal registration and comparison with image translation based approaches
CoMIR: Contrastive Multimodal Image Representation for Registration Framework 🖼 Registration of images in different modalities with Deep Learning 🤖
 55 Dec 9, 2022
55 Dec 9, 2022

Source code for "MusCaps: Generating Captions for Music Audio" (IJCNN 2021)
MusCaps: Generating Captions for Music Audio Ilaria Manco1 2, Emmanouil Benetos1, Elio Quinton2, Gyorgy Fazekas1 1 Queen Mary University of London, 2
 57 Dec 7, 2022
57 Dec 7, 2022
A modular framework for vision & language multimodal research from Facebook AI Research (FAIR)
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains reference implementations of state-of-t
5.1k Dec 26, 2022

Code and datasets for the paper "Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction" (RA-L, 2021)
Combining Events and Frames using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction This is the code for the paper Combining E
 69 Dec 26, 2022
69 Dec 26, 2022

An official implementation for "CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval"
The implementation of paper CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval. CLIP4Clip is a video-text retrieval model based
 456 Jan 6, 2023
456 Jan 6, 2023
PyKale is a PyTorch library for multimodal learning and transfer learning as well as deep learning and dimensionality reduction on graphs, images, texts, and videos
PyKale is a PyTorch library for multimodal learning and transfer learning as well as deep learning and dimensionality reduction on graphs, images, texts, and videos. By adopting a unified pipeline-based API design, PyKale enforces standardization and minimalism, via reusing existing resources, reducing repetitions and redundancy, and recycling learning models across areas.
 370 Dec 27, 2022
370 Dec 27, 2022
Official implementation of "Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision" ECCV2020
XDVioDet Official implementation of "Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision" ECCV2020. The proj
 64 Dec 12, 2022
64 Dec 12, 2022

Rethinking the U-Net architecture for multimodal biomedical image segmentation
MultiResUNet Rethinking the U-Net architecture for multimodal biomedical image segmentation This repository contains the original implementation of "M
 308 Jan 5, 2023
308 Jan 5, 2023

Deep Multimodal Neural Architecture Search
MMNas: Deep Multimodal Neural Architecture Search This repository corresponds to the PyTorch implementation of the MMnas for visual question answering
 23 Dec 21, 2022
23 Dec 21, 2022

CVPR 2021: "Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE"
Diverse Structure Inpainting ArXiv | Papar | Supplementary Material | BibTex This repository is for the CVPR 2021 paper, "Generating Diverse Structure
 152 Nov 4, 2022
152 Nov 4, 2022

This repo provides the official code for TransBTS: Multimodal Brain Tumor Segmentation Using Transformer (https://arxiv.org/pdf/2103.04430.pdf).
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer This repo is the official implementation for TransBTS: Multimodal Brain Tumor Segmenta
 247 Dec 28, 2022
247 Dec 28, 2022
Solving reinforcement learning tasks which require language and vision
Multimodal Reinforcement Learning JAX implementations of the following multimodal reinforcement learning approaches. Dual-coding Episodic Memory from
 31 Feb 26, 2022
31 Feb 26, 2022
Open-AI's DALL-E for large scale training in mesh-tensorflow.
DALL-E in Mesh-Tensorflow [WIP] Open-AI's DALL-E in Mesh-Tensorflow. If this is similarly efficient to GPT-Neo, this repo should be able to train mode
 432 Dec 16, 2022
432 Dec 16, 2022

A Comparative Framework for Multimodal Recommender Systems
Cornac Cornac is a comparative framework for multimodal recommender systems. It focuses on making it convenient to work with models leveraging auxilia
 671 Jan 3, 2023
671 Jan 3, 2023