2158 Repositories
Python vision-transformer-search-space Libraries
Are you obsessed with playing the increasingly-popular word game Wordle?
WORDLE-VISION Up your Wordle game! Are you obsessed with playing the increasingly-popular word game Wordle? Ever wondered what the optimal first word
 5 May 10, 2022
5 May 10, 2022
A fast, efficiency python package for searching and getting search results with many different search engines
search A fast, efficiency python package for searching and getting search results with many different search engines. Installation To install the pack
 0 Oct 6, 2022
0 Oct 6, 2022

OMNIVORE is a single vision model for many different visual modalities
Omnivore: A Single Model for Many Visual Modalities [paper][website] OMNIVORE is a single vision model for many different visual modalities. It learns
 451 Dec 27, 2022
451 Dec 27, 2022

Cereal box identification in store shelves using computer vision and a single train image per model.
Product Recognition on Store Shelves Description You can read the task description here. Report You can read and download our report here. Step A - Mu
 1 Jan 21, 2022
1 Jan 21, 2022

Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
 42 Dec 30, 2022
42 Dec 30, 2022
This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector of the financial market.
GPlearn_finiance_stock_futures_extension This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector
 189 Dec 25, 2022
189 Dec 25, 2022
Deep Learning Topics with Computer Vision & NLP
Deep learning Udacity Course Deep Learning Topics with Computer Vision & NLP for the AWS Machine Learning Engineer Nanodegree Program Tasks are mostly
 1 Jan 20, 2022
1 Jan 20, 2022
Some experiments with tennis player aging curves using Hilbert space GPs in PyMC. Only experimental for now.
NOTE: This is still being developed! Setup notes This document uses Jeff Sackmann's tennis data. You can obtain it as follows: git clone https://githu
 1 Jan 20, 2022
1 Jan 20, 2022

FFCV: Fast Forward Computer Vision (and other ML workloads!)
Fast Forward Computer Vision: train models at a fraction of the cost with accele
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022
A Simple Telegram Inline Torrent Search Bot by @infotechIT
Torrent-Search-RoBot A Simple Telegram Inline Torrent Search Bot by @infotechIT. Torrent API Using api.infotech.wtf API Host Bot Deploy to Heroku Clic
 0 May 5, 2022
0 May 5, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Transformer in Computer Vision
Transformer-in-Vision A paper list of some recent Transformer-based CV works. If you find some ignored papers, please open issues or pull requests. **
 506 Dec 26, 2022
506 Dec 26, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022
Detail-Preserving Transformer for Light Field Image Super-Resolution
DPT Official Pytorch implementation of the paper "Detail-Preserving Transformer for Light Field Image Super-Resolution" accepted by AAAI 2022 . Update
 50 Jan 1, 2023
50 Jan 1, 2023

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction. arxiv This repository contains python scripts for tr
 12 Dec 12, 2022
12 Dec 12, 2022
TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning
TransZero++ This repository contains the testing code for the paper "TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning" submitted
 3 Jan 5, 2022
3 Jan 5, 2022
Dynamic Token Normalization Improves Vision Transformers
Dynamic Token Normalization Improves Vision Transformers This is the PyTorch implementation of the paper Dynamic Token Normalization Improves Vision T
 20 Oct 9, 2022
20 Oct 9, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022

Code for the CVPR2021 workshop paper "Noise Conditional Flow Model for Learning the Super-Resolution Space"
NCSR: Noise Conditional Flow Model for Learning the Super-Resolution Space Official NCSR training PyTorch Code for the CVPR2021 workshop paper "Noise
 57 Oct 3, 2022
57 Oct 3, 2022

PyTorch implementation of image classification models for CIFAR-10/CIFAR-100/MNIST/FashionMNIST/Kuzushiji-MNIST/ImageNet
PyTorch Image Classification Following papers are implemented using PyTorch. ResNet (1512.03385) ResNet-preact (1603.05027) WRN (1605.07146) DenseNet
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

X-VLM: Multi-Grained Vision Language Pre-Training
X-VLM: learning multi-grained vision language alignments Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. Yan Zeng, Xi
 286 Dec 23, 2022
286 Dec 23, 2022

Codes and scripts for "Explainable Semantic Space by Grounding Languageto Vision with Cross-Modal Contrastive Learning"
Visually Grounded Bert Language Model This repository is the official implementation of Explainable Semantic Space by Grounding Language to Vision wit
 17 Dec 17, 2022
17 Dec 17, 2022

TiP-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
TiP-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling This is the official code release for the paper 'TiP-Adapter: Training-fre
 189 Jan 4, 2023
189 Jan 4, 2023

A PyTorch implementation of VIOLET
VIOLET: End-to-End Video-Language Transformers with Masked Visual-token Modeling A PyTorch implementation of VIOLET Overview VIOLET is an implementati
 119 Dec 30, 2022
119 Dec 30, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022

Official Code Release for "CLIP-Adapter: Better Vision-Language Models with Feature Adapters"
Official Code Release for "CLIP-Adapter: Better Vision-Language Models with Feature Adapters" Pipeline of CLIP-Adapter CLIP-Adapter is a drop-in modul
157 Dec 26, 2022

Python Computer Vision from Scratch
This repository explores the variety of techniques commonly used to analyze and interpret images. It also describes challenging real-world applications where vision is being successfully used, both for specialized applications such as medical imaging, and for fun, consumer-level tasks such as image editing and stitching, which students can apply to their own personal photos and videos.
 221 Dec 26, 2022
221 Dec 26, 2022
Duke Machine Learning Winter School: Computer Vision 2022
mlwscv2002 Welcome to the Duke Machine Learning Winter School: Computer Vision 2022! The MLWS-CV includes 3 hands-on training sessions on implementing
 9 May 25, 2022
9 May 25, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

This repository provides the code for MedViLL(Medical Vision Language Learner).
MedViLL This repository provides the code for MedViLL(Medical Vision Language Learner). Our proposed architecture MedViLL is a single BERT-based model
 39 Jan 5, 2023
39 Jan 5, 2023

This project is an Algorithm Visualizer where a user can visualize algorithms like Bubble Sort, Merge Sort, Quick Sort, Selection Sort, Linear Search and Binary Search.
Algo_Visualizer This project is an Algorithm Visualizer where a user can visualize common algorithms like "Bubble Sort", "Merge Sort", "Quick Sort", "
 4 Feb 7, 2022
4 Feb 7, 2022
Used Logistic Regression, Random Forest, and XGBoost to predict the outcome of Search & Destroy games from the Call of Duty World League for the 2018 and 2019 seasons.
Call of Duty World League: Search & Destroy Outcome Predictions Growing up as an avid Call of Duty player, I was always curious about what factors led
 2 Jan 18, 2022
2 Jan 18, 2022
PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation
PyGRANSO PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation Please check https://ncvx.org/PyGRANSO for detailed instructions (introd
 26 Nov 16, 2022
26 Nov 16, 2022

Predicting 10 different clothing types using Xception pre-trained model.
Predicting-Clothing-Types Predicting 10 different clothing types using Xception pre-trained model from Keras library. It is reimplemented version from
 3 Dec 29, 2021
3 Dec 29, 2021

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022

Official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
 199 Jan 3, 2023
199 Jan 3, 2023
[ACM MM 2021] Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation) [arXiv] [paper] @inproceedings{hou2021multiview, title={Multiview
 27 Dec 13, 2022
27 Dec 13, 2022

Unifying Global-Local Representations in Salient Object Detection with Transformer
GLSTR (Global-Local Saliency Transformer) This is the official implementation of paper "Unifying Global-Local Representations in Salient Object Detect
 11 Aug 24, 2022
11 Aug 24, 2022
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
 27 Nov 7, 2022
27 Nov 7, 2022

This is a code repository for paper OODformer: Out-Of-Distribution Detection Transformer
OODformer: Out-Of-Distribution Detection Transformer This repo is the official the implementation of the OODformer: Out-Of-Distribution Detection Tran
 34 Dec 2, 2022
34 Dec 2, 2022
Image Fusion Transformer
Image-Fusion-Transformer Platform Python 3.7 Pytorch =1.0 Training Dataset MS-COCO 2014 (T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ram
 68 Dec 23, 2022
68 Dec 23, 2022
Official implementation of Sparse Transformer-based Action Recognition
STAR Official implementation of S parse T ransformer-based A ction R ecognition Dataset download NTU RGB+D 60 action recognition of 2D/3D skeleton fro
 15 Nov 2, 2022
15 Nov 2, 2022
MlTr: Multi-label Classification with Transformer
MlTr: Multi-label Classification with Transformer This is official implement of "MlTr: Multi-label Classification with Transformer". Abstract The task
 38 Nov 8, 2022
38 Nov 8, 2022
"Exploring Vision Transformers for Fine-grained Classification" at CVPRW FGVC8
FGVC8 Exploring Vision Transformers for Fine-grained Classification paper presented at the CVPR 2021, The Eight Workshop on Fine-Grained Visual Catego
 19 Dec 6, 2022
19 Dec 6, 2022

Official implementation of "Refiner: Refining Self-attention for Vision Transformers".
RefinerViT This repo is the official implementation of "Refiner: Refining Self-attention for Vision Transformers". The repo is build on top of timm an
 101 Dec 29, 2022
101 Dec 29, 2022
Pyramid Pooling Transformer for Scene Understanding
Pyramid Pooling Transformer for Scene Understanding Requirements: torch 1.6+ torchvision 0.7.0 timm==0.3.2 Validated on torch 1.6.0, torchvision 0.7.0
 119 Dec 29, 2022
119 Dec 29, 2022
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022
High dimensional black-box optimizer using Latent Action Monte Carlo Tree Search algorithm
LA-MCTS The code is based of paper Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search. Component LA-MCTS has thr
18 Oct 24, 2022

LegoDNN: a block-grained scaling tool for mobile vision systems
Table of contents 1 Introduction 1.1 Major features 1.2 Architecture 2 Code and Installation 2.1 Code 2.2 Installation 3 Repository of DNNs in vision
 41 Dec 24, 2022
41 Dec 24, 2022
Scaling Vision with Sparse Mixture of Experts
Scaling Vision with Sparse Mixture of Experts This repository contains the code for training and fine-tuning Sparse MoE models for vision (V-MoE) on I
 290 Dec 25, 2022
290 Dec 25, 2022

Instant neural graphics primitives: lightning fast NeRF and more
Instant Neural Graphics Primitives Ever wanted to train a NeRF model of a fox in under 5 seconds? Or fly around a scene captured from photos of a fact
 10.6k Jan 1, 2023
10.6k Jan 1, 2023

Bringing Computer Vision and Flutter together , to build an awesome app !!
Bringing Computer Vision and Flutter together , to build an awesome app !! Explore the Directories Flutter · Machine Learning Table of Contents About
 14 Apr 7, 2022
14 Apr 7, 2022
Face Mask Detector by live camera using tensorflow-keras, openCV and Python
Face Mask Detector 😷 by Live Camera Detecting masked or unmasked faces by live camera with percentange of mask occupation About Project: This an Arti
 2 Apr 4, 2022
2 Apr 4, 2022

Deep learning transformer model that generates unique music sequences.
music-ai Deep learning transformer model that generates unique music sequences. Abstract In 2017, a new state-of-the-art was published for natural lan
 6 Nov 19, 2022
6 Nov 19, 2022

Step by Step on how to create an vision recognition model using LOBE.ai, export the model and run the model in an Azure Function
Step by Step on how to create an vision recognition model using LOBE.ai, export the model and run the model in an Azure Function
 3 Mar 30, 2022
3 Mar 30, 2022

PyTorch implementation of Higher Order Recurrent Space-Time Transformer
Higher Order Recurrent Space-Time Transformer (HORST) This is the official PyTorch implementation of Higher Order Recurrent Space-Time Transformer. Th
 13 Oct 18, 2022
13 Oct 18, 2022

Pytorch implementation of Decoupled Spatial-Temporal Transformer for Video Inpainting
Decoupled Spatial-Temporal Transformer for Video Inpainting By Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, J
 51 Dec 13, 2022
51 Dec 13, 2022

NeWT: Natural World Tasks
NeWT: Natural World Tasks This repository contains resources for working with the NeWT dataset. ❗ At this time the binary tasks are not publicly avail
 26 Oct 18, 2022
26 Oct 18, 2022
Official PyTorch Implementation of "AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecasting".
AgentFormer This repo contains the official implementation of our paper: AgentFormer: Agent-Aware Transformers for Socio-Temporal Multi-Agent Forecast
 161 Dec 23, 2022
161 Dec 23, 2022

Single-Shot Motion Completion with Transformer
Single-Shot Motion Completion with Transformer 👉 [Preprint] 👈 Abstract Motion completion is a challenging and long-discussed problem, which is of gr
 78 Dec 29, 2022
78 Dec 29, 2022
![[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation](https://github.com/MCG-NJU/RTD-Action/raw/main/rtd_overview.png)
[ICCV 2021] Relaxed Transformer Decoders for Direct Action Proposal Generation
RTD-Net (ICCV 2021) This repo holds the codes of paper: "Relaxed Transformer Decoders for Direct Action Proposal Generation", accepted in ICCV 2021. N
 80 Nov 30, 2022
80 Nov 30, 2022
IOT: Instance-wise Layer Reordering for Transformer Structures
Introduction This repository contains the code for Instance-wise Ordered Transformer (IOT), which is introduced in the ICLR2021 paper IOT: Instance-wi
 19 Nov 15, 2022
19 Nov 15, 2022

Code and Resources for the Transformer Encoder Reasoning Network (TERN)
Transformer Encoder Reasoning Network Code for the cross-modal visual-linguistic retrieval method from "Transformer Reasoning Network for Image-Text M
 53 Dec 30, 2022
53 Dec 30, 2022
Effective Use of Transformer Networks for Entity Tracking
Effective Use of Transformer Networks for Entity Tracking (EMNLP19) This is a PyTorch implementation of our EMNLP paper on the effectiveness of pre-tr
 5 Nov 6, 2021
5 Nov 6, 2021
Pytorch implementation of set transformer
set_transformer Official PyTorch implementation of the paper Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks .
 410 Jan 6, 2023
410 Jan 6, 2023

An implementation of the efficient attention module.
Efficient Attention An implementation of the efficient attention module. Description Efficient attention is an attention mechanism that substantially
 194 Dec 15, 2022
194 Dec 15, 2022
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
GCNet for Object Detection By Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, Han Hu. This repo is a official implementation of "GCNet: Non-local Networ
 1.1k Dec 29, 2022
1.1k Dec 29, 2022

Pytorch implementation of Compressive Transformers, from Deepmind
Compressive Transformer in Pytorch Pytorch implementation of Compressive Transformers, a variant of Transformer-XL with compressed memory for long-ran
 118 Dec 1, 2022
118 Dec 1, 2022
Code repo for "Transformer on a Diet" paper
Transformer on a Diet Reference: C Wang, Z Ye, A Zhang, Z Zhang, A Smola. "Transformer on a Diet". arXiv preprint arXiv (2020). Installation pip insta
 31 Sep 26, 2021
31 Sep 26, 2021
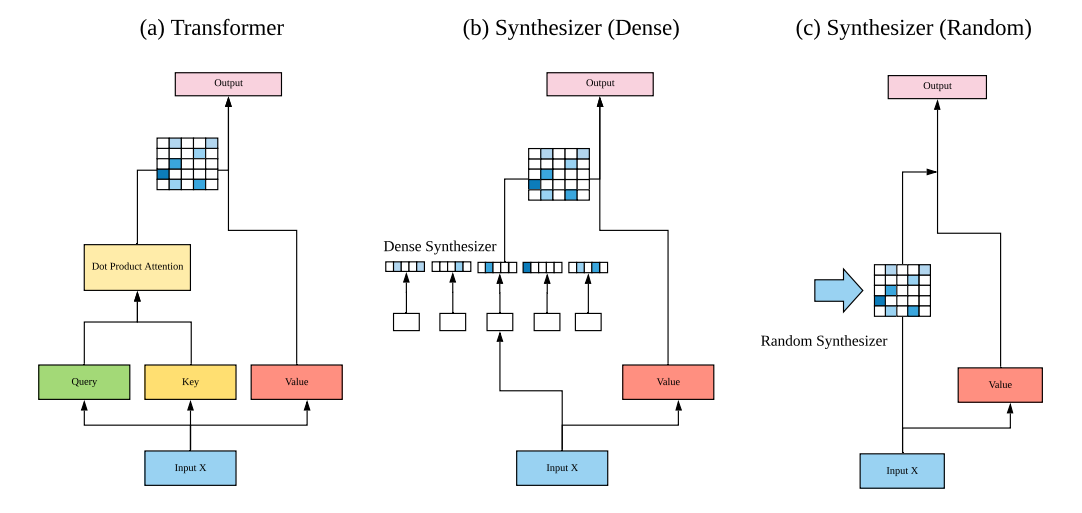
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch
Implementing SYNTHESIZER: Rethinking Self-Attention in Transformer Models using Pytorch Reference Paper URL Author: Yi Tay, Dara Bahri, Donald Metzler
 66 Nov 30, 2022
66 Nov 30, 2022

Implementation of Memformer, a Memory-augmented Transformer, in Pytorch
Memformer - Pytorch Implementation of Memformer, a Memory-augmented Transformer, in Pytorch. It includes memory slots, which are updated with attentio
60 Nov 6, 2022
Collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets
The repository collects many various multi-modal transformer architectures, including image transformer, video transformer, image-language transformer, video-language transformer and related datasets. Additionally, it also collects many useful tutorials and tools in these related domains.
 139 Dec 21, 2022
139 Dec 21, 2022

Repository for 2021 Computer Vision Class @ Chulalongkorn University
2110443 - Computer Vision (2021/2) Computer Vision @ Chulalongkorn University Anaconda Download Link https://www.anaconda.com/download/ Miniconda and
 5 Jul 19, 2022
5 Jul 19, 2022
📚 A collection of all the Deep Learning Metrics that I came across which are not accuracy/loss.
📚 A collection of all the Deep Learning Metrics that I came across which are not accuracy/loss.
 1 Jan 17, 2022
1 Jan 17, 2022
Connects to an active BitCoin Peer and communicates in order to locate a specific block number (height)
BitCoin-Peer-Client Connects to an active BitCoin Peer, and locates a predetermined block number (height) by downloading block headers. Once required
 1 Jan 16, 2022
1 Jan 16, 2022

Search msDS-AllowedToActOnBehalfOfOtherIdentity
前言 现在进行RBCD的攻击手段主要是搜索mS-DS-CreatorSID,如果机器的创建者是我们可控的话,那就可以修改对应机器的msDS-AllowedToActOnBehalfOfOtherIdentity,利用工具SharpAllowedToAct-Modify 那我们索性也试试搜索所有计算机
 26 Dec 5, 2022
26 Dec 5, 2022
Tree-based Search Graph for Approximate Nearest Neighbor Search
TBSG: Tree-based Search Graph for Approximate Nearest Neighbor Search. TBSG is a graph-based algorithm for ANNS based on Cover Tree, which is also an
 2 Dec 27, 2022
2 Dec 27, 2022

This is the official implementation of our proposed SwinMR
SwinMR This is the official implementation of our proposed SwinMR: Swin Transformer for Fast MRI Please cite: @article{huang2022swin, title={Swi
 27 Nov 17, 2022
27 Nov 17, 2022
Accurate identification of bacteriophages from metagenomic data using Transformer
PhaMer is a python library for identifying bacteriophages from metagenomic data. PhaMer is based on a Transorfer model and rely on protein-based vocab
 9 Nov 30, 2022
9 Nov 30, 2022

VisionKG: Vision Knowledge Graph
VisionKG: Vision Knowledge Graph Official Repository of VisionKG by Anh Le-Tuan, Trung-Kien Tran, Manh Nguyen-Duc, Jicheng Yuan, Manfred Hauswirth and
 9 Jun 23, 2022
9 Jun 23, 2022
EmployeeDB - Advanced Redis search functionalities on Python applied on an Employee management backend app
EmployeeDB - Advanced Redis search functionalities on Python applied on an Employee management backend app
 58 Oct 10, 2022
58 Oct 10, 2022
📚 Papers & tech blogs by companies sharing their work on data science & machine learning in production.
applied-ml Curated papers, articles, and blogs on data science & machine learning in production. ⚙️ Figuring out how to implement your ML project? Lea
 22.1k Jan 3, 2023
22.1k Jan 3, 2023
EBay-email-tracker - Scapes an entire search page of a particular item on eBay and sends regular updates to an email address
Introduction This is a project I built with the sole intent to learn more about
 1 Jan 14, 2022
1 Jan 14, 2022
Repo for the paper Extrapolating from a Single Image to a Thousand Classes using Distillation
Extrapolating from a Single Image to a Thousand Classes using Distillation by Yuki M. Asano* and Aaqib Saeed* (*Equal Contribution) Extrapolating from
 16 Nov 4, 2022
16 Nov 4, 2022

LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation
LEDNet: A Lightweight Encoder-Decoder Network for Real-time Semantic Segmentation Table of Contents: Introduction Project Structure Installation Datas
 492 Dec 2, 2022
492 Dec 2, 2022
The official implementation of ELSA: Enhanced Local Self-Attention for Vision Transformer
ELSA: Enhanced Local Self-Attention for Vision Transformer By Jingkai Zhou, Pich
 87 Dec 19, 2022
87 Dec 19, 2022
A simple python module to generate anchor (aka default/prior) boxes for object detection tasks.
PyBx WIP A simple python module to generate anchor (aka default/prior) boxes for object detection tasks. Calculated anchor boxes are returned as ndarr
 4 Dec 15, 2022
4 Dec 15, 2022
MPViT:Multi-Path Vision Transformer for Dense Prediction
MPViT : Multi-Path Vision Transformer for Dense Prediction This repository inlcu
 272 Dec 20, 2022
272 Dec 20, 2022
Generic Foreground Segmentation in Images
Pixel Objectness The following repository contains pretrained model for pixel objectness. Please visit our project page for the paper and visual resul
 157 Nov 21, 2022
157 Nov 21, 2022
Food recognition model using convolutional neural network & computer vision
Food recognition model using convolutional neural network & computer vision. The goal is to match or beat the DeepFood Research Paper
 1 Jan 13, 2022
1 Jan 13, 2022