280 Repositories
Python ocr-papers Libraries
A curated list of the latest breakthroughs in AI by release date with a clear video explanation, link to a more in-depth article, and code.
A curated list of the latest breakthroughs in AI by release date with a clear video explanation, link to a more in-depth article, and code
 2.9k Jan 8, 2023
2.9k Jan 8, 2023

This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
 75 Oct 21, 2022
75 Oct 21, 2022

OCR Post Correction for Endangered Language Texts
📌 Coming soon: an update to the software including features from our paper on semi-supervised OCR post-correction, to be published in the Transaction
 96 Dec 31, 2022
96 Dec 31, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
285 Dec 8, 2022

Code for ICMI2020 and ICMI2021 papers: "Studying Person-Specific Pointing and Gaze Behavior for Multimodal Referencing of Outside Objects from a Moving Vehicle" and "ML-PersRef: A Machine Learning-based Personalized Multimodal Fusion Approach for Referencing Outside Objects From a Moving Vehicle"
ML-PersRef This repository has python code (in jupyter notebooks) for both of the following papers: ML-PersRef: A Machine Learning-based Personalized
 3 Sep 4, 2022
3 Sep 4, 2022
Classical OCR DCNN reproduction based on PaddlePaddle framework.
Paddle-SVHN Classical OCR DCNN reproduction based on PaddlePaddle framework. This project reproduces Multi-digit Number Recognition from Street View I
 1 Nov 12, 2021
1 Nov 12, 2021
a discord bot that pulls the latest or most relevant research papers from arxiv.org
AI arxiver a discord bot that pulls the latest or most relevant research papers from arxiv.org invite link : Arxiver bot link works in progress Usage
 14 Sep 3, 2022
14 Sep 3, 2022
This is a implementation of CRAFT OCR method
This is a implementation of CRAFT OCR method
 0 Nov 1, 2021
0 Nov 1, 2021
This is a GUI for scrapping PDFs with the help of optical character recognition making easier than ever to scrape PDFs.
pdf-scraper-with-ocr With this tool I am aiming to facilitate the work of those who need to scrape PDFs either by hand or using tools that doesn't imp
75 Oct 21, 2022
Dirty, ugly, and hopefully useful OCR of Facebook Papers docs released by Gizmodo
Quick and Dirty OCR of Facebook Papers Gizmodo has been working through the Facebook Papers and releasing the docs that they process and review. As lu
 2 Oct 28, 2021
2 Oct 28, 2021
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
A Vietnamese personal card OCR website built with Django.
Django VietCardOCR Installation Creation of virtual environments is done by executing the command venv: python -m venv venv That will create a new fol
 4 Sep 4, 2021
4 Sep 4, 2021
Convolutional Recurrent Neural Network (CRNN) for image-based sequence recognition.
Convolutional Recurrent Neural Network This software implements the Convolutional Recurrent Neural Network (CRNN), a combination of CNN, RNN and CTC l
 2k Dec 31, 2022
2k Dec 31, 2022

Key information extraction from invoice document with Graph Convolution Network
Key Information Extraction from Scanned Invoices Key information extraction from invoice document with Graph Convolution Network Related blog post fro
 39 Dec 16, 2022
39 Dec 16, 2022

Machine Leaning applied to denoise images to improve OCR Accuracy
Machine Learning to Denoise Images for Better OCR Accuracy This project is an adaptation of this tutorial and used only for learning purposes: https:/
 2 Nov 16, 2022
2 Nov 16, 2022
A bot that extract text from images using the Tesseract OCR.
Text from image (OCR) @ocr_text_bot A simple bot to extract text from images. Usage What do I need? A AWS key configured locally, see here. NodeJS. I
 4 Aug 6, 2021
4 Aug 6, 2021

Use Youdao OCR API to covert your clipboard image to text.
Alfred Clipboard OCR 注:本仓库基于 oott123/alfred-clipboard-ocr 的逻辑用 Python 重写,换用了有道 AI 的 API,准确率更高,有效防止百度导致隐私泄露等问题,并且有道 AI 初始提供的 50 元体验金对于其资费而言个人用户基本可以永久使用
 6 Sep 19, 2022
6 Sep 19, 2022
A Collection of Papers and Codes for ICCV2021 Low Level Vision and Image Generation
A Collection of Papers and Codes for ICCV2021 Low Level Vision and Image Generation
 196 Jan 5, 2023
196 Jan 5, 2023
SciBERT is a BERT model trained on scientific text.
SciBERT is a BERT model trained on scientific text.
 1.2k Dec 24, 2022
1.2k Dec 24, 2022
My implementation of transformers related papers for computer vision in pytorch
vision_transformers This is my personnal repo to implement new transofrmers based and other computer vision DL models I am currenlty working without a
 1 Nov 10, 2021
1 Nov 10, 2021
A repository for collating all the resources such as articles, blogs, papers, and books related to Bayesian Statistics.
A repository for collating all the resources such as articles, blogs, papers, and books related to Bayesian Statistics.
 80 Dec 12, 2022
80 Dec 12, 2022
Usando o Amazon Textract como OCR para Extração de Dados no DynamoDB
dio-live-textract2 Repositório de código para o live coding do dia 05/10/2021 sobre extração de dados estruturados e gravação em banco de dados a part
 0 Jan 19, 2022
0 Jan 19, 2022

A collection of papers about Transformer in the field of medical image analysis.
A collection of papers about Transformer in the field of medical image analysis.
 377 Jan 5, 2023
377 Jan 5, 2023

jfc is an utility to make reviewing ArXiv papers for your Journal Club easier.
jfc is an utility to make reviewing ArXiv papers for your Journal Club easier.
 3 Dec 20, 2021
3 Dec 20, 2021

Ground truth data for the Optical Character Recognition of Historical Classical Commentaries.
OCR Ground Truth for Historical Commentaries The dataset OCR ground truth for historical commentaries (GT4HistComment) was created from the public dom
 3 Sep 8, 2022
3 Sep 8, 2022
a micro OCR network with 0.07mb params.
MicroOCR a micro OCR network with 0.07mb params. Layer (type) Output Shape Param # Conv2d-1 [-1, 64, 8,
 29 Aug 6, 2022
29 Aug 6, 2022
Programa que viabiliza a OCR (Optical Character Reading - leitura óptica de caracteres) de um PDF.
Este programa tem o intuito de ser um modificador de arquivos PDF. Os arquivos PDFs podem ser 3: PDFs verdadeiros - em que podem ser selecionados o ti
 2 Oct 11, 2021
2 Oct 11, 2021
It is a image ocr tool using the Tesseract-OCR engine with the pytesseract package and has a GUI.
OCR-Tool It is a image ocr tool made in Python using the Tesseract-OCR engine with the pytesseract package and has a GUI. This is my second ever pytho
 4 Jul 11, 2022
4 Jul 11, 2022

METS/ALTO OCR enhancing tool by the National Library of Luxembourg (BnL)
Nautilus-OCR The National Library of Luxembourg (BnL) started its first initiative in digitizing newspapers, with layout recognition and OCR on articl
 36 Dec 5, 2022
36 Dec 5, 2022
🎓Automatically Update CV Papers Daily using Github Actions (Update at 12:00 UTC Every Day)
🎓Automatically Update CV Papers Daily using Github Actions (Update at 12:00 UTC Every Day)
 270 Jan 7, 2023
270 Jan 7, 2023

A simple but complete full-attention transformer with a set of promising experimental features from various papers
x-transformers A concise but fully-featured transformer, complete with a set of promising experimental features from various papers. Install $ pip ins
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
This repository contains an overview of important follow-up works based on the original Vision Transformer (ViT) by Google.
This repository contains an overview of important follow-up works based on the original Vision Transformer (ViT) by Google.
 75 Dec 2, 2022
75 Dec 2, 2022

Automatically download multiple papers by keywords in CVPR
Automatically download multiple papers by keywords in CVPR
 46 Jun 8, 2022
46 Jun 8, 2022
Must-read papers on improving efficiency for pre-trained language models.
Must-read papers on improving efficiency for pre-trained language models.
 89 Jan 3, 2023
89 Jan 3, 2023
Must-read Papers on Physics-Informed Neural Networks.
PINNpapers Contributed by IDRL lab. Introduction Physics-Informed Neural Network (PINN) has achieved great success in scientific computing since 2017.
 330 Jan 7, 2023
330 Jan 7, 2023
A Screen Translator/OCR Translator made by using Python and Tesseract, the user interface are made using Tkinter. All code written in python.
About An OCR translator tool. Made by me by utilizing Tesseract, compiled to .exe using pyinstaller. I made this program to learn more about python. I
 41 Dec 30, 2022
41 Dec 30, 2022

Web interface for browsing arXiv papers
Currently, arxivbox considers only major computer vision and machine learning conferences
 12 Sep 11, 2022
12 Sep 11, 2022
Automatically download multiple papers by keywords in CVPR
CVFPaperHelper Automatically download multiple papers by keywords in CVPR Install mkdir PapersToRead cd PaperToRead pip install requests tqdm git clon
46 Jun 8, 2022

Generate text line images for training deep learning OCR model (e.g. CRNN)
Generate text line images for training deep learning OCR model (e.g. CRNN)
 532 Jan 6, 2023
532 Jan 6, 2023
The papers published in top-tier AI conferences in recent years.
AI-conference-papers The papers published in top-tier AI conferences in recent years. Paper table AAAI ICLR CVPR ICML ICCV ECCV NIPS 2019 ✔️ ✔️ ✔️ ✔️
 6 Dec 9, 2022
6 Dec 9, 2022
一个多语言支持、易使用的 OCR 项目。An easy-to-use OCR project with multilingual support.
AgentOCR 简介 AgentOCR 是一个基于 PaddleOCR 和 ONNXRuntime 项目开发的一个使用简单、调用方便的 OCR 项目 本项目目前包含 Python Package 【AgentOCR】 和 OCR 标注软件 【AgentOCRLabeling】 使用指南 Pytho
 98 Nov 10, 2022
98 Nov 10, 2022
Experiments on Flood Segmentation on Sentinel-1 SAR Imagery with Cyclical Pseudo Labeling and Noisy Student Training
Flood Detection Challenge This repository contains code for our submission to the ETCI 2021 Competition on Flood Detection (Winning Solution #2). Acco
 108 Dec 28, 2022
108 Dec 28, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
 235 Dec 22, 2022
235 Dec 22, 2022

Official implementation of SynthTIGER (Synthetic Text Image GEneratoR) ICDAR 2021
🐯 SynthTIGER: Synthetic Text Image GEneratoR Official implementation of SynthTIGER | Paper | Datasets Moonbin Yim1, Yoonsik Kim1, Han-cheol Cho1, Sun
 256 Jan 5, 2023
256 Jan 5, 2023
Collect super-resolution related papers, data, repositories
Collect super-resolution related papers, data, repositories
 1.7k Jan 3, 2023
1.7k Jan 3, 2023

This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
This project is a sample demo of Arxiv search related to AI/ML Papers built using Streamlit, sentence-transformers and Faiss.
 49 Oct 30, 2022
49 Oct 30, 2022

🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
🍀 Pytorch implementation of various Attention Mechanisms, MLP, Re-parameter, Convolution, which is helpful to further understand papers.⭐⭐⭐
 7.7k Jan 5, 2023
7.7k Jan 5, 2023

A collection of research papers and software related to explainability in graph machine learning.
A collection of research papers and software related to explainability in graph machine learning.
 1.9k Dec 26, 2022
1.9k Dec 26, 2022

The Incredible PyTorch: a curated list of tutorials, papers, projects, communities and more relating to PyTorch.
This is a curated list of tutorials, projects, libraries, videos, papers, books and anything related to the incredible PyTorch. Feel free to make a pu
 9.2k Jan 2, 2023
9.2k Jan 2, 2023
A selection of State Of The Art research papers (and code) on human locomotion (pose + trajectory) prediction (forecasting)
A selection of State Of The Art research papers (and code) on human trajectory prediction (forecasting). Papers marked with [W] are workshop papers.
 40 Nov 18, 2022
40 Nov 18, 2022
A curated list of papers, code and resources pertaining to image composition
A curated list of resources including papers, datasets, and relevant links pertaining to image composition.
 391 Dec 30, 2022
391 Dec 30, 2022

A dataset for online Arabic calligraphy
Calliar Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic callig
 114 Dec 28, 2022
114 Dec 28, 2022
Some Boring Research About Products Recognition 、Duplicate Img Detection、Img Stitch、OCR
Products Recognition 介绍 商品识别,围绕在复杂的商场零售场景中,识别出货架图像中的商品信息。主要组成部分: 重复图像检测。【更新进度 4/10】 图像拼接。【更新进度 0/10】 目标检测。【更新进度 0/10】 商品识别。【更新进度 1/10】 OCR。【更新进度 1/10】
 18 Jan 27, 2022
18 Jan 27, 2022

Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH
Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH. It leverages selenium, a website testing framework to crawl the titles and pdf urls from the conference website, and download them one by one with some simple anti-anti-crawler tricks.
 39 Nov 21, 2022
39 Nov 21, 2022
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
A cross platform OCR Library based on PaddleOCR & OnnxRuntime
 767 Jan 9, 2023
767 Jan 9, 2023
Code for papers "Generation-Augmented Retrieval for Open-Domain Question Answering" and "Reader-Guided Passage Reranking for Open-Domain Question Answering", ACL 2021
This repo provides the code of the following papers: (GAR) "Generation-Augmented Retrieval for Open-domain Question Answering", ACL 2021 (RIDER) "Read
 49 Dec 26, 2022
49 Dec 26, 2022

Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
 78 Aug 23, 2022
78 Aug 23, 2022
Repository of conference publications and source code for first-/ second-authored papers published at NeurIPS, ICML, and ICLR.
Repository of conference publications and source code for first-/ second-authored papers published at NeurIPS, ICML, and ICLR.
 26 Jun 17, 2021
26 Jun 17, 2021
Generate a list of papers with publicly available source code in the daily arxiv
2021-06-08 paper code optimal network slicing for service-oriented networks with flexible routing and guaranteed e2e latency networkslicing multi-moda
 79 Jan 3, 2023
79 Jan 3, 2023
Automatic voice-synthetised summaries of latest research papers on arXiv
PaperWhisperer PaperWhisperer is a Python application that keeps you up-to-date with research papers. How? It retrieves the latest articles from arXiv
 124 Dec 20, 2022
124 Dec 20, 2022

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022
The code for two papers: Feedback Transformer and Expire-Span.
transformer-sequential This repo contains the code for two papers: Feedback Transformer Expire-Span The training code is structured for long sequentia
 125 Dec 25, 2022
125 Dec 25, 2022
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
 17 May 16, 2021
17 May 16, 2021

A curated list of programmatic weak supervision papers and resources
A curated list of programmatic weak supervision papers and resources
 118 Jan 2, 2023
118 Jan 2, 2023

COVID-19 Related NLP Papers
COVID-19 outbreak has become a global pandemic. NLP researchers are fighting the epidemic in their own way.
 28 Oct 30, 2022
28 Oct 30, 2022
A list of papers regarding generalization in (deep) reinforcement learning
A list of papers regarding generalization in (deep) reinforcement learning
 13 Apr 26, 2021
13 Apr 26, 2021
A list of multi-task learning papers and projects.
A list of multi-task learning papers and projects.
 84 Apr 27, 2021
84 Apr 27, 2021
A list of multi-task learning papers and projects.
This page contains a list of papers on multi-task learning for computer vision. Please create a pull request if you wish to add anything. If you are interested, consider reading our recent survey paper.
297 Dec 17, 2022
Classic Papers for Beginners and Impact Scope for Authors.
There have been billions of academic papers around the world. However, maybe only 0.0...01% among them are valuable or are worth reading. Since our limited life has never been forever, TopPaper provide a Top Academic Paper Chart for beginners and reseachers to take one step faster.
 228 Dec 18, 2022
228 Dec 18, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023
Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
176 Nov 28, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022

Layout Parser is a deep learning based tool for document image layout analysis tasks.
A Python Library for Document Layout Understanding
 3.4k Dec 30, 2022
3.4k Dec 30, 2022
Recommender System Papers
Included Conferences: SIGIR 2020, SIGKDD 2020, RecSys 2020, CIKM 2020, AAAI 2021, WSDM 2021, WWW 2021
 704 Jan 6, 2023
704 Jan 6, 2023
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf # it's a scriptable c
 7.9k Jan 3, 2023
7.9k Jan 3, 2023

Convolutional Recurrent Neural Networks(CRNN) for Scene Text Recognition
CRNN_Tensorflow This is a TensorFlow implementation of a Deep Neural Network for scene text recognition. It is mainly based on the paper "An End-to-En
 1000 Dec 27, 2022
1000 Dec 27, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

A simple OCR API server, seriously easy to be deployed by Docker, on Heroku as well
ocrserver Simple OCR server, as a small working sample for gosseract. Try now here https://ocr-example.herokuapp.com/, and deploy your own now. Deploy
 541 Dec 28, 2022
541 Dec 28, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

Detect text blocks and OCR poorly scanned PDFs in bulk. Python module available via pip.
doc2text doc2text extracts higher quality text by fixing common scan errors Developing text corpora can be a massive pain in the butt. Much of the tex
 1.3k Jan 4, 2023
1.3k Jan 4, 2023

An OCR evaluation tool
dinglehopper dinglehopper is an OCR evaluation tool and reads ALTO, PAGE and text files. It compares a ground truth (GT) document page with a OCR resu
 40 Dec 20, 2022
40 Dec 20, 2022

Text recognition (optical character recognition) with deep learning methods.
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis | paper | training and evaluation data | failure cases and cle
3.2k Jan 4, 2023

TedEval: A Fair Evaluation Metric for Scene Text Detectors
TedEval: A Fair Evaluation Metric for Scene Text Detectors Official Python 3 implementation of TedEval | paper | slides Chae Young Lee, Youngmin Baek,
167 Nov 20, 2022
The CIS OCR PostCorrectionTool
The CIS OCR Post Correction Tool PoCoTo Source code for the Java-based PoCoTo client enabling fast interactive batch corrections of complete OCR error
 36 Dec 15, 2022
36 Dec 15, 2022
Toolbox for OCR post-correction
Ochre Ochre is a toolbox for OCR post-correction. Please note that this software is experimental and very much a work in progress! Overview of OCR pos
 117 Nov 10, 2022
117 Nov 10, 2022

Binarize document images
Binarization Binarization for document images Examples Introduction This tool performs document image binarization (i.e. transform colour/grayscale to
48 Jan 2, 2023
Pre-Recognize Library - library with algorithms for improving OCR quality.
PRLib - Pre-Recognition Library. The main aim of the library - prepare image for recogntion. Image processing can really help to improve recognition q
 80 Dec 30, 2022
80 Dec 30, 2022

Generate text images for training deep learning ocr model
New version release:https://github.com/oh-my-ocr/text_renderer Text Renderer Generate text images for training deep learning OCR model (e.g. CRNN). Su
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
list all open dataset about ocr.
ocr-open-dataset list all open dataset about ocr. printed dataset year Born-Digital Images (Web and Email) 2011-2015 COCO-Text 2017 Text Extraction fr
 95 Nov 24, 2022
95 Nov 24, 2022
Tools for manipulating and evaluating the hOCR format for representing multi-lingual OCR results by embedding them into HTML.
hocr-tools About About the code Installation System-wide with pip System-wide from source virtualenv Available Programs hocr-check -- check the hOCR f
285 Dec 8, 2022
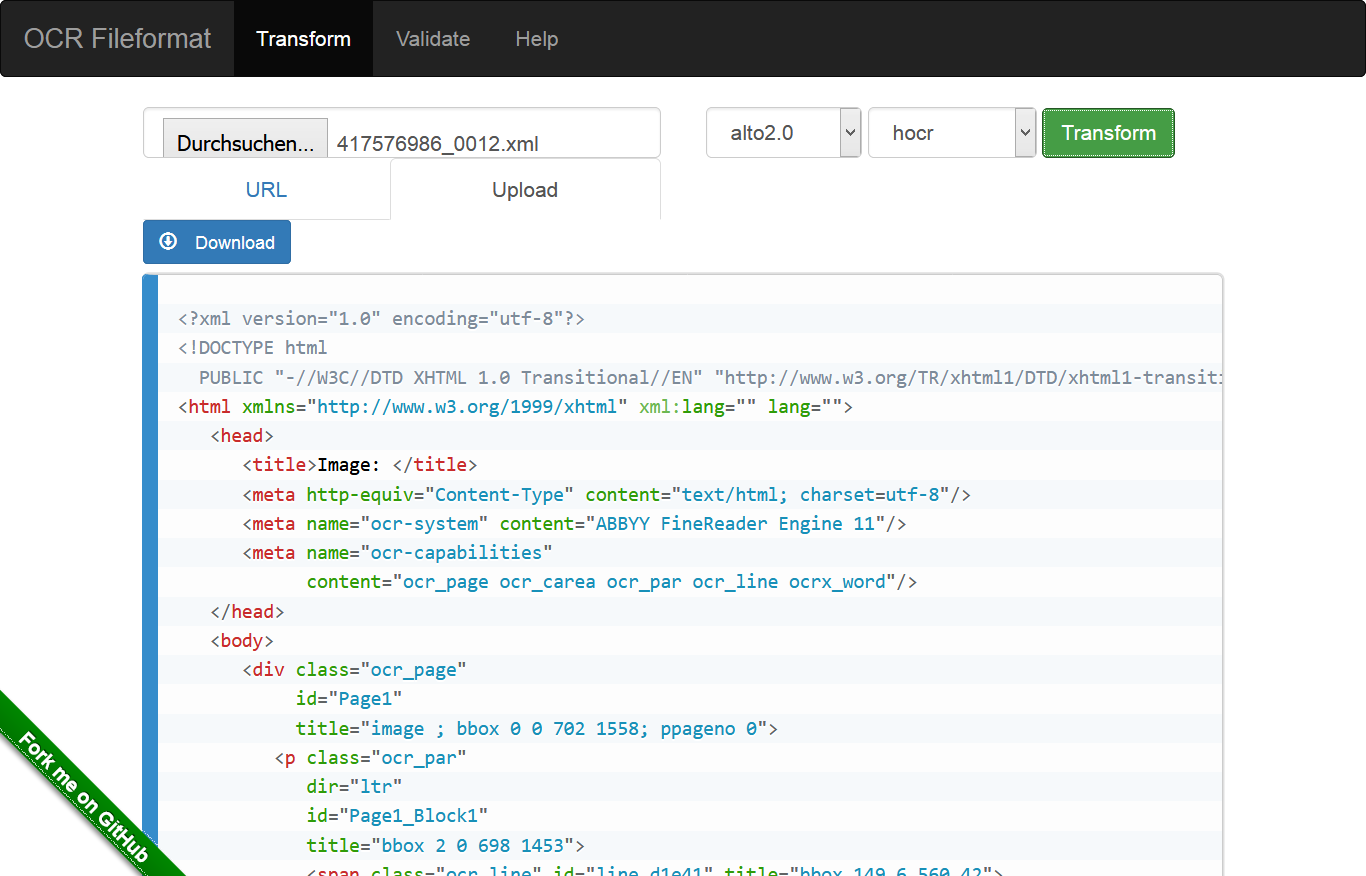
Validate and transform various OCR file formats (hOCR, ALTO, PAGE, FineReader)
ocr-fileformat Validate and transform between OCR file formats (hOCR, ALTO, PAGE, FineReader) Installation Docker System-wide Usage CLI GUI API Transf
 152 Dec 20, 2022
152 Dec 20, 2022
OCR, Scene-Text-Understanding, Text Recognition
Scene-Text-Understanding Survey [2015-PAMI] Text Detection and Recognition in Imagery: A Survey paper [2014-Front.Comput.Sci] Scene Text Detection and
 354 Dec 12, 2022
354 Dec 12, 2022
Tracking the latest progress in Scene Text Detection and Recognition: Must-read papers well organized
SceneTextPapers Tracking the latest progress in Scene Text Detection and Recognition: must-read papers well organized Information about this repositor
 763 Jan 1, 2023
763 Jan 1, 2023
A curated list of promising OCR resources
Call for contributor(paper summary,dataset generation,algorithm implementation and any other useful resources) awesome-ocr A curated list of promising
 1.6k Jan 4, 2023
1.6k Jan 4, 2023