3636 Repositories
Python data-efficient-gan-training Libraries
Microsoft Azure provides a wide number of services for managing and storing data
Microsoft Azure provides a wide number of services for managing and storing data. One product is Microsoft Azure SQL. Which gives us the capability to create and manage instances of SQL Servers hosted in the cloud. This project, demonstrates how to use these services to manage data we collect from different sources.
 1 Dec 12, 2021
1 Dec 12, 2021

Upload an Excel/CSV file ( 200 MB) and produce a short summary of the data.
Data-Analysis-Report Deployed App 1. What is this app? Upload an excel/csv file and produce a summary report of the data. 2. Where to upload? How to p
 0 Feb 26, 2022
0 Feb 26, 2022

easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
easyNeuron is a simple way to create powerful machine learning models, analyze data and research cutting-edge AI.
 5 Jun 18, 2022
5 Jun 18, 2022
Search for files under the specified directory. Extract the file name and file path and import them as data.
Search for files under the specified directory. Extract the file name and file path and import them as data. Based on that, search for the file, select it and open it.
 2 Jan 10, 2022
2 Jan 10, 2022

Atari2600 Training / Evaluation with RLlib
Training Atari2600 by Reinforcement Learning Train Atari2600 and check how it works! How to Setup You can setup packages on your local env. $ make set
 1 Dec 12, 2021
1 Dec 12, 2021
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal
A lightweight library designed to accelerate the process of training PyTorch models by providing a minimal, but extensible training loop which is flexible enough to handle the majority of use cases, and capable of utilizing different hardware options with no code changes required.
 110 Dec 23, 2022
110 Dec 23, 2022
pandas-gbq is a package providing an interface to the Google BigQuery API from pandas
pandas-gbq pandas-gbq is a package providing an interface to the Google BigQuery API from pandas Installation Install latest release version via conda
 348 Jan 3, 2023
348 Jan 3, 2023
Utils for streaming large files (S3, HDFS, gzip, bz2...)
smart_open — utils for streaming large files in Python What? smart_open is a Python 3 library for efficient streaming of very large files from/to stor
 2.7k Jan 6, 2023
2.7k Jan 6, 2023
A system for quickly generating training data with weak supervision
Programmatically Build and Manage Training Data Announcement The Snorkel team is now focusing their efforts on Snorkel Flow, an end-to-end AI applicat
 5.4k Jan 2, 2023
5.4k Jan 2, 2023
Extract data from a wide range of Internet sources into a pandas DataFrame.
pandas-datareader Up to date remote data access for pandas, works for multiple versions of pandas. Installation Install using pip pip install pandas-d
 2.5k Jan 9, 2023
2.5k Jan 9, 2023
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of.
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of. Th
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
Synthetic Data Generation for tabular, relational and time series data.
An Open Source Project from the Data to AI Lab, at MIT Website: https://sdv.dev Documentation: https://sdv.dev/SDV User Guides Developer Guides Github
 1.2k Jan 7, 2023
1.2k Jan 7, 2023
Flexible HDF5 saving/loading and other data science tools from the University of Chicago
deepdish Flexible HDF5 saving/loading and other data science tools from the University of Chicago. This repository also host a Deep Learning blog: htt
 255 Dec 10, 2022
255 Dec 10, 2022
Python library for reading and writing tabular data via streams.
tabulator-py A library for reading and writing tabular data (csv/xls/json/etc). [Important Notice] We have released Frictionless Framework. This frame
 231 Dec 9, 2022
231 Dec 9, 2022
A common, beautiful interface to tabular data, no matter the format
rows No matter in which format your tabular data is: rows will import it, automatically detect types and give you high-level Python objects so you can
 834 Jan 3, 2023
834 Jan 3, 2023
Tools for test driven data-wrangling and data validation.
datatest: Test driven data-wrangling and data validation Datatest helps to speed up and formalize data-wrangling and data validation tasks. It impleme
 269 Dec 16, 2022
269 Dec 16, 2022
Tools for parsing messy tabular data.
Parsing for messy tables A library for dealing with messy tabular data in several formats, guessing types and detecting headers. See the documentation
 382 Nov 10, 2022
382 Nov 10, 2022
A wrapper library to read, manipulate and write data in xlsx and xlsm format using openpyxl
pyexcel-xlsx - Let you focus on data, instead of xlsx format pyexcel-xlsx is a tiny wrapper library to read, manipulate and write data in xlsx and xls
 110 Nov 16, 2022
110 Nov 16, 2022
Excalibur: A web interface to extract tabular data from PDFs
Excalibur: A web interface to extract tabular data from PDFs Excalibur is a web interface to extract tabular data from PDFs, written in Python 3! It i
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
Deep Difference and search of any Python object/data.
DeepDiff v 5.6.0 DeepDiff Overview DeepDiff: Deep Difference of dictionaries, iterables, strings and other objects. It will recursively look for all t
 1.6k Jan 8, 2023
1.6k Jan 8, 2023

Python supercharged for the fastai library
Welcome to fastcore Python goodies to make your coding faster, easier, and more maintainable Python is a powerful, dynamic language. Rather than bake
 810 Jan 6, 2023
810 Jan 6, 2023

Analyze, visualize and process sound field data recorded by spherical microphone arrays.
Sound Field Analysis toolbox for Python The sound_field_analysis toolbox (short: sfa) is a Python port of the Sound Field Analysis Toolbox (SOFiA) too
 69 Nov 23, 2022
69 Nov 23, 2022
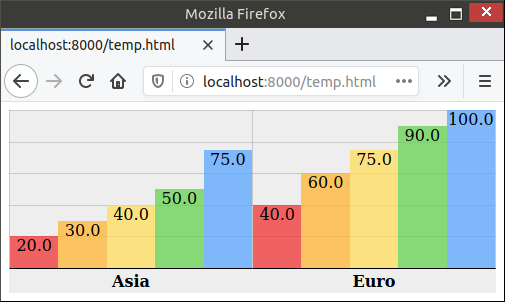
`charts.css.py` brings `charts.css` to Python. Online documentation and samples is available at the link below.
charts.css.py charts.css.py provides a python API to convert your 2-dimension data lists into html snippet, which will be rendered into charts by CSS,
 3 Sep 23, 2021
3 Sep 23, 2021

A dashboard built using Plotly-Dash for interactive visualization of Dex-connected individuals across the country.
Dashboard For The DexConnect Platform of Dexterity Global Working prototype submission for internship at Dexterity Global Group. Dashboard for real ti
 2 Jun 15, 2021
2 Jun 15, 2021
Larch: Applications and Python Library for Data Analysis of X-ray Absorption Spectroscopy (XAS, XANES, XAFS, EXAFS), X-ray Fluorescence (XRF) Spectroscopy and Imaging
Larch: Data Analysis Tools for X-ray Spectroscopy and More Documentation: http://xraypy.github.io/xraylarch Code: http://github.com/xraypy/xraylarch L
 95 Dec 13, 2022
95 Dec 13, 2022

A python-generated website for visualizing the novel coronavirus (COVID-19) data for Greece.
COVID-19-Greece A python-generated website for visualizing the novel coronavirus (COVID-19) data for Greece. Data sources Data provided by Johns Hopki
 23 Jan 3, 2023
23 Jan 3, 2023
Self-Supervised Image Denoising via Iterative Data Refinement
Self-Supervised Image Denoising via Iterative Data Refinement Yi Zhang1, Dasong Li1, Ka Lung Law2, Xiaogang Wang1, Hongwei Qin2, Hongsheng Li1 1CUHK-S
 8 Dec 11, 2021
8 Dec 11, 2021
The Pytorch implementation for "Video-Text Pre-training with Learned Regions"
Region_Learner The Pytorch implementation for "Video-Text Pre-training with Learned Regions" (arxiv) We are still cleaning up the code further and pre
 9 Dec 11, 2021
9 Dec 11, 2021

An efficient toolkit for Face Stylization based on the paper "AgileGAN: Stylizing Portraits by Inversion-Consistent Transfer Learning"
MMGEN-FaceStylor English | 简体中文 Introduction This repo is an efficient toolkit for Face Stylization based on the paper "AgileGAN: Stylizing Portraits
 182 Dec 27, 2022
182 Dec 27, 2022

Open-source codebase for EfficientZero, from "Mastering Atari Games with Limited Data" at NeurIPS 2021.
EfficientZero (NeurIPS 2021) Open-source codebase for EfficientZero, from "Mastering Atari Games with Limited Data" at NeurIPS 2021. Environments Effi
 671 Jan 3, 2023
671 Jan 3, 2023

Code for ShadeGAN (NeurIPS2021) A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis Project Page | Paper A Shading-Guided Generative Implicit Model
 71 Dec 10, 2021
71 Dec 10, 2021
Official code for "Maximum Likelihood Training of Score-Based Diffusion Models", NeurIPS 2021 (spotlight)
Maximum Likelihood Training of Score-Based Diffusion Models This repo contains the official implementation for the paper Maximum Likelihood Training o
 84 Dec 12, 2022
84 Dec 12, 2022
Python3 library that can retrieve Chrome-based browser's saved login info.
Passax EDUCATIONAL PURPOSES ONLY Python3 library that can retrieve Chrome-based browser's saved login info. Requirements secretstorage~=3.3.1 pywin32=
 1 Jan 25, 2022
1 Jan 25, 2022
Python script that extract data via YouTube Api and manipulates it.
UNLIMITED README for the Unlimited game [Mining game] Explore the docs » View Demo · Report Bug · Request Feature Table of Contents About The Project
 1 Dec 12, 2021
1 Dec 12, 2021

This script has been created in order to find what are the most common demanded technologies in Data Engineering field.
This is a Python script that given a whole corpus of job descriptions and a file with keywords it extracts the number of number of ocurrences of these keywords and write it to a file. This script it is easy to extend to accept more functionalities
 0 Jul 17, 2022
0 Jul 17, 2022
Kodi script for proper Australian weather data
Kodi Oz Weather weather.ozweather Script for Kodi for high quality Australian weather data sourced directly from the BOM. Available from the Kodi offi
 5 Nov 24, 2022
5 Nov 24, 2022
A Python package for Misty II development
Misty2py Misty2py is a Python 3 package for Misty II development using Misty's REST API. Read the full documentation here! Installation Poetry To inst
 1 Mar 7, 2022
1 Mar 7, 2022

rastrainer is a QGIS plugin to training remote sensing semantic segmentation model based on PaddlePaddle.
rastrainer rastrainer is a QGIS plugin to training remote sensing semantic segmentation model based on PaddlePaddle. UI TODO Init UI. Add Block. Add l
 5 Mar 4, 2022
5 Mar 4, 2022
Code for the AAAI-2022 paper: Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification (AAAI 2022) Prerequisite PyTorch = 1.2.0 P
 16 Dec 14, 2022
16 Dec 14, 2022

Unimodal Face Classification with Multimodal Training
Unimodal Face Classification with Multimodal Training This is a PyTorch implementation of the following paper: Unimodal Face Classification with Multi
 3 Jul 6, 2022
3 Jul 6, 2022
Official Implementation of SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Official Implementation of SimIPU SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations Since
 37 Dec 1, 2022
37 Dec 1, 2022
Evaluating saliency methods on artificial data with different background types
Evaluating saliency methods on artificial data with different background types This repository contains the relevant code for the MedNeurips 2021 subm
 2 Jul 5, 2022
2 Jul 5, 2022

Official source code of paper 'IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo'
IterMVS official source code of paper 'IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo' Introduction IterMVS is a novel lear
 127 Jan 4, 2023
127 Jan 4, 2023
ScisorWiz: Differential Isoform Visualizer for Long-Read RNA Sequencing Data
ScisorWiz: Vizualizer for Differential Isoform Expression README ScisorWiz is a linux-based R-package for visualizing differential isoform expression
 6 Oct 4, 2022
6 Oct 4, 2022
Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data.
Deep Learning Dataset Maker Deep Learning Datasets Maker is a QGIS plugin to make datasets creation easier for raster and vector data. How to use Down
25 Dec 15, 2022
The test data, code and detailed description of the AW t-SNE algorithm
AW-t-SNE The test data, code and result of the AW t-SNE algorithm Structure of the folder Datasets: This folder contains two datasets, the MNIST datas
 1 Mar 9, 2022
1 Mar 9, 2022
Validation and inference over LinkML instance data using souffle
Translates LinkML schemas into Datalog programs and executes them using Souffle, enabling advanced validation and inference over instance data
 7 Aug 7, 2022
7 Aug 7, 2022
Python Data Structures and Algorithms
No non-sense and no BS repo for how data structure code should be in Python - simple and elegant.
 1.9k Jan 8, 2023
1.9k Jan 8, 2023

 9.3k Jan 7, 2023
9.3k Jan 7, 2023
Haphazard scripts for scraping bitcoin/bitcoin data from GitHub
This is a quick-and-dirty tool used to scrape bitcoin/bitcoin pull request and commentary data. Each output/pr number folder contains comments.json:
 8 Oct 12, 2022
8 Oct 12, 2022

An implementation of the methods presented in Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data.
An implementation of the methods presented in Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data.
 9 Apr 4, 2022
9 Apr 4, 2022

VarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
VarCLR: Variable Representation Pre-training via Contrastive Learning New: Paper accepted by ICSE 2022. Preprint at arXiv! This repository contain
 14 Dec 10, 2021
14 Dec 10, 2021

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023

Code for CVPR2019 paper《Unequal Training for Deep Face Recognition with Long Tailed Noisy Data》
Unequal-Training-for-Deep-Face-Recognition-with-Long-Tailed-Noisy-Data. This is the code of CVPR 2019 paper《Unequal Training for Deep Face Recognition
 68 Jan 7, 2023
68 Jan 7, 2023
![[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning](https://github.com/YyzHarry/imbalanced-semi-self/raw/master/assets/tsne_semi.png)
[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning
Rethinking the Value of Labels for Improving Class-Imbalanced Learning This repository contains the implementation code for paper: Rethinking the Valu
 656 Dec 28, 2022
656 Dec 28, 2022

Conceptual 12M is a dataset containing (image-URL, caption) pairs collected for vision-and-language pre-training.
Conceptual 12M We introduce the Conceptual 12M (CC12M), a dataset with ~12 million image-text pairs meant to be used for vision-and-language pre-train
 226 Dec 7, 2022
226 Dec 7, 2022
Repo for CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
CReST in Tensorflow 2 Code for the paper: "CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning" by Chen Wei, Ki
 75 Nov 1, 2022
75 Nov 1, 2022

Supercharging Imbalanced Data Learning WithCausal Representation Transfer
ECRT: Energy-based Causal Representation Transfer Code for Supercharging Imbalanced Data Learning With Energy-basedContrastive Representation Transfer
 11 May 2, 2022
11 May 2, 2022
Machine Learning automation and tracking
The Open-Source MLOps Orchestration Framework MLRun is an open-source MLOps framework that offers an integrative approach to managing your machine-lea
 873 Jan 4, 2023
873 Jan 4, 2023
ZenML 🙏: MLOps framework to create reproducible ML pipelines for production machine learning.
ZenML is an extensible, open-source MLOps framework to create production-ready machine learning pipelines. It has a simple, flexible syntax, is cloud and tool agnostic, and has interfaces/abstractions that are catered towards ML workflows.
 2.6k Dec 27, 2022
2.6k Dec 27, 2022

Kubernetes-native workflow automation platform for complex, mission-critical data and ML processes at scale. It has been battle-tested at Lyft, Spotify, Freenome, and others and is truly open-source.
Flyte Flyte is a workflow automation platform for complex, mission-critical data, and ML processes at scale Home Page · Quick Start · Documentation ·
 3k Jan 1, 2023
3k Jan 1, 2023

Reproducible Data Science at Scale!
Pachyderm: The Data Foundation for Machine Learning Pachyderm provides the data layer that allows machine learning teams to productionize and scale th
 5.7k Dec 29, 2022
5.7k Dec 29, 2022
A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch.
WebDataset WebDataset is a PyTorch Dataset (IterableDataset) implementation providing efficient access to datasets stored in POSIX tar archives and us
 1.1k Jan 8, 2023
1.1k Jan 8, 2023
Uni-Fold: Training your own deep protein-folding models.
Uni-Fold: Training your own deep protein-folding models. This package provides and implementation of a trainable, Transformer-based deep protein foldi
 88 Jan 3, 2023
88 Jan 3, 2023
Torchrecipes provides a set of reproduci-able, re-usable, ready-to-run RECIPES for training different types of models, across multiple domains, on PyTorch Lightning.
Recipes are a standard, well supported set of blueprints for machine learning engineers to rapidly train models using the latest research techniques without significant engineering overhead.Specifically, recipes aims to provide- Consistent access to pre-trained SOTA models ready for production- Reference implementations for SOTA research reproducibility, and infrastructure to guarantee correctness, efficiency, and interoperability.
 193 Dec 28, 2022
193 Dec 28, 2022
Existing Literature about Machine Unlearning
Machine Unlearning Papers 2021 Brophy and Lowd. Machine Unlearning for Random Forests. In ICML 2021. Bourtoule et al. Machine Unlearning. In IEEE Symp
 213 Jan 8, 2023
213 Jan 8, 2023

Pytorch Implementations of large number classical backbone CNNs, data enhancement, torch loss, attention, visualization and some common algorithms.
Torch-template-for-deep-learning Pytorch implementations of some **classical backbone CNNs, data enhancement, torch loss, attention, visualization and
 270 Dec 31, 2022
270 Dec 31, 2022
Garbage classification using structure data.
垃圾分类模型使用说明 1.包含以下数据文件 文件 描述 data/MaterialMapping.csv 物体以及其归类的信息 data/TestRecords 光谱原始测试数据 CSV 文件 data/TestRecordDesc.zip CSV 文件描述文件 data/Boundaries.cs
 1 Dec 10, 2021
1 Dec 10, 2021
Discord bot ( discord.py ), uses pandas library from python for data-management.
Discord_bot A Best and the most easy-to-use Discord bot !! Some simple basic auto moderations, Chat functions. It includes a game similar to Casino, g
 4 Aug 30, 2022
4 Aug 30, 2022

Official PyTorch Implementation of GAN-Supervised Dense Visual Alignment
GAN-Supervised Dense Visual Alignment — Official PyTorch Implementation Paper | Project Page | Video This repo contains training, evaluation and visua
 944 Jan 7, 2023
944 Jan 7, 2023
iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
435 Jan 6, 2023

Make dbt docs and Apache Superset talk to one another
dbt-superset-lineage Make dbt docs and Apache Superset talk to one another Why do I need something like this? Odds are rather high that you use dbt to
 81 Jan 6, 2023
81 Jan 6, 2023
A simple and lightweight genetic algorithm for optimization of any machine learning model
geneticml This package contains a simple and lightweight genetic algorithm for optimization of any machine learning model. Installation Use pip to ins
 8 Aug 10, 2022
8 Aug 10, 2022
KIDA: Knowledge Inheritance in Data Aggregation
KIDA: Knowledge Inheritance in Data Aggregation This project releases our 1st place solution on NeurIPS2021 ML4CO Dual Task. Slide and model weights a
 24 Sep 8, 2022
24 Sep 8, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
Model Validation Toolkit is a collection of tools to assist with validating machine learning models prior to deploying them to production and monitoring them after deployment to production.
 25 Dec 28, 2022
25 Dec 28, 2022
Does MAML Only Work via Feature Re-use? A Data Set Centric Perspective
Does-MAML-Only-Work-via-Feature-Re-use-A-Data-Set-Centric-Perspective Does MAML Only Work via Feature Re-use? A Data Set Centric Perspective Installin
 2 Nov 7, 2022
2 Nov 7, 2022

Python scripts for plotting audiograms and related data from Interacoustics Equinox audiometer and Otoaccess software.
audiometry Python scripts for plotting audiograms and related data from Interacoustics Equinox 2.0 audiometer and Otoaccess software. Maybe similar sc
 2 Jun 15, 2022
2 Jun 15, 2022

Data Analysis for First Year Laboratory at Imperial College, London.
Data Analysis for First Year Laboratory at Imperial College, London. For personal reference only, and to reference in lab reports and lab books.
 0 Aug 29, 2022
0 Aug 29, 2022
Training code for Korean multi-class sentiment analysis
KoSentimentAnalysis Bert implementation for the Korean multi-class sentiment analysis 왜 한국어 감정 다중분류 모델은 거의 없는 것일까?에서 시작된 프로젝트 Environment: Pytorch, Da
 3 Dec 2, 2022
3 Dec 2, 2022
This is a project of data parallel that running on NLP tasks.
This is a project of data parallel that running on NLP tasks.
 2 Dec 12, 2021
2 Dec 12, 2021
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
 1 Dec 9, 2021
1 Dec 9, 2021
DANet for Tabular data classification/ regression.
Deep Abstract Networks A PyTorch code implemented for the submission DANets: Deep Abstract Networks for Tabular Data Classification and Regression. Do
 55 Sep 14, 2022
55 Sep 14, 2022
Parameter Efficient Deep Probabilistic Forecasting
PEDPF Parameter Efficient Deep Probabilistic Forecasting (PEDPF) is a repository containing code to run experiments for several deep learning based pr
 10 Jun 13, 2022
10 Jun 13, 2022

GLIP: Grounded Language-Image Pre-training
GLIP: Grounded Language-Image Pre-training Updates 12/06/2021: GLIP paper on arxiv https://arxiv.org/abs/2112.03857. Code and Model are under internal
 862 Jan 1, 2023
862 Jan 1, 2023

Package for extracting emotions from social media text. Tailored for financial data.
EmTract: Extracting Emotions from Social Media Text Tailored for Financial Contexts EmTract is a tool that extracts emotions from social media text. I
 13 Nov 17, 2022
13 Nov 17, 2022
BrainGNN - A deep learning model for data-driven discovery of functional connectivity
A deep learning model for data-driven discovery of functional connectivity https://doi.org/10.3390/a14030075 Usman Mahmood, Zengin Fu, Vince D. Calhou
 3 Aug 28, 2022
3 Aug 28, 2022

Multiview 3D object detection on MultiviewC dataset through moft3d.
Voxelized 3D Feature Aggregation for Multiview Detection [arXiv] Multiview 3D object detection on MultiviewC dataset through VFA. Introduction We prop
 20 Dec 21, 2022
20 Dec 21, 2022
This repository is an implementation of paper : Improving the Training of Graph Neural Networks with Consistency Regularization
CRGNN Paper : Improving the Training of Graph Neural Networks with Consistency Regularization Environments Implementing environment: GeForce RTX™ 3090
28 Dec 9, 2022
Unofficial implementation of "Coordinate Attention for Efficient Mobile Network Design"
Unofficial implementation of "Coordinate Attention for Efficient Mobile Network Design". CoordAttention tensorflow slim
 9 Aug 22, 2022
9 Aug 22, 2022
Official PyTorch implementation of the ICRA 2021 paper: Adversarial Differentiable Data Augmentation for Autonomous Systems.
Adversarial Differentiable Data Augmentation This repository provides the official PyTorch implementation of the ICRA 2021 paper: Adversarial Differen
 3 Oct 15, 2022
3 Oct 15, 2022
Projeto job insights - Projeto avaliativo da Trybe do Bloco 32: Introdução à Python
Termos e acordos Ao iniciar este projeto, você concorda com as diretrizes do Código de Ética e Conduta e do Manual da Pessoa Estudante da Trybe. Boas
 1 Dec 9, 2021
1 Dec 9, 2021
A data driven app for bicycle hiring in London(UK)
bicycle_hiring_app_deployed A data driven app for bicycle hiring in London(UK). It predicts expected number of bicycle hire in London. It asks users t
 1 Dec 10, 2021
1 Dec 10, 2021
Post-Training Quantization for Vision transformers.
PTQ4ViT Post-Training Quantization Framework for Vision Transformers. We use the twin uniform quantization method to reduce the quantization error on
 61 Dec 28, 2022
61 Dec 28, 2022

This is a re-implementation of TransGAN: Two Pure Transformers Can Make One Strong GAN (CVPR 2021) in PyTorch.
TransGAN: Two Transformers Can Make One Strong GAN [YouTube Video] Paper Authors: Yifan Jiang, Shiyu Chang, Zhangyang Wang CVPR 2021 This is re-implem
 79 Jan 5, 2023
79 Jan 5, 2023

Script to create an animated data visualisation for categorical timeseries data - GIF choropleth map with annotations.
choropleth_ldn Simple script to create a chloropleth map of London with categorical timeseries data. The script in main.py creates a gif of the most f
 1 Oct 7, 2021
1 Oct 7, 2021
PyTorch implementation for OCT-GAN Neural ODE-based Conditional Tabular GANs (WWW 2021)
OCT-GAN: Neural ODE-based Conditional Tabular GANs (OCT-GAN) Code for reproducing the experiments in the paper: Jayoung Kim*, Jinsung Jeon*, Jaehoon L
 7 Dec 27, 2022
7 Dec 27, 2022
Uni-Fold: Training your own deep protein-folding models
Uni-Fold: Training your own deep protein-folding models. This package provides an implementation of a trainable, Transformer-based deep protein foldin
 187 Jan 4, 2023
187 Jan 4, 2023
Simple Python project using Opencv and datetime package to recognise faces and log attendance data in a csv file.
Attendance-System-based-on-Facial-recognition-Attendance-data-stored-in-csv-file- Simple Python project using Opencv and datetime package to recognise
 3 Aug 9, 2022
3 Aug 9, 2022
Extracts data from the database for a graph-node and stores it in parquet files
subgraph-extractor Extracts data from the database for a graph-node and stores it in parquet files Installation For developing, it's recommended to us
 0 Jan 10, 2022
0 Jan 10, 2022