976 Repositories
Python cross-dataset-bias Libraries
Repository relating to the CVPR21 paper TimeLens: Event-based Video Frame Interpolation
TimeLens: Event-based Video Frame Interpolation This repository is about the High Speed Event and RGB (HS-ERGB) dataset, used in the 2021 CVPR paper T
 544 Dec 19, 2022
544 Dec 19, 2022
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources (NAACL-2021).
Unifying Cross-Lingual Semantic Role Labeling with Heterogeneous Linguistic Resources Description This is the repository for the paper Unifying Cross-
 16 Sep 9, 2022
16 Sep 9, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
 213 Dec 26, 2022
213 Dec 26, 2022
A Dataset of Python Challenges for AI Research
Python Programming Puzzles (P3) This repo contains a dataset of python programming puzzles which can be used to teach and evaluate an AI's programming
 850 Dec 24, 2022
850 Dec 24, 2022

Official implement of "CAT: Cross Attention in Vision Transformer".
CAT: Cross Attention in Vision Transformer This is official implement of "CAT: Cross Attention in Vision Transformer". Abstract Since Transformer has
 100 Dec 15, 2022
100 Dec 15, 2022

Aerial Imagery dataset for fire detection: classification and segmentation (Unmanned Aerial Vehicle (UAV))
Aerial Imagery dataset for fire detection: classification and segmentation using Unmanned Aerial Vehicle (UAV) Title FLAME (Fire Luminosity Airborne-b
 79 Jan 6, 2023
79 Jan 6, 2023
A embed able annotation tool for end to end cross document co-reference
CoRefi CoRefi is an emebedable web component and stand alone suite for exaughstive Within Document and Cross Document Coreference Anntoation. For a de
 39 Dec 12, 2022
39 Dec 12, 2022

COVID-19 deaths statistics around the world
COVID-19-Deaths-Dataset COVID-19 deaths statistics around the world This is a daily updated dataset of COVID-19 deaths around the world. The dataset c
 4 Jul 10, 2022
4 Jul 10, 2022
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022
Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive Learning".
ERICA Source code and dataset for ACL2021 paper: "ERICA: Improving Entity and Relation Understanding for Pre-trained Language Models via Contrastive L
 75 Nov 2, 2022
75 Nov 2, 2022
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023

Pytorch implementation of MaskFlownet
MaskFlownet-Pytorch Unofficial PyTorch implementation of MaskFlownet (https://github.com/microsoft/MaskFlownet). Tested with: PyTorch 1.5.0 CUDA 10.1
 84 Nov 2, 2022
84 Nov 2, 2022
![[CVPR 2021] Monocular depth estimation using wavelets for efficiency](https://github.com/nianticlabs/wavelet-monodepth/raw/main/assets/combo_kitti.gif)
[CVPR 2021] Monocular depth estimation using wavelets for efficiency
Single Image Depth Prediction with Wavelet Decomposition Michaël Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit and Daniyar Turmukhambeto
 205 Jan 2, 2023
205 Jan 2, 2023
Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021)
L1-Refinement Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021) 🙈 A more detailed readme is co
 4 Jun 9, 2021
4 Jun 9, 2021
Code for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned Language Models in the wild .
🌳 Fingerprinting Fine-tuned Language Models in the wild This is the code and dataset for our ACL 2021 (Findings) Paper - Fingerprinting Fine-tuned La
 5 Sep 13, 2022
5 Sep 13, 2022
![[CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision](https://github.com/charlesCXK/TorchSemiSeg/raw/main/ReadmePic/cps.png)
[CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
TorchSemiSeg [CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision by Xiaokang Chen1, Yuhui Yuan2, Gang Zeng1, Jingdong Wang
 387 Jan 8, 2023
387 Jan 8, 2023

The toolkit to generate auto labeled datasets
Ozeu Ozeu is the toolkit to autolabal dataset for instance segmentation. You can generate datasets labaled with segmentation mask and bounding box fro
 28 Mar 28, 2022
28 Mar 28, 2022

Cross-modal Deep Face Normals with Deactivable Skip Connections
Cross-modal Deep Face Normals with Deactivable Skip Connections Victoria Fernández Abrevaya*, Adnane Boukhayma*, Philip H. S. Torr, Edmond Boyer (*Equ
 72 Nov 27, 2022
72 Nov 27, 2022

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022

Official repository for "Action-Based Conversations Dataset: A Corpus for Building More In-Depth Task-Oriented Dialogue Systems"
Action-Based Conversations Dataset (ABCD) This respository contains the code and data for ABCD (Chen et al., 2021) Introduction Whereas existing goal-
 49 Oct 9, 2022
49 Oct 9, 2022

(AAAI2020)Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing
Grapy-ML: Graph Pyramid Mutual Learning for Cross-dataset Human Parsing This repository contains pytorch source code for AAAI2020 oral paper: Grapy-ML
 54 Aug 4, 2022
54 Aug 4, 2022

Cross-media Structured Common Space for Multimedia Event Extraction (ACL2020)
Cross-media Structured Common Space for Multimedia Event Extraction Table of Contents Overview Requirements Data Quickstart Citation Overview The code
 49 Nov 21, 2022
49 Nov 21, 2022
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset.
ProteinBERT is a universal protein language model pretrained on ~106M proteins from the UniRef90 dataset. Through its Python API, the pretrained model can be fine-tuned on any protein-related task in a matter of minutes. Based on our experiments with a wide range of benchmarks, ProteinBERT usually achieves state-of-the-art performance. ProteinBERT is built on TenforFlow/Keras.
 241 Jan 4, 2023
241 Jan 4, 2023

Repo for the Video Person Clustering dataset, and code for the associated paper
Video Person Clustering Repo for the Video Person Clustering dataset, and code for the associated paper. This reporsitory contains the Video Person Cl
 47 Nov 2, 2022
47 Nov 2, 2022
Extract MNIST handwritten digits dataset binary file into bmp images
MNIST-dataset-extractor Extract MNIST handwritten digits dataset binary file into bmp images More info at http://yann.lecun.com/exdb/mnist/ Dependenci
 6 May 24, 2021
6 May 24, 2021

When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings
When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings This is the repository for t
 39 Jan 7, 2023
39 Jan 7, 2023
Code for reproducing our analysis in the paper titled: Image Cropping on Twitter: Fairness Metrics, their Limitations, and the Importance of Representation, Design, and Agency
Image Crop Analysis This is a repo for the code used for reproducing our Image Crop Analysis paper as shared on our blog post. If you plan to use this
 239 Jan 2, 2023
239 Jan 2, 2023

A public available dataset for road boundary detection in aerial images
Topo-boundary This is the official github repo of paper Topo-boundary: A Benchmark Dataset on Topological Road-boundary Detection Using Aerial Images
 79 Jan 4, 2023
79 Jan 4, 2023

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 44 Jan 6, 2023
44 Jan 6, 2023

Official Implementation and Dataset of "PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask and Group-Level Consistency", CVPR 2021
Portrait Photo Retouching with PPR10K Paper | Supplementary Material PPR10K: A Large-Scale Portrait Photo Retouching Dataset with Human-Region Mask an
 184 Dec 11, 2022
184 Dec 11, 2022
Few-NERD: Not Only a Few-shot NER Dataset
Few-NERD: Not Only a Few-shot NER Dataset This is the source code of the ACL-IJCNLP 2021 paper: Few-NERD: A Few-shot Named Entity Recognition Dataset.
319 Dec 30, 2022

Code for Referring Image Segmentation via Cross-Modal Progressive Comprehension, CVPR2020.
CMPC-Refseg Code of our CVPR 2020 paper Referring Image Segmentation via Cross-Modal Progressive Comprehension. Shaofei Huang*, Tianrui Hui*, Si Liu,
 55 Dec 1, 2022
55 Dec 1, 2022
Show Data: Show your dataset in web browser!
Show Data is to generate html tables for large scale image dataset, especially for the dataset in remote server. It provides some useful commond line tools and fully customizeble API reference to generate html table different tasks.
 83 Nov 26, 2022
83 Nov 26, 2022
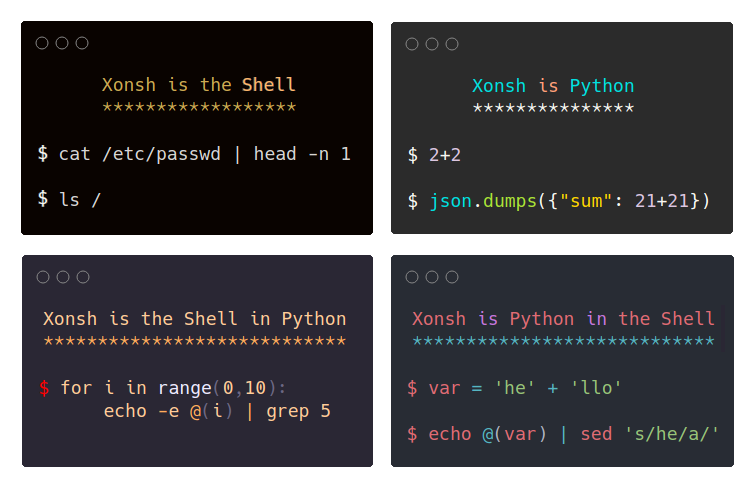
xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt.
xonsh xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt. The language is a superset of Python 3.6+ with additio
 6.7k Jan 8, 2023
6.7k Jan 8, 2023
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition.
TraND This is the code for the paper "Jinkai Zheng, Xinchen Liu, Chenggang Yan, Jiyong Zhang, Wu Liu, Xiaoping Zhang and Tao Mei: TraND: Transferable
 32 Apr 4, 2022
32 Apr 4, 2022
Code and data for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources.
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS) The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limit
 43 Nov 7, 2022
43 Nov 7, 2022

Ever felt tired after preprocessing the dataset, and not wanting to write any code further to train your model? Ever encountered a situation where you wanted to record the hyperparameters of the trained model and able to retrieve it afterward? Models Playground is here to help you do that. Models playground allows you to train your models right from the browser.
Models Playground 🗂️ Upload a Preprocessed Dataset 🌠 Choose whether to perform Classification or Regression 🦹 Enter the Dependent Variable ?
 19 Dec 10, 2022
19 Dec 10, 2022
Multi-Track Music Generation with the Transfomer and the Johann Sebastian Bach Chorales dataset
MMM: Exploring Conditional Multi-Track Music Generation with the Transformer and the Johann Sebastian Bach Chorales Dataset. Implementation of the pap
 102 Dec 8, 2022
102 Dec 8, 2022
An unopinionated replacement for PyTorch's Dataset and ImageFolder, that handles Tar archives
Simple Tar Dataset An unopinionated replacement for PyTorch's Dataset and ImageFolder classes, for datasets stored as uncompressed Tar archives. Just
 47 Dec 20, 2022
47 Dec 20, 2022

The project help you to quickly build layouts in terminal,cross-platform
The project help you to quickly build layouts in terminal,cross-platform
 133 Nov 30, 2022
133 Nov 30, 2022
:hot_pepper: R²SQL: "Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing." (AAAI 2021)
R²SQL The PyTorch implementation of paper Dynamic Hybrid Relation Network for Cross-Domain Context-Dependent Semantic Parsing. (AAAI 2021) Requirement
 60 Dec 31, 2022
60 Dec 31, 2022
Meta Representation Transformation for Low-resource Cross-lingual Learning
MetaXL: Meta Representation Transformation for Low-resource Cross-lingual Learning This repo hosts the code for MetaXL, published at NAACL 2021. [Meta
36 Aug 17, 2022
Official implementation of ETH-XGaze dataset baseline
ETH-XGaze baseline Official implementation of ETH-XGaze dataset baseline. ETH-XGaze dataset ETH-XGaze dataset is a gaze estimation dataset consisting
 134 Jan 3, 2023
134 Jan 3, 2023
A large-scale dataset of both raw MRI measurements and clinical MRI images
fastMRI is a collaborative research project from Facebook AI Research (FAIR) and NYU Langone Health to investigate the use of AI to make MRI scans faster. NYU Langone Health has released fully anonymized knee and brain MRI datasets that can be downloaded from the fastMRI dataset page. Publications associated with the fastMRI project can be found at the end of this README.
907 Jan 4, 2023

This is the dataset for testing the robustness of various VO/VIO methods
KAIST VIO dataset This is the dataset for testing the robustness of various VO/VIO methods You can download the whole dataset on KAIST VIO dataset Ind
 1 Sep 1, 2022
1 Sep 1, 2022
Django app for handling the server headers required for Cross-Origin Resource Sharing (CORS)
django-cors-headers A Django App that adds Cross-Origin Resource Sharing (CORS) headers to responses. This allows in-browser requests to your Django a
 4.8k Jan 5, 2023
4.8k Jan 5, 2023

Location-Sensitive Visual Recognition with Cross-IOU Loss
The trained models are temporarily unavailable, but you can train the code using reasonable computational resource. Location-Sensitive Visual Recognit
 146 Dec 25, 2022
146 Dec 25, 2022
This is a Cross-Platform Plot Manager for Chia Plotting that is simple, easy-to-use, and reliable.
Swar's Chia Plot Manager A plot manager for Chia plotting: https://www.chia.net/ Development Version: v0.0.1 This is a cross-platform Chia Plot Manage
 1.3k Dec 13, 2022
1.3k Dec 13, 2022
![The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]](https://github.com/Paranioar/SGRAF/raw/main/fig/model.png)
The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]
SGRAF PyTorch implementation for AAAI2021 paper of “Similarity Reasoning and Filtration for Image-Text Matching”. It is built on top of the SCAN and C
 149 Dec 22, 2022
149 Dec 22, 2022
Code and data of the Fine-Grained R2R Dataset proposed in paper Sub-Instruction Aware Vision-and-Language Navigation
Fine-Grained R2R Code and data of the Fine-Grained R2R Dataset proposed in the EMNLP2020 paper Sub-Instruction Aware Vision-and-Language Navigation. C
 34 Nov 15, 2022
34 Nov 15, 2022

Lighting the Darkness in the Deep Learning Era: A Survey, An Online Platform, A New Dataset
Lighting the Darkness in the Deep Learning Era: A Survey, An Online Platform, A New Dataset This repository provides a unified online platform, LoLi-P
 457 Jan 3, 2023
457 Jan 3, 2023
Code for "Learning the Best Pooling Strategy for Visual Semantic Embedding", CVPR 2021
Learning the Best Pooling Strategy for Visual Semantic Embedding Official PyTorch implementation of the paper Learning the Best Pooling Strategy for V
 106 Jan 6, 2023
106 Jan 6, 2023

A repository with scraping code and soccer dataset from understat.com.
UNDERSTAT - SHOTS DATASET As many people interested in soccer analytics know, Understat is an amazing source of information. They provide Expected Goa
 48 Jan 3, 2023
48 Jan 3, 2023
![[CVPR 2021 Oral] Variational Relational Point Completion Network](https://github.com/paul007pl/VRCNet/raw/main/images/intro.png)
[CVPR 2021 Oral] Variational Relational Point Completion Network
VRCNet: Variational Relational Point Completion Network This repository contains the PyTorch implementation of the paper: Variational Relational Point
 121 Dec 12, 2022
121 Dec 12, 2022
Activity image-based video retrieval
Cross-modal-retrieval Our approach is focus on Activity Image-to-Video Retrieval (AIVR) task. The compared methods are state-of-the-art single modalit
 75 Oct 21, 2021
75 Oct 21, 2021
Focus on Algorithm Design, Not on Data Wrangling
The dataTap Python library is the primary interface for using dataTap's rich data management tools. Create datasets, stream annotations, and analyze model performance all with one library.
 37 Nov 25, 2022
37 Nov 25, 2022

A Python package that provides evaluation and visualization tools for the DexYCB dataset
DexYCB Toolkit DexYCB Toolkit is a Python package that provides evaluation and visualization tools for the DexYCB dataset. The dataset and results wer
 107 Dec 26, 2022
107 Dec 26, 2022
This is the official implementation of 3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object Detection, built on SECOND.
3D-CVF This is the official implementation of 3D-CVF: Generating Joint Camera and LiDAR Features Using Cross-View Spatial Feature Fusion for 3D Object
 97 Dec 20, 2022
97 Dec 20, 2022

Official repository for Few-shot Image Generation via Cross-domain Correspondence (CVPR '21)
Few-shot Image Generation via Cross-domain Correspondence Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A. Efros, Yong Jae Lee, Eli Shechtman, Richard Zh
 251 Dec 11, 2022
251 Dec 11, 2022
Devkit for 3D -- Some utils for 3D object detection based on Numpy and Pytorch
D3D Devkit for 3D: Some utils for 3D object detection and tracking based on Numpy and Pytorch Please consider siting my work if you find this library
 27 Jul 7, 2022
27 Jul 7, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023

Implementation of Cross Transformer for spatially-aware few-shot transfer, in Pytorch
Cross Transformers - Pytorch (wip) Implementation of Cross Transformer for spatially-aware few-shot transfer, in Pytorch Install $ pip install cross-t
 40 Dec 22, 2022
40 Dec 22, 2022

《Where am I looking at? Joint Location and Orientation Estimation by Cross-View Matching》(CVPR 2020)
This contains the codes for cross-view geo-localization method described in: Where am I looking at? Joint Location and Orientation Estimation by Cross-View Matching, CVPR2020.
 41 Oct 27, 2022
41 Oct 27, 2022
Source code for the GPT-2 story generation models in the EMNLP 2020 paper "STORIUM: A Dataset and Evaluation Platform for Human-in-the-Loop Story Generation"
Storium GPT-2 Models This is the official repository for the GPT-2 models described in the EMNLP 2020 paper [STORIUM: A Dataset and Evaluation Platfor
 27 Dec 20, 2022
27 Dec 20, 2022
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 226 Dec 29, 2022
226 Dec 29, 2022
《Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis》(2021)
Image2Reverb Image2Reverb is an end-to-end neural network that generates plausible audio impulse responses from single images of acoustic environments
 48 Nov 27, 2022
48 Nov 27, 2022

SimDeblur is a simple framework for image and video deblurring, implemented by PyTorch
SimDeblur (Simple Deblurring) is an open source framework for image and video deblurring toolbox based on PyTorch, which contains most deep-learning based state-of-the-art deblurring algorithms. It is easy to implement your own image or video deblurring or other restoration algorithms.
 220 Jan 7, 2023
220 Jan 7, 2023
《LXMERT: Learning Cross-Modality Encoder Representations from Transformers》(EMNLP 2020)
The Most Important Thing. Our code is developed based on: LXMERT: Learning Cross-Modality Encoder Representations from Transformers
 53 Dec 16, 2022
53 Dec 16, 2022

Code for the paper "A Study of Face Obfuscation in ImageNet"
A Study of Face Obfuscation in ImageNet Code for the paper: A Study of Face Obfuscation in ImageNet Kaiyu Yang, Jacqueline Yau, Li Fei-Fei, Jia Deng,
 35 Oct 4, 2022
35 Oct 4, 2022
Code for CVPR 2021 paper: Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning This is the PyTorch companion code for the paper: A
 69 Jan 3, 2023
69 Jan 3, 2023
Leveraging Instance-, Image- and Dataset-Level Information for Weakly Supervised Instance Segmentation
Leveraging Instance-, Image- and Dataset-Level Information for Weakly Supervised Instance Segmentation This paper has been accepted and early accessed
 39 Sep 20, 2022
39 Sep 20, 2022
A Python utility belt containing simple tools, a stdlib like feel, and extra batteries. Hashing, Caching, Timing, Progress, and more made easy!
Ubelt is a small library of robust, tested, documented, and simple functions that extend the Python standard library. It has a flat API that all behav
 638 Dec 13, 2022
638 Dec 13, 2022
Common Voice Dataset explorer
Common Voice Dataset Explorer Common Voice Dataset is by Mozilla Made during huggingface finetuning week Usage pip install -r requirements.txt streaml
 22 Nov 16, 2022
22 Nov 16, 2022
scikit-learn cross validators for iterative stratification of multilabel data
iterative-stratification iterative-stratification is a project that provides scikit-learn compatible cross validators with stratification for multilab
 745 Jan 5, 2023
745 Jan 5, 2023

General purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabled, asynchronous and optimized for advanced GPU data processing usecases.
Vulkan Kompute The general purpose GPU compute framework for cross vendor graphics cards (AMD, Qualcomm, NVIDIA & friends). Blazing fast, mobile-enabl
 1k Dec 26, 2022
1k Dec 26, 2022
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment. With Qlib, you can easily try your ideas to create better Quant investment strategies.
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technol
10.1k Dec 31, 2022

Release of SPLASH: Dataset for semantic parse correction with natural language feedback in the context of text-to-SQL parsing
SPLASH: Semantic Parsing with Language Assistance from Humans SPLASH is dataset for the task of semantic parse correction with natural language feedba
 35 Oct 31, 2022
35 Oct 31, 2022
dataset for ECCV 2020 "Motion Capture from Internet Videos"
Motion Capture from Internet Videos Motion Capture from Internet Videos Junting Dong*, Qing Shuai*, Yuanqing Zhang, Xian Liu, Xiaowei Zhou, Hujun Bao
 98 Dec 7, 2022
98 Dec 7, 2022

CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent performances in several models such as Faster R-CNN, YOLOv4, RetinaNet and . There is a maximum AP improvement of 1.9% and an average AP of 0.8% improvement on MS COCO dataset, compared to traditional evaluation-feedback modules. Here we just use as an example to illustrate the code.
CDIoU-CDIoUloss CDIoU and CDIoU loss is like a convenient plug-in that can be used in multiple models. CDIoU and CDIoU loss have different excellent p
 24 Jul 19, 2022
24 Jul 19, 2022
Graviti TensorBay Python SDK
TensorBay Python SDK is a python library to access TensorBay and manage your datasets. It provides: A pythonic way to access your
 72 Aug 22, 2022
72 Aug 22, 2022
darija - english dictionary
darija-dictionary Having advanced IT solutions that are well adapted to the Moroccan context passes inevitably through understanding Moroccan dialect.
 102 Jan 1, 2023
102 Jan 1, 2023
![[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias](https://github.com/yuleiniu/cfvqa/raw/main/assets/cfvqa.png)
[CVPR 2021] Counterfactual VQA: A Cause-Effect Look at Language Bias
Counterfactual VQA (CF-VQA) This repository is the Pytorch implementation of our paper "Counterfactual VQA: A Cause-Effect Look at Language Bias" in C
 94 Dec 3, 2022
94 Dec 3, 2022

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023

Total Text Dataset. It consists of 1555 images with more than 3 different text orientations: Horizontal, Multi-Oriented, and Curved, one of a kind.
Total-Text-Dataset (Official site) Updated on April 29, 2020 (Detection leaderboard is updated - highlighted E2E methods. Thank you shine-lcy.) Update
 671 Dec 27, 2022
671 Dec 27, 2022
list all open dataset about ocr.
ocr-open-dataset list all open dataset about ocr. printed dataset year Born-Digital Images (Web and Email) 2011-2015 COCO-Text 2017 Text Extraction fr
 95 Nov 24, 2022
95 Nov 24, 2022

OCR system for Arabic language that converts images of typed text to machine-encoded text.
Arabic OCR OCR system for Arabic language that converts images of typed text to machine-encoded text. The system currently supports only letters (29 l
 144 Jan 5, 2023
144 Jan 5, 2023

Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector
CRAFT: Character-Region Awareness For Text detection Packaged, Pytorch-based, easy to use, cross-platform version of the CRAFT text detector | Paper |
 188 Dec 28, 2022
188 Dec 28, 2022
This repository provides train&test code, dataset, det.&rec. annotation, evaluation script, annotation tool, and ranking.
SCUT-CTW1500 Datasets We have updated annotations for both train and test set. Train: 1000 images [images][annos] Additional point annotation for each
 600 Dec 18, 2022
600 Dec 18, 2022
TableBank: A Benchmark Dataset for Table Detection and Recognition
TableBank TableBank is a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on th
 844 Jan 4, 2023
844 Jan 4, 2023

Use Convolutional Recurrent Neural Network to recognize the Handwritten line text image without pre segmentation into words or characters. Use CTC loss Function to train.
Handwritten Line Text Recognition using Deep Learning with Tensorflow Description Use Convolutional Recurrent Neural Network to recognize the Handwrit
 224 Jan 7, 2023
224 Jan 7, 2023

Handwritten_Text_Recognition
Deep Learning framework for Line-level Handwritten Text Recognition Short presentation of our project Introduction Installation 2.a Install conda envi
 24 Jul 15, 2022
24 Jul 15, 2022
This repository lets you train neural networks models for performing end-to-end full-page handwriting recognition using the Apache MXNet deep learning frameworks on the IAM Dataset.
Handwritten Text Recognition (OCR) with MXNet Gluon These notebooks have been created by Jonathan Chung, as part of his internship as Applied Scientis
 422 Jan 3, 2023
422 Jan 3, 2023

Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
Dataset Cartography Code for the paper Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics at EMNLP 2020. This repository cont
 125 Dec 22, 2022
125 Dec 22, 2022
Code and model benchmarks for "SEVIR : A Storm Event Imagery Dataset for Deep Learning Applications in Radar and Satellite Meteorology"
NeurIPS 2020 SEVIR Code for paper: SEVIR : A Storm Event Imagery Dataset for Deep Learning Applications in Radar and Satellite Meteorology Requirement
 46 Dec 15, 2022
46 Dec 15, 2022
A python script to lookup Passport Index Dataset
visa-cli A python script to lookup Passport Index Dataset Installation pip install visa-cli Usage usage: visa-cli [-h] [-d DESTINATION_COUNTRY] [-f]
 16 Oct 18, 2022
16 Oct 18, 2022
[CIKM 2019] Code and dataset for "Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Prediction"
FiGNN for CTR prediction The code and data for our paper in CIKM2019: Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Predicti
 75 Dec 30, 2022
75 Dec 30, 2022

Komodo Edit is a fast and free multi-language code editor. Written in JS, Python, C++ and based on the Mozilla platform.
Komodo Edit This readme explains how to get started building, using and developing with the Komodo Edit source base. Whilst the main Komodo Edit sourc
 2k Dec 28, 2022
2k Dec 28, 2022

Pytorch implementation of Each Part Matters: Local Patterns Facilitate Cross-view Geo-localization https://arxiv.org/abs/2008.11646
[TCSVT] Each Part Matters: Local Patterns Facilitate Cross-view Geo-localization LPN [Paper] NEWs Prerequisites Python 3.6 GPU Memory = 8G Numpy 1.
 46 Dec 14, 2022
46 Dec 14, 2022
Pupy is an opensource, cross-platform (Windows, Linux, OSX, Android) remote administration and post-exploitation tool mainly written in python
Pupy Installation Installation instructions are on the wiki, in addition to all other documentation. For maximum compatibility, it is recommended to u
 7.4k Jan 4, 2023
7.4k Jan 4, 2023