296 Repositories
Python ocr-pdf Libraries

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022
Incomplete easy-to-use math solver and PDF generator.
Math Expert Let me do your work Preview preview.mp4 Introduction Math Expert is our (@salastro, @younis-tarek, @marawn-mogeb) math high school graduat
 22 Jul 11, 2022
22 Jul 11, 2022

Optical Character Recognition + Instance Segmentation for russian and english languages
Распознавание рукописного текста в школьных тетрадях Соревнование, проводимое в рамках олимпиады НТО, разработанное Сбером. Платформа ODS. Результаты
 21 Dec 19, 2022
21 Dec 19, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

Let's create a tool to convert Thailand budget from PDF to CSV.
thailand-budget-pdf2csv Let's create a tool to convert Thailand Government Budgeting from PDF to CSV! รวมพลัง Dev แปลงงบ จาก PDF สู่ Machine-readable
 88 Dec 19, 2022
88 Dec 19, 2022

This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf
Behavior-Sequence-Transformer-Pytorch This is a pytorch implementation for the BST model from Alibaba https://arxiv.org/pdf/1905.06874.pdf This model
 83 Jan 5, 2023
83 Jan 5, 2023
Read Japanese manga inside browser with selectable text.
mokuro Read Japanese manga with selectable text inside a browser. See demo: https://kha-white.github.io/manga-demo mokuro_demo.mp4 Demo contains excer
170 Dec 27, 2022
A modern pure-Python library for reading PDF files
pdf A modern pure-Python library for reading PDF files. The goal is to have a modern interface to handle PDF files which is consistent with itself and
 6 Apr 6, 2022
6 Apr 6, 2022

Comparison-of-OCR (KerasOCR, PyTesseract,EasyOCR)
Optical Character Recognition OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper
21 Dec 25, 2022
Pydf: A modular Telegram Bot which provides Pdf Tools using PyPdf2
pyDF-Bot 🌍 Pydf - Pyrogram Document File Bot, a modular Telegram Bot which prov
 2 Feb 18, 2022
2 Feb 18, 2022
Pgn2tex - Scripts to convert pgn files to latex document. Useful to build books or pdf from pgn studies
Pgn2Latex (WIP) A simple script to make pdf from pgn files and studies. It's sti
 12 Jul 23, 2022
12 Jul 23, 2022
Wats2PDF - Convert whatsapp exported chat(without media) into a readable pdf format
Wats2PDF convert whatsApp exported chat into a readable pdf format. convert with
 5 Apr 26, 2022
5 Apr 26, 2022
Digitalizing-Prescription-Image - PIRDS - Prescription Image Recognition and Digitalizing System is a OCR make with Tensorflow
Digitalizing-Prescription-Image PIRDS - Prescription Image Recognition and Digit
 2 May 11, 2022
2 May 11, 2022
Convert PDF to AudioBook and Audio Speech to PDF
In this Python project, we will build a GUI-based PDF to Audio and Audio to PDF converter using the Tkinter, OS, path, pyttsx3, SpeechRecognition, PyPDF4, and Pydub libraries and the messagebox module of the Tkinter library.
 1 Feb 13, 2022
1 Feb 13, 2022
Select range and every time the screen changes, OCR is activated.
ASOCR(Auto Screen OCR) Select range and every time you press Space key, OCR is activated. 範囲を選ぶと、あなたがスペースキーを押すたびに、画面が変わる度にOCRが起動します。 usage1: simple OC
 1 Feb 13, 2022
1 Feb 13, 2022
Split given PDF document into 4 page groups and convert them to booklet format
PUTO: PDF to Booklet converter Split given PDF document into 4 page groups and convert them to booklet format. It creates a PDF like shown below: Fir
 3 Mar 12, 2022
3 Mar 12, 2022
Convert MD files to PDF automatically (with CSS) 📄🚀
MD2PDF Action Convert MD files to PDF automatically (with CSS)! Converts a pattern described set of markdown files and converts them to pdf whilst app
 1 Feb 9, 2022
1 Feb 9, 2022
DietPDF aims at reducing PDF file size while not degrading quality nor losing metadata
DietPDF aims at reducing PDF file size while not degrading quality nor losing metadata
 6 Jul 27, 2022
6 Jul 27, 2022

OCR, Object Detection, Number Plate, Real Time
README.md PrePareded anaconda env requirements.txt clova AI → deep text recognition → trained weights (ex, .pth) wpod-net weights (ex, .h5 , .json) ht
 7 Dec 6, 2022
7 Dec 6, 2022
JoplinPdf2Images - Converts a PDF to images in Joplin and adds it to the specified note as a printout
joplinPdf2Images Converts a PDF to images in Joplin and adds it to the specified
 2 Apr 20, 2022
2 Apr 20, 2022
Svg2pdfgen - Svg To PDF gen with python
Svg2pdfgen - Svg To PDF gen with python
 3 May 30, 2022
3 May 30, 2022
Compare-pdf - A Flask driven restful API for comparing two PDF files
COMPARE-PDF A Flask driven restful API for comparing two PDF files. Description
 3 Mar 13, 2022
3 Mar 13, 2022
Python tool that takes the OCR.space JSON output as input and draws a text overlay on top of the image.
OCR.space OCR Result Checker = Draw OCR overlay on top of image Python tool that takes the OCR.space JSON output as input, and draws an overlay on to
 4 Oct 18, 2022
4 Oct 18, 2022

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
327 Jan 1, 2023
This pyhton script converts a pdf to Image then using tesseract as OCR engine converts Image to Text
Script_Convertir_PDF_IMG_TXT Este script de pyhton convierte un pdf en Imagen luego utilizando tesseract como motor OCR convierte la Imagen a Texto. p
 1 Jan 27, 2022
1 Jan 27, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

OCR-ID-Card VietNamese (new id-card)
OCR-ID-Card VietNamese (new id-card) run project: download 2 file weights and pu
 12 Jun 15, 2022
12 Jun 15, 2022
OCR-D wrapper for detectron2 based segmentation models
ocrd_detectron2 OCR-D wrapper for detectron2 based segmentation models Introduction Installation Usage OCR-D processor interface ocrd-detectron2-segm
 13 Dec 6, 2022
13 Dec 6, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022
A backend for mdbook in Python for generating PDF based on Chrome DevTools Protocol.
mdbook-pdf A backend for mdbook written in Python for generating PDF based on Chrome DevTools Protocol. Python library dependency Usage Put mdbook-pdf
 49 Dec 27, 2022
49 Dec 27, 2022
A bot for PDF for doing Many Things....
Telegram PDF Bot A Telegram bot that can: Compress, crop, decrypt, encrypt, merge, preview, rename, rotate, scale and split PDF files Compare text dif
 60 Dec 27, 2022
60 Dec 27, 2022
PDFSanitizer - Renders possibly unsafe PDF files and outputs harmless PDF files
PDFSanitizer Renders possibly malicious PDF files and outputs harmless PDF files
 9 Jan 30, 2022
9 Jan 30, 2022
Ddddocr - 通用验证码识别OCR pypi版
带带弟弟OCR通用验证码识别SDK免费开源版 今天ddddocr又更新啦! 当前版本为1.3.1 想必很多做验证码的新手,一定头疼碰到点选类型的图像,做样本费时
 4.4k Dec 31, 2022
4.4k Dec 31, 2022
Python utility library for compositing PDF documents with reportlab.
pdfdoc-py Python utility library for compositing PDF documents with reportlab. Installation The pdfdoc-py package can be installed directly from the s
 1 Jan 6, 2022
1 Jan 6, 2022
A bot that plays TFT using OCR. Keeps track of bench, board, items, and plays the user defined team comp.
NOTES: To ensure best results, make sure you are running this on a computer that has decent specs. 1920x1080 fullscreen is required in League, game mu
 125 Dec 30, 2022
125 Dec 30, 2022
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022
Htmdf - html to pdf with support for variables using fastApi.
htmdf Converts html to pdf with support for variables using fastApi. Installation Clone this repository. git clone https://github.com/ShreehariVaasish
 1 Jan 30, 2022
1 Jan 30, 2022
Image Compression GUI APP Python: PyQt5
Image Compression GUI APP Image Compression GUI APP Python: PyQt5 Use : f5 or debug or simply run it on your ids(vscode , pycham, anaconda etc.) socia
 1 May 21, 2022
1 May 21, 2022
Awesome-AI-books - Some awesome AI related books and pdfs for learning and downloading
Awesome AI books Some awesome AI related books and pdfs for downloading and learning. Preface This repo only used for learning, do not use in business
 1k Jan 1, 2023
1k Jan 1, 2023

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
Omdena-abuja-anpd - Automatic Number Plate Detection for the security of lives and properties using Computer Vision.
 1 Jan 1, 2022
1 Jan 1, 2022
Mipdfcompressor - 💕A simple pdf size compressing telegram robot
Pdf Compressor Telegram Bot A simple pdf size compressing telegram robot. Useful for digital documentation. Mandatory Variables API_HASH - Your A
 1 Feb 14, 2022
1 Feb 14, 2022

IDCARD-VERIFYING-SYSTEM - The "IDCARD VERIFYING SYSTEM" uses the Google's latest version of Tesseract OCR[Optical Character Recognition]
IDCARD VERIFYING SYSTEM The "IDCARD VERIFYING SYSTEM" uses the Google's latest v
 1 Dec 31, 2021
1 Dec 31, 2021
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched
OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. ocrmypdf
 8k Jan 8, 2023
8k Jan 8, 2023

Highlight Translator can help you translate the words quickly and accurately.
Highlight Translator can help you translate the words quickly and accurately. By only highlighting, copying, or screenshoting the content you want to translate anywhere on your computer (ex. PDF, PPT, WORD etc.), the translated results will then be automatically displayed before you.
 48 Dec 21, 2022
48 Dec 21, 2022

A bulk pdf generator. This application can generate PDFs in bulk by using just one click.
A bulk html pdf generator. This application can generate PDFs in bulk by using just one click. Screenshots Requirements 🧱 Your system must have the f
 3 Apr 23, 2022
3 Apr 23, 2022
This wrapper now has async support, its basically the same except it uses asyncio
This is a python wrapper for my api api_url = "https://api.dhravya.me/" This wrapper now has async support, its basically the same except it uses asyn
 5 Mar 10, 2022
5 Mar 10, 2022

A tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background.
EasyLaMa (WIP) This is a tool combining EasyOCR and LaMa to automatically detect text and replace it with an inpainted background. Installation For GP
 3 Sep 17, 2022
3 Sep 17, 2022
轻量级公式 OCR 小工具:一键识别各类公式图片,并转换为 LaTeX 格式
QC-Formula | 青尘公式 OCR 介绍 轻量级开源公式 OCR 小工具:一键识别公式图片,并转换为 LaTeX 格式。 支持从 电脑本地 导入公式图片;(后续版本将支持直接从网页导入图片) 公式图片支持 .png / .jpg / .bmp,大小为 4M 以内均可; 支持印刷体及手写体,前
 26 Jan 7, 2023
26 Jan 7, 2023
Produce pdf in python backend from simple bootstrap vue frontend and download to browser
vollmacht produce pdf in python backend from simple bootstrap vue frontend and download to browser Frontend in one file with bootstrap-vue (allthough
 1 Nov 8, 2020
1 Nov 8, 2020
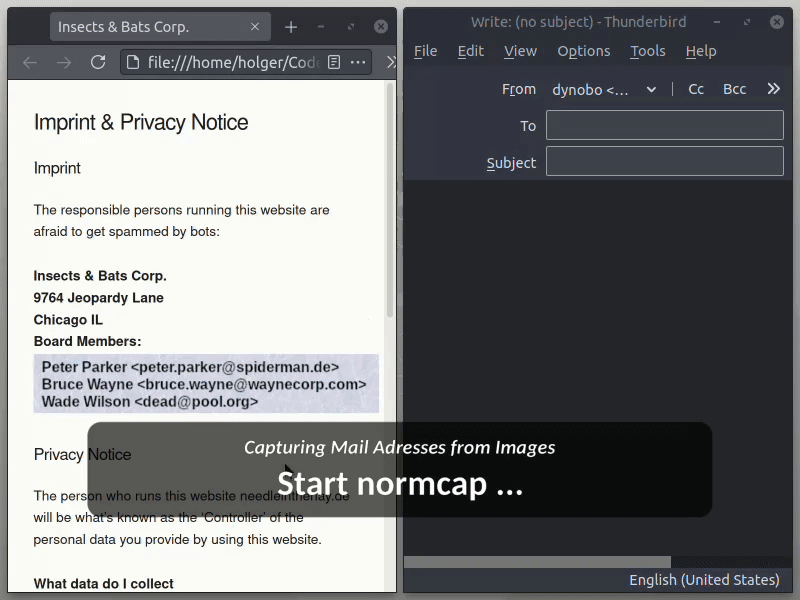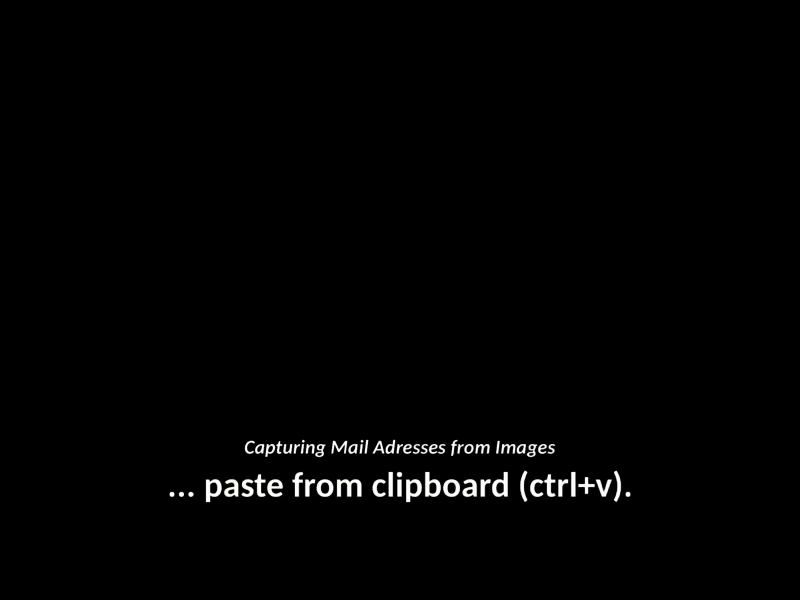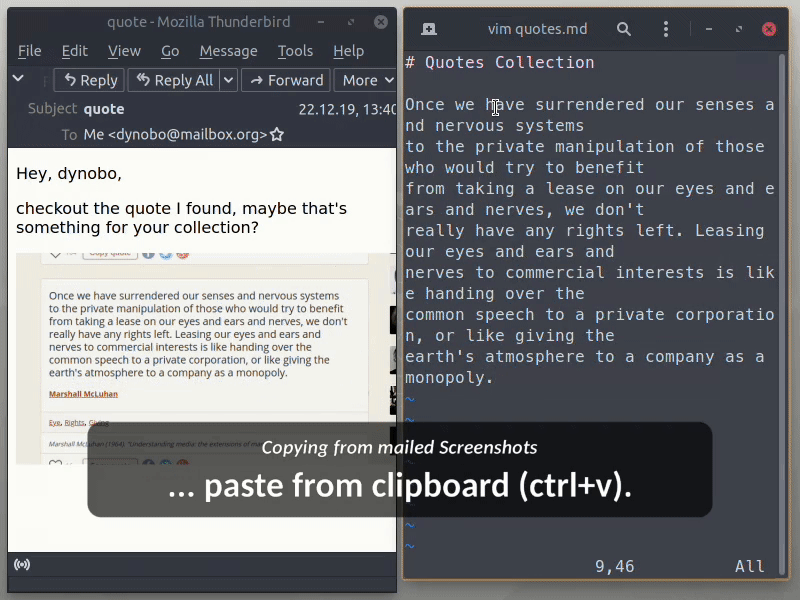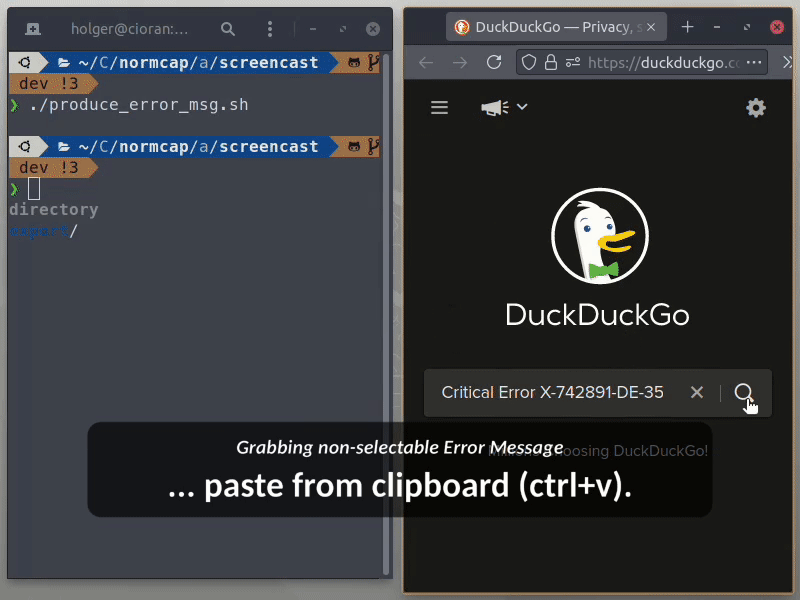
OCR powered screen-capture tool to capture information instead of images
NormCap OCR powered screen-capture tool to capture information instead of images. Links: Repo | PyPi | Releases | Changelog | FAQs Content: Quickstart
 575 Dec 31, 2022
575 Dec 31, 2022
Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python.
About Zen-Knit: Zen-Knit is a formal (PDF), informal (HTML) report generator for data analyst and data scientist who wants to use python. Inspired fro
 27 Jul 13, 2022
27 Jul 13, 2022
Software that extracts spreadsheets from various .pdf files to .csv
Extração de planilhas de diversos arquivos .pdf para .csv O código inteiro foi desenvolvido em Python. Foi utilizado o pacote "tabula" e a biblioteca
 2 Jan 9, 2022
2 Jan 9, 2022

Simple pdf editor while preserving structure and format.
SIMPdf Simple pdf editor while preserving structure and format.
 242 Jan 4, 2023
242 Jan 4, 2023
minipdf is a package for creating simple, single-page PDF documents.
minipdf minipdf is a package for creating simple, single-page PDF documents. Installation You can install the development version from GitHub with: #
 41 Dec 19, 2022
41 Dec 19, 2022

Useful PDF-related productivity tool.
Luftmensch 1.4.7 (Español) | 1.4.3 (English) Version 1.4.7 (Español) released in October 2021. Version 1.4.3 (English) released in September 2021. 🏮
 8 Dec 29, 2022
8 Dec 29, 2022

Scans pdfs for links written in plaintext and checks if they are active or returns an error code.
Scans pdfs for links written in plaintext and checks if they are active or returns an error code. It then generates a report of its findings. Extract references (pdf, url, doi, arxiv) and metadata from a PDF.
 22 Nov 21, 2022
22 Nov 21, 2022

Convert given source code into .pdf with syntax highlighting and more features
Code2pdf 📠 Convert given source code into .pdf with syntax highlighting and more features Build Status Version Downloads Python Demo Installation Bui
 343 Jan 5, 2023
343 Jan 5, 2023
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
AdelaiDet is an open source toolbox for multiple instance-level detection and recognition tasks.
 3k Jan 2, 2023
3k Jan 2, 2023

Automate the case review on legal case documents and find the most critical cases using network analysis
Automation on Legal Court Cases Review This project is to automate the case review on legal case documents and find the most critical cases using netw
 7 Dec 28, 2022
7 Dec 28, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
 7.8k Jan 9, 2023
7.8k Jan 9, 2023
Demo processor to illustrate OCR-D Python API
ocrd_vandalize/ Demo processor to illustrate the OCR-D/core Python API Description :TODO: write docs :) Installation From PyPI pip3 install ocrd_vanda
 5 May 5, 2022
5 May 5, 2022

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022
Telegram bot that can do a lot of things related to PDF files.
Telegram PDF Bot A Telegram bot that can: Compress, crop, decrypt, encrypt, merge, preview, rename, rotate, scale and split PDF files Compare text dif
 130 Dec 26, 2022
130 Dec 26, 2022
Excalibur: A web interface to extract tabular data from PDFs
Excalibur: A web interface to extract tabular data from PDFs Excalibur is a web interface to extract tabular data from PDFs, written in Python 3! It i
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Educational application aimed at automating user-defined workflows for the mobile game, "Granblue Fantasy", using a variety of CV technologies in the backend such as OpenCV, PyAutoGUI and EasyOCR and a frontend coded in Typescript.
Granblue Automation using Template Matching (It is like Full Auto, but with Full Customization!) Discord here: https://discord.gg/5Yv4kqjAbm Android v
 71 Dec 30, 2022
71 Dec 30, 2022

Python bindings for MuPDF's rendering library.
PyMuPDF 1.19.3 Release date: December 15, 2021 On PyPI since August 2016: Author Jorj X. McKie, based on original code by Ruikai Liu. Introduction PyM
 0 Nov 3, 2022
0 Nov 3, 2022
This tool crawls a list of websites and download all PDF and office documents
This tool crawls a list of websites and download all PDF and office documents. Then it analyses the PDF documents and tries to detect accessibility issues.
 7 Sep 30, 2022
7 Sep 30, 2022

Convert PDF/Image to TXT using EasyOcr - the best OCR engine available!
PDFImage2TXT - DOWNLOAD INSTALLER HERE What can you do with it? Convert scanned PDFs to TXT. Convert scanned Documents to TXT. No coding required!! In
 2 Feb 22, 2022
2 Feb 22, 2022

A little but useful tool to explore OCR data extracted with `pytesseract` and `opencv`
Screenshot OCR Tool Extracting data from screen time screenshots in iOS and Android. We are exploring 3 options: Simple OCR with no text position usin
 1 Dec 7, 2021
1 Dec 7, 2021

pubmex.py - a script to get a fancy paper title based on given DOI or PMID
pubmex.py is a script to get a fancy paper title based on given DOI or PMID (can be also combined with macOS Finder)
 13 Nov 20, 2022
13 Nov 20, 2022

A tool for certificate PDF generation.
certificate-pdf-generator 获奖证书PDF批量生成工具 | a Tool for certificate PDF generation. ⚠️ 下载前请注意 本项目使用了LFS来存储PDF等大文件。在克隆或下载本仓库前,请先使用apt等包管理器安装git-lfs包。如果已经克
 4 Nov 28, 2022
4 Nov 28, 2022
Web and PDF Scraper Refactoring
Web and PDF Scraper Refactoring This repository contains the example code of the Web and PDF scraper code roast. Here are the links to the videos: Par
 18 Dec 31, 2022
18 Dec 31, 2022
A python script that fetches the grades of a student from a WAEC result in pdf format.
About waec-result-analyzer A python script that fetches the grades of a student from a WAEC result in pdf format. Built for federal government college
 2 Dec 4, 2021
2 Dec 4, 2021
FOTS Pytorch Implementation
News!!! Recognition branch now is added into model. The whole project has beed optimized and refactored. ICDAR Dataset SynthText 800K Dataset detectio
 599 Dec 19, 2022
599 Dec 19, 2022
Indonesian ID Card OCR using tesseract OCR
KTP OCR Indonesian ID Card OCR using tesseract OCR KTP OCR is python-flask with tesseract web application to convert Indonesian ID Card to text / JSON
 5 Dec 6, 2021
5 Dec 6, 2021

The open source extract transaction infomation by using OCR.
Transaction OCR Mã nguồn trích xuất thông tin transaction từ file scaned pdf, ở đây tôi lựa chọn tài liệu sao kê công khai của Thuy Tien. Mã nguồn có
 18 Jun 2, 2022
18 Jun 2, 2022
A leetcode scraper to compile all questions in leetcode free tier to text file. pdf also available.
A leetcode scraper to compile all questions in leetcode free tier to text file, pdf also available. if new questions get added, run again to get new questions.
 3 Dec 7, 2021
3 Dec 7, 2021
Trata PDF para torná-lo compatível com PDF/X e com impressoras em escala de cinza.
tratapdf Trata PDF para torná-lo compatível com PDF/X e com impressoras em escala de cinza. dependências icc-profiles ghostscript visualizador de PDF
 1 Nov 30, 2021
1 Nov 30, 2021

Meaningful titles for tabs and PDF downloads! Also supports tab search.
arxiv-utils If you are a researcher that reads a lot on ArXiv, you'll benefit a lot from this web extension. Renames the title of PDF page to the pape
 174 Dec 20, 2022
174 Dec 20, 2022
Busca no nome e conteúdo de arquivos PDF no diretório e subdiretórios.
PDF Finder Este script auxilia na pesquisa em pastas com inúmeros arquivos PDF. A pesquisa é feita em todos os arquivos do doretório e subdiretórios.
 1 Nov 27, 2021
1 Nov 27, 2021

Camelot is a Python library that makes it easy for anyone to extract tables from PDF files
Camelot: PDF Table Extraction for Humans Camelot is a Python library that makes it easy for anyone to extract tables from PDF files! Note: You can als
 3.3k Jan 6, 2023
3.3k Jan 6, 2023
CLI tool to generate pdf invoices written in python
invoicepy CLI invoice tool, store and print invoices as pdf. save companies and customers for later use. installation pip install invoicepy config co
 9 Aug 1, 2022
9 Aug 1, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023
DivNoising is an unsupervised denoising method to generate diverse denoised samples for any noisy input image. This repository contains the code to reproduce the results reported in the paper https://openreview.net/pdf?id=agHLCOBM5jP
DivNoising: Diversity Denoising with Fully Convolutional Variational Autoencoders Mangal Prakash1, Alexander Krull1,2, Florian Jug2 1Authors contribut
 33 Dec 30, 2022
33 Dec 30, 2022

OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages
OCR-Streamlit-App OCR Streamlit App is used to extract text from images using python's easyocr, pytorch and streamlit packages OCR app gets an image a
 5 Apr 5, 2022
5 Apr 5, 2022
Sheet Data Image/PDF-to-CSV Converter
Sheet Data Image/PDF-to-CSV Converter
 5 Nov 22, 2021
5 Nov 22, 2021

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023

The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
 2 Nov 20, 2021
2 Nov 20, 2021
rst2pdf: Use a text editor. Make a PDF.
rst2pdf: Use a text editor. Make a PDF.
 487 Jan 6, 2023
487 Jan 6, 2023
This is PDF Merger Application Developed using Just Python
This is PDF Merger Application Developed using Just Python
 2 Nov 18, 2021
2 Nov 18, 2021
Chilean Digital Vaccination Pass Parser (CDVPP) parses digital vaccination passes from PDF files
cdvpp Chilean Digital Vaccination Pass Parser (CDVPP) parses digital vaccination passes from PDF files Reads a Digital Vaccination Pass PDF file as in
 1 Nov 17, 2021
1 Nov 17, 2021
A simple Python script to convert multiple images (well technically also a single image) into a pdf.
PythonImage2PDF A simple Python script to convert multiple images into a single PDF-document. Created basically for only my own needs for converting m
 1 Jun 28, 2022
1 Jun 28, 2022
A simple Telegram bot can convert web docs, Telegraph links, etc. to Pdf !
A Telegram Bot to convert http Links to PDF
 10 Oct 28, 2022
10 Oct 28, 2022
The goal of this project is for anyone with an old printer to be able to double-sided printing.
Welcome to PDF-double-side! Hi! I'm 15. I have a old printer so I can't print double-sided outs. The goal of this project is for anyone with an old pr
 4 Dec 28, 2021
4 Dec 28, 2021
Simple python tool for the purpose of swapping latinic letters with cirilic ones and vice versa in txt, docx and pdf files in Serbian language
Alpha Swap English This is a simple python tool for the purpose of swapping latinic letters with cirylic ones and vice versa, in txt, docx and pdf fil
 3 May 31, 2022
3 May 31, 2022

Extract the table in the PDF,outputs the data similar to the json format
extract the table in the PDF,outputs the data similar to the json format
 3 Nov 25, 2021
3 Nov 25, 2021

Reads Data from given Excel File and exports Single PDFs and a complete PDF grouped by Gateway
E-Shelter Excel2QR Reads Data from given Excel File and exports Single PDFs and a complete PDF grouped by Gateway Features Reads Excel 2021 Export Sin
 1 Nov 13, 2021
1 Nov 13, 2021
OCR of Chicago 1909 Renumbering Plan
Requirements: Python 3 (probably at least 3.4) pipenv (pip3 install pipenv) tesseract (brew install tesseract, at least if you have a mac and homebrew
 2 Nov 21, 2021
2 Nov 21, 2021