262 Repositories
Python policy-gradient-with-baseline Libraries
MagTape is a Policy-as-Code tool for Kubernetes that allows for evaluating Kubernetes resources against a set of defined policies to inform and enforce best practice configurations.
MagTape is a Policy-as-Code tool for Kubernetes that allows for evaluating Kubernetes resources against a set of defined policies to inform and enforce best practice configurations. MagTape includes variable policy enforcement, notifications, and targeted metrics.
 143 Dec 27, 2022
143 Dec 27, 2022

Code and models for "Pano3D: A Holistic Benchmark and a Solid Baseline for 360 Depth Estimation", OmniCV Workshop @ CVPR21.
Pano3D A Holistic Benchmark and a Solid Baseline for 360o Depth Estimation Pano3D is a new benchmark for depth estimation from spherical panoramas. We
 50 Dec 29, 2022
50 Dec 29, 2022

Gym environments used in the paper: "Developmental Reinforcement Learning of Control Policy of a Quadcopter UAV with Thrust Vectoring Rotors"
gym_multirotor Gym to train reinforcement learning agents on UAV platforms Quadrotor Tiltrotor Requirements This package has been tested on Ubuntu 18.
 19 Dec 29, 2022
19 Dec 29, 2022

Safe Policy Optimization with Local Features
Safe Policy Optimization with Local Feature (SPO-LF) This is the source-code for implementing the algorithms in the paper "Safe Policy Optimization wi
 6 Jun 5, 2022
6 Jun 5, 2022
6D Grasping Policy for Point Clouds
GA-DDPG [website, paper] Installation git clone https://github.com/liruiw/GA-DDPG.git --recursive Setup: Ubuntu 16.04 or above, CUDA 10.0 or above, py
 48 Dec 21, 2022
48 Dec 21, 2022
The ARCA23K baseline system
ARCA23K Baseline System This is the source code for the baseline system associated with the ARCA23K dataset. Details about ARCA23K and the baseline sy
 4 Jul 2, 2022
4 Jul 2, 2022
Safe Policy Optimization with Local Features
Safe Policy Optimization with Local Feature (SPO-LF) This is the source-code for implementing the algorithms in the paper "Safe Policy Optimization wi
6 Jun 5, 2022
Code for Greedy Gradient Ensemble for Visual Question Answering (ICCV 2021, Oral)
Greedy Gradient Ensemble for De-biased VQA Code release for "Greedy Gradient Ensemble for Robust Visual Question Answering" (ICCV 2021, Oral). GGE can
 21 Jun 29, 2022
21 Jun 29, 2022

(ICCV 2021 Oral) Re-distributing Biased Pseudo Labels for Semi-supervised Semantic Segmentation: A Baseline Investigation.
DARS Code release for the paper "Re-distributing Biased Pseudo Labels for Semi-supervised Semantic Segmentation: A Baseline Investigation", ICCV 2021
 58 Jan 1, 2023
58 Jan 1, 2023

MAUS: A Dataset for Mental Workload Assessment Using Wearable Sensor - Baseline system
MAUS: A Dataset for Mental Workload Assessment Using Wearable Sensor - Baseline system Getting started To start working on this assignment, you should
 2 Aug 6, 2022
2 Aug 6, 2022
PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch.
snn-localization repo PyTorch implementation of Spiking Neural Networks trained on surrogate gradient & BPTT using snntorch. Install Dependencies Orig
 1 Jan 6, 2022
1 Jan 6, 2022
Trains an agent with stochastic policy gradient ascent to solve the Lunar Lander challenge from OpenAI
Introduction This script trains an agent with stochastic policy gradient ascent to solve the Lunar Lander challenge from OpenAI. In order to run this
 0 Jan 2, 2022
0 Jan 2, 2022

This tool allows to automatically test for Content Security Policy bypass payloads.
CSPass This tool allows to automatically test for Content Security Policy bypass payloads. Usage [cspass]$ ./cspass.py -h usage: cspass.py [-h] [--no-
 30 Nov 22, 2022
30 Nov 22, 2022

Official implementation of Generalized Data Weighting via Class-level Gradient Manipulation (NeurIPS 2021).
Generalized Data Weighting via Class-level Gradient Manipulation This repository is the official implementation of Generalized Data Weighting via Clas
 9 Nov 3, 2021
9 Nov 3, 2021
Baseline is a cross-platform library and command-line utility that creates file-oriented baselines of your systems.
Baselining, on steroids! Baseline is a cross-platform library and command-line utility that creates file-oriented baselines of your systems. The proje
 4 Dec 9, 2022
4 Dec 9, 2022
Generalized Proximal Policy Optimization with Sample Reuse (GePPO)
Generalized Proximal Policy Optimization with Sample Reuse This repository is the official implementation of the reinforcement learning algorithm Gene
 9 Nov 28, 2022
9 Nov 28, 2022
Generalized Data Weighting via Class-level Gradient Manipulation
Generalized Data Weighting via Class-level Gradient Manipulation This repository is the official implementation of Generalized Data Weighting via Clas
18 Nov 12, 2022

The command line interface for Gradient - Gradient is an an end-to-end MLOps platform
Gradient CLI Get started: Create Account • Install CLI • Tutorials • Docs Resources: Website • Blog • Support • Contact Sales Gradient is an an end-to
 58 Dec 6, 2022
58 Dec 6, 2022
[NeurIPS 2021] Official implementation of paper "Learning to Simulate Self-driven Particles System with Coordinated Policy Optimization".
Code for Coordinated Policy Optimization Webpage | Code | Paper | Talk (English) | Talk (Chinese) Hi there! This is the source code of the paper “Lear
 81 Dec 19, 2022
81 Dec 19, 2022
Gradient representations in ReLU networks as similarity functions
Gradient representations in ReLU networks as similarity functions by Dániel Rácz and Bálint Daróczy. This repo contains the python code related to our
 1 Oct 8, 2021
1 Oct 8, 2021
CARMS: Categorical-Antithetic-REINFORCE Multi-Sample Gradient Estimator
CARMS: Categorical-Antithetic-REINFORCE Multi-Sample Gradient Estimator This is the official code repository for NeurIPS 2021 paper: CARMS: Categorica
 1 Jul 9, 2022
1 Jul 9, 2022

Learning where to learn - Gradient sparsity in meta and continual learning
Learning where to learn - Gradient sparsity in meta and continual learning In this paper, we investigate gradient sparsity found by MAML in various co
 28 Dec 9, 2022
28 Dec 9, 2022

Gradient Inversion with Generative Image Prior
Gradient Inversion with Generative Image Prior This repository is an implementation of "Gradient Inversion with Generative Image Prior", accepted to N
 25 Jan 9, 2023
25 Jan 9, 2023
Iterative stochastic gradient descent (SGD) linear regressor with regularization
SGD-Linear-Regressor Iterative stochastic gradient descent (SGD) linear regressor with regularization Dataset: Kaggle “Graduate Admission 2” https://w
 1 Oct 29, 2021
1 Oct 29, 2021
PyTorch implementation of "A Simple Baseline for Low-Budget Active Learning".
A Simple Baseline for Low-Budget Active Learning This repository is the implementation of A Simple Baseline for Low-Budget Active Learning. In this pa
 10 Nov 14, 2022
10 Nov 14, 2022

An implementation of the proximal policy optimization algorithm
PPO Pytorch C++ This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch. It uses a simple TestEnvironment t
 59 Dec 9, 2022
59 Dec 9, 2022

PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL).
PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL).
 3k Dec 31, 2022
3k Dec 31, 2022

Off-policy continuous control in PyTorch, with RDPG, RTD3 & RSAC
arXiv technical report soon available. we are updating the readme to be as comprehensive as possible Please ask any questions in Issues, thanks. Intro
 31 Dec 30, 2022
31 Dec 30, 2022
Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app.
django-permissions-policy Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app. Requirements Python 3.
 78 Jan 2, 2023
78 Jan 2, 2023
Time Discretization-Invariant Safe Action Repetition for Policy Gradient Methods
Time Discretization-Invariant Safe Action Repetition for Policy Gradient Methods This repository is the official implementation of Seohong Park, Jaeky
 6 Aug 2, 2022
6 Aug 2, 2022
Stochastic Gradient Trees implementation in Python
Stochastic Gradient Trees - Python Stochastic Gradient Trees1 by Henry Gouk, Bernhard Pfahringer, and Eibe Frank implementation in Python. Based on th
 2 Nov 18, 2022
2 Nov 18, 2022
[WACV 2022] Contextual Gradient Scaling for Few-Shot Learning
CxGrad - Official PyTorch Implementation Contextual Gradient Scaling for Few-Shot Learning Sanghyuk Lee, Seunghyun Lee, and Byung Cheol Song In WACV 2
 4 Dec 5, 2022
4 Dec 5, 2022
MEND: Model Editing Networks using Gradient Decomposition
MEND: Model Editing Networks using Gradient Decomposition Setup Environment This codebase uses Python 3.7.9. Other versions may work as well. Create a
 141 Dec 2, 2022
141 Dec 2, 2022
Baseline model for Augmented Home Assistant
Dataset Preparation Step 1. Rename the Virtual-Home output directory to 'vh.[name]', for example: 'vh.door' Make sure the directory contains 100+ fram
 1 Aug 24, 2022
1 Aug 24, 2022
A new mini-batch framework for optimal transport in deep generative models, deep domain adaptation, approximate Bayesian computation, color transfer, and gradient flow.
BoMb-OT Python3 implementation of the papers On Transportation of Mini-batches: A Hierarchical Approach and Improving Mini-batch Optimal Transport via
 18 Nov 14, 2022
18 Nov 14, 2022

Project code for weakly supervised 3D object detectors using wide-baseline multi-view traffic camera data: WIBAM.
WIBAM (Work in progress) Weakly Supervised Training of Monocular 3D Object Detectors Using Wide Baseline Multi-view Traffic Camera Data 3D object dete
 10 Aug 24, 2022
10 Aug 24, 2022
MBPO (paper: When to trust your model: Model-based policy optimization) in offline RL settings
offline-MBPO This repository contains the code of a version of model-based RL algorithm MBPO, which is modified to perform in offline RL settings Pape
 1 Oct 24, 2021
1 Oct 24, 2021
Deep Reinforcement Learning by using an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO)
V-MPO Simple code to demonstrate Deep Reinforcement Learning by using an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) in Pyt
 9 Jun 6, 2022
9 Jun 6, 2022

Ranger - a synergistic optimizer using RAdam (Rectified Adam), Gradient Centralization and LookAhead in one codebase
Ranger-Deep-Learning-Optimizer Ranger - a synergistic optimizer combining RAdam (Rectified Adam) and LookAhead, and now GC (gradient centralization) i
 1.1k Dec 21, 2022
1.1k Dec 21, 2022

Official PyTorch implementation of "Edge Rewiring Goes Neural: Boosting Network Resilience via Policy Gradient".
Edge Rewiring Goes Neural: Boosting Network Resilience via Policy Gradient This repository is the official PyTorch implementation of "Edge Rewiring Go
 4 Dec 12, 2022
4 Dec 12, 2022

PyTorch implementation of Constrained Policy Optimization
PyTorch implementation of Constrained Policy Optimization (CPO) This repository has a simple to understand and use implementation of CPO in PyTorch. A
 25 Dec 8, 2022
25 Dec 8, 2022
Gradient-free global optimization algorithm for multidimensional functions based on the low rank tensor train format
ttopt Description Gradient-free global optimization algorithm for multidimensional functions based on the low rank tensor train (TT) format and maximu
 5 May 23, 2022
5 May 23, 2022
[ICCV 2021] A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
[ICCV 2021] A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
 45 Dec 12, 2022
45 Dec 12, 2022
ProMP: Proximal Meta-Policy Search
ProMP: Proximal Meta-Policy Search Implementations corresponding to ProMP (Rothfuss et al., 2018). Overall this repository consists of two branches: m
 212 Dec 20, 2022
212 Dec 20, 2022
Progressive Image Deraining Networks: A Better and Simpler Baseline
Progressive Image Deraining Networks: A Better and Simpler Baseline [arxiv] [pdf] [supp] Introduction This paper provides a better and simpler baselin
 190 Dec 1, 2022
190 Dec 1, 2022
Baseline of DCASE 2020 task 4
Couple Learning for SED This repository provides the data and source code for sound event detection (SED) task. The improvement of the Couple Learning
 21 Oct 18, 2022
21 Oct 18, 2022
CAPITAL: Optimal Subgroup Identification via Constrained Policy Tree Search
CAPITAL: Optimal Subgroup Identification via Constrained Policy Tree Search This repository is the official implementation of CAPITAL: Optimal Subgrou
 0 Oct 19, 2021
0 Oct 19, 2021

BasicRL: easy and fundamental codes for deep reinforcement learning。It is an improvement on rainbow-is-all-you-need and OpenAI Spinning Up.
BasicRL: easy and fundamental codes for deep reinforcement learning BasicRL is an improvement on rainbow-is-all-you-need and OpenAI Spinning Up. It is
 12 Apr 28, 2022
12 Apr 28, 2022

A game theoretic approach to explain the output of any machine learning model.
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allo
 18.2k Jan 2, 2023
18.2k Jan 2, 2023

Simple Python tool that generates a pseudo-random password with numbers, letters, and special characters in accordance with password policy best practices.
Simple Python tool that generates a pseudo-random password with numbers, letters, and special characters in accordance with password policy best practices.
 7 Mar 25, 2022
7 Mar 25, 2022

Gradient Step Denoiser for convergent Plug-and-Play
Source code for the paper "Gradient Step Denoiser for convergent Plug-and-Play"
 11 Sep 17, 2022
11 Sep 17, 2022
Training vision models with full-batch gradient descent and regularization
Stochastic Training is Not Necessary for Generalization -- Training competitive vision models without stochasticity This repository implements trainin
 32 Jan 6, 2023
32 Jan 6, 2023

Official Implementation of 'UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers' ICLR 2021(spotlight)
UPDeT Official Implementation of UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers (ICLR 2021 spotlight) The
 96 Dec 22, 2022
96 Dec 22, 2022
Wonk is a tool for combining a set of AWS policy files into smaller compiled policy sets.
Wonk is a tool for combining a set of AWS policy files into smaller compiled policy sets.
 140 Dec 16, 2022
140 Dec 16, 2022

Pytorch implementation of convolutional neural network visualization techniques
Convolutional Neural Network Visualizations This repository contains a number of convolutional neural network visualization techniques implemented in
 7k Jan 3, 2023
7k Jan 3, 2023

ilpyt: imitation learning library with modular, baseline implementations in Pytorch
ilpyt The imitation learning toolbox (ilpyt) contains modular implementations of common deep imitation learning algorithms in PyTorch, with unified in
 11 Nov 17, 2022
11 Nov 17, 2022
Tutorial for surrogate gradient learning in spiking neural networks
SpyTorch A tutorial on surrogate gradient learning in spiking neural networks Version: 0.4 This repository contains tutorial files to get you started
 203 Nov 28, 2022
203 Nov 28, 2022
A PyTorch implementation of Learning to learn by gradient descent by gradient descent
Intro PyTorch implementation of Learning to learn by gradient descent by gradient descent. Run python main.py TODO Initial implementation Toy data LST
300 Dec 11, 2022

Conditional probing: measuring usable information beyond a baseline
Conditional probing: measuring usable information beyond a baseline
 20 Dec 15, 2022
20 Dec 15, 2022

TensorFlow implementation of "A Simple Baseline for Bayesian Uncertainty in Deep Learning"
TensorFlow implementation of "A Simple Baseline for Bayesian Uncertainty in Deep Learning"
 7 Aug 28, 2022
7 Aug 28, 2022
ppo_pytorch_cpp - an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch
PPO Pytorch C++ This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch. It uses a simple TestEnvironment t
59 Dec 9, 2022

Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286
Pytorch-DPPO Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286 Using PPO with clip loss (from https
 163 Dec 26, 2022
163 Dec 26, 2022
A PyTorch implementation of Learning to learn by gradient descent by gradient descent
Intro PyTorch implementation of Learning to learn by gradient descent by gradient descent. Run python main.py TODO Initial implementation Toy data LST
300 Dec 11, 2022
Implementation of algorithms for continuous control (DDPG and NAF).
DEPRECATION This repository is deprecated and is no longer maintaned. Please see a more recent implementation of RL for continuous control at jax-sac.
288 Dec 31, 2022

A PyTorch implementation of the baseline method in Panoptic Narrative Grounding (ICCV 2021 Oral)
A PyTorch implementation of the baseline method in Panoptic Narrative Grounding (ICCV 2021 Oral)
 52 Dec 19, 2022
52 Dec 19, 2022

Demonstration that AWS IAM policy evaluation docs are incorrect
The flowchart from the AWS IAM policy evaluation documentation page, as of 2021-09-12, and dating back to at least 2018-12-27, is the following: The f
 15 Oct 21, 2022
15 Oct 21, 2022

PPO is a very popular Reinforcement Learning algorithm at present.
PPO is a very popular Reinforcement Learning algorithm at present. OpenAI takes PPO as the current baseline algorithm. We use the PPO algorithm to train a policy to give the best action in any situation.
 11 Aug 23, 2021
11 Aug 23, 2021

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
An efficient framework for reinforcement learning.
rl: An efficient framework for reinforcement learning Requirements Introduction PPO Test Requirements name version Python =3.7 numpy =1.19 torch =1
 16 Nov 30, 2022
16 Nov 30, 2022
VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection (ICCV 2021)
Preparation Please see dataset/README.md to get more details about our datasets-VIL100 Please see INSTALL.md to install environment and evaluation too
 82 Dec 15, 2022
82 Dec 15, 2022
Pytorch implementation of Distributed Proximal Policy Optimization
Pytorch-DPPO Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286 Using PPO with clip loss (from https
164 Jan 5, 2023
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022
PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL).
pytorch-a2c-ppo-acktr Update (April 12th, 2021) PPO is great, but Soft Actor Critic can be better for many continuous control tasks. Please check out
3k Jan 9, 2023
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
 2.8k Jan 7, 2023
2.8k Jan 7, 2023
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 463 Dec 9, 2022
463 Dec 9, 2022
Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app.
django-permissions-policy Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app. Requirements Python 3.
76 Nov 30, 2022
Code for technical report "An Improved Baseline for Sentence-level Relation Extraction".
RE_improved_baseline Code for technical report "An Improved Baseline for Sentence-level Relation Extraction". Requirements torch = 1.8.1 transformers
 74 Nov 29, 2022
74 Nov 29, 2022
Code for the paper "TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks"
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks This is a Python3 / Pytorch implementation of TadGAN paper. The associated
 92 Dec 3, 2022
92 Dec 3, 2022
Finetuning Pipeline
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
74 Dec 13, 2022
Pytorch implementations of popular off-policy multi-agent reinforcement learning algorithms, including QMix, VDN, MADDPG, and MATD3.
Off-Policy Multi-Agent Reinforcement Learning (MARL) Algorithms This repository contains implementations of various off-policy multi-agent reinforceme
 183 Dec 28, 2022
183 Dec 28, 2022
Continuum Learning with GEM: Gradient Episodic Memory
Gradient Episodic Memory for Continual Learning Source code for the paper: @inproceedings{GradientEpisodicMemory, title={Gradient Episodic Memory
 360 Dec 27, 2022
360 Dec 27, 2022

Pytorch Implementation of paper "Noisy Natural Gradient as Variational Inference"
Noisy Natural Gradient as Variational Inference PyTorch implementation of Noisy Natural Gradient as Variational Inference. Requirements Python 3 Pytor
 119 Dec 2, 2022
119 Dec 2, 2022
PyTorch implementation of Trust Region Policy Optimization
PyTorch implementation of TRPO Try my implementation of PPO (aka newer better variant of TRPO), unless you need to you TRPO for some specific reasons.
366 Nov 15, 2022
Proximal Backpropagation - a neural network training algorithm that takes implicit instead of explicit gradient steps
Proximal Backpropagation Proximal Backpropagation (ProxProp) is a neural network training algorithm that takes implicit instead of explicit gradient s
 40 Dec 17, 2022
40 Dec 17, 2022

A tiny, friendly, strong baseline code for Person-reID (based on pytorch).
Pytorch ReID Strong, Small, Friendly A tiny, friendly, strong baseline code for Person-reID (based on pytorch). Strong. It is consistent with the new
 3.5k Jan 8, 2023
3.5k Jan 8, 2023
A Strong Baseline for Image Semantic Segmentation
A Strong Baseline for Image Semantic Segmentation Introduction This project is an open source semantic segmentation toolbox based on PyTorch. It is ba
 49 Sep 20, 2022
49 Sep 20, 2022

This is the pytorch implementation of the paper - Axiomatic Attribution for Deep Networks.
Integrated Gradients This is the pytorch implementation of "Axiomatic Attribution for Deep Networks". The original tensorflow version could be found h
 150 Dec 23, 2022
150 Dec 23, 2022
This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch
This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch. It uses a simple TestEnvironment to test the algorithm
59 Dec 9, 2022

Bonsai: Gradient Boosted Trees + Bayesian Optimization
Bonsai is a wrapper for the XGBoost and Catboost model training pipelines that leverages Bayesian optimization for computationally efficient hyperparameter tuning.
 24 Oct 27, 2022
24 Oct 27, 2022

Official implementation of paper Gradient Matching for Domain Generalization
Gradient Matching for Domain Generalisation This is the official PyTorch implementation of Gradient Matching for Domain Generalisation. In our paper,
 94 Dec 23, 2022
94 Dec 23, 2022
a baseline to practice
ccks2021_track3_baseline a baseline to practice 路径可能会有问题,自己改改 torch==1.7.1 pyhton==3.7.1 transformers==4.7.0 cuda==11.0 this is a baseline, you can fi
 45 Nov 23, 2022
45 Nov 23, 2022
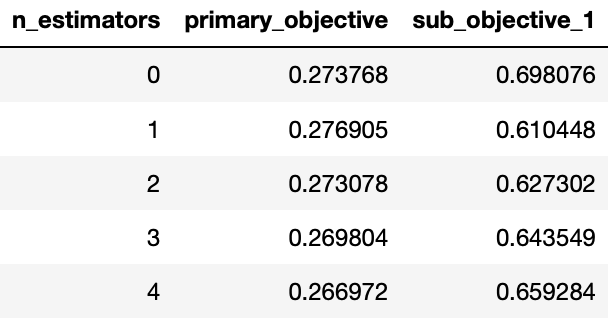
MooGBT is a library for Multi-objective optimization in Gradient Boosted Trees.
MooGBT is a library for Multi-objective optimization in Gradient Boosted Trees. MooGBT optimizes for multiple objectives by defining constraints on sub-objective(s) along with a primary objective. The constraints are defined as upper bounds on sub-objective loss function. MooGBT uses a Augmented Lagrangian(AL) based constrained optimization framework with Gradient Boosted Trees, to optimize for multiple objectives.
 66 Dec 6, 2022
66 Dec 6, 2022

DFM: A Performance Baseline for Deep Feature Matching
DFM: A Performance Baseline for Deep Feature Matching Python (Pytorch) and Matlab (MatConvNet) implementations of our paper DFM: A Performance Baselin
 143 Jan 2, 2023
143 Jan 2, 2023
ASVspoof 2021 Baseline Systems
ASVspoof 2021 Baseline Systems Baseline systems are grouped by task: Speech Deepfake (DF) Logical Access (LA) Physical Access (PA) Please find more de
 91 Dec 28, 2022
91 Dec 28, 2022
Implementation of Learning Gradient Fields for Molecular Conformation Generation (ICML 2021).
[PDF] | [Slides] The official implementation of Learning Gradient Fields for Molecular Conformation Generation (ICML 2021 Long talk) Installation Inst
 117 Dec 9, 2022
117 Dec 9, 2022
A baseline code for VSPW
A baseline code for VSPW Preparation Download VSPW dataset The VSPW dataset with extracted frames and masks is available here.
 28 Aug 22, 2022
28 Aug 22, 2022

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

Official Code for ICML 2021 paper "Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline"
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline Ankit Goyal, Hei Law, Bowei Liu, Alejandro Newell, Jia Deng Internati
 115 Jan 4, 2023
115 Jan 4, 2023