945 Repositories
Python styleGAN2-ADA-training-jupyter Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

"SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image", Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Humphrey Shi, Zhangyang Wang
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image [Paper] [Website] Pipeline Code Environment pip install -r requirements
 250 Jan 5, 2023
250 Jan 5, 2023

Official implementation for "Style Transformer for Image Inversion and Editing" (CVPR 2022)
Style Transformer for Image Inversion and Editing (CVPR2022) https://arxiv.org/abs/2203.07932 Existing GAN inversion methods fail to provide latent co
 153 Dec 2, 2022
153 Dec 2, 2022
✨ Real-life Data Analysis and Model Training Workshop by Global AI Hub.
🎓 Data Analysis and Model Training Course by Global AI Hub Syllabus: Day 1 What is Data? Multimedia Structured and Unstructured Data Data Types Data
 71 Oct 28, 2022
71 Oct 28, 2022
![[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception](https://github.com/hongfz16/HCMoCo/raw/main/assets/teaser.png)
[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception
Versatile Multi-Modal Pre-Training for Human-Centric Perception Fangzhou Hong1 Liang Pan1 Zhongang Cai1,2,3 Ziwei Liu1* 1S-Lab, Nanyang Technologic
 96 Jan 3, 2023
96 Jan 3, 2023
CLOOB training (JAX) and inference (JAX and PyTorch)
cloob-training Pretrained models There are two pretrained CLOOB models in this repo at the moment, a 16 epoch and a 32 epoch ViT-B/16 checkpoint train
 64 Nov 27, 2022
64 Nov 27, 2022
Display your data in an attractive way in your notebook!
Bloxs Bloxs is a simple python package that helps you display information in an attractive way (formed in blocks). Perfect for building dashboards, re
 192 Dec 28, 2022
192 Dec 28, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022
Example notebooks for working with SageMaker Studio Lab. Sign up for an account at the link below!
SageMaker Studio Lab Sample Notebooks Available today in public preview. If you are looking for a no-cost compute environment to run Jupyter notebooks
 304 Jan 1, 2023
304 Jan 1, 2023

Learn the basics of Python. These tutorials are for Python beginners. so even if you have no prior knowledge of Python, you won’t face any difficulty understanding these tutorials.
01_Python_Introduction Introduction 👋 Python is a modern, robust, high level programming language. It is very easy to pick up even if you are complet
 245 Dec 30, 2022
245 Dec 30, 2022
A series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in Python using Scikit-Learn, Keras and TensorFlow 2.
Machine Learning Notebooks, 3rd edition This project aims at teaching you the fundamentals of Machine Learning in python. It contains the example code
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
Flow control is the order in which statements or blocks of code are executed at runtime based on a condition. Learn Conditional statements, Iterative statements, and Transfer statements
03_Python_Flow_Control Introduction 👋 The control flow statements are an essential part of the Python programming language. A control flow statement
209 Oct 31, 2022
My Solutions to 120 commonly asked data science interview questions.
Data_Science_Interview_Questions Introduction 👋 Here are the answers to 120 Data Science Interview Questions The above answer some is modified based
181 Dec 31, 2022
This repository contains Python games that I've worked on. You'll learn how to create python games with AI. I try to focus on creating board games without GUI in Jupyter-notebook.
92_Python_Games 🎮 Introduction 👋 This repository contains Python games that I've worked on. You'll learn how to create python games with AI. I try t
166 Jan 1, 2023
Jupyter Dock is a set of Jupyter Notebooks for performing molecular docking protocols interactively, as well as visualizing, converting file formats and analyzing the results.
Molecular Docking integrated in Jupyter Notebooks Description | Citation | Installation | Examples | Limitations | License Table of content Descriptio
 173 Dec 25, 2022
173 Dec 25, 2022
Implementation of RITA (Real Intelligence Threat Analytics) in Jupyter Notebook with improved scoring algorithm.
RITA (Real Intelligence Threat Analytics) in Jupyter Notebook RITA is an open source framework for network traffic analysis sponsored by Active Counte
 157 Nov 24, 2022
157 Nov 24, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022

Coreference resolution for English, French, German and Polish, optimised for limited training data and easily extensible for further languages
Coreferee Author: Richard Paul Hudson, Explosion AI 1. Introduction 1.1 The basic idea 1.2 Getting started 1.2.1 English 1.2.2 French 1.2.3 German 1.2
 70 Dec 12, 2022
70 Dec 12, 2022

Detecting silent model failure. NannyML estimates performance with an algorithm called Confidence-based Performance estimation (CBPE), developed by core contributors. It is the only open-source algorithm capable of fully capturing the impact of data drift on performance.
Website • Docs • Community Slack 💡 What is NannyML? NannyML is an open-source python library that allows you to estimate post-deployment model perfor
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
Repository for training material for the 2022 SDSC HPC/CI User Training Course
hpc-training-2022 Repository for training material for the 2022 SDSC HPC/CI Training Series HPC/CI Training Series home https://www.sdsc.edu/event_ite
 21 Jul 27, 2022
21 Jul 27, 2022

Easy Parallel Library (EPL) is a general and efficient deep learning framework for distributed model training.
English | 简体中文 Easy Parallel Library Overview Easy Parallel Library (EPL) is a general and efficient library for distributed model training. Usability
 185 Dec 21, 2022
185 Dec 21, 2022

code for TCL: Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022
Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022 News (03/16/2022) upload retrieval checkpoints finetuned on COCO and Flickr T
 187 Jan 2, 2023
187 Jan 2, 2023
Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along with material in the form of Jupyter Notebooks.
Databricks Certification Spark Databricks Certified Associate Spark Developer preparation toolkit to setup single node Standalone Spark Cluster along
 19 Dec 13, 2022
19 Dec 13, 2022
Containerized Demo of Apache Spark MLlib on a Data Lakehouse (2022)
Spark-DeltaLake-Demo Reliable, Scalable Machine Learning (2022) This project was completed in an attempt to become better acquainted with the latest b
 8 Mar 21, 2022
8 Mar 21, 2022
torchlm is aims to build a high level pipeline for face landmarks detection, it supports training, evaluating, exporting, inference(Python/C++) and 100+ data augmentations
💎A high level pipeline for face landmarks detection, supports training, evaluating, exporting, inference and 100+ data augmentations, compatible with torchvision and albumentations, can easily install with pip.
 142 Dec 25, 2022
142 Dec 25, 2022

Responsible AI Workshop: a series of tutorials & walkthroughs to illustrate how put responsible AI into practice
Responsible AI Workshop Responsible innovation is top of mind. As such, the tech industry as well as a growing number of organizations of all kinds in
 9 Sep 14, 2022
9 Sep 14, 2022

As-ViT: Auto-scaling Vision Transformers without Training
As-ViT: Auto-scaling Vision Transformers without Training [PDF] Wuyang Chen, Wei Huang, Xianzhi Du, Xiaodan Song, Zhangyang Wang, Denny Zhou In ICLR 2
68 Sep 5, 2022

Machine learning beginner to Kaggle competitor in 30 days. Non-coders welcome. The program starts Monday, August 2, and lasts four weeks. It's designed for people who want to learn machine learning.
30-Days-of-ML-Kaggle 🔥 About the Hands On Program 💻 Machine learning beginner → Kaggle competitor in 30 days. Non-coders welcome The program starts
 145 Jan 1, 2023
145 Jan 1, 2023
Get started with Machine Learning with Python - An introduction with Python programming examples
Machine Learning With Python Get started with Machine Learning with Python An engaging introduction to Machine Learning with Python TL;DR Download all
 130 Jan 2, 2023
130 Jan 2, 2023

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022
🏎️ Accelerate training and inference of 🤗 Transformers with easy to use hardware optimization tools
Hugging Face Optimum 🤗 Optimum is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to t
 842 Dec 30, 2022
842 Dec 30, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

ipyvizzu - Jupyter notebook integration of Vizzu
ipyvizzu - Jupyter notebook integration of Vizzu. Tutorial · Examples · Repository About The Project ipyvizzu is the Jupyter Notebook integration of V
 729 Jan 8, 2023
729 Jan 8, 2023

Code of paper: "DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks"
DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks Abstract: Adversarial training has been proven to
 58 Nov 10, 2022
58 Nov 10, 2022
Potato Disease Classification - Training, Rest APIs, and Frontend to test.
Potato Disease Classification Setup for Python: Install Python (Setup instructions) Install Python packages pip3 install -r training/requirements.txt
 95 Dec 21, 2022
95 Dec 21, 2022
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
TorchMultimodal (Alpha Release) Introduction TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
 663 Jan 6, 2023
663 Jan 6, 2023

PromptDet: Expand Your Detector Vocabulary with Uncurated Images
PromptDet: Expand Your Detector Vocabulary with Uncurated Images Paper Website Introduction The goal of this work is to establish a scalable pipeline
 103 Dec 20, 2022
103 Dec 20, 2022
Code for our paper "Graph Pre-training for AMR Parsing and Generation" in ACL2022
AMRBART An implementation for ACL2022 paper "Graph Pre-training for AMR Parsing and Generation". You may find our paper here (Arxiv). Requirements pyt
 60 Jan 3, 2023
60 Jan 3, 2023
![[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators](https://github.com/microsoft/AMOS/raw/main/AMOS.png)
[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
AMOS This repository contains the scripts for fine-tuning AMOS pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: Pretraining Text Encoders wi
22 Sep 15, 2022

Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
beyond masking Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers The code is coming Figure 1: Pipeline of token-based pre-
 23 Sep 27, 2022
23 Sep 27, 2022
Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL)
LUPerson-NL Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL) The repository is for our CVPR2022 paper Large-Scale
 43 Dec 26, 2022
43 Dec 26, 2022

SIGIR'22 paper: Axiomatically Regularized Pre-training for Ad hoc Search
Introduction This codebase contains source-code of the Python-based implementation (ARES) of our SIGIR 2022 paper. Chen, Jia, et al. "Axiomatically Re
 17 Nov 9, 2022
17 Nov 9, 2022

CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
CLIP-GEN [简体中文][English] 本项目在萤火二号集群上用 PyTorch 实现了论文 《CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP》。 CLIP-GEN 是一个 Language-F
 75 Dec 29, 2022
75 Dec 29, 2022
DeepGNN is a framework for training machine learning models on large scale graph data.
DeepGNN Overview DeepGNN is a framework for training machine learning models on large scale graph data. DeepGNN contains all the necessary features in
45 Jan 1, 2023
Aiming at the common training datsets split, spectrum preprocessing, wavelength select and calibration models algorithm involved in the spectral analysis process
Aiming at the common training datsets split, spectrum preprocessing, wavelength select and calibration models algorithm involved in the spectral analysis process, a complete algorithm library is established, which is named opensa (openspectrum analysis).
 50 Jan 7, 2023
50 Jan 7, 2023

Princeton NLP's pre-training library based on fairseq with DeepSpeed kernel integration 🚃
This repository provides a library for efficient training of masked language models (MLM), built with fairseq. We fork fairseq to give researchers mor
 92 Dec 27, 2022
92 Dec 27, 2022
Code for our SIGIR 2022 accepted paper : P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-based Learning and Pre-finetuning
P3 Ranker Implementation for our SIGIR2022 accepted paper: P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-bas
 14 Jan 4, 2023
14 Jan 4, 2023

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
Implementaion of our ACL 2022 paper Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation This is the implementaion of our paper: Bridging the
 20 Dec 12, 2022
20 Dec 12, 2022
Repository for DNN training, theory to practice, part of the Large Scale Machine Learning class at Mines Paritech
DNN Training, from theory to practice This repository is complementary to the deep learning training lesson given to les Mines ParisTech on the 11th o
 6 Nov 14, 2022
6 Nov 14, 2022
![[CVPR 2022]](https://github.com/VITA-Group/Diverse-ViT/raw/main/Figs/Diversity_overview.png)
[CVPR 2022] "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy" by Tianlong Chen, Zhenyu Zhang, Yu Cheng, Ahmed Awadallah, Zhangyang Wang
The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy Codes for this paper: [CVPR 2022] The Pr
16 Nov 26, 2022
Architecture Patterns with Python (TDD, DDD, EDM)
architecture-traning Architecture Patterns with Python (TDD, DDD, EDM) Chapter 5. 높은 기어비와 낮은 기어비의 TDD 5.2 도메인 계층 테스트를 서비스 계층으로 옮겨야 하는가? 도메인 계층 테스트 def
 2 Mar 4, 2022
2 Mar 4, 2022
Jupyter notebooks showing best practices for using cx_Oracle, the Python DB API for Oracle Database
Python cx_Oracle Notebooks, 2022 The repository contains Jupyter notebooks showing best practices for using cx_Oracle, the Python DB API for Oracle Da
 13 Dec 15, 2022
13 Dec 15, 2022

E2e music remastering system - End-to-end Music Remastering System Using Self-supervised and Adversarial Training
End-to-end Music Remastering System This repository includes source code and pre
 37 Dec 15, 2022
37 Dec 15, 2022
Super-Fast-Adversarial-Training - A PyTorch Implementation code for developing super fast adversarial training
Super-Fast-Adversarial-Training This is a PyTorch Implementation code for develo
 26 Dec 2, 2022
26 Dec 2, 2022

HashNeRF-pytorch - Pure PyTorch Implementation of NVIDIA paper on Instant Training of Neural Graphics primitives
HashNeRF-pytorch Instant-NGP recently introduced a Multi-resolution Hash Encodin
 616 Jan 6, 2023
616 Jan 6, 2023

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022

The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training
[ICLR 2022] The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training The Unreasonable Effectiveness of
44 Dec 23, 2022
LyaNet: A Lyapunov Framework for Training Neural ODEs
LyaNet: A Lyapunov Framework for Training Neural ODEs Provide the model type--config-name to train and test models configured as those shown in the pa
 21 Nov 21, 2022
21 Nov 21, 2022
This is the replication package for paper submission: Towards Training Reproducible Deep Learning Models.
This is the replication package for paper submission: Towards Training Reproducible Deep Learning Models.
 0 Feb 2, 2022
0 Feb 2, 2022

This repository contains some analysis of possible nerdle answers
Nerdle Analysis https://nerdlegame.com/ This repository contains some analysis of possible nerdle answers. Here's a quick overview: nerdle.py contains
 0 Dec 16, 2022
0 Dec 16, 2022
Customizing Visual Styles in Plotly
Customizing Visual Styles in Plotly Code for a workshop originally developed for an Unconference session during the Outlier Conference hosted by Data
 9 Aug 3, 2022
9 Aug 3, 2022

Price Prediction model is used to develop an LSTM model to predict the future market price of Bitcoin and Ethereum.
Price Prediction model is used to develop an LSTM model to predict the future market price of Bitcoin and Ethereum.
 2 Jun 14, 2022
2 Jun 14, 2022

A research of IT labor market based especially on hh.ru. Salaries, rate of technologies and etc.
hh_ru_research Проект реализован в учебных целях анализа рынка труда, в особенности по hh.ru Input data В качестве входных данных используются сериали
 3 Sep 7, 2022
3 Sep 7, 2022

To build a regression model to predict the concrete compressive strength based on the different features in the training data.
Cement-Strength-Prediction Problem Statement To build a regression model to predict the concrete compressive strength based on the different features
 4 Jun 11, 2022
4 Jun 11, 2022
Contains a Jupyter Notebook for calculating remaining plants required based on field/lathhouse data.
Davis-Sunflowers-Su21 Project goals: Plants influence their reproduction and mating system in many ways. Various factors such as time of flowering, ab
 1 Feb 10, 2022
1 Feb 10, 2022
A training task for web scraping using python multithreading and a real-time-updated list of available proxy servers.
Parallel web scraping The project is a training task for web scraping using python multithreading and a real-time-updated list of available proxy serv
 1 Feb 10, 2022
1 Feb 10, 2022

Official code of Retinal Vessel Segmentation with Pixel-wise Adaptive Filters and Consistency Training
Official code of Retinal Vessel Segmentation with Pixel-wise Adaptive Filters and Consistency Training (ISBI 2022)
 7 Feb 10, 2022
7 Feb 10, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
Visualize a molecule and its conformations in Jupyter notebooks/lab using py3dmol
Mol Viewer This is a simple package wrapping py3dmol for a single command visualization of a RDKit molecule and its conformations (embed as Conformer
 1 Feb 11, 2022
1 Feb 11, 2022
FewBit — a library for memory efficient training of large neural networks
FewBit FewBit — a library for memory efficient training of large neural networks. Its efficiency originates from storage optimizations applied to back
 24 Oct 22, 2022
24 Oct 22, 2022
Code for the tech report Toward Training at ImageNet Scale with Differential Privacy
Differentially private Imagenet training Code for the tech report Toward Training at ImageNet Scale with Differential Privacy by Alexey Kurakin, Steve
 29 Nov 3, 2022
29 Nov 3, 2022

Official PyTorch implementation of the paper "Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory (SB-FBSDE)"
Official PyTorch implementation of the paper "Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory (SB-FBSDE)" which introduces a new class of deep generative models that generalizes score-based models to fully nonlinear forward and backward diffusions.
 43 Jan 3, 2023
43 Jan 3, 2023
This repository provides an efficient PyTorch-based library for training deep models.
An Efficient Library for Training Deep Models This repository provides an efficient PyTorch-based library for training deep models. Installation Make
 123 Jan 5, 2023
123 Jan 5, 2023
A collection of Jupyter notebooks to play with NVIDIA's StyleGAN3 and OpenAI's CLIP for a text-based guided image generation.
StyleGAN3 CLIP-based guidance StyleGAN3 + CLIP StyleGAN3 + inversion + CLIP This repo is a collection of Jupyter notebooks made to easily play with St
 176 Dec 30, 2022
176 Dec 30, 2022

A web porting for NVlabs' StyleGAN2, to facilitate exploring all kinds characteristic of StyleGAN networks
This project is a web porting for NVlabs' StyleGAN2, to facilitate exploring all kinds characteristic of StyleGAN networks. Thanks for NVlabs' excelle
 150 Dec 15, 2022
150 Dec 15, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

A curated list of Machine Learning and Deep Learning tutorials in Jupyter Notebook format ready to run in Google Colaboratory
Awesome Machine Learning Jupyter Notebooks for Google Colaboratory A curated list of Machine Learning and Deep Learning tutorials in Jupyter Notebook
 245 Jan 1, 2023
245 Jan 1, 2023
Human segmentation models, training/inference code, and trained weights, implemented in PyTorch
Human-Segmentation-PyTorch Human segmentation models, training/inference code, and trained weights, implemented in PyTorch. Supported networks UNet: b
 474 Dec 19, 2022
474 Dec 19, 2022
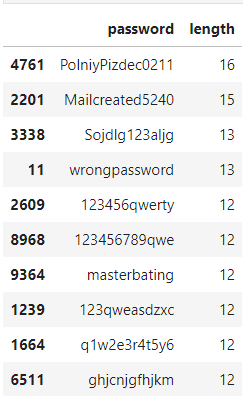
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
Analysis of a dataset of 10000 passwords to find common trends and mistakes people generally make while setting up a password.
 7 Sep 4, 2022
7 Sep 4, 2022

For educational purposes, a simple script that assists in solving the word game Wordle.
WordleSolver For educational purposes, a simple script that assists in solving the word game Wordle. Instructions Pick your first word from the sugges
 2 Mar 25, 2022
2 Mar 25, 2022
Data from "Datamodels: Predicting Predictions with Training Data"
Data from "Datamodels: Predicting Predictions with Training Data" Here we provid
 51 Dec 9, 2022
51 Dec 9, 2022
Training a deep learning model on the noisy CIFAR dataset
Training-a-deep-learning-model-on-the-noisy-CIFAR-dataset This repository contai
 1 Jun 14, 2022
1 Jun 14, 2022

Jupyter notebooks and AWS CloudFormation template to show how Hudi, Iceberg, and Delta Lake work
Modern Data Lake Storage Layers This repository contains supporting assets for my research in modern Data Lake storage layers like Apache Hudi, Apache
 25 Oct 31, 2022
25 Oct 31, 2022
Simple codebase for flexible neural net training
neural-modular Simple codebase for flexible neural net training. Allows for seamless exchange of models, dataset, and optimizers. Uses hydra for confi
 7 Apr 5, 2022
7 Apr 5, 2022
This is an early in-development version of training CLIP models with hivemind.
A transformer that does not hog your GPU memory This is an early in-development codebase: if you want a stable and documented hivemind codebase, look
 4 Nov 6, 2022
4 Nov 6, 2022

A Sign Language detection project using Mediapipe landmark detection and Tensorflow LSTM's
sign-language-detection A Sign Language detection project using Mediapipe landmark detection and Tensorflow LSTM. The project is built for a vocabular
 4 Feb 6, 2022
4 Feb 6, 2022

Convert monolithic Jupyter notebooks into Ploomber pipelines.
Soorgeon Join our community | Newsletter | Contact us | Blog | Website | YouTube Convert monolithic Jupyter notebooks into Ploomber pipelines. soorgeo
 65 Dec 16, 2022
65 Dec 16, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity
[ICLR 2022] Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity by Shiwei Liu, Tianlong Chen, Zahra Atashgahi, Xiaohan Chen, Ghada Sokar, Elena Mocanu, Mykola Pechenizkiy, Zhangyang Wang, Decebal Constantin Mocanu
18 Dec 31, 2022
This is an implementation example of a bot that periodically sends predictions to the alphasea-agent.
alphasea-example-model alphasea-example-modelは、 alphasea-agent に対して毎ラウンド、予測を投稿するプログラムです。 Numeraiのexample modelに相当します。 準備 alphasea-example-modelの動作には、
 11 Jul 28, 2022
11 Jul 28, 2022

A Python Jupyter Kernel in Slack. Just send Python code as a message.
Slack IPython bot 🤯 One Slack bot to rule them all. PyBot. Just send Python code as a message. Install pip install slack-ipython To start the bot, si
 44 May 23, 2022
44 May 23, 2022
Computer Vision Paper Reviews with Key Summary of paper, End to End Code Practice and Jupyter Notebook converted papers
Computer-Vision-Paper-Reviews Computer Vision Paper Reviews with Key Summary along Papers & Codes. Jonathan Choi 2021 The repository provides 100+ Pap
 2 Mar 17, 2022
2 Mar 17, 2022
Training DiffWave using variational method from Variational Diffusion Models.
Variational DiffWave Training DiffWave using variational method from Variational Diffusion Models. Quick Start python train_distributed.py discrete_10
 26 Dec 13, 2022
26 Dec 13, 2022
BaseCls BaseCls 是一个基于 MegEngine 的预训练模型库,帮助大家挑选或训练出更适合自己科研或者业务的模型结构
BaseCls BaseCls 是一个基于 MegEngine 的预训练模型库,帮助大家挑选或训练出更适合自己科研或者业务的模型结构。 文档地址:https://basecls.readthedocs.io 安装 安装环境 BaseCls 需要 Python = 3.6。 BaseCls 依赖 M
 28 Dec 23, 2022
28 Dec 23, 2022
JASS: Japanese-specific Sequence to Sequence Pre-training for Neural Machine Translation
JASS: Japanese-specific Sequence to Sequence Pre-training for Neural Machine Translation This the repository for this paper. Find extensions of this w
 14 Oct 26, 2022
14 Oct 26, 2022