2334 Repositories
Python pre-trained-language-models Libraries
A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models
wav2vec-toolkit A collection of scripts to preprocess ASR datasets and finetune language-specific Wav2Vec2 XLSR models This repository accompanies the
 29 Oct 23, 2022
29 Oct 23, 2022

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
 11.2k Jan 9, 2023
11.2k Jan 9, 2023
The source code for the Cutoff data augmentation approach proposed in this paper: "A Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation".
Cutoff: A Simple Data Augmentation Approach for Natural Language This repository contains source code necessary to reproduce the results presented in
 49 Dec 22, 2022
49 Dec 22, 2022
Source code for the GPT-2 story generation models in the EMNLP 2020 paper "STORIUM: A Dataset and Evaluation Platform for Human-in-the-Loop Story Generation"
Storium GPT-2 Models This is the official repository for the GPT-2 models described in the EMNLP 2020 paper [STORIUM: A Dataset and Evaluation Platfor
 27 Dec 20, 2022
27 Dec 20, 2022
Official repository for "PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation"
pair-emnlp2020 Official repository for the paper: Xinyu Hua and Lu Wang: PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long
 31 Oct 13, 2022
31 Oct 13, 2022

Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT CheXbert is an accurate, automated dee
 51 Dec 8, 2022
51 Dec 8, 2022
Code, Data and Demo for Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting
InversePrompting Paper: Controllable Generation from Pre-trained Language Models via Inverse Prompting Code: The code is provided in the "chinese_ip"
 101 Dec 16, 2022
101 Dec 16, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022
Official code for the CVPR 2021 paper "How Well Do Self-Supervised Models Transfer?"
How Well Do Self-Supervised Models Transfer? This repository hosts the code for the experiments in the CVPR 2021 paper How Well Do Self-Supervised Mod
 157 Dec 16, 2022
157 Dec 16, 2022
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks,
TextFlint is a multilingual robustness evaluation platform for natural language processing tasks, which unifies general text transformation, task-specific transformation, adversarial attack, sub-population, and their combinations to provide a comprehensive robustness analysis.
 587 Dec 20, 2022
587 Dec 20, 2022
(ImageNet pretrained models) The official pytorch implemention of the TPAMI paper "Res2Net: A New Multi-scale Backbone Architecture"
Res2Net The official pytorch implemention of the paper "Res2Net: A New Multi-scale Backbone Architecture" Our paper is accepted by IEEE Transactions o
 928 Dec 29, 2022
928 Dec 29, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
This tool extracts Credit card numbers, NTLM(DCE-RPC, HTTP, SQL, LDAP, etc), Kerberos (AS-REQ Pre-Auth etype 23), HTTP Basic, SNMP, POP, SMTP, FTP, IMAP, etc from a pcap file or from a live interface.
 1.6k Jan 1, 2023
1.6k Jan 1, 2023
Neural models of common sense. 🤖
Unicorn on Rainbow Neural models of common sense. This repository is for the paper: Unicorn on Rainbow: A Universal Commonsense Reasoning Model on a N
 60 Jan 5, 2023
60 Jan 5, 2023
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
This project is part of Eleuther AI's quest to create a massive repository of high quality text data for training language models.
 42 Dec 13, 2022
42 Dec 13, 2022

A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''.
P-tuning A novel method to tune language models. Codes and datasets for paper ``GPT understands, too''. How to use our code We have released the code
562 Dec 27, 2022

source code and pre-trained/fine-tuned checkpoint for NAACL 2021 paper LightningDOT
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval This repository contains source code and pre-trained/fine-tun
 65 Dec 26, 2022
65 Dec 26, 2022

Implementation of the paper "Language-agnostic representation learning of source code from structure and context".
Code Transformer This is an official PyTorch implementation of the CodeTransformer model proposed in: D. Zügner, T. Kirschstein, M. Catasta, J. Leskov
 131 Dec 13, 2022
131 Dec 13, 2022

The guide to tackle with the Text Summarization
The guide to tackle with the Text Summarization
 1.2k Dec 30, 2022
1.2k Dec 30, 2022

Implementation of 'lightweight' GAN, proposed in ICLR 2021, in Pytorch. High resolution image generations that can be trained within a day or two
512x512 flowers after 12 hours of training, 1 gpu 256x256 flowers after 12 hours of training, 1 gpu Pizza 'Lightweight' GAN Implementation of 'lightwe
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
JMESPath is a query language for JSON.
JMESPath JMESPath (pronounced "james path") allows you to declaratively specify how to extract elements from a JSON document. For example, given this
 1.7k Dec 31, 2022
1.7k Dec 31, 2022

Viewflow is an Airflow-based framework that allows data scientists to create data models without writing Airflow code.
Viewflow Viewflow is a framework built on the top of Airflow that enables data scientists to create materialized views. It allows data scientists to f
 114 Oct 12, 2022
114 Oct 12, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023

Tracking Progress in Natural Language Processing
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 21.2k Dec 30, 2022
21.2k Dec 30, 2022
A probabilistic programming library for Bayesian deep learning, generative models, based on Tensorflow
ZhuSuan is a Python probabilistic programming library for Bayesian deep learning, which conjoins the complimentary advantages of Bayesian methods and
 2.2k Dec 28, 2022
2.2k Dec 28, 2022
A probabilistic programming language in TensorFlow. Deep generative models, variational inference.
Edward is a Python library for probabilistic modeling, inference, and criticism. It is a testbed for fast experimentation and research with probabilis
 4.7k Jan 9, 2023
4.7k Jan 9, 2023
Describing statistical models in Python using symbolic formulas
Patsy is a Python library for describing statistical models (especially linear models, or models that have a linear component) and building design mat
 866 Dec 16, 2022
866 Dec 16, 2022
A Python package for Bayesian forecasting with object-oriented design and probabilistic models under the hood.
Disclaimer This project is stable and being incubated for long-term support. It may contain new experimental code, for which APIs are subject to chang
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
Python Library for learning (Structure and Parameter) and inference (Statistical and Causal) in Bayesian Networks.
pgmpy pgmpy is a python library for working with Probabilistic Graphical Models. Documentation and list of algorithms supported is at our official sit
 2.2k Dec 25, 2022
2.2k Dec 25, 2022
Fast, flexible and easy to use probabilistic modelling in Python.
Please consider citing the JMLR-MLOSS Manuscript if you've used pomegranate in your academic work! pomegranate is a package for building probabilistic
 3k Jan 2, 2023
3k Jan 2, 2023
Hidden Markov Models in Python, with scikit-learn like API
hmmlearn hmmlearn is a set of algorithms for unsupervised learning and inference of Hidden Markov Models. For supervised learning learning of HMMs and
 2.7k Jan 3, 2023
2.7k Jan 3, 2023

Scikit-learn compatible estimation of general graphical models
skggm : Gaussian graphical models using the scikit-learn API In the last decade, learning networks that encode conditional independence relationships
 213 Jan 2, 2023
213 Jan 2, 2023

Differentiable SDE solvers with GPU support and efficient sensitivity analysis.
PyTorch Implementation of Differentiable SDE Solvers This library provides stochastic differential equation (SDE) solvers with GPU support and efficie
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Pretrained EfficientNet, EfficientNet-Lite, MixNet, MobileNetV3 / V2, MNASNet A1 and B1, FBNet, Single-Path NAS
(Generic) EfficientNets for PyTorch A 'generic' implementation of EfficientNet, MixNet, MobileNetV3, etc. that covers most of the compute/parameter ef
 1.5k Jan 1, 2023
1.5k Jan 1, 2023

Rembg Video Virtual Green Screen Edition
Rembg Virtual Greenscreen Edition is a tool to create a green screen matte for videos
 61 Mar 28, 2021
61 Mar 28, 2021
Library for faster pinned CPU - GPU transfer in Pytorch
SpeedTorch Faster pinned CPU tensor - GPU Pytorch variabe transfer and GPU tensor - GPU Pytorch variable transfer, in certain cases. Update 9-29-1
 657 Dec 19, 2022
657 Dec 19, 2022
Decentralized deep learning in PyTorch. Built to train models on thousands of volunteers across the world.
Hivemind: decentralized deep learning in PyTorch Hivemind is a PyTorch library to train large neural networks across the Internet. Its intended usage
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
Petastorm library enables single machine or distributed training and evaluation of deep learning models from datasets in Apache Parquet format. It supports ML frameworks such as Tensorflow, Pytorch, and PySpark and can be used from pure Python code.
Petastorm Contents Petastorm Installation Generating a dataset Plain Python API Tensorflow API Pytorch API Spark Dataset Converter API Analyzing petas
1.6k Dec 31, 2022

AtsPy: Automated Time Series Models in Python (by @firmai)
Automated Time Series Models in Python (AtsPy) SSRN Report Easily develop state of the art time series models to forecast univariate data series. Simp
 465 Jan 2, 2023
465 Jan 2, 2023
Automatically build ARIMA, SARIMAX, VAR, FB Prophet and XGBoost Models on Time Series data sets with a Single Line of Code. Now updated with Dask to handle millions of rows.
Auto_TS: Auto_TimeSeries Automatically build multiple Time Series models using a Single Line of Code. Now updated with Dask. Auto_timeseries is a comp
 519 Jan 3, 2023
519 Jan 3, 2023
A python library for easy manipulation and forecasting of time series.
Time Series Made Easy in Python darts is a python library for easy manipulation and forecasting of time series. It contains a variety of models, from
 5.2k Jan 4, 2023
5.2k Jan 4, 2023
A statistical library designed to fill the void in Python's time series analysis capabilities, including the equivalent of R's auto.arima function.
pmdarima Pmdarima (originally pyramid-arima, for the anagram of 'py' + 'arima') is a statistical library designed to fill the void in Python's time se
 1.3k Dec 22, 2022
1.3k Dec 22, 2022
ARCH models in Python
arch Autoregressive Conditional Heteroskedasticity (ARCH) and other tools for financial econometrics, written in Python (with Cython and/or Numba used
 1k Jan 4, 2023
1k Jan 4, 2023
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment. With Qlib, you can easily try your ideas to create better Quant investment strategies.
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technol
 10.1k Dec 31, 2022
10.1k Dec 31, 2022

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022
NaturalProofs: Mathematical Theorem Proving in Natural Language
NaturalProofs: Mathematical Theorem Proving in Natural Language NaturalProofs: Mathematical Theorem Proving in Natural Language Sean Welleck, Jiacheng
 83 Jan 5, 2023
83 Jan 5, 2023

PyTorch implementation of "Contrast to Divide: self-supervised pre-training for learning with noisy labels"
Contrast to Divide: self-supervised pre-training for learning with noisy labels This is an official implementation of "Contrast to Divide: self-superv
 55 Nov 23, 2022
55 Nov 23, 2022
Source code, datasets and trained models for the paper Learning Advanced Mathematical Computations from Examples (ICLR 2021), by François Charton, Amaury Hayat (ENPC-Rutgers) and Guillaume Lample
Maths from examples - Learning advanced mathematical computations from examples This is the source code and data sets relevant to the paper Learning a
 171 Nov 23, 2022
171 Nov 23, 2022

Diverse Image Captioning with Context-Object Split Latent Spaces (NeurIPS 2020)
Diverse Image Captioning with Context-Object Split Latent Spaces This repository is the PyTorch implementation of the paper: Diverse Image Captioning
 34 Nov 21, 2022
34 Nov 21, 2022

CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent performances in several models such as Faster R-CNN, YOLOv4, RetinaNet and . There is a maximum AP improvement of 1.9% and an average AP of 0.8% improvement on MS COCO dataset, compared to traditional evaluation-feedback modules. Here we just use as an example to illustrate the code.
CDIoU-CDIoUloss CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent p
 24 Jul 19, 2022
24 Jul 19, 2022

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023
UNION: An Unreferenced Metric for Evaluating Open-ended Story Generation
UNION Automatic Evaluation Metric described in the paper UNION: An UNreferenced MetrIc for Evaluating Open-eNded Story Generation (EMNLP 2020). Please
 50 Dec 30, 2022
50 Dec 30, 2022
Monocular Depth Estimation - Weighted-average prediction from multiple pre-trained depth estimation models
merged_depth runs (1) AdaBins, (2) DiverseDepth, (3) MiDaS, (4) SGDepth, and (5) Monodepth2, and calculates a weighted-average per-pixel absolute dept
 39 Nov 21, 2022
39 Nov 21, 2022
Repository providing a wide range of self-supervised pretrained models for computer vision tasks.
Hierarchical Pretraining: Research Repository This is a research repository for reproducing the results from the project "Self-supervised pretraining
 53 Nov 9, 2022
53 Nov 9, 2022
![[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias](https://github.com/yuleiniu/cfvqa/raw/main/assets/cfvqa.png)
[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias
Counterfactual VQA (CF-VQA) This repository is the Pytorch implementation of our paper "Counterfactual VQA: A Cause-Effect Look at Language Bias" in C
 94 Dec 3, 2022
94 Dec 3, 2022
Pre-Recognize Library - library with algorithms for improving OCR quality.
PRLib - Pre-Recognition Library. The main aim of the library - prepare image for recogntion. Image processing can really help to improve recognition q
 80 Dec 30, 2022
80 Dec 30, 2022

OCR system for Arabic language that converts images of typed text to machine-encoded text.
Arabic OCR OCR system for Arabic language that converts images of typed text to machine-encoded text. The system currently supports only letters (29 l
 144 Jan 5, 2023
144 Jan 5, 2023
Natural language detection
Detect the language of text. What’s so cool about franc? franc can support more languages(†) than any other library franc is packaged with support for
 3.8k Jan 2, 2023
3.8k Jan 2, 2023
Tensorflow-based CNN+LSTM trained with CTC-loss for OCR
Overview This collection demonstrates how to construct and train a deep, bidirectional stacked LSTM using CNN features as input with CTC loss to perfo
 489 Dec 21, 2022
489 Dec 21, 2022
Text language identification using Wikipedia data
Text language identification using Wikipedia data The aim of this project is to provide high-quality language detection over all the web's languages.
 28 Jul 9, 2022
28 Jul 9, 2022
Lightning Fast Language Prediction 🚀
whatthelang Lightning Fast Language Prediction 🚀 Dependencies The dependencies can be installed using the requirements.txt file: $ pip install -r req
 152 Oct 16, 2022
152 Oct 16, 2022
👄 The most accurate natural language detection library for Java and the JVM, suitable for long and short text alike
Quick Info this library tries to solve language detection of very short words and phrases, even shorter than tweets makes use of both statistical and
 532 Dec 28, 2022
532 Dec 28, 2022

Use Convolutional Recurrent Neural Network to recognize the Handwritten line text image without pre segmentation into words or characters. Use CTC loss Function to train.
Handwritten Line Text Recognition using Deep Learning with Tensorflow Description Use Convolutional Recurrent Neural Network to recognize the Handwrit
 224 Jan 7, 2023
224 Jan 7, 2023
This repository lets you train neural networks models for performing end-to-end full-page handwriting recognition using the Apache MXNet deep learning frameworks on the IAM Dataset.
Handwritten Text Recognition (OCR) with MXNet Gluon These notebooks have been created by Jonathan Chung, as part of his internship as Applied Scientis
 422 Jan 3, 2023
422 Jan 3, 2023

TensorFlow code for the neural network presented in the paper: "Structural Language Models of Code" (ICML'2020)
SLM: Structural Language Models of Code This is an official implementation of the model described in: "Structural Language Models of Code" [PDF] To ap
 73 Nov 6, 2022
73 Nov 6, 2022

中文语音识别系列,读者可以借助它快速训练属于自己的中文语音识别模型,或直接使用预训练模型测试效果。
MASR中文语音识别(pytorch版) 开箱即用 自行训练 使用与训练分离(增量训练) 识别率高 说明:因为每个人电脑机器不同,而且有些安装包安装起来比较麻烦,强烈建议直接用我编译好的docker环境跑 目前docker基础环境为ubuntu-cuda10.1-cudnn7-pytorch1.6.
 180 Dec 17, 2022
180 Dec 17, 2022

(under submission) Bayesian Integration of a Generative Prior for Image Restoration
BIGPrior: Towards Decoupling Learned Prior Hallucination and Data Fidelity in Image Restoration Authors: Majed El Helou, and Sabine Süsstrunk {Note: p
 22 Dec 17, 2022
22 Dec 17, 2022
Uncertain natural language inference
Uncertain Natural Language Inference This repository hosts the code for the following paper: Tongfei Chen*, Zhengping Jiang*, Adam Poliak, Keisuke Sak
 14 Sep 1, 2022
14 Sep 1, 2022

Code for the paper Language as a Cognitive Tool to Imagine Goals in Curiosity Driven Exploration
IMAGINE: Language as a Cognitive Tool to Imagine Goals in Curiosity Driven Exploration This repo contains the code base of the paper Language as a Cog
 26 Dec 22, 2022
26 Dec 22, 2022

ReText: Simple but powerful editor for Markdown and reStructuredText
Welcome to ReText! ReText is a simple but powerful editor for Markdown and reStructuredText markup languages. One can also add support for custom mark
 1.6k Dec 23, 2022
1.6k Dec 23, 2022

Komodo Edit is a fast and free multi-language code editor. Written in JS, Python, C++ and based on the Mozilla platform.
Komodo Edit This readme explains how to get started building, using and developing with the Komodo Edit source base. Whilst the main Komodo Edit sourc
 2k Dec 28, 2022
2k Dec 28, 2022

A collection of full-stack resources for programmers.
A collection of full-stack resources for programmers.
 22.3k Dec 30, 2022
22.3k Dec 30, 2022

Deep generative modeling for time-stamped heterogeneous data, enabling high-fidelity models for a large variety of spatio-temporal domains.
Neural Spatio-Temporal Point Processes [arxiv] Ricky T. Q. Chen, Brandon Amos, Maximilian Nickel Abstract. We propose a new class of parameterizations
75 Dec 19, 2022
Official code of our work, Unified Pre-training for Program Understanding and Generation [NAACL 2021].
PLBART Code pre-release of our work, Unified Pre-training for Program Understanding and Generation accepted at NAACL 2021. Note. A detailed documentat
 138 Dec 30, 2022
138 Dec 30, 2022
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
 10.9k Jan 9, 2023
10.9k Jan 9, 2023
ProxyLogon Pre-Auth SSRF To Arbitrary File Write
ProxyLogon Pre-Auth SSRF To Arbitrary File Write For Education and Research Usage: C:\python proxylogon.py mail.evil.corp [email protected] At
 117 Nov 28, 2022
117 Nov 28, 2022
The swas programming language
The Swas programming language This is a language that was made for fun. Installation Step 0: Make sure you have python installed Step 1. Clone this re
 19 Jul 18, 2022
19 Jul 18, 2022

Code for ICLR 2021 Paper, "Anytime Sampling for Autoregressive Models via Ordered Autoencoding"
Anytime Autoregressive Model Anytime Sampling for Autoregressive Models via Ordered Autoencoding , ICLR 21 Yilun Xu, Yang Song, Sahaj Gara, Linyuan Go
 22 Sep 8, 2022
22 Sep 8, 2022
![[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator](https://github.com/d-li14/involution/raw/main/fig/involution.png)
[CVPR 2021] Involution: Inverting the Inherence of Convolution for Visual Recognition, a brand new neural operator
involution Official implementation of a neural operator as described in Involution: Inverting the Inherence of Convolution for Visual Recognition (CVP
 1.3k Dec 28, 2022
1.3k Dec 28, 2022
![[CVPR2021 Oral] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers](https://github.com/dddzg/up-detr/raw/master/.github/UP-DETR.png)
[CVPR2021 Oral] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers This is the official PyTorch implementation and models for UP-DETR paper: @a
 430 Dec 23, 2022
430 Dec 23, 2022
Beyond the Imitation Game collaborative benchmark for enormous language models
BIG-bench 🪑 The Beyond the Imitation Game Benchmark (BIG-bench) will be a collaborative benchmark intended to probe large language models, and extrap
 1.3k Jan 1, 2023
1.3k Jan 1, 2023
Scripts of Machine Learning Algorithms from Scratch. Implementations of machine learning models and algorithms using nothing but NumPy with a focus on accessibility. Aims to cover everything from basic to advance.
Algo-ScriptML Python implementations of some of the fundamental Machine Learning models and algorithms from scratch. The goal of this project is not t
 81 Nov 26, 2022
81 Nov 26, 2022
Django project starter on steroids: quickly create a Django app AND generate source code for data models + REST/GraphQL APIs (the generated code is auto-linted and has 100% test coverage).
Create Django App 💛 We're a Django project starter on steroids! One-line command to create a Django app with all the dependencies auto-installed AND
 68 Oct 19, 2022
68 Oct 19, 2022
Code associated with the "Data Augmentation using Pre-trained Transformer Models" paper
Data Augmentation using Pre-trained Transformer Models Code associated with the Data Augmentation using Pre-trained Transformer Models paper Code cont
 44 Dec 31, 2022
44 Dec 31, 2022
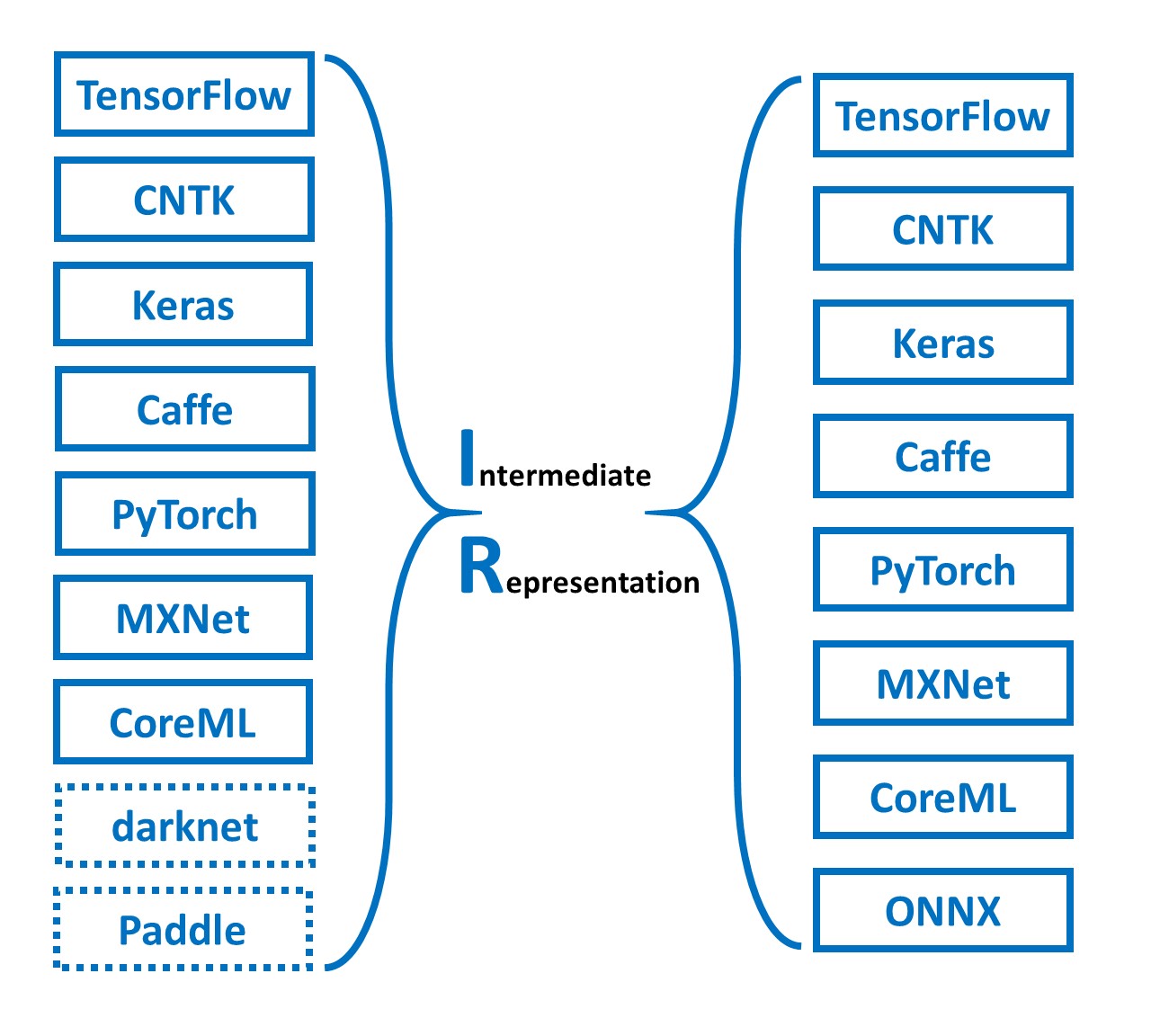
MMdnn is a set of tools to help users inter-operate among different deep learning frameworks. E.g. model conversion and visualization. Convert models between Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx and CoreML.
MMdnn MMdnn is a comprehensive and cross-framework tool to convert, visualize and diagnose deep learning (DL) models. The "MM" stands for model manage
5.7k Jan 9, 2023
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. Flair is: A powerful NLP library. Flair allo
 12.3k Jan 2, 2023
12.3k Jan 2, 2023
A library for hidden semi-Markov models with explicit durations
hsmmlearn hsmmlearn is a library for unsupervised learning of hidden semi-Markov models with explicit durations. It is a port of the hsmm package for
 69 Dec 20, 2022
69 Dec 20, 2022
Scikit-learn compatible estimation of general graphical models
skggm : Gaussian graphical models using the scikit-learn API In the last decade, learning networks that encode conditional independence relationships
213 Jan 2, 2023

Visualizer for neural network, deep learning, and machine learning models
Netron is a viewer for neural network, deep learning and machine learning models. Netron supports ONNX (.onnx, .pb, .pbtxt), Keras (.h5, .keras), Tens
 20.9k Dec 28, 2022
20.9k Dec 28, 2022
Interpretability and explainability of data and machine learning models
AI Explainability 360 (v0.2.1) The AI Explainability 360 toolkit is an open-source library that supports interpretability and explainability of datase
 1.2k Dec 29, 2022
1.2k Dec 29, 2022
FairML - is a python toolbox auditing the machine learning models for bias.
======== FairML: Auditing Black-Box Predictive Models FairML is a python toolbox auditing the machine learning models for bias. Description Predictive
 338 Nov 9, 2022
338 Nov 9, 2022
Algorithms for monitoring and explaining machine learning models
Alibi is an open source Python library aimed at machine learning model inspection and interpretation. The focus of the library is to provide high-qual
 1.9k Dec 30, 2022
1.9k Dec 30, 2022
NLP made easy
GluonNLP: Your Choice of Deep Learning for NLP GluonNLP is a toolkit that helps you solve NLP problems. It provides easy-to-use tools that helps you l
 2.5k Jan 4, 2023
2.5k Jan 4, 2023

Ludwig is a toolbox that allows to train and evaluate deep learning models without the need to write code.
Translated in 🇰🇷 Korean/ Ludwig is a toolbox that allows users to train and test deep learning models without the need to write code. It is built on
 8.7k Dec 31, 2022
8.7k Dec 31, 2022
📝 Wrapper library for text generation / language models at char and word level with RNN in TensorFlow
tensorlm Generate Shakespeare poems with 4 lines of code. Installation tensorlm is written in / for Python 3.4+ and TensorFlow 1.1+ pip3 install tenso
 63 May 22, 2021
63 May 22, 2021
Datasets, Transforms and Models specific to Computer Vision
torchvision The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. Installat
 13.1k Jan 2, 2023
13.1k Jan 2, 2023
Home repository for the Regularized Greedy Forest (RGF) library. It includes original implementation from the paper and multithreaded one written in C++, along with various language-specific wrappers.
Regularized Greedy Forest Regularized Greedy Forest (RGF) is a tree ensemble machine learning method described in this paper. RGF can deliver better r
 363 Dec 14, 2022
363 Dec 14, 2022
Probabilistic programming framework that facilitates objective model selection for time-varying parameter models.
Time series analysis today is an important cornerstone of quantitative science in many disciplines, including natural and life sciences as well as eco
 129 Dec 24, 2022
129 Dec 24, 2022
![[HELP REQUESTED] Generalized Additive Models in Python](https://github.com/dswah/pyGAM/raw/master/imgs/pygam_tensor.png)
[HELP REQUESTED] Generalized Additive Models in Python
pyGAM Generalized Additive Models in Python. Documentation Official pyGAM Documentation: Read the Docs Building interpretable models with Generalized
 747 Jan 5, 2023
747 Jan 5, 2023