848 Repositories
Python training-pipeline Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

"SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image", Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Humphrey Shi, Zhangyang Wang
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image [Paper] [Website] Pipeline Code Environment pip install -r requirements
 250 Jan 5, 2023
250 Jan 5, 2023
✨ Real-life Data Analysis and Model Training Workshop by Global AI Hub.
🎓 Data Analysis and Model Training Course by Global AI Hub Syllabus: Day 1 What is Data? Multimedia Structured and Unstructured Data Data Types Data
 71 Oct 28, 2022
71 Oct 28, 2022

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
 115 Dec 16, 2022
115 Dec 16, 2022
![[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception](https://github.com/hongfz16/HCMoCo/raw/main/assets/teaser.png)
[CVPR 2022 Oral] Versatile Multi-Modal Pre-Training for Human-Centric Perception
Versatile Multi-Modal Pre-Training for Human-Centric Perception Fangzhou Hong1 Liang Pan1 Zhongang Cai1,2,3 Ziwei Liu1* 1S-Lab, Nanyang Technologic
 96 Jan 3, 2023
96 Jan 3, 2023
CLOOB training (JAX) and inference (JAX and PyTorch)
cloob-training Pretrained models There are two pretrained CLOOB models in this repo at the moment, a 16 epoch and a 32 epoch ViT-B/16 checkpoint train
 64 Nov 27, 2022
64 Nov 27, 2022
Example notebooks for working with SageMaker Studio Lab. Sign up for an account at the link below!
SageMaker Studio Lab Sample Notebooks Available today in public preview. If you are looking for a no-cost compute environment to run Jupyter notebooks
 304 Jan 1, 2023
304 Jan 1, 2023

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022

Coreference resolution for English, French, German and Polish, optimised for limited training data and easily extensible for further languages
Coreferee Author: Richard Paul Hudson, Explosion AI 1. Introduction 1.1 The basic idea 1.2 Getting started 1.2.1 English 1.2.2 French 1.2.3 German 1.2
 70 Dec 12, 2022
70 Dec 12, 2022
Repository for training material for the 2022 SDSC HPC/CI User Training Course
hpc-training-2022 Repository for training material for the 2022 SDSC HPC/CI Training Series HPC/CI Training Series home https://www.sdsc.edu/event_ite
 21 Jul 27, 2022
21 Jul 27, 2022

Easy Parallel Library (EPL) is a general and efficient deep learning framework for distributed model training.
English | 简体中文 Easy Parallel Library Overview Easy Parallel Library (EPL) is a general and efficient library for distributed model training. Usability
 185 Dec 21, 2022
185 Dec 21, 2022

code for TCL: Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022
Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022 News (03/16/2022) upload retrieval checkpoints finetuned on COCO and Flickr T
 187 Jan 2, 2023
187 Jan 2, 2023
![[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)](https://github.com/cheng-01037/Causality-Medical-Image-Domain-Generalization/raw/main/intro.png)
[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation Arxiv preprint Repository under construction. Might still be bug
 31 Dec 27, 2022
31 Dec 27, 2022
torchlm is aims to build a high level pipeline for face landmarks detection, it supports training, evaluating, exporting, inference(Python/C++) and 100+ data augmentations
💎A high level pipeline for face landmarks detection, supports training, evaluating, exporting, inference and 100+ data augmentations, compatible with torchvision and albumentations, can easily install with pip.
 142 Dec 25, 2022
142 Dec 25, 2022
Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogramas anuais com spark, em pyspark e SQL!
Olá! Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogr
 10 Apr 4, 2022
10 Apr 4, 2022

As-ViT: Auto-scaling Vision Transformers without Training
As-ViT: Auto-scaling Vision Transformers without Training [PDF] Wuyang Chen, Wei Huang, Xianzhi Du, Xiaodan Song, Zhangyang Wang, Denny Zhou In ICLR 2
68 Sep 5, 2022

CLIP (Contrastive Language–Image Pre-training) for Italian
Italian CLIP CLIP (Radford et al., 2021) is a multimodal model that can learn to represent images and text jointly in the same space. In this project,
 114 Dec 29, 2022
114 Dec 29, 2022

Open-source data observability for modern data teams
Use cases Monitor your data warehouse in minutes: Data anomalies monitoring as dbt tests Data lineage made simple, reliable, and automated dbt operati
 889 Jan 1, 2023
889 Jan 1, 2023
🏎️ Accelerate training and inference of 🤗 Transformers with easy to use hardware optimization tools
Hugging Face Optimum 🤗 Optimum is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to t
 842 Dec 30, 2022
842 Dec 30, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023

Code of paper: "DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks"
DropAttack: A Masked Weight Adversarial Training Method to Improve Generalization of Neural Networks Abstract: Adversarial training has been proven to
 58 Nov 10, 2022
58 Nov 10, 2022
Potato Disease Classification - Training, Rest APIs, and Frontend to test.
Potato Disease Classification Setup for Python: Install Python (Setup instructions) Install Python packages pip3 install -r training/requirements.txt
 95 Dec 21, 2022
95 Dec 21, 2022
TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
TorchMultimodal (Alpha Release) Introduction TorchMultimodal is a PyTorch library for training state-of-the-art multimodal multi-task models at scale.
 663 Jan 6, 2023
663 Jan 6, 2023

PromptDet: Expand Your Detector Vocabulary with Uncurated Images
PromptDet: Expand Your Detector Vocabulary with Uncurated Images Paper Website Introduction The goal of this work is to establish a scalable pipeline
 103 Dec 20, 2022
103 Dec 20, 2022
Code for our paper "Graph Pre-training for AMR Parsing and Generation" in ACL2022
AMRBART An implementation for ACL2022 paper "Graph Pre-training for AMR Parsing and Generation". You may find our paper here (Arxiv). Requirements pyt
 60 Jan 3, 2023
60 Jan 3, 2023
![[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators](https://github.com/microsoft/AMOS/raw/main/AMOS.png)
[ICLR 2022] Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
AMOS This repository contains the scripts for fine-tuning AMOS pretrained models on GLUE and SQuAD 2.0 benchmarks. Paper: Pretraining Text Encoders wi
 22 Sep 15, 2022
22 Sep 15, 2022

Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
beyond masking Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers The code is coming Figure 1: Pipeline of token-based pre-
 23 Sep 27, 2022
23 Sep 27, 2022
Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL)
LUPerson-NL Large-Scale Pre-training for Person Re-identification with Noisy Labels (LUPerson-NL) The repository is for our CVPR2022 paper Large-Scale
 43 Dec 26, 2022
43 Dec 26, 2022

SIGIR'22 paper: Axiomatically Regularized Pre-training for Ad hoc Search
Introduction This codebase contains source-code of the Python-based implementation (ARES) of our SIGIR 2022 paper. Chen, Jia, et al. "Axiomatically Re
 17 Nov 9, 2022
17 Nov 9, 2022

CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
CLIP-GEN [简体中文][English] 本项目在萤火二号集群上用 PyTorch 实现了论文 《CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP》。 CLIP-GEN 是一个 Language-F
 75 Dec 29, 2022
75 Dec 29, 2022
DeepGNN is a framework for training machine learning models on large scale graph data.
DeepGNN Overview DeepGNN is a framework for training machine learning models on large scale graph data. DeepGNN contains all the necessary features in
45 Jan 1, 2023
Aiming at the common training datsets split, spectrum preprocessing, wavelength select and calibration models algorithm involved in the spectral analysis process
Aiming at the common training datsets split, spectrum preprocessing, wavelength select and calibration models algorithm involved in the spectral analysis process, a complete algorithm library is established, which is named opensa (openspectrum analysis).
 50 Jan 7, 2023
50 Jan 7, 2023

Princeton NLP's pre-training library based on fairseq with DeepSpeed kernel integration 🚃
This repository provides a library for efficient training of masked language models (MLM), built with fairseq. We fork fairseq to give researchers mor
 92 Dec 27, 2022
92 Dec 27, 2022
Code for our SIGIR 2022 accepted paper : P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-based Learning and Pre-finetuning
P3 Ranker Implementation for our SIGIR2022 accepted paper: P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-bas
 14 Jan 4, 2023
14 Jan 4, 2023

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
Implementaion of our ACL 2022 paper Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation This is the implementaion of our paper: Bridging the
 20 Dec 12, 2022
20 Dec 12, 2022
Repository for DNN training, theory to practice, part of the Large Scale Machine Learning class at Mines Paritech
DNN Training, from theory to practice This repository is complementary to the deep learning training lesson given to les Mines ParisTech on the 11th o
 6 Nov 14, 2022
6 Nov 14, 2022

This is the first released system towards complex meters` detection and recognition, which is implemented by computer vision techniques.
A three-stage detection and recognition pipeline of complex meters in wild This is the first released system towards detection and recognition of comp
 19 Nov 28, 2022
19 Nov 28, 2022
![[CVPR 2022]](https://github.com/VITA-Group/Diverse-ViT/raw/main/Figs/Diversity_overview.png)
[CVPR 2022] "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy" by Tianlong Chen, Zhenyu Zhang, Yu Cheng, Ahmed Awadallah, Zhangyang Wang
The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy Codes for this paper: [CVPR 2022] The Pr
16 Nov 26, 2022
Architecture Patterns with Python (TDD, DDD, EDM)
architecture-traning Architecture Patterns with Python (TDD, DDD, EDM) Chapter 5. 높은 기어비와 낮은 기어비의 TDD 5.2 도메인 계층 테스트를 서비스 계층으로 옮겨야 하는가? 도메인 계층 테스트 def
 2 Mar 4, 2022
2 Mar 4, 2022

E2e music remastering system - End-to-end Music Remastering System Using Self-supervised and Adversarial Training
End-to-end Music Remastering System This repository includes source code and pre
 37 Dec 15, 2022
37 Dec 15, 2022

Vad-sli-asr - A Python scripts for a speech processing pipeline with Voice Activity Detection (VAD)
VAD-SLI-ASR Python scripts for a speech processing pipeline with Voice Activity
 14 Dec 9, 2022
14 Dec 9, 2022
Super-Fast-Adversarial-Training - A PyTorch Implementation code for developing super fast adversarial training
Super-Fast-Adversarial-Training This is a PyTorch Implementation code for develo
 26 Dec 2, 2022
26 Dec 2, 2022
Udacity-api-reporting-pipeline - Udacity api reporting pipeline
udacity-api-reporting-pipeline In this exercise, you'll use portions of each of
 1 Feb 15, 2022
1 Feb 15, 2022

HashNeRF-pytorch - Pure PyTorch Implementation of NVIDIA paper on Instant Training of Neural Graphics primitives
HashNeRF-pytorch Instant-NGP recently introduced a Multi-resolution Hash Encodin
 616 Jan 6, 2023
616 Jan 6, 2023
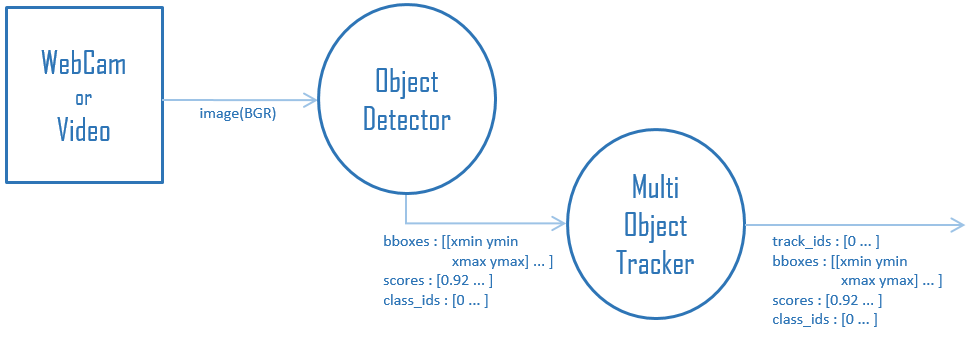
MOT-Tracking-by-Detection-Pipeline - For Tracking-by-Detection format MOT (Multi Object Tracking), is it a framework that separates Detection and Tracking processes?
MOT-Tracking-by-Detection-Pipeline Tracking-by-Detection形式のMOT(Multi Object Trac
 41 Nov 23, 2022
41 Nov 23, 2022
Bugbane - Application security tools for CI/CD pipeline
BugBane Набор утилит для аудита безопасности приложений. Основные принципы и осо
 20 Dec 9, 2022
20 Dec 9, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training
[ICLR 2022] The Unreasonable Effectiveness of Random Pruning: Return of the Most Naive Baseline for Sparse Training The Unreasonable Effectiveness of
44 Dec 23, 2022
LyaNet: A Lyapunov Framework for Training Neural ODEs
LyaNet: A Lyapunov Framework for Training Neural ODEs Provide the model type--config-name to train and test models configured as those shown in the pa
 21 Nov 21, 2022
21 Nov 21, 2022
This is the replication package for paper submission: Towards Training Reproducible Deep Learning Models.
This is the replication package for paper submission: Towards Training Reproducible Deep Learning Models.
 0 Feb 2, 2022
0 Feb 2, 2022

Benchmarking Pipeline for Prediction of Protein-Protein Interactions
B4PPI Benchmarking Pipeline for the Prediction of Protein-Protein Interactions How this benchmarking pipeline has been built, and how to use it, is de
 4 Jun 27, 2022
4 Jun 27, 2022

To build a regression model to predict the concrete compressive strength based on the different features in the training data.
Cement-Strength-Prediction Problem Statement To build a regression model to predict the concrete compressive strength based on the different features
 4 Jun 11, 2022
4 Jun 11, 2022

MLOps pipeline project using Amazon SageMaker Pipelines
This project shows steps to build an end to end MLOps architecture that covers data prep, model training, realtime and batch inference, build model registry, track lineage of artifacts and model drift detection. It utilizes SageMaker Pipelines that offers machine learning (ML) to orchestrate SageMaker jobs and author reproducible ML pipelines.
 3 Sep 16, 2022
3 Sep 16, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022
A training task for web scraping using python multithreading and a real-time-updated list of available proxy servers.
Parallel web scraping The project is a training task for web scraping using python multithreading and a real-time-updated list of available proxy serv
 1 Feb 10, 2022
1 Feb 10, 2022

Official code of Retinal Vessel Segmentation with Pixel-wise Adaptive Filters and Consistency Training
Official code of Retinal Vessel Segmentation with Pixel-wise Adaptive Filters and Consistency Training (ISBI 2022)
 7 Feb 10, 2022
7 Feb 10, 2022

The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding.
SuperGen The source code for Generating Training Data with Language Models: Towards Zero-Shot Language Understanding. Requirements Before running, you
 38 Dec 12, 2022
38 Dec 12, 2022
FewBit — a library for memory efficient training of large neural networks
FewBit FewBit — a library for memory efficient training of large neural networks. Its efficiency originates from storage optimizations applied to back
 24 Oct 22, 2022
24 Oct 22, 2022

Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics
[AAAI2022] Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics Overall pipeline of OCN. Paper Link: [arXiv] [AAAI
 13 Nov 21, 2022
13 Nov 21, 2022
Code for the tech report Toward Training at ImageNet Scale with Differential Privacy
Differentially private Imagenet training Code for the tech report Toward Training at ImageNet Scale with Differential Privacy by Alexey Kurakin, Steve
 29 Nov 3, 2022
29 Nov 3, 2022

Official PyTorch implementation of the paper "Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory (SB-FBSDE)"
Official PyTorch implementation of the paper "Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory (SB-FBSDE)" which introduces a new class of deep generative models that generalizes score-based models to fully nonlinear forward and backward diffusions.
 43 Jan 3, 2023
43 Jan 3, 2023
This repository provides an efficient PyTorch-based library for training deep models.
An Efficient Library for Training Deep Models This repository provides an efficient PyTorch-based library for training deep models. Installation Make
 123 Jan 5, 2023
123 Jan 5, 2023
Human segmentation models, training/inference code, and trained weights, implemented in PyTorch
Human-Segmentation-PyTorch Human segmentation models, training/inference code, and trained weights, implemented in PyTorch. Supported networks UNet: b
 474 Dec 19, 2022
474 Dec 19, 2022
Data from "Datamodels: Predicting Predictions with Training Data"
Data from "Datamodels: Predicting Predictions with Training Data" Here we provid
 51 Dec 9, 2022
51 Dec 9, 2022
Training a deep learning model on the noisy CIFAR dataset
Training-a-deep-learning-model-on-the-noisy-CIFAR-dataset This repository contai
 1 Jun 14, 2022
1 Jun 14, 2022
Simple codebase for flexible neural net training
neural-modular Simple codebase for flexible neural net training. Allows for seamless exchange of models, dataset, and optimizers. Uses hydra for confi
 7 Apr 5, 2022
7 Apr 5, 2022
This is an early in-development version of training CLIP models with hivemind.
A transformer that does not hog your GPU memory This is an early in-development codebase: if you want a stable and documented hivemind codebase, look
 4 Nov 6, 2022
4 Nov 6, 2022

The NewSHead dataset is a multi-doc headline dataset used in NHNet for training a headline summarization model.
This repository contains the raw dataset used in NHNet [1] for the task of News Story Headline Generation. The code of data processing and training is available under Tensorflow Models - NHNet.
 31 Jul 15, 2022
31 Jul 15, 2022
A scrapy pipeline that provides an easy way to store files and images using various folder structures.
scrapy-folder-tree This is a scrapy pipeline that provides an easy way to store files and images using various folder structures. Supported folder str
 7 Oct 23, 2022
7 Oct 23, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022

Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity
[ICLR 2022] Deep Ensembling with No Overhead for either Training or Testing: The All-Round Blessings of Dynamic Sparsity by Shiwei Liu, Tianlong Chen, Zahra Atashgahi, Xiaohan Chen, Ghada Sokar, Elena Mocanu, Mykola Pechenizkiy, Zhangyang Wang, Decebal Constantin Mocanu
18 Dec 31, 2022
Training DiffWave using variational method from Variational Diffusion Models.
Variational DiffWave Training DiffWave using variational method from Variational Diffusion Models. Quick Start python train_distributed.py discrete_10
 26 Dec 13, 2022
26 Dec 13, 2022
BaseCls BaseCls 是一个基于 MegEngine 的预训练模型库,帮助大家挑选或训练出更适合自己科研或者业务的模型结构
BaseCls BaseCls 是一个基于 MegEngine 的预训练模型库,帮助大家挑选或训练出更适合自己科研或者业务的模型结构。 文档地址:https://basecls.readthedocs.io 安装 安装环境 BaseCls 需要 Python = 3.6。 BaseCls 依赖 M
 28 Dec 23, 2022
28 Dec 23, 2022
JASS: Japanese-specific Sequence to Sequence Pre-training for Neural Machine Translation
JASS: Japanese-specific Sequence to Sequence Pre-training for Neural Machine Translation This the repository for this paper. Find extensions of this w
 14 Oct 26, 2022
14 Oct 26, 2022
WPPNets: Unsupervised CNN Training with Wasserstein Patch Priors for Image Superresolution
WPPNets: Unsupervised CNN Training with Wasserstein Patch Priors for Image Superresolution This code belongs to the paper [1] available at https://arx
 5 Jun 2, 2022
5 Jun 2, 2022
For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training.
LongScientificFormer For encoding a text longer than 512 tokens, for example 800. Set max_pos to 800 during both preprocessing and training. Some code
 6 Nov 2, 2022
6 Nov 2, 2022
Framework for training options with different attention mechanism and using them to solve downstream tasks.
Using Attention in HRL Framework for training options with different attention mechanism and using them to solve downstream tasks. Requirements GPU re
 5 Nov 3, 2022
5 Nov 3, 2022
Identifying a Training-Set Attack’s Target Using Renormalized Influence Estimation
Identifying a Training-Set Attack’s Target Using Renormalized Influence Estimation By: Zayd Hammoudeh and Daniel Lowd Paper: Arxiv Preprint Coming soo
 2 Oct 8, 2022
2 Oct 8, 2022
Post-training Quantization for Neural Networks with Provable Guarantees
Post-training Quantization for Neural Networks with Provable Guarantees Authors: Jinjie Zhang ([email protected]), Yixuan Zhou ([email protected]) and Ray
 2 Nov 29, 2022
2 Nov 29, 2022

Hyperparameters tuning and features selection are two common steps in every machine learning pipeline.
shap-hypetune A python package for simultaneous Hyperparameters Tuning and Features Selection for Gradient Boosting Models. Overview Hyperparameters t
 422 Jan 8, 2023
422 Jan 8, 2023

SAS: Self-Augmentation Strategy for Language Model Pre-training
SAS: Self-Augmentation Strategy for Language Model Pre-training This repository
5 Nov 2, 2022
Revisiting Weakly Supervised Pre-Training of Visual Perception Models
SWAG: Supervised Weakly from hashtAGs This repository contains SWAG models from the paper Revisiting Weakly Supervised Pre-Training of Visual Percepti
134 Jan 5, 2023
Cycle Self-Training for Domain Adaptation (NeurIPS 2021)
CST Code release for "Cycle Self-Training for Domain Adaptation" (NeurIPS 2021) Prerequisites torch=1.7.0 torchvision qpsolvers numpy prettytable tqd
 16 Jan 22, 2022
16 Jan 22, 2022
Compute execution plan: A DAG representation of work that you want to get done. Individual nodes of the DAG could be simple python or shell tasks or complex deeply nested parallel branches or embedded DAGs themselves.
Hello from magnus Magnus provides four capabilities for data teams: Compute execution plan: A DAG representation of work that you want to get done. In
 12 Feb 8, 2022
12 Feb 8, 2022
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
 11 Nov 8, 2022
11 Nov 8, 2022

CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs
CLIP [Blog] [Paper] [Model Card] [Colab] CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pair
 6k Jan 25, 2022
6k Jan 25, 2022
The repository includes the code for training cell counting applications. (Keras + Tensorflow)
cell_counting_v2 The repository includes the code for training cell counting applications. (Keras + Tensorflow) Dataset can be downloaded here : http:
 113 Oct 6, 2022
113 Oct 6, 2022

Segmentation Training Pipeline
Segmentation Training Pipeline This package is a part of Musket ML framework. Reasons to use Segmentation Pipeline Segmentation Pipeline was developed
 52 Dec 12, 2022
52 Dec 12, 2022

PyTorchMemTracer - Depict GPU memory footprint during DNN training of PyTorch
A Memory Tracer For PyTorch OOM is a nightmare for PyTorch users. However, most
 9 Nov 14, 2022
9 Nov 14, 2022
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022
First steps with Python in Life Sciences
First steps with Python in Life Sciences This course material is part of the "First Steps with Python in Life Science" three-day course of SIB-trainin
 22 Jan 8, 2023
22 Jan 8, 2023
Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a local folder
Ingestinator Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a
 2 Nov 18, 2022
2 Nov 18, 2022

Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Collapse by Conditioning: Training Class-conditional GANs with Limited Data Moha
 33 Dec 6, 2022
33 Dec 6, 2022
ESGD-M - A stochastic non-convex second order optimizer, suitable for training deep learning models, for PyTorch
ESGD-M - A stochastic non-convex second order optimizer, suitable for training deep learning models, for PyTorch
53 Dec 29, 2022