1703 Repositories
Python Dynamic-Vision-Transformer Libraries

Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer.
DocEnTR Description Pytorch implementation of the paper DocEnTr: An End-to-End Document Image Enhancement Transformer. This model is implemented on to
 74 Jan 7, 2023
74 Jan 7, 2023
Vision transformers (ViTs) have found only limited practical use in processing images
CXV Convolutional Xformers for Vision Vision transformers (ViTs) have found only limited practical use in processing images, in spite of their state-o
 23 Sep 10, 2022
23 Sep 10, 2022

Labelme is a graphical image annotation tool, It is written in Python and uses Qt for its graphical interface
Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
 9.6k Jan 9, 2023
9.6k Jan 9, 2023

Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch
Semantic Segmentation Easy to use and customizable SOTA Semantic Segmentation models with abundant datasets in PyTorch Features Applicable to followin
 530 Jan 5, 2023
530 Jan 5, 2023

Object classification with basic computer vision techniques
naive-image-classification Object classification with basic computer vision techniques. Final assignment for the computer vision course I took at univ
 2 Jul 1, 2022
2 Jul 1, 2022
Computer vision applications project (Flask and OpenCV)
Computer Vision Applications Project This project is at it's initial phase. This is all about the implementation of different computer vision techniqu
 1 Jan 26, 2022
1 Jan 26, 2022

Dynamic vae - Dynamic VAE algorithm is used for anomaly detection of battery data
Dynamic VAE frame Automatic feature extraction can be achieved by probability di
 10 Oct 7, 2022
10 Oct 7, 2022
Code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization,
FSRA This repository contains the dataset link and the code for our paper A Transformer-Based Feature Segmentation and Region Alignment Method For UAV
 32 Dec 18, 2022
32 Dec 18, 2022

EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation
EdiBERT, a generative model for image editing EdiBERT is a generative model based on a bi-directional transformer, suited for image manipulation. The
 16 Dec 7, 2022
16 Dec 7, 2022

Human Dynamics from Monocular Video with Dynamic Camera Movements
Human Dynamics from Monocular Video with Dynamic Camera Movements Ri Yu, Hwangpil Park and Jehee Lee Seoul National University ACM Transactions on Gra
 215 Jan 1, 2023
215 Jan 1, 2023

On the Adversarial Robustness of Visual Transformer
On the Adversarial Robustness of Visual Transformer Code for our paper "On the Adversarial Robustness of Visual Transformers"
 35 Dec 14, 2022
35 Dec 14, 2022

This is the repo of the manuscript "Dual-branch Attention-In-Attention Transformer for speech enhancement"
DB-AIAT: A Dual-branch attention-in-attention transformer for single-channel SE
 68 Dec 16, 2022
68 Dec 16, 2022
RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2
RoNER RoNER is a Named Entity Recognition model based on a pre-trained BERT transformer model trained on RONECv2. It is meant to be an easy to use, hi
 9 Nov 7, 2022
9 Nov 7, 2022

Eye-Blink-Counter - Python based Computer Vision project which counts how many time a person blinks
Eye Blink Counter OpenCV and Mediapipe No Blink Blink
 2 Mar 24, 2022
2 Mar 24, 2022

Vit-ImageClassification - Pytorch ViT for Image classification on the CIFAR10 dataset
Vit-ImageClassification Introduction This project uses ViT to perform image clas
 4 Jun 1, 2022
4 Jun 1, 2022
Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications
Labelbox Labelbox is the fastest way to annotate data to build and ship artificial intelligence applications. Use this github repository to help you s
 1.7k Dec 29, 2022
1.7k Dec 29, 2022

CVAT is free, online, interactive video and image annotation tool for computer vision
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 4, 2023
8.6k Jan 4, 2023
A curated list and survey of awesome Vision Transformers.
English | 简体中文 A curated list and survey of awesome Vision Transformers. You can use mind mapping software to open the mind mapping source file. You c
 281 Dec 21, 2022
281 Dec 21, 2022
STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs
STonKGs STonKGs is a Sophisticated Transformer that can be jointly trained on biomedical text and knowledge graphs. This multimodal Transformer combin
 27 Aug 11, 2022
27 Aug 11, 2022
Simple and understandable swin-transformer OCR project
swin-transformer-ocr ocr with swin-transformer Overview Simple and understandable swin-transformer OCR project. The model in this repository heavily r
 67 Dec 31, 2022
67 Dec 31, 2022

Awesome Transformers in Medical Imaging
This repo supplements our Survey on Transformers in Medical Imaging Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat,
 666 Jan 6, 2023
666 Jan 6, 2023

Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images
Multimodal Co-Attention Transformer (MCAT) for Survival Prediction in Gigapixel Whole Slide Images [ICCV 2021] © Mahmood Lab - This code is made avail
 63 Dec 1, 2022
63 Dec 1, 2022

RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting
RATCHET: RAdiological Text Captioning for Human Examined Thoraxes RATCHET is a Medical Transformer for Chest X-ray Diagnosis and Reporting. Based on t
 26 Nov 14, 2022
26 Nov 14, 2022
Generating Radiology Reports via Memory-driven Transformer
R2Gen This is the implementation of Generating Radiology Reports via Memory-driven Transformer at EMNLP-2020. Citations If you use or extend our work,
 101 Dec 13, 2022
101 Dec 13, 2022
Pytorch Implementation of Residual Vision Transformers(ResViT)
ResViT Official Pytorch Implementation of Residual Vision Transformers(ResViT) which is described in the following paper: Onat Dalmaz and Mahmut Yurt
 41 Dec 8, 2022
41 Dec 8, 2022

This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
ICCV Workshop 2021 VTGAN This code is for our paper "VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers"
 25 Dec 8, 2022
25 Dec 8, 2022
Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021)
T2Net Task Transformer Network for Joint MRI Reconstruction and Super-Resolution (MICCAI 2021) [Paper][Code] Dependencies numpy==1.18.5 scikit_image==
 64 Nov 23, 2022
64 Nov 23, 2022
COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models
COVID-ViT COVID-VIT: Classification of Covid-19 from CT chest images based on vision transformer models This code is to response to te MIA-COV19 compe
 17 Dec 30, 2022
17 Dec 30, 2022

Accepted at ICCV-2021: Workshop on Computer Vision for Automated Medical Diagnosis (CVAMD)
Is it Time to Replace CNNs with Transformers for Medical Images? Accepted at ICCV-2021: Workshop on Computer Vision for Automated Medical Diagnosis (C
 80 Dec 27, 2022
80 Dec 27, 2022
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification [NeurIPS 2021] Abstract Multiple instance learn
 132 Dec 30, 2022
132 Dec 30, 2022
Mixed Transformer UNet for Medical Image Segmentation
MT-UNet Update 2022/01/05 By another round of training based on previous weights, our model also achieved a better performance on ACDC (91.61% DSC). W
 92 Dec 25, 2022
92 Dec 25, 2022
Official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation
SegPC-2021 This is the official repository for the ISBI 2021 paper Transformer Assisted Convolutional Neural Network for Cell Instance Segmentation by
 13 Dec 14, 2022
13 Dec 14, 2022

This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
 89 Jan 24, 2022
89 Jan 24, 2022
nnFormer: Interleaved Transformer for Volumetric Segmentation
nnFormer: Interleaved Transformer for Volumetric Segmentation Code for paper "nnFormer: Interleaved Transformer for Volumetric Segmentation ". Please
 610 Dec 28, 2022
610 Dec 28, 2022
Raster Vision is an open source Python framework for building computer vision models on satellite, aerial, and other large imagery sets
Raster Vision is an open source Python framework for building computer vision models on satellite, aerial, and other large imagery sets (including obl
 1.7k Dec 22, 2022
1.7k Dec 22, 2022

🛰️ Awesome Satellite Imagery Datasets
Awesome Satellite Imagery Datasets List of aerial and satellite imagery datasets with annotations for computer vision and deep learning. Newest datase
 3k Jan 3, 2023
3k Jan 3, 2023

Source code of all the projects of Udacity Self-Driving Car Engineer Nanodegree.
self-driving-car In this repository I will share the source code of all the projects of Udacity Self-Driving Car Engineer Nanodegree. Hope this might
 2.4k Dec 29, 2022
2.4k Dec 29, 2022
Computer Vision is an elective course of MSAI, SCSE, NTU, Singapore
[AI6122] Computer Vision is an elective course of MSAI, SCSE, NTU, Singapore. The repository corresponds to the AI6122 of Semester 1, AY2021-2022, starting from 08/2021. The instructor of this course is Prof. Lu Shijian.
 5 Sep 12, 2022
5 Sep 12, 2022

Exadel CompreFace is a free and open-source face recognition GitHub project
Exadel CompreFace is a leading free and open-source face recognition system Exadel CompreFace is a free and open-source face recognition service that
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

TetrisAI - Tetris AI Bot using computer vision to play game automatically
Tetris AI Tetris AI Bot using computer vision to play game automatically bot.py
 11 Aug 29, 2022
11 Aug 29, 2022

Pytorch implementation of ICASSP 2022 paper Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 6 Sep 21, 2022
6 Sep 21, 2022

Attention Probe: Vision Transformer Distillation in the Wild
Attention Probe: Vision Transformer Distillation in the Wild Jiahao Wang, Mingdeng Cao, Shuwei Shi, Baoyuan Wu, Yujiu Yang In ICASSP 2022 This code is
 3 Oct 31, 2022
3 Oct 31, 2022
Are you obsessed with playing the increasingly-popular word game Wordle?
WORDLE-VISION Up your Wordle game! Are you obsessed with playing the increasingly-popular word game Wordle? Ever wondered what the optimal first word
 5 May 10, 2022
5 May 10, 2022

OMNIVORE is a single vision model for many different visual modalities
Omnivore: A Single Model for Many Visual Modalities [paper][website] OMNIVORE is a single vision model for many different visual modalities. It learns
 451 Dec 27, 2022
451 Dec 27, 2022

Cereal box identification in store shelves using computer vision and a single train image per model.
Product Recognition on Store Shelves Description You can read the task description here. Report You can read and download our report here. Step A - Mu
 1 Jan 21, 2022
1 Jan 21, 2022

Fast Differentiable Matrix Sqrt Root
Official Pytorch implementation of ICLR 22 paper Fast Differentiable Matrix Square Root
 42 Dec 30, 2022
42 Dec 30, 2022
This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector of the financial market.
GPlearn_finiance_stock_futures_extension This implementation contains the application of GPlearn's symbolic transformer on a commodity futures sector
 189 Dec 25, 2022
189 Dec 25, 2022
Deep Learning Topics with Computer Vision & NLP
Deep learning Udacity Course Deep Learning Topics with Computer Vision & NLP for the AWS Machine Learning Engineer Nanodegree Program Tasks are mostly
 1 Jan 20, 2022
1 Jan 20, 2022
AIDynamicTextReader - A simple dynamic text reader based on Artificial intelligence
AI Dynamic Text Reader: This is a simple dynamic text reader based on Artificial
 1 Jan 18, 2022
1 Jan 18, 2022

FFCV: Fast Forward Computer Vision (and other ML workloads!)
Fast Forward Computer Vision: train models at a fraction of the cost with accele
 2.3k Jan 3, 2023
2.3k Jan 3, 2023
ServiceX Transformer that converts flat ROOT ntuples into columnwise data
ServiceX_Uproot_Transformer ServiceX Transformer that converts flat ROOT ntuples into columnwise data Usage You can invoke the transformer from the co
 0 Jan 20, 2022
0 Jan 20, 2022

GNES enables large-scale index and semantic search for text-to-text, image-to-image, video-to-video and any-to-any content form
GNES is Generic Neural Elastic Search, a cloud-native semantic search system based on deep neural network.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022
Transformer in Computer Vision
Transformer-in-Vision A paper list of some recent Transformer-based CV works. If you find some ignored papers, please open issues or pull requests. **
 506 Dec 26, 2022
506 Dec 26, 2022
A curated list of efficient attention modules
awesome-fast-attention A curated list of efficient attention modules
 891 Dec 22, 2022
891 Dec 22, 2022
Compact Bidirectional Transformer for Image Captioning
Compact Bidirectional Transformer for Image Captioning Requirements Python 3.8 Pytorch 1.6 lmdb h5py tensorboardX Prepare Data Please use git clone --
 7 Jan 13, 2022
7 Jan 13, 2022
Video-Music Transformer
VMT Video-Music Transformer (VMT) is an attention-based multi-modal model, which generates piano music for a given video. Paper https://arxiv.org/abs/
 5 Jul 13, 2022
5 Jul 13, 2022
Detail-Preserving Transformer for Light Field Image Super-Resolution
DPT Official Pytorch implementation of the paper "Detail-Preserving Transformer for Light Field Image Super-Resolution" accepted by AAAI 2022 . Update
 50 Jan 1, 2023
50 Jan 1, 2023

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction
Full Transformer Framework for Robust Point Cloud Registration with Deep Information Interaction. arxiv This repository contains python scripts for tr
 12 Dec 12, 2022
12 Dec 12, 2022
TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning
TransZero++ This repository contains the testing code for the paper "TransZero++: Cross Attribute-guided Transformer for Zero-Shot Learning" submitted
 3 Jan 5, 2022
3 Jan 5, 2022
Dynamic Token Normalization Improves Vision Transformers
Dynamic Token Normalization Improves Vision Transformers This is the PyTorch implementation of the paper Dynamic Token Normalization Improves Vision T
 20 Oct 9, 2022
20 Oct 9, 2022

TransVTSpotter: End-to-end Video Text Spotter with Transformer
TransVTSpotter: End-to-end Video Text Spotter with Transformer Introduction A Multilingual, Open World Video Text Dataset and End-to-end Video Text Sp
 66 Dec 26, 2022
66 Dec 26, 2022

Local-Global Stratified Transformer for Efficient Video Recognition
DualFormer This repo is the implementation of our manuscript entitled "Local-Global Stratified Transformer for Efficient Video Recognition". Our model
 19 Dec 7, 2022
19 Dec 7, 2022

MADT: Offline Pre-trained Multi-Agent Decision Transformer
MADT: Offline Pre-trained Multi-Agent Decision Transformer A link to our paper can be found on Arxiv. Overview Official codebase for Offline Pre-train
 51 Dec 21, 2022
51 Dec 21, 2022

Meta Self-learning for Multi-Source Domain Adaptation: A Benchmark
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark Project | Arxiv | YouTube | | Abstract In recent years, deep learning-based methods
 188 Dec 12, 2022
188 Dec 12, 2022

PyTorch implementation of image classification models for CIFAR-10/CIFAR-100/MNIST/FashionMNIST/Kuzushiji-MNIST/ImageNet
PyTorch Image Classification Following papers are implemented using PyTorch. ResNet (1512.03385) ResNet-preact (1603.05027) WRN (1605.07146) DenseNet
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

X-VLM: Multi-Grained Vision Language Pre-Training
X-VLM: learning multi-grained vision language alignments Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. Yan Zeng, Xi
 286 Dec 23, 2022
286 Dec 23, 2022

Codes and scripts for "Explainable Semantic Space by Grounding Languageto Vision with Cross-Modal Contrastive Learning"
Visually Grounded Bert Language Model This repository is the official implementation of Explainable Semantic Space by Grounding Language to Vision wit
 17 Dec 17, 2022
17 Dec 17, 2022

TiP-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
TiP-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling This is the official code release for the paper 'TiP-Adapter: Training-fre
 189 Jan 4, 2023
189 Jan 4, 2023

A PyTorch implementation of VIOLET
VIOLET: End-to-End Video-Language Transformers with Masked Visual-token Modeling A PyTorch implementation of VIOLET Overview VIOLET is an implementati
 119 Dec 30, 2022
119 Dec 30, 2022

The official code for “DocTr: Document Image Transformer for Geometric Unwarping and Illumination Correction”, ACM MM, Oral Paper, 2021.
Good news! Our new work exhibits state-of-the-art performances on DocUNet benchmark dataset: DocScanner: Robust Document Image Rectification with Prog
 231 Dec 26, 2022
231 Dec 26, 2022
![[BMVC2021]](https://github.com/HowieMa/TransFusion-Pose/raw/main/images/framework.jpg)
[BMVC2021] "TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation"
TransFusion-Pose TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation Haoyu Ma, Liangjian Chen, Deying Kong, Zhe Wang, Xingwei
 29 Dec 23, 2022
29 Dec 23, 2022

Official Code Release for "CLIP-Adapter: Better Vision-Language Models with Feature Adapters"
Official Code Release for "CLIP-Adapter: Better Vision-Language Models with Feature Adapters" Pipeline of CLIP-Adapter CLIP-Adapter is a drop-in modul
157 Dec 26, 2022

Python Computer Vision from Scratch
This repository explores the variety of techniques commonly used to analyze and interpret images. It also describes challenging real-world applications where vision is being successfully used, both for specialized applications such as medical imaging, and for fun, consumer-level tasks such as image editing and stitching, which students can apply to their own personal photos and videos.
 221 Dec 26, 2022
221 Dec 26, 2022
Duke Machine Learning Winter School: Computer Vision 2022
mlwscv2002 Welcome to the Duke Machine Learning Winter School: Computer Vision 2022! The MLWS-CV includes 3 hands-on training sessions on implementing
 9 May 25, 2022
9 May 25, 2022
This repository contains demos I made with the Transformers library by HuggingFace.
Transformers-Tutorials Hi there! This repository contains demos I made with the Transformers library by 🤗 HuggingFace. Currently, all of them are imp
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

This repository provides the code for MedViLL(Medical Vision Language Learner).
MedViLL This repository provides the code for MedViLL(Medical Vision Language Learner). Our proposed architecture MedViLL is a single BERT-based model
 39 Jan 5, 2023
39 Jan 5, 2023
PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation
PyGRANSO PyGRANSO: A PyTorch-enabled port of GRANSO with auto-differentiation Please check https://ncvx.org/PyGRANSO for detailed instructions (introd
 26 Nov 16, 2022
26 Nov 16, 2022

Predicting 10 different clothing types using Xception pre-trained model.
Predicting-Clothing-Types Predicting 10 different clothing types using Xception pre-trained model from Keras library. It is reimplemented version from
 3 Dec 29, 2021
3 Dec 29, 2021

Cross-modal Retrieval using Transformer Encoder Reasoning Networks (TERN). With use of Metric Learning and FAISS for fast similarity search on GPU
Cross-modal Retrieval using Transformer Encoder Reasoning Networks This project reimplements the idea from "Transformer Reasoning Network for Image-Te
 5 Nov 5, 2022
5 Nov 5, 2022
Official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer"
[AAAI2022] UCTransNet This repo is the official implementation of "UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspectiv
199 Jan 3, 2023
[ACM MM 2021] Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation)
Multiview Detection with Shadow Transformer (and View-Coherent Data Augmentation) [arXiv] [paper] @inproceedings{hou2021multiview, title={Multiview
 27 Dec 13, 2022
27 Dec 13, 2022

Unifying Global-Local Representations in Salient Object Detection with Transformer
GLSTR (Global-Local Saliency Transformer) This is the official implementation of paper "Unifying Global-Local Representations in Salient Object Detect
 11 Aug 24, 2022
11 Aug 24, 2022
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
Official PyTorch Implementation of paper EAN: Event Adaptive Network for Efficient Action Recognition
 27 Nov 7, 2022
27 Nov 7, 2022

This is a code repository for paper OODformer: Out-Of-Distribution Detection Transformer
OODformer: Out-Of-Distribution Detection Transformer This repo is the official the implementation of the OODformer: Out-Of-Distribution Detection Tran
 34 Dec 2, 2022
34 Dec 2, 2022
Image Fusion Transformer
Image-Fusion-Transformer Platform Python 3.7 Pytorch =1.0 Training Dataset MS-COCO 2014 (T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ram
 68 Dec 23, 2022
68 Dec 23, 2022
Official implementation of Sparse Transformer-based Action Recognition
STAR Official implementation of S parse T ransformer-based A ction R ecognition Dataset download NTU RGB+D 60 action recognition of 2D/3D skeleton fro
 15 Nov 2, 2022
15 Nov 2, 2022
MlTr: Multi-label Classification with Transformer
MlTr: Multi-label Classification with Transformer This is official implement of "MlTr: Multi-label Classification with Transformer". Abstract The task
 38 Nov 8, 2022
38 Nov 8, 2022
"Exploring Vision Transformers for Fine-grained Classification" at CVPRW FGVC8
FGVC8 Exploring Vision Transformers for Fine-grained Classification paper presented at the CVPR 2021, The Eight Workshop on Fine-Grained Visual Catego
 19 Dec 6, 2022
19 Dec 6, 2022

Official implementation of "Refiner: Refining Self-attention for Vision Transformers".
RefinerViT This repo is the official implementation of "Refiner: Refining Self-attention for Vision Transformers". The repo is build on top of timm an
 101 Dec 29, 2022
101 Dec 29, 2022
Pyramid Pooling Transformer for Scene Understanding
Pyramid Pooling Transformer for Scene Understanding Requirements: torch 1.6+ torchvision 0.7.0 timm==0.3.2 Validated on torch 1.6.0, torchvision 0.7.0
 119 Dec 29, 2022
119 Dec 29, 2022
Dynamic Head: Unifying Object Detection Heads with Attentions
Dynamic Head: Unifying Object Detection Heads with Attentions dyhead_video.mp4 This is the official implementation of CVPR 2021 paper "Dynamic Head: U
 550 Dec 21, 2022
550 Dec 21, 2022
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022
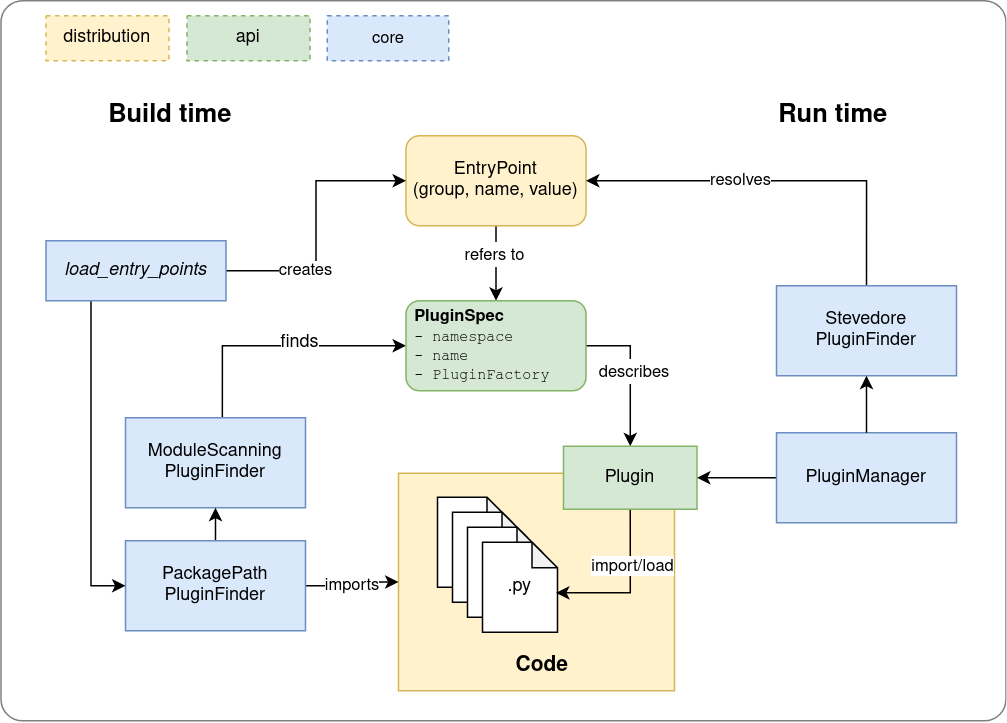
Plux - A dynamic code loading framework for building plugable Python distributions
Plux plux is the dynamic code loading framework used in LocalStack. Overview The
 65 Dec 20, 2022
65 Dec 20, 2022

LegoDNN: a block-grained scaling tool for mobile vision systems
Table of contents 1 Introduction 1.1 Major features 1.2 Architecture 2 Code and Installation 2.1 Code 2.2 Installation 3 Repository of DNNs in vision
 41 Dec 24, 2022
41 Dec 24, 2022
Scaling Vision with Sparse Mixture of Experts
Scaling Vision with Sparse Mixture of Experts This repository contains the code for training and fine-tuning Sparse MoE models for vision (V-MoE) on I
 290 Dec 25, 2022
290 Dec 25, 2022

Instant neural graphics primitives: lightning fast NeRF and more
Instant Neural Graphics Primitives Ever wanted to train a NeRF model of a fox in under 5 seconds? Or fly around a scene captured from photos of a fact
 10.6k Jan 1, 2023
10.6k Jan 1, 2023

Bringing Computer Vision and Flutter together , to build an awesome app !!
Bringing Computer Vision and Flutter together , to build an awesome app !! Explore the Directories Flutter · Machine Learning Table of Contents About
 14 Apr 7, 2022
14 Apr 7, 2022